Flink状态编程学习笔记
Flink状态编程学习笔记
简介
状态编程为Flink处理机制的核心,状态用来保存信息,辅助计算,以及方便于故障恢复。
内容
一、有状态和无状态的算子
有状态:计算时需要依赖其他数据,例如需要先有下单状态,才能有支付状态(sum…)
无状态:计算时不需要依赖其他数据,单独自身数据就足矣(Map,Filter…)
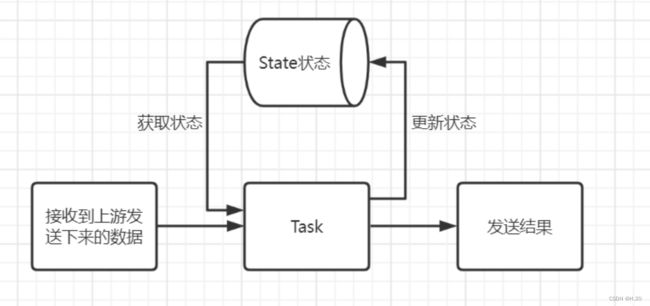
二、状态管理
传统状态管理:状态保存在数据库中,造成对数据库频繁访问耗费性能。
Flink状态管理:将状态保存在内存中,并通过分布式扩展保证高吞吐量,同时需要给状态做个持久化保存,以便于在发生故障后恢复到正常状态。
(FLink将状态管理中很多核心功能封装起来了,我们直接调用API即可,从而实现将状态管理这一麻烦事简化)
三、状态发分类
(1)托管状态(Managed State)
所有状态统一由Flink管理,全部都有FLink接口实现。---->推荐
(2)原始状态(Raw State)
自己开辟一块内存,自己管理状态的一系列功能。
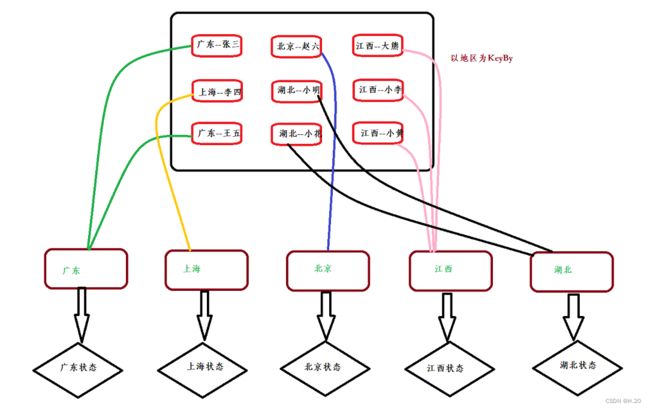
四、算子状态和按键分区状态
因一个算子任务在多个并行度的状态下占据不同的任务槽,他们之间是物理隔绝的,状态无法共享,所以任务进行的计算只能针对当前key有效。
1、算子状态(Operator State):限定于当前算子,使用时需要实现CheckpointedFunction接口
2、按键分区状态(Keyed State):只能定义在按键分区流中,只能keyby后才能使用,类似于MySQL的group by
3、按键分区状态具体使用:
概念:类似于MySQL group by,按键为作业范围进行隔绝作业
4、支持的结构类型
(1)值状态(value state):状态只保存一个值
public interface ValueState<T> extends State {
//获取当前状态的值
T value() throws IOException;
//更新状态
void update(T value) throws IOException;
}
//具体使用时为了清楚是哪个状态,需要创建个状态描述器
//传入状态的名称和类型
public ValueStateDescriptor(String name,Class<T> typeClass) {
super(name,typeClass,null)
}
(2)列表状态:与值状态类似,列表状态描述器称为ListStateDescriptor
(3)映射状态:把一些键值对作为整体保存起来,对应的MapState
(4)规约状态(ReducingState):类似于值状态,不过他是将传进来的值进行规约,将规约聚合后的数据作为状态保存下来,规约的逻辑定义是在规约状态描述器中通过传入一个规约函数ReduceFunction(状态类型与输入的数据类型要一致)
public ReducingStateDescriptor(String name,ReduceFunction<T> reduceFunction,Class<T> typeClass){
//第二个参数为定义规约逻辑的ReduceFunction
}
(5)聚合状态:与规约状态类似,通过聚合函数(AggregateFunction),调用这个接口也和规约状态一致,使用add方法。(状态类型与输入的数据类型不需要一致)
五、状态的使用

1、代码中使用状态整体代码:
package com.mtaite.travel.Test;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
/**
* @version 1.0
* @Author Hzx
* @Created on 2022/5/24 13:49
*/
public class MyFlatMapFunction extends RichFlatMapFunction<Long,String> {
//声明状态
private transient ValueState<Long> state;
@Override
public void open(Configuration parameters) throws Exception {
//在open生命周期方法中获取状态
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<Long>(
"my state", //状态名
Types.LONG //状态类型
);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Long aLong, Collector<String> out) throws Exception {
//访问状态
Long currentState = state.value();
