Clickhouse学习笔记(4)—— Clickhouse SQL
insert
insert操作和mysql一致
- 标准语法:
insert into [table_name] values(…),(….) - 从表到表的插入:
insert into [table_name] select a,b,c from [table_name_2]
update 和 delete
ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看做 Alter 的一种;
具体语法:
Delete:ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr
Update:ALTER TABLE [db.]table [ON CLUSTER cluster] UPDATE column1 = expr1 [, ...] [IN PARTITION partition_id] WHERE filter_expr
相关文档:
ALTER TABLE … DELETE Statement | ClickHouse Docs
ALTER TABLE … UPDATE Statements | ClickHouse Docs
从官方文档可以看出:

虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务,不建议经常使用
为什么说Mutation 语句是一种很“重”的操作?
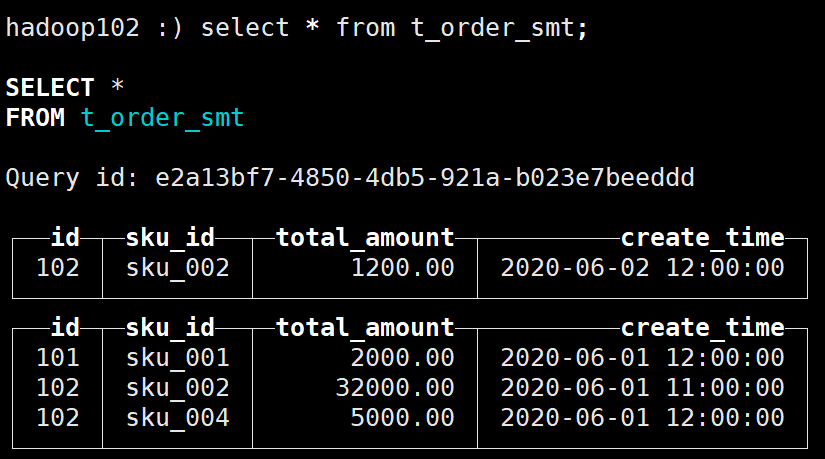
以
t_order_smt表为例:其中的数据如下:
data中的数据可以看出数据经过了一次合并:
在该表中进行删除操作:
alter table t_order_smt delete where sku_id ='sku_001';虽然执行速度很快,但是可以看到多出来了两个数据文件:
这是因为Mutation 语句分两步执行,同步执行的部分其实只是进行新增数据、新增分区和并把旧分区打上逻辑上的失效标记;直到触发分区合并的时候,才会删除旧数据释放磁盘空间
因此每一次delete、update都意味着对于之前数据的复制,所以说是一种
heavy operation同时可以注意到,每进行一次mutation操作,都会产生一个mutation_num.txt文件,其中有对于此次mutation操作的详细记录:
而num的数值和数据文件的后缀相对应;



因为delete和update起初都是很”重“的操作,因此官方也提供了相对轻量级的操作:

但仅限于delete操作,详见官网:The Lightweight DELETE Statement | ClickHouse Docs
这里的delete操作语法和MySQL等OLTP数据库相同:
DELETE FROM [db.]table [ON CLUSTER cluster] WHERE expr
尝试一下效果:
当前表中的数据如下:
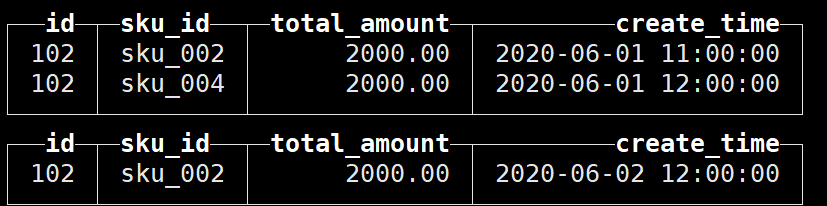
执行删除语句:delete from t_order_smt where sku_id = "sku_004";

