Multi-task Adversarial Learning for Semi-supervised Trajectory-User Linking
该论文发表于2022年的 ECML PKDD。
创新点:
1.对轨迹进行补全操作,并且使用卡尔曼滤波器进行细粒度的位置补全。
2.在轨迹补全时补全的是轨迹缺失点所在的单元区域,这样容易建模。
3.采用对抗学习的半监督方式来解决TUL问题。
4.在数据分布级别而不是一对一匹配的方式解决TUL问题。
思考:
1. 数据分布级别对于大量轨迹补全与轨迹特征提取工作量很大。
2.需要完整的轨迹作为标签,在实际应用中可能没有条件。
Abstract
现有方法通常将 TUL 视为一个监督学习问题,需要大量标记的轨迹-用户对。然而,在实际场景中,由于数据隐私问题,用户可能不愿意公开他们的身份,从而导致标记轨迹用户对的稀缺。此外,轨迹数据通常是稀疏的,因为用户在去 POI 时并不总是签到。所以存在以下两个通用问题:(1)标记的轨迹-用户对缺失(2)轨迹的签到点稀疏。然后作者提出了一个半监督学习框架。分为两个部分,第一部分是seq2seq部分,由编码器和解码器组成,主要用于完成轨迹补全。第二部分是体现半监督性质的对抗学习模块,由生成器和辨别器组成,主要用于完成用户与他生成的轨迹对应。
1 Introduction
在许多在线应用程序中,由于隐私问题,用户通常不愿意公开与他们的轨迹相关的个人身份信息。 在这种情况下,平台只能收集轨迹数据,但生成这些数据的用户是未知的。 将轨迹链接到生成它们的用户,也称为轨迹用户链接 (TUL),对于许多任务至关重要。
然而,由于以下两大挑战,现有作品的性能在实际应用场景中可能并不乐观。 首先,在 Foursquare 等许多 LBSN 平台中,用户在前往 POI 时并不总是会签到并分享他们的位置。 由于数据隐私问题,用户不愿意签到是很常见的,这导致了大量稀疏和不完整的轨迹。 现有工作大多认为用户轨迹是完整的,因此它们可能不适用于实际应用。 其次,现有的基于监督学习的方法需要大量带注释的轨迹-用户对,这非常耗时且成本高。 如何在半监督学习框架下用几个标记的轨迹-用户对进行 TUL 具有挑战性且探索较少。
本文提出了一种名为 TULMAL 的多任务对抗学习模型,以同时执行稀疏轨迹补全和半监督 TUL。 具体来说,TULMAL 首先通过提出的 seq2seq 模型补全稀疏原始轨迹数据。 稀疏轨迹数据首先输入 seq2seq 模型的编码器以学习潜在特征表示。 然后,由于卡尔曼滤波器在校准时间数据噪声估计方面的有效性,我们采用卡尔曼滤波来校准补全轨迹时估计的缺失单元区域位置,并将其耦合到 seq2seq 模型的解码器中。 然后将补全的轨迹输入到 TUL 的对抗性学习模型中。 我们不是将轨迹-用户对一对一地进行匹配,而是将所有用户和轨迹作为一个整体来考虑,并从数据分布层面进行 TUL(Multi-task Learning)。 我们的目标是学习一个投影函数 Φ 以将用户和轨迹嵌入到一个共同的潜在空间中。 假设如果两个用户的轨迹相似,则两个用户相似,反之亦然,投影 Φ 应该使轨迹接近在特征空间中生成它的用户。 为此,TULMAL 使用对抗学习框架来学习投影函数 Φ。 具体来说,TULMAL 包含一个编码器 E、一个解码器 O 和一个鉴别器 D。编码器 E 将轨迹的特征向量映射到一个共享的潜在空间,解码器 O 将潜在空间特征作为生成的样本投射到用户空间。 编码器和解码器一起作为投影函数 Φ 工作。 鉴别器 D 旨在将用户的真实实例与解码器生成的样本区分开来。 通过对抗性学习,鉴别器实质上估计了用户分布与投影轨迹分布之间的近似 Wasserstein 距离。 通过与鉴别器的竞争,投影函数 Φ 将被更新以最小化估计的 Wasserstein 距离。 给定一条新的未标记轨迹,它将首先通过 Φ 投影到用户空间,然后链接到离它最近的用户。
