基于Docker快速安装Spark及基础使用
基于Docker快速安装Spark及基础使用
- 实战环境信息
- docker编排工具docker-compose安装
-
- 使用官网指导方式安装(不推荐)
- 使用国内镜像源安装(推荐)
- 安装docker的spark镜像
- 结果
- 通过 Spark Shell 进行交互分析
- 基础操作
-
- 新建RDD
- RDD的更多操作
- 缓存
- Spark SQL 和 DataFrames
- Spark Streaming
- 独立应用程序(Self-Contained Applications)
-
- 应用程序代码
- 安装 sbt
- 使用 sbt 打包 Scala 程序
- 通过 spark-submit 运行程序
- 进阶学习
学习和开发阶段的同学关注的是spark应用的开发,他们希望整个环境能快速搭建好,从而尽快投入编码和调试,今天咱们就借助docker,极速搭建和体验spark和hdfs的集群环境。
实战环境信息
以下是本次实战涉及的版本号:
操作系统:macOS Catalina 10.15.7
hadoop:2.8.2
spark:2.2.1
docker:19.03.13
docker-compose:1.27.4
docker编排工具docker-compose安装
使用官网指导方式安装(不推荐)
https://docs.docker.com/compose/install/
使用国内镜像源安装(推荐)
curl -L https://get.daocloud.io/docker/compose/releases/download/1.27.4/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
测试是否安装成功
docker-compose --version
出现
docker-compose version 1.27.4, build 40524192
就安装成功了
安装docker的spark镜像
singularities/spark:2.2
yzheng@zhengyideMacBook-Pro bin % docker pull singularities/spark
查看镜像是否安装成功
docker image ls
创建docker-compose.yml
yzheng@zhengyideMacBook-Pro bin % pwd
/Users/yzheng/Work/docker/spark/local/bin
yzheng@zhengyideMacBook-Pro bin % mkdir singularitiesCR
yzheng@zhengyideMacBook-Pro bin % cd singularitiesCR
yzheng@zhengyideMacBook-Pro singularitiesCR % vim docker-compose.yml
编辑
version: "2"
services:
master:
image: singularities/spark
command: start-spark master
hostname: master
ports:
- "6066:6066"
- "7070:7070"
- "8080:8080"
- "50070:50070"
worker:
image: singularities/spark
command: start-spark worker master
environment:
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 2g
links:
- master
volumes:
# 设置本地目录和镜像目录的映射关系(格式:本地机器目录:镜像中对应路径)
- /Users/yzheng/Work/docker/spark/local/bin/singularitiesCR/data:/input_files
在刚刚建立docker-compose.yml文件目录下面使用命令
yzheng@zhengyideMacBook-Pro singularitiesCR % docker-compose up -d
Creating network "singularitiescr_default" with the default driver
Creating singularitiescr_master_1 ... done
Creating singularitiescr_worker_1 ... done
查看容器运行
yzheng@zhengyideMacBook-Pro singularitiesCR % docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------------------------
singularitiescr_master_1 start-spark master Up 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp,
0.0.0.0:50070->50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp,
0.0.0.0:6066->6066/tcp, 0.0.0.0:7070->7070/tcp, 7077/tcp, 8020/tcp,
0.0.0.0:8080->8080/tcp, 8081/tcp, 9000/tcp
singularitiescr_worker_1 start-spark worker master Up 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp,
50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp, 6066/tcp, 7077/tcp, 8020/tcp,
8080/tcp, 8081/tcp, 9000/tcp
查看本机IP
yzheng@zhengyideMacBook-Pro bin % ifconfig
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=1203<RXCSUM,TXCSUM,TXSTATUS,SW_TIMESTAMP>
