大一大二项目总结
表记识别系统
背景
近年来我国电网规模不断扩大,变电站数量激增,设备规模的快速增长对设备状态管控及运行可 靠性提出了更高要求。目前的巡检大部分由人工完成,运营成本过高,但工作强度大,人员能力不同,巡检质量存在问题;记录方式落后,数据也难以查找和长期储存,不利于电表的维护与更新;存在安全隐患。
设计与实现过程
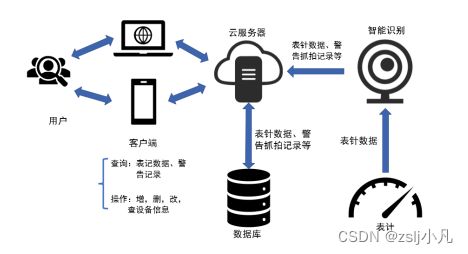
在某变电站进行机器人抓拍或固定摄像头拍摄,传送到云端进行图像识别,得到读数结果后再转发给后端处理,分析读数结果,最后使用可视化数据大屏展示给变电站运维人员。
重难点和创新点
可以多表记同时识别
可以多指针提取识别
可以残缺刻度补全

识别可视化图
此项目关键点在于语义分割模型识别准确度和残缺刻度补全算法。
本项目是学长领着做的,主要体验了数据集的制作和处理,了解计算机视觉方面的知识,会应用。
手语识别系统
背景
据统计全球有超过7000万聋哑人,然而绝大部分正常人对手语的了解基本为零,目前国内手语翻译机器市场也仍然处于萌芽期,至今未能有一种较为全面的手语翻译设备在市场上普及。目前国内手语翻译市场中大多数仍为人工翻译,然而人工翻译成本极高,在最新的一项调查表明,手语翻译员供给严重不足,46.8%的手语译员专业知识不够,不能够做到同步翻译。
 标题路演ppt
标题路演ppt
tellme团队于2022年12月成立,团队从成立之初就致力于为全球7000万聋哑人提供与正常人交流的桥梁,团队成员结合所学知识,通过不断讨论,在老师的指导下开发出了基于多场景应用下的聋哑人双向交流设备,系统使用多种传感器和计算机视觉技术捕捉聋哑人的手语动作,并将其翻译成文本或语音输出给正常人。使用麦克风捕捉正常人的声音并将其翻译成手语,以数字人的形式播放手语动作给聋哑人观看;系统通过算法与多种传感器的结合,提高翻译准确率,帮助聋哑人更好地交流。使用双通道技术可以解决了聋哑人与正常人的实时双向交流的问题 ,适用于多种使用场景,打造针对聋哑人沟通交流的一站式平台。经过团队成员不断实践,2023年3月确定核心算法和模型、完成用户界面和交互系统的开发,2023年5月采用计算机视觉技术开发出立体式树莓派智慧屏产品,2023年6月采用多模态传感器开发出便携式可穿戴手套产品。
设计与实现过程
使用stm32加各类传感器的可穿戴式手套和树莓派搭载摄像头实现双通道的聋哑人手语识别,同时使用麦克风对正常人的语音进行识别,然后用数字人的方式向聋哑人展示手语动作,完成了聋哑人与正常人的实时双向交流。