currentState += 1; //状态值加1
//更新状态
state.update(currentState);
if (currentState > 5) {
out.collect("state:"+currentState);
//清空状态
state.clear();
}
}
}
2、部分算子等解释:
(1)SingleOutputStreamOperator:是DataStream的tranformation,且输出指定类型
(2)assignTimestampAndWaterMarks:指定时间戳和水印
3、注册定时器代码案例:
public static class Timer extends KeyedProcessFunction<String,BTrack,String>{
//定义两个状态,保存当前x值以及定时器时间戳
ValueState<Long> countState;
ValueState<Long> TimerState;
@Override
public void open(Configuration parameters) throws Exception {
countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count",Long.class));
TimerState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("Timer",Long.class));
}
@Override
public void processElement(BTrack value,COntext ctx,Collector<String> out) {
//更新count值
Long count = countState.value();
if(count == null){
countState.update(1L);
} else {
countState.update(count+1);
}
}
}
4、双流join
对于双流处理,flink提供的connect能灵活处理
stream1.keyBy(r -> r.f0).connect(stream2.keyBy(r -> r.f0))
.process(new CoProcessFunction<Tuple2<Long,String>,Tuple2<Long,String>,String>(){
private ListState<Tuple2<Long,String>> stream1ListState;
private ListState<Tuple2<Long,String>> stream2ListState;
//open方法内getRuntimeContext获取状态
//处理逻辑
}
5、状态生存时间
状态一般会随着时间的推移而逐渐增长,为了节约资源,需要设置一个状态生存时间,当某个状态时长达到预设时间则会被清理掉节约资源。生效时间=当前时间+生存时间(TTL)
StateTtlConfig ttlConfig = StateTtlConfig
//状态TTL的构造器方法,里面传入一个状态生存时间
.newBuilder(Time.seconds(10))
//更新类型(此类型表示只有在创建和更改状态时更新生效时间)
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//设置状态可见性,这里设置的是表示不返回过期状态
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<String>(
"my state",
String.class
);
stateDescriptor.enableTimeToLive(ttlConfig);
六、算子状态中设定CheckPointedFunction接口(检查点)
public interface CheckPointedFuntion {
//保存状态快照到检查点时调用这个方法
void snapshotState(FunctionSnapshotContext context) throws Exception
//初始化状态调用这个方法,也会在恢复状态时调用
void initializeState(FunctioninitializationContext context) throw Exception;
}
七、状态后端
(1)哈希表状态后端(HashMapStateBackend)
把状态存放在内存上,比较常用的方法
(2)内嵌RocksDB状态后端(EmbeddedRocksDBStateBackend)
状态持久化到磁盘中
如果在IDEA中使用内嵌状态后端,需要提供如下依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>1.13.0</version>
</dependency>