发现并不支持,这是因为轻量级删除时v22.8版本才开放支持的功能
https://www.alibabacloud.com/help/zh/clickhouse/latest/new-features-overview
select
SELECT Query | ClickHouse Docs
查询操作和标准SQL语句差别不大:
1.支持子查询
2.支持 CTE(Common Table Expression 通用表表达式)
CTE是一种临时表,使用“WITH”命令,可以执行递归查询:
语法如下:
WITH cte1 AS (SELECT a, b FROM table1), cte2 AS (SELECT c, d FROM table2) SELECT b, d FROM cte1 JOIN cte2 WHERE cte1.a= cte2.c;
3.支持各种 JOIN,但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新 SQL
4.窗口函数(v21.3之后开放实验性窗口函数;目前已全面支持窗口函数)
Window Functions | ClickHouse Docs
5.不支持自定义函数
6.GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计
with rollup:从右至左去掉维度进行小计
with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
with totals: 只计算合计
比如说group by a,b
with rollup:相当于group by a,b,group by a,group by null
with cube:相当于group by a,b,group by a,group by b,group by null
with totals:相当于group by a,b,group by null
group by 测试
插入数据:
alter table t_order_mt delete where 1=1;
insert into t_order_mt values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),\
(101,'sku_002',2000.00,'2020-06-01 12:00:00'),\
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),\
(105,'sku_003',600.00,'2020-06-02 12:00:00'),\
(106,'sku_001',1000.00,'2020-06-04 12:00:00'),\
(107,'sku_002',2000.00,'2020-06-04 12:00:00'),\
(108,'sku_004',2500.00,'2020-06-04 12:00:00'),\
(109,'sku_002',2000.00,'2020-06-04 12:00:00'),\
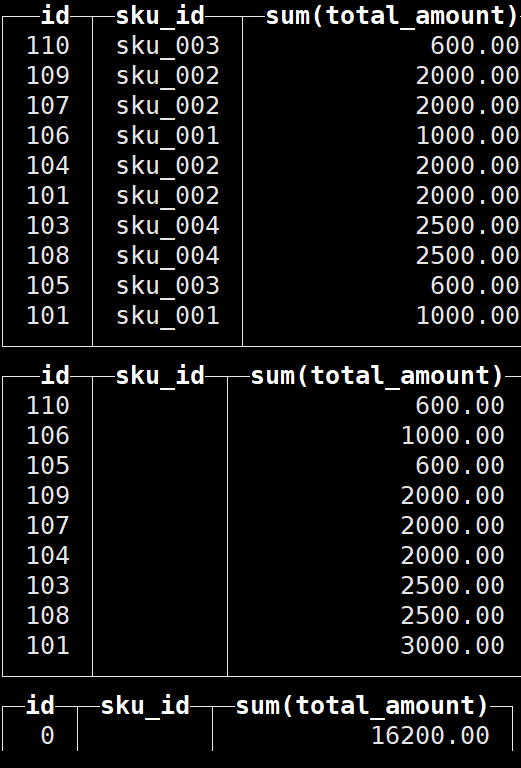
(110,'sku_003',600.00,'2020-06-01 12:00:00');with rollup:
select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with rollup;
结果如下:
with cube:
select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with cube;
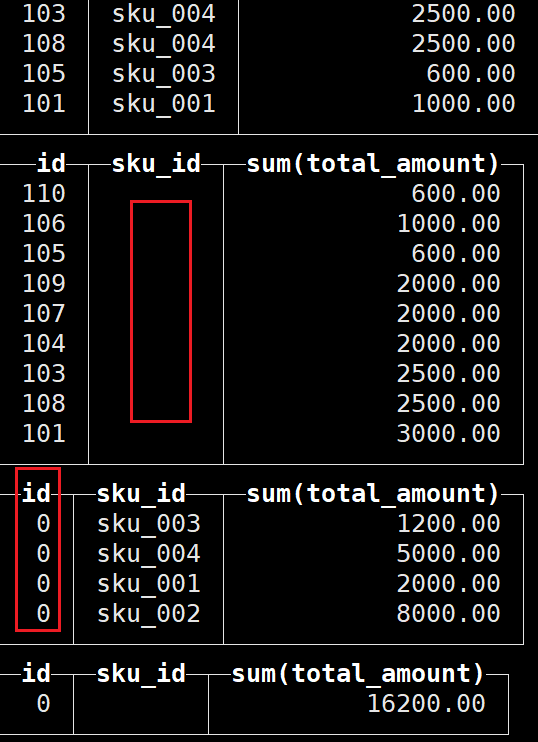
with totals:
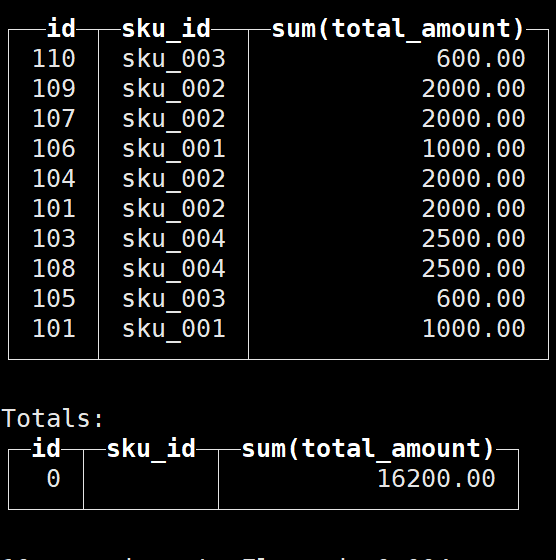
alter操作
新增字段 add column
alter table tableName add column newcolname String after col1;
可以指定新增字段的位置
修改字段 modify column
alter table tableName modify column newcolname String;
删除字段
alter table tableName drop column newcolname;
更多操作详见:Column Manipulations | ClickHouse Docs
数据导出
语法格式如下:
clickhouse-client --password=why666 --query "select * from t_order_mt where create_time='2020-06-01 12:00:00'" --format CSVWithNames> /home/why/data/ck1.csv执行命令后可以看到相应的csv文件:

注意:因为clickhouse中的一般是宽表,导出数据的功能不常用
更多数据格式详见:Formats for Input and Output Data | ClickHouse Docs