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
nd6 options=201<PERFORMNUD,DAD>
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
ap1: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
options=400<CHANNEL_IO>
ether b2:9c:4a:c2:9a:e5
media: autoselect
status: inactive
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=400<CHANNEL_IO>
ether 90:9c:4a:c2:9a:e5
inet6 fe80::1070:511d:43bc:b01e%en0 prefixlen 64 secured scopeid 0x6
inet 192.168.101.33 netmask 0xfffffe00 broadcast 192.168.101.255
nd6 options=201<PERFORMNUD,DAD>
media: autoselect
status: active
结果
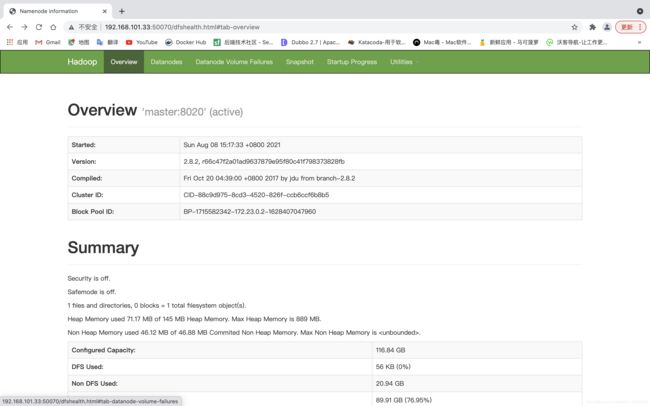
Hadoop管理界面:
http://本机IP:50070/dfshealth.html#tab-overview
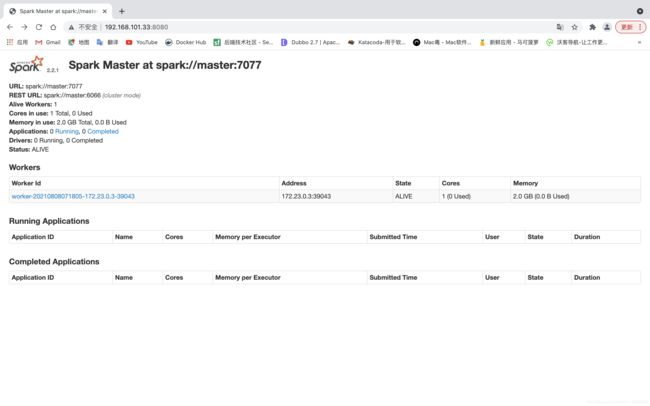
Spark任务管理页面
http://本机IP:8080/
停止容器
yzheng@zhengyideMacBook-Pro singularitiesCR % docker-compose stop
删除容器
yzheng@zhengyideMacBook-Pro singularitiesCR % docker-compose rm
通过 Spark Shell 进行交互分析
Spark shell 提供了简单的方式来学习 API,也提供了交互的方式来分析数据。Spark Shell 支持 Scala 和 Python,本教程选择使用 Scala 来进行介绍。
Scala
Scala是一门现代的多范式编程语言,志在以简练、优雅及类型安全的方式来表达常用编程模式。它平滑地集成了面向对象和函数语言的特性。Scala 运行于
Java 平台(JVM,Java 虚拟机),并兼容现有的 Java 程序。
Scala 是 Spark 的主要编程语言,如果仅仅是写 Spark 应用,并非一定要用 Scala,用 Java、Python 都是可以的。使用 Scala 的优势是开发效率更高,代码更精简,并且可以通过 Spark Shell 进行交互式实时查询,方便排查问题。
进入容器
yzheng@zhengyideMacBook-Pro singularitiesCR % docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
69d96c280b0e singularities/spark "start-spark worker …" 32 minutes ago Up 32 minutes 6066/tcp, 7077/tcp, 8020/tcp, 8080-8081/tcp, 9000/tcp, 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp singularitiescr_worker_1
b2d23798e960 singularities/spark "start-spark master" 32 minutes ago Up 32 minutes 0.0.0.0:6066->6066/tcp, 7077/tcp, 0.0.0.0:7070->7070/tcp, 8020/tcp, 8081/tcp, 9000/tcp, 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 0.0.0.0:8080->8080/tcp, 50020/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 0.0.0.0:50070->50070/tcp, 50475/tcp singularitiescr_master_1
yzheng@zhengyideMacBook-Pro singularitiesCR % docker exec -it '容器的CONTAINER ID' /bin/bash
执行如下命令启动 Spark Shell:
root@master:~# /usr/local/spark-2.2.1/bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/08/08 09:16:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://172.23.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-1628414163526).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
基础操作
Spark 的主要抽象是分布式的元素集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDDs 可以通过 Hadoop InputFormats 创建(如 HDFS),或者从其他 RDDs 转化而来。
我们从 ./README 文件新建一个 RDD,代码如下(本文出现的 Spark 交互式命令代码中,与位于同一行的注释内容为该命令的说明,命令之后的注释内容表示交互式输出结果):
val textFile = sc.textFile("file:///usr/local/spark-2.2.1/README.md")
// textFile: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark-2.2.1/README.md MapPartitionsRDD[1] at textFile at :24