计算机视觉 tensorflow
yolov7+mobilenetv3首先目标检测手掌位置,然后图像分类判断手语内容,每隔0.5s抽一帧识别,普通人和聋哑人语法不同,将手语识别结果放入set中,
nlp成正常语序,最后使用文字转语音功能在音响中播放出手语内容。
resnet50和mobilenetv3都试了 居然mobilenetv3的体积小准确率还高,可能我处理方式有问题,一开始文字转语音、语音转文字功能和手语识别模型不在一个平台上,很麻烦。后来转到了百度飞浆上,百度飞浆比较难用,我看文档看半天没看懂,他们搞一个软件想让新手用,可是我死活看不懂,真不如黑框框呢,可能我没充钱?还好最后还是移植过来了。
数据集让不同的人在不同地方进行拍摄,然后使用常见的数据增强方法增强数据,按模型平台要求处理数据集,然后训练,我用的自己的3060,打个大学生竞赛足够了。tf2平台时安装了cuda和cudnn,但是训练的时候总觉得我的3060在划水,没有出全力,不是很会整。换到百度飞浆的时候,主要是按要求改数据集格式,和tf2的不太一样。
命名不要有特殊符号和中文,一定和标数据集的人说好了,要不然自己还要处理,不过改个名也没那么麻烦,还好大一就有经验了。
主要用了paddlex和paddlehub
模型部署到了华为云上,一开始准备用边缘端设备的,可是感觉边缘端设备算力都很弱,最后就上云了。
Linux服务器 使用flask部署 华为真阔绰啊,送了计算型服务器供我们学习。
服务器上用了tmux、vim conda管理包 配好环境就能用了
上云部署模型对于我们软件工程专业的没一点难度,是做这个项目最顺利的方面。
前后端
介绍产品 卖产品 存数据 vue+springboot 打比赛主要搞前端,好看真的很重要。
后端如果真的做可能会很麻烦,不过竞赛里评委老师并不关注,所以就没有在后端下功夫,大三准备好好做个后端项目。
树莓派
使用opencv获取图像 pyqt制作页面 pyaudio录音
平常都是用的conda树莓派居然用不成,py最高版本3.6。本地一点问题没有,但是树莓派上库经常报错,环境配的让人很崩溃。
树莓派opencv和pyqt一直线程冲突,以下解决了问题
解决opencv-python和PyQt5相冲突问题(qt.qpa.plugin: Could not load the Qt platform plugin “xcb“)_pyqt5和opencv的冲突_shier_smile的博客-CSDN博客
数字人
建模一个我们自己的数字人形象,将文字转换为手语,因为大部分聋哑人并不识字,只能看懂手语。
本项目主要精力放在了计算机视觉和树莓派展示上,体验了深度学习各大平台计算机视觉的应用流程,在linux上部署深度学习模型,树莓派、海思视觉、各种传感器等硬件设备。
重难点和创新点
数据集
双向沟通交流
智慧书桌
背景
父母越来越重视孩子的教育和健康成长,而现实大多数父母很忙,无法顾及孩子,我们设计这款智慧书桌,可以代替部分家长职责,当然父母在外也可以监督到孩子的学习,同时保护孩子的身体姿态健康。

设计与实现过程
书法检测
yolov8+deepsort
识别笔画和顺序
智能问答
类似与老师或父母,书桌可以帮儿童解决作业难题,讲解知识,也可陪伴儿童讲故事等。
调用chatgpt或者其他模型,chatgpt已经预设形象,支持上下文,提问的问题进行prompt工程调优,以获得更好的答案,最后文字转语音播放给儿童听,儿童可使用麦克风向书桌提问。之后可以训练对应的儿童伴学模型以获得更好的效果,而不是依赖chatgpt。
智能点读
使用mediapipe进行手部关键点识别,以双手食指为选中区域,保持0.5s后对选中的部分进行ocr和目标检测。
这玩意想的挺简单,实现了蛮久的。

坐姿检测
图像分类 让孩子保持健康书写、学习姿势。
学习计划 聊天
springboot+微信小程序+qt实现孩子和家长、孩子和孩子、孩子和老师的沟通,家长和老师可以设定学习计划。
后期可以设计书桌,符合人体工程学,儿童成长较快,书桌易调整。
灯光控制,坐姿调整等。
目前做的核心是学习智能化,可以做成台灯那种样子,如果有精力设计书桌可以继续搞书桌。
总结
两个项目最后拿了四个国奖。我个人是想工作的,技术上还差很多,大概了解了前后端,人工智能,嵌入式,大数据,后面需要好好学一个方面,争取找到一份好工作,刚好疫情结束,出去玩了几次,很棒的体验。
感觉最大的成就是从零开始做一个项目吧,没有用祖传项目。从零构思想点子,系统设计,系统实现,项目路演和答辩,收获还是蛮多的。
创意确实重要,但最重要的还是落地吧,不实现就是0,一个感觉很简单的东西,配环境,写代码,就能让人头疼一下午。
Tale is cheap. Show me your code.
目前大三准备继续和室友去acm当当炮灰,然后就软件转嵌入式了。