PySpark实战(二)——Spark环境配置
# 下载spark安装包
cd /export/software
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
# 解压
tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /export/servers/安装Python3环境
下载安装包
wget https://www.python.org/ftp/python/3.8.15/Python-3.8.15.tgz解压
tar -zxvf Python-3.8.15.tgz -C /export/servers/配置
# 安装依赖
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel gcc make
# 更新
cd /export/servers/Python-3.8.15
./configure --prefix=/export/servers/Python-3.8.15
make && make install
# 添加软连接,保证每个目录下都能使用
ln -s /export/servers/Python-3.8.15/bin/pip3.8 /usr/bin/pip3
ln -s /export/servers/Python-3.8.15/bin/python3.8 /usr/bin/python3
# 配置镜像源
pip3 config --global set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/# 检验环境是否成功
cd /export/servers/spark-3.3.2-bin-hadoop3/bin
./spark-submit ../examples/src/main/python/pi.py
Spark环境
配置日志文件
cd /export/servers/spark-3.3.2-bin-hadoop3/conf重命名log4j2.properties.template文件为log4j2.properties
修改内容如下

保存后再执行,就没有多余的输出信息了

进入Spark交互界面
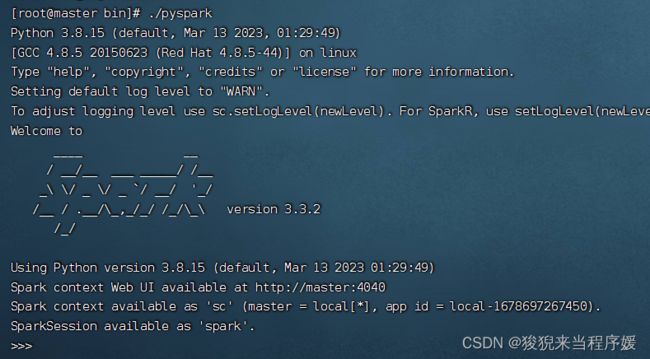
安装配置Spark集群
master机,切换目录,修改配置文件
![]()
重名名为spark-env.sh
# 切换目录
cd /export/servers/spark-3.3.2-bin-hadoop3/conf
# 修改配置文件,内容如下图
vi spark-env.sh
# 添加以下内容
PYSPARK_PYTHON=/export/servers/Python-3.8.15/bin/python3 export JAVA_HOME=/export/servers/jdk1.8.0_361 export HADOOP_HOME=/export/servers/hadoop-3.3.3 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop SPARK_MASTER_IP=master SPARK_LOCAL_DIRS=/export/servers/spark-3.3.2-bin-hadoop3
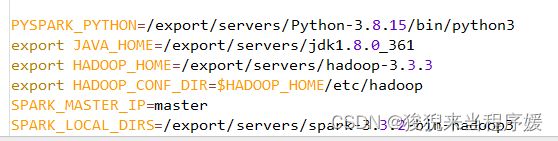
修改配置文件
vi /etc/profile
# 添加以下内容
export SPARK_HOME=/export/servers/spark-3.3.2-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
更新配置文件

修改下面这个文件的名字为workers
![]()
更改里面的内容为
server01
server02
【去三台机器上进行相同的配置】
# 启动Hadoop
cd /export/servers/hadoop-3.3.3/sbin
start-all.sh
# 启动Spark
cd /export/servers/spark-3.3.2-bin-hadoop3/sbin
start-master.sh
start-slaves.sh
# 提交Spark命令
cd /export/servers/spark-3.3.2-bin-hadoop3/bin
spark-submit --master=spark://master:7077 $SPARK_HOME/examples/src/main/python/pi.py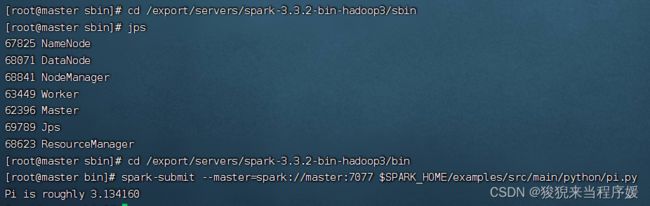
进入页面就能看到一条已经执行了的任务记录
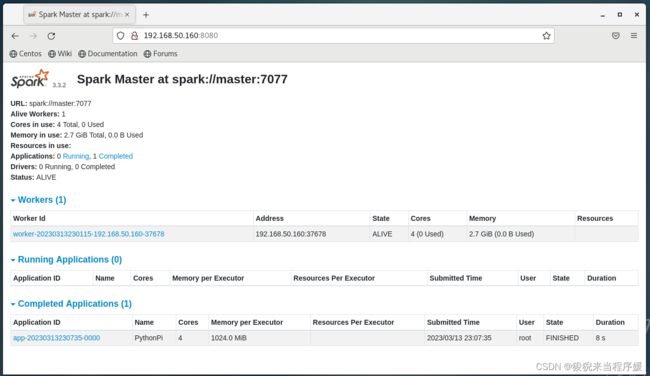
【上述是在Standalone集群下提交任务,在YARN提交如下所示】
# 执行命令
spark-submit --master yarn --deploy-mode client $SPARK_HOME/examples/src/main/python/pi.pyHive 和 Spark整合
# master机
# 将Hive的配置文件hive-site.xml复制到spark的conf目录
cd $HIVE_HOME/conf
cp hive-site.xml /export/servers/spark-3.3.2-bin-hadoop3/conf/
# 分发到其他电脑
scp -rq hive-site.xml server01:/export/servers/spark-3.3.2-bin-hadoop3/conf/
scp -rq hive-site.xml server02:/export/servers/spark-3.3.2-bin-hadoop3/conf/
scp /export/servers/apache-hive-2.3.9-bin/lib/HikariCP-2.5.1.jar master:/export/servers/spark-3.3.2-bin-hadoop3/jars
scp /export/servers/apache-hive-2.3.9-bin/lib/HikariCP-2.5.1.jar server01:/export/servers/spark-3.3.2-bin-hadoop3/jars
scp /export/servers/apache-hive-2.3.9-bin/lib/HikariCP-2.5.1.jar server02:/export/servers/spark-3.3.2-bin-hadoop3/jars
# 上传Mysql的JDBC驱动
cd /export/servers/mysql-connector-java-5.1.46
scp mysql-connector-java-5.1.46.jar master:/export/servers/spark-3.3.2-bin-hadoop3/jars
scp mysql-connector-java-5.1.46.jar server01:/export/servers/spark-3.3.2-bin-hadoop3/jars
scp mysql-connector-java-5.1.46.jar server02:/export/servers/spark-3.3.2-bin-hadoop3/jars【Hadoop引入了一个安全伪装机制,使得Hadoop不允许上层系统直接将实际用户传递到Hadoop层,而是将实际用户传递给一个超级代理,由代理在Hadoop上执行操作】
# 修改配置文件
vi /export/servers/hadoop-3.3.3/etc/hadoop/core-site.xml添加以下内容,解决User:root is not allowed to impersonate root的错误
hadoop.proxyuser.root.hosts * hadoop.proxyuser.roo.groups *

修改master的hive-site,添加以下内容
datanucleus.connectionPoolingType dbcp Expects one of [bonecp, dbcp, hikaricp, none]. Specify connection pool library for datanucleus
重启集群服务,使用Spark-sql

成功