代码中通过 “file://” 前缀指定读取本地文件。Spark shell 默认是读取 HDFS 中的文件,需要先上传文件到 HDFS 中,否则会有“org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://localhost:9000/user/hadoop/README.md”的错误。
新建RDD
RDDs 支持两种类型的操作
- actions: 在数据集上运行计算后返回值
- transformations: 转换, 从现有数据集创建一个新的数据集
下面我们就来演示 count() 和 first() 操作:
textFile.count() // RDD 中的 item 数量,对于文本文件,就是总行数
// res0: Long = 103
textFile.first() // RDD 中的第一个 item,对于文本文件,就是第一行内容
// res1: String = # Apache Spark
接着演示 transformation,通过 filter transformation 来返回一个新的 RDD,代码如下:
val linesWithSpark = textFile.filter(line => line.contains("Spark")) // 筛选出包含 Spark 的行
linesWithSpark.count() // 统计行数
// res4: Long = 20
可以看到一共有20行内容包含 Spark,这与通过 Linux 命令
cat ./README.md | grep "Spark" -c
得到的结果一致,说明是正确的。
action 和 transformation 可以用链式操作的方式结合使用,使代码更为简洁:
textFile.filter(line => line.contains("Spark")).count() // 统计包含 Spark 的行数
// res4: Long = 20
RDD的更多操作
RDD 的 actions 和 transformations 可用在更复杂的计算中,例如通过如下代码可以找到包含单词最多的那一行内容共有几个单词:
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
// res5: Int = 22
代码首先将每一行内容 map 为一个整数,这将创建一个新的 RDD,并在这个 RDD 中执行 reduce 操作,找到最大的数。map()、reduce() 中的参数是 Scala 的函数字面量(function literals,也称为闭包 closures),并且可以使用语言特征或 Scala/Java 的库。例如,通过使用 Math.max() 函数(需要导入 Java 的 Math 库),可以使上述代码更容易理解:
import java.lang.Math
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
// res6: Int = 22
Hadoop MapReduce 是常见的数据流模式,在 Spark 中同样可以实现(下面这个例子也就是 WordCount):
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 实现单词统计
// wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[7] at reduceByKey at :26
wordCounts.collect() // 输出单词统计结果
// res5: Array[(String, Int)] = Array((package,1), (this,1), (Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1), (Because,1), (Python,2), (page](http://spark.apache.org/documentation.html).,1), (cluster.,1), (its,1), ([run,1), (general,3), (have,1), (pre-built,1), (YARN,,1), (locally,2), (changed,1), (locally.,1), (sc.parallelize(1,1), (only,1), (several,1), (This,2), (basic,1), (Configuration,1), (learning,,1), (documentation,3), (first,1), (graph,1), (Hive,2), (info,1), (["Specifying,1), ("yarn",1), ([params]`.,1), ([project,1), (prefer,1), (SparkPi,2), (缓存
Spark 支持在集群范围内将数据集缓存至每一个节点的内存中,可避免数据传输,当数据需要重复访问时这个特征非常有用,例如查询体积小的“热”数据集,或是运行如 PageRank 的迭代算法。调用 cache(),就可以将数据集进行缓存:
linesWithSpark.cache()
Spark SQL 和 DataFrames
Spark SQL 是 Spark 内嵌的模块,用于结构化数据。在 Spark 程序中可以使用 SQL 查询语句或 DataFrame API。DataFrames 和 SQL 提供了通用的方式来连接多种数据源,支持 Hive、Avro、Parquet、ORC、JSON、和 JDBC,并且可以在多种数据源之间执行 join 操作。
下面仍在 Spark shell 中演示一下 Spark SQL 的基本操作,该部分内容主要参考了 Spark SQL、DataFrames 和 Datasets 指南。
Spark SQL 的功能是通过 SQLContext 类来使用的,而创建 SQLContext 是通过 SparkContext 创建的。在 Spark shell 启动时,输出日志的最后有这么几条信息
16/01/16 13:25:41 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
16/01/16 13:25:41 INFO repl.SparkILoop: Created sql context..