2 Related Work
2.1 Trajectory Completion
现有的轨迹补全工作有两类:第一类工作是直接补全缺失位置的轨迹,第二类是通过下一步或短期POI预测来恢复轨迹。
第一类:
Reducing Uncertainty of Low-Sampling-Rate Trajectories(2012 ICDE)提出通过比较历史轨迹与稀疏轨迹的相似性来推断稀疏轨迹的缺失部分。
AttnMove: History Enhanced Trajectory Recovery via Attentional Network(2021 AAAI)通过基于历史轨迹恢复未观察到的位置来完成个体轨迹。
Modelling of Bi-Directional Spatio-Temporal Dependence and Users’ Dynamic Preferences for Missing POI Check-In Identification(2019 AAAI)提出了双向空间和时间依赖性和用户的动态偏好模型来识别丢失的 POI 签到。
MTRAJREC: map-constrained trajectory recovery via seq2seq multi-task learning(2021 SIGKDD)使用 seq2seq 多任务学习模型来修补缺失的轨迹点,同时将它们映射到道路网络。
第二类:
Predicting the Next Location: A Recurrent Model with Spatial and Temporal Contexts(2016 AAAI)试图对每一层的时间和空间背景进行建模。 具体来说,STRNN 针对不同的时间间隔和地理距离使用特定的超额矩阵来预测下一个 POI。
Deepmove: predicting human mobility with attentional recurrent networks(2018 WWW)提出了一种名为 DeepMove 的多模态嵌入递归神经网络,通过联合嵌入控制人体运动的多个因素来捕捉复杂的顺序转换。 DeepMove 还使用具有两种机制的历史注意力模型来捕获多级周期性,有效地利用周期性的性质来增强递归神经网络的移动性预测。 然而,现有工作的一个显着缺点是它们不能有效地减少轨迹数据补全中的数据噪声。
2.2 Trajectory-User Linking
大多TUL模型是有监督的,使用RNN的方法,通过大量标记的轨迹-用户对来学习用户和轨迹之间的投影函数。
TULER:Identifying Human Mobility via Trajectory Embeddings(2017 IJCAI)为 TUL 提出的第一个模型。 它使用 RNN 对轨迹序列进行建模,以捕获位置点之间的依赖关系。
DeepTUL:Trajectory-User Linking with Attentive Recurrent Network(2020 AAMAS)从用户的历史轨迹中学习用户移动的多周期性,并使用轨迹数据的空间和时间特征进行用户轨迹匹配。
TULSN:Siamese Network for Trajectory-user Linking(2020 IJCNN)提出了通过连接网络对轨迹数据进行建模,训练模型只需要少量的轨迹数据。