SQL context available as sqlContext.
Spark context available as 'sc' (master = local[*], app id = local-1628414163526).
Spark session available as 'spark'.
这些信息表明 Spark context 和 Spark session 都已经初始化好了,可通过对应的 sc、spark 变量直接进行访问。
使用 Spark session 可以从现有的 RDD 或数据源创建 DataFrames。作为示例,我们通过 Spark 提供的 JSON 格式的数据源文件 ./examples/src/main/resources/people.json 来进行演示,该数据源内容如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
执行如下命令导入数据源,并输出内容:
val df = spark.read.json("file:///usr/local/spark-2.2.1/examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show() // 输出数据源内容
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
接着,我们来演示 DataFrames 处理结构化数据的一些基本操作:
df.select("name").show() // 只显示 "name" 列
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
df.select(df("name"), df("age") + 1).show() // 将 "age" 加 1
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
df.filter(df("age") > 21).show() // 条件语句
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
df.groupBy("age").count().show() // groupBy 操作
// +----+-----+
// | age|count|
// +----+-----+
// |null| 1|
// | 19| 1|
// | 30| 1|
// +----+-----+
当然,我们也可以使用 SQL 语句来进行操作:
df.createOrReplaceTempView("people") // 将 DataFrame 注册为临时表 people
val result = spark.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19") // 执行 SQL 查询
result.show() // 输出结果
// +------+---+
// | name|age|
// +------+---+
// |Justin| 19|
// +------+---+
更多的功能可以查看完整的 DataFrames API ,此外 DataFrames 也包含了丰富的 DataFrames Function 可用于字符串处理、日期计算、数学计算等。
Spark Streaming
流计算除了使用 Storm 框架,使用 Spark Streaming 也是一个很好的选择。基于 Spark Streaming,可以方便地构建可拓展、高容错的流计算应用程序。Spark Streaming 使用 Spark API 进行流计算,这意味着在 Spark 上进行流处理与批处理的方式一样。因此,你可以复用批处理的代码,使用 Spark Streaming 构建强大的交互式应用程序,而不仅仅是用于分析数据。
下面以一个简单的 Spark Streaming 示例(基于流的单词统计)来演示一下 Spark Streaming:本地服务器通过 TCP 接收文本数据,实时输出单词统计结果。该部分内容主要参考了 Spark Streaming 编程指南。
运行该示例需要 Netcat(在网络上通过 TCP 或 UDP 读写数据),CentOS 6.x 系统中默认没有安装,经过测试,如果通过 yum 直接安装,运行时会有 “nc: Protocol not available” 的错误,需要下载较低版本的 nc 才能正常使用。我们选择 Netcat 0.6.1 版本,在终端中运行如下命令进行安装:
wget http://downloads.sourceforge.net/project/netcat/netcat/0.6.1/netcat-0.6.1-1.i386.rpm -O ~/netcat-0.6.1-1.i386.rpm # 下载
sudo rpm -iUv ~/netcat-0.6.1-1.i386.rpm # 安装
安装好 NetCat 之后,使用如下命令建立本地数据服务,监听 TCP 端口 9999:
// 记为终端 1
nc -l -p 9999
启动后,该端口就被占用了,需要开启另一个终端运行示例程序,执行如下命令:
// 需要另外开启一个终端,记为终端 2,然后运行如下命令
/usr/local/spark-2.2.1/bin/run-example streaming.NetworkWordCount localhost 9999
接着在终端 1 中输入文本,在终端 2 中就可以实时看到单词统计结果了。
Spark Streaming 的内容较多,本教程就简单介绍到这,更详细的内容可查看官网教程。
最后需要关掉终端 2,并按 ctrl+c 退出 终端 1 的Netcat。
独立应用程序(Self-Contained Applications)
接着我们通过一个简单的应用程序 SimpleApp 来演示如何通过 Spark API 编写一个独立应用程序。使用 Scala 编写的程序需要使用 sbt 进行编译打包,相应的,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。
应用程序代码
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark-2.2.1/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。在 ./sparkapp 中新建文件 simple.sbt(vim ./sparkapp/simple.sbt),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.2.1"
文件 simple.sbt 需要指明 Spark 和 Scala 的版本。启动 Spark shell 的过程中,当输出到 Spark 的符号图形时,可以看到相关的版本信息。
安装 sbt
Spark 中没有自带 sbt,需要手动安装 sbt,我们选择安装在 /usr/local/sbt 中:
sudo mkdir /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名
cd /usr/local/sbt
经笔者测试,按官网教程安装 sbt 0.13.9 后,使用时可能存在网络问题,无法下载依赖包,导致 sbt 无法正常使用,需要进行一定的修改。为方便,请使用笔者修改后的版本,下载地址:http://pan.baidu.com/s/1eRyFddw。
下载后,执行如下命令拷贝至 /usr/local/sbt 中:
cp ~/download/sbt-launch.jar .