TULVAE:Trajectory-User Linking via Variational AutoEncoder(2018 IJCAI)是一种新颖的半监督变分自动编码器框架,它使用变分自动编码器来学习用户轨迹的层次语义特征,并结合未标记的数据来解决 TUL 的数据稀疏性问题。
然而,现有工作在很大程度上忽略了许多实际场景中的数据稀疏性问题。 现有工作通常需要大量带注释的轨迹-用户对,这是劳动密集型且成本高昂的,因此在许多应用中是不可行的。
3 Problem Definition
单元区域:

轨迹:

 稀疏轨迹:
稀疏轨迹:![]()
补全的完整轨迹:![]() 其中
其中![]()
并且一组稀疏轨迹集合包含了一小部分的标记数据或者已经连接用户的轨迹和一大部分的未标记数据或者未连接用户的轨迹。
解决TUL问题的办法是:将所有包含连接轨迹用户对和未连接轨迹用户对补全,然后学习一个映射函数,将所有未连接生成用户的轨迹连接。
4 Methodolody
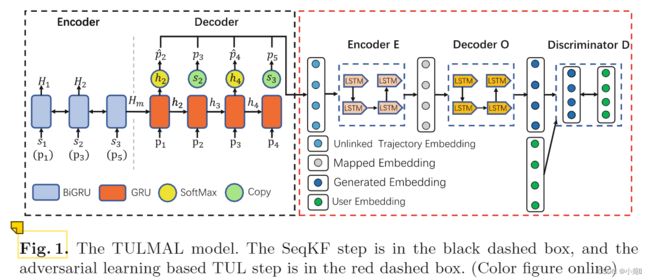
我们首先通过Seq2Seq获取坐标所在的单元区域。 然后使用卡尔曼滤波进行细粒度(确定预测单元区域的具体位置)标定,得到准确的坐标值。 在对抗性学习步骤中,我们的目标是学习一个投影函数,使生成的轨迹分布与用户分布之间的距离(Wasserstein距离)最小化。
4.1 SeqKF for Trajectory Completion
轨迹补全的 SeqKF 模型由编码器 + 带有卡尔曼滤波器的解码器组成。
Encoder学习轨迹的时空依赖性,而Decoder生成完整的轨迹。
我们不是直接预测缺失轨迹点的坐标值,而是预测它所在的单元区域。 这种方法比直接使用坐标值更容易建模。 然后我们通过Seq2Seq模型预测定位点所在的单元区域,以单元区域的中心作为定位点的预测坐标值。 最后,我们通过卡尔曼滤波器校正预测的坐标值以获得准确的预测。
编码器:采用的是BiGRU。长短期记忆 (LSTM) 网络,能够在不降低性能的情况下学习连续数据的长期依赖性,而 BiGRU 可以捕获前向和后向时间依赖性。与 LSTM 相比,GRU 内部少了一个”门控“,参数比LSTM 少,但是却也能够达到与 LSTM 相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的 GRU 。总的来说就是,参数少,性能相当。BiGRU将前向和后向的数据特征结合,然后输入编码器。

下面是输入的当前时刻轨迹位置,s1 s2 s3是稀疏轨迹的签到点,下面括号是一个完整轨迹的点。说明原本稀疏的轨迹点的签到点s1,应该对应完整轨迹位置的p1,s2对应p3,s3对应p5。说明p2和p4位置点缺失了。上面的H1H2 ...Hm是对应每个时刻的输出值。最后将双向结合的Hm传入解码器中。
解码器:GRU 解码器用于恢复稀疏轨迹![]() 。本文首先采用了一种replication operation,该方法广泛用于NLP中。我们直接从解码器的输出槽中复制这些点。通过下面一个公式:
。本文首先采用了一种replication operation,该方法广泛用于NLP中。我们直接从解码器的输出槽中复制这些点。通过下面一个公式:
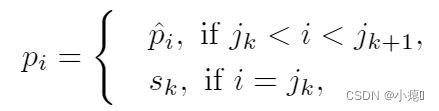
pi是解码器输出槽中的位置点,其中pi_hat代表缺失位置点的单元格(因为解码器预测的是单元格而不是缺失点),sk代表没有缺失的位置点。即,遍历轨迹的所有点,如果发现与完整轨迹的某一个点匹配不上,则判断此位置缺失签到点,标记为pi_hat。然后具体单元格位置坐标(x,y)再通过后面的卡尔曼滤波器补齐。然后之前(稀疏轨迹中)位置存在的点,直接复制到对应位置,比如下图绿色部分。在解码器的GRU中,融合了注意力机制,是为了更好地捕获一个全局的时空依赖性。当我们从解码器获得隐藏状态 hi 时,对于不在轨迹中的点,我们应用 softmax 函数以 p(c|hi) 的概率为条件生成缺失轨迹点的相应单元格:

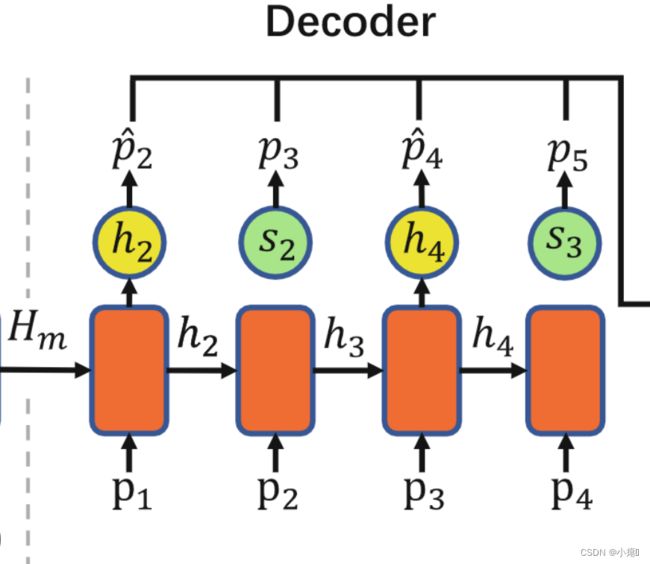
整个流程为 :Hm传入解码器中,解码器由带有注意力机制的GRU组成,是为了对编码器编码的特征向量进行更好地捕获全局信息,防止上下文依赖丢失。然后先对p1位置解码,得到下一个位置的预测h2。当从解码器获得隐藏状态 h2 时,对于不在轨迹中的点,应用 softmax 函数以 p(c|hi) 的概率为条件生成缺失轨迹点的相应单元格p2_hat。现在有了与缺失位置相对应的单元区域,接下来将卡尔曼滤波器 (KF) 与解码器结合起来以估计确切位置,这个稍后细致讲解。然后s2位置不缺少,则直接用之前的replication operation复制,然后和完整的轨迹点的单元格对应起来。然后处理完整条轨迹。
卡尔曼滤波器:KF本质上是线性和高斯噪声假设下的最优状态估计器。 它用于校准由 Seq2Seq 输出生成的粗粒度(得到具体的位置信息)预测。论文中有很长一段复杂的公式,可以看看这个卡尔曼滤波。

![]() 代表第i时间经过预测和校准后的细粒度预测值,
代表第i时间经过预测和校准后的细粒度预测值, 代表得到最终预测值的一个估计误差(矩阵),
代表得到最终预测值的一个估计误差(矩阵), 代表第i时间步的测量值(是解码器输出的预测单元格的中心坐标(x,y)作为的值),
代表第i时间步的测量值(是解码器输出的预测单元格的中心坐标(x,y)作为的值),![]() 代表预测该单元格中心坐标的测量误差(矩阵),
代表预测该单元格中心坐标的测量误差(矩阵),![]() 代表第i时间步的预测的真实单元区域。
代表第i时间步的预测的真实单元区域。
如图2所示,在每个时间步i,解码器单元将预测单元的中心坐标输入到KF分量中,KF通过预测和校正两个过程校准观测值,得到最终的预测![]() 。 然后将
。 然后将![]() 进一步分解为一个网格单元
进一步分解为一个网格单元 ![]() ,用作下一个解码器单元的输入。 通过这种组合,可以有效降低预测噪声。
,用作下一个解码器单元的输入。 通过这种组合,可以有效降低预测噪声。
Loss function:
1. 训练损失:
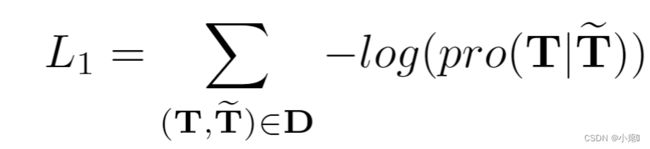
2.卡尔曼滤波器损失:
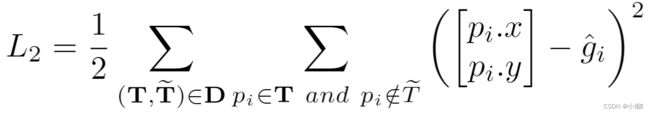
总损失为: ![]()
4.2 Adversarial Learning for Semi-supervised TUL
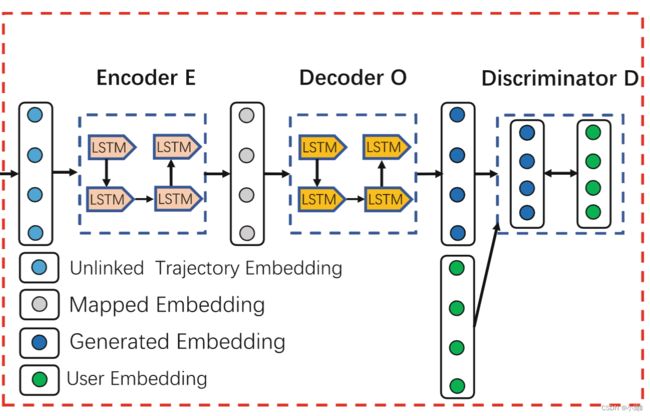
生成器:生成器由编码器E和解码器O构成。生成器旨在生成从原始特征空间到用户空间的轨迹表示,它由编码器和解码器组成。 编码器负责将输入轨迹映射到潜在空间,解码器负责将潜在空间中的潜在嵌入投影到目标用户空间。 我们使用 LSTM 作为编码器和解码器。 在生成器将轨迹映射到目标用户空间后,我们可以通过鉴别器D从用户中识别出真实实例。即生成器生成一个用户与轨迹的连接对,然后鉴别器找出真实的用户轨迹连接。Wasserstein 距离衡量了这用户数据与轨迹数据分布的差异性。通过最小化该距离完成用户与其生成的轨迹对应。
未连接的轨迹嵌入——>潜在空间的映射嵌入——>用户空间嵌入
生成器与鉴别器的目标函数:
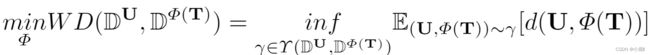