接着在 /usr/local/sbt 中创建 sbt 脚本(vim ./sbt),添加如下内容:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
保存后,为 ./sbt 脚本增加可执行权限:
chmod u+x ./sbt
最后检验 sbt 是否可用(首次运行会处于 “Getting org.scala-sbt sbt 0.13.9 …” 的下载状态,请耐心等待。笔者等待了 7 分钟才出现第一条下载提示):
./sbt sbt-version
下载过程中可能会类似 “Server access Error: java.security.ProviderException: java.security.KeyException url=https://jcenter.bintray.com/org/scala-sbt/precompiled-2_9_3/0.13.9/precompiled-2_9_3-0.13.9.jar” 的错误,可以忽略。可再执行一次 ./sbt sbt-version,只要能得到如下图的版本信息就没问题:
如果由于网络问题无法下载依赖,导致 sbt 无法正确运行的话,可以下载笔者提供的离线依赖包 sbt-0.13.9-repo.tar.gz 到本地中(依赖包的本地位置为 ~/.sbt 和 ~/.ivy2,检查依赖关系时,首先检查本地,本地未找到,再从网络中下载),下载地址:http://pan.baidu.com/s/1sjTQ8yD。下载后,执行如下命令解压依赖包:
tar -zxf ~/download/sbt-0.13.9-local-repo.tar.gz ~
通过这个方式,一般可以解决依赖包缺失的问题(读者提供的依赖包仅适合于 Spark 1.6 版本,不同版本依赖关系不一样)。
如果对 sbt 存在的网络问题以及如何解决感兴趣,请点击下方查看。
点击查看:解决 sbt 无法下载依赖包的问题
使用 sbt 打包 Scala 程序
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp
find .
文件结构应如下图所示:
SimpleApp的文件结构
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包,如果这边遇到网络问题无法成功,也请下载上述安装 sbt 提到的离线依赖包 sbt-0.13.9-repo.tar.gz ):
/usr/local/sbt/sbt package
打包成功的话,会输出如下图内容:
SimpleApp的文件结构
生成的 jar 包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
通过 spark-submit 运行程序
最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark-2.2.1/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
# 输出信息太多,可以通过如下命令过滤直接查看结果
/usr/local/spark-2.2.1/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
最终得到的结果如下:
Lines with a: 58, Lines with b: 26
自此,你就完成了你的第一个 Spark 应用程序了。
进阶学习
Spark 官网提供了完善的学习文档(许多技术文档都只有英文版本,因此学会查看英文文档也是学习大数据技术的必备技能):
- 如果想对 Spark 的 API 有更深入的了解,可查看的 Spark 编程指南(Spark Programming Guide);
- 如果你想对 Spark SQL 的使用有更多的了解,可以查看 Spark SQL、DataFrames 和 Datasets 指南;
- 如果你想对 Spark Streaming 的使用有更多的了解,可以查看 Spark Streaming 编程指南;
- 如果需要在集群环境中运行 Spark 程序,可查看官网的 Spark 集群部署