![]() 是用户数据的分布,D^Φ(T)是生成轨迹数据的分布。Wasserstein 距离衡量了这两个分布函数的差异性。在分布 DU 和 DΦ(T) 组合的所有可能联合概率分布的集合中(遍历所有分布),对于每一个可能的分布y中,可以采样到y~(U,Φ(T))这个样本,并且可以计算这两个样本之间的距离,然后计算样本对距离的期望值E。最后希望,在所有可能的联合分布中能够对这个期望值取到的下界,这个下界就是wassertein距离。WD的目标就是达到期望下界的理想联合分布 Y。总的来说,就是最小化所有可能联合分布下,两个样本相对距离之间的代价。但是这个公式实现较麻烦,遍历所有的联合分布是不可能的。于是有了简化公式:
是用户数据的分布,D^Φ(T)是生成轨迹数据的分布。Wasserstein 距离衡量了这两个分布函数的差异性。在分布 DU 和 DΦ(T) 组合的所有可能联合概率分布的集合中(遍历所有分布),对于每一个可能的分布y中,可以采样到y~(U,Φ(T))这个样本,并且可以计算这两个样本之间的距离,然后计算样本对距离的期望值E。最后希望,在所有可能的联合分布中能够对这个期望值取到的下界,这个下界就是wassertein距离。WD的目标就是达到期望下界的理想联合分布 Y。总的来说,就是最小化所有可能联合分布下,两个样本相对距离之间的代价。但是这个公式实现较麻烦,遍历所有的联合分布是不可能的。于是有了简化公式:
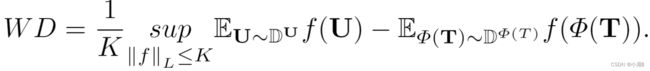
![]() 是用户数据的分布,D^Φ(T)是生成轨迹数据的分布。Wasserstein 距离衡量了这两个分布函数的差异性。K取最小值则代表利浦希兹系数,sup代表上确界。通过限制函数f的上界(函数的变化幅度,即梯度),使判别器函数 f 更平滑。Lipschitz continuous 的函数的梯度上界被限制,因此函数更平滑,在神经网络的优化过程中,参数变化也会更稳定,不容易出现梯度爆炸,因此 Lipschitz continuity 是一个很好的性质。从上式推导下来较复杂,需要添加格外项,可以参考:Lipschitz Continuity and Wasserstein Distance。为了找到理想的K-Lipschitz f 函数(无限逼近上界)。将鉴别器设置为一个多层的神经网络,因为神经网络有强大的收敛能力。因此这个神经网络可以看作是区分目标样本和生成样本的鉴别器D。
是用户数据的分布,D^Φ(T)是生成轨迹数据的分布。Wasserstein 距离衡量了这两个分布函数的差异性。K取最小值则代表利浦希兹系数,sup代表上确界。通过限制函数f的上界(函数的变化幅度,即梯度),使判别器函数 f 更平滑。Lipschitz continuous 的函数的梯度上界被限制,因此函数更平滑,在神经网络的优化过程中,参数变化也会更稳定,不容易出现梯度爆炸,因此 Lipschitz continuity 是一个很好的性质。从上式推导下来较复杂,需要添加格外项,可以参考:Lipschitz Continuity and Wasserstein Distance。为了找到理想的K-Lipschitz f 函数(无限逼近上界)。将鉴别器设置为一个多层的神经网络,因为神经网络有强大的收敛能力。因此这个神经网络可以看作是区分目标样本和生成样本的鉴别器D。
鉴别器损失函数:

为了保证K-Lipschitz约束,需要进行weight clipping操作。使权重α始终保持在[-c,c]以使式子满足K-李普希兹约束。
生成器损失函数:

随着生成器 Φ 的损失逐渐减小,判别器 D 的损失,即 WD,也随之减小,因此属于同一用户的轨迹在潜在空间中被分组在一起。
同时,我们还合并了少量标记数据和轨迹用户连接对:
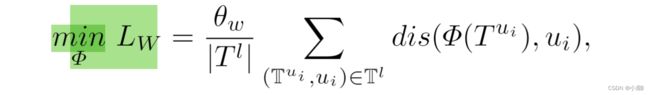
对抗学习总损失:

整个模型总损失:

5 Experiment
5.1 Dataset and Experiment Setup
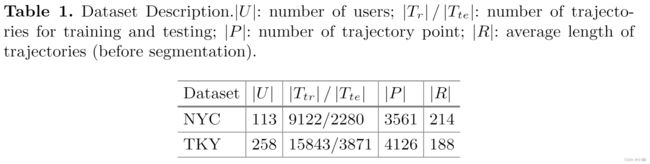
Dateset:我们的实验使用了从 Foursquare 收集的两个数据集。 NYC 数据集记录了纽约市大约 10 个月的签到情况。 每次签到都包括其时间戳、GPS 坐标和语义信息(由细粒度的场地类别表示)。 TKY 数据集包含大约十个月的东京签到记录。
我们随机选择 |U | 用户及其从两个数据集中生成的轨迹进行评估。 对于每个轨迹,我们随机采样 r% 个点并移除其他点以模拟稀疏轨迹。 在我们的实验中,我们分别为每个轨迹保留 50% 和 70% 的点。 整个轨迹的 10% 及其用户用作监督的注释。
我猜想本文使用了同一数据集下,人工模拟的稀疏轨迹和完整轨迹。将完整轨迹作为label,对稀疏轨迹进行半监督训练。但是在实际应用中,稀疏轨迹对应的完整轨迹并不存在,感觉TUL应用在实际生活中还有距离。
5.2 Experimental Results
上图是在采样率70%下的。seqKF代表卡尔曼滤波器的轨迹补全。TULMAL是完整的对抗多任务学习。
上图是50%采样率。可以看见两个表中,NYC的效果比TKY好,这主要是因为 NYC 的用户比 TKY 少,导致 NYC 的轨迹比 TKY 更密集。 更密集的轨迹提供更多信息,因此模型可以获得更好的性能。
5.3 Effectiveness of Trajectory Completion

RMSE 是缺失轨迹点坐标的实际值和预测值之间的均方根误差,越小误差越小。
NDTW 是两条轨迹之间(同一完整轨迹和稀疏轨迹)的归一化动态时间规整距离,由动态时间规整距离 (DTW) 修改而来,越小代表两个轨迹越相似,侧面反映轨迹补全精度。
EDR 是真实序列上的编辑距离。 即,一个稀疏轨迹通过一些列操作(插入,删除,替换)成为一个完整轨迹所有的操作数。
可以观察到,seqKF效果是最好的。进一步验证了SeqKF通过将Seq2Seq与卡尔曼滤波器相结合,可以有效降低噪声的影响,提高模型的鲁棒性。 两个基线的性能迅速下降,因为较小的稀疏率导致更稀疏的轨迹。
5.4 Parameter Sensitivity Study
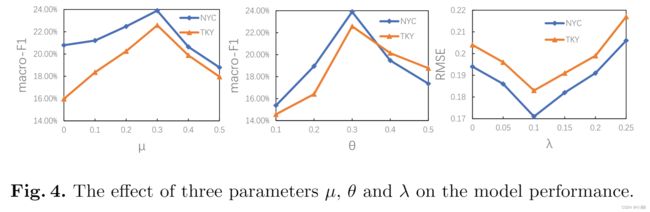
我们最终研究了 TULMAL 对三个参数的性能敏感性:最终损失函数的权重 μ、TUL 中的注释指导权重 θ 和 SeqKF 中损失函数的权重 λ。 我们让 μ 从 0 增加到 0.5,θ 从 0.1 增加到 0.5,λ 从 0 增加到 0.25。 在我们的实验中,两个数据集的采样率都设置为 70%。 从图4可以看出,随着μ的不断增大,模型的性能先升高后降低,说明适当的SeqKF损失可以提高TUL的性能,但过大的SeqKF损失会压倒对抗性损失, 从而损害性能。 注释指导权重 θ 产生了类似的结果。 模型的性能随着θ的增大先增大后减小。 θ =0.3 是两个数据集的合适设置。 随着λ的增大,RMSE先减小后增大。 当λ为0.1时,SeqKF的性能最好,证明KF在提高轨迹补全性能方面是有效的。
参考资料:
Lipschitz Continuity and Wasserstein Distance
Optimal Transport
Wasserstein Distance
Weight Clipping