Netty导学之NIO,Channel、Buffer、Selector详解
介绍
NIO可翻译为Non-Blocking IO非阻塞IO,也可以称其为New IO 因为其是JDK1.4新出现的。
java中的流要么是输入流,要么是输出流,不可能都是,它面向流编程。而在NIO中,有三个组件,它是面向块或缓冲区编程的,基于通道,NIO读写文件更加高效,javaAPI 提供了两套NIO,一套用于标准输入输出,一套基于网络NIO。
阻塞和非阻塞的区别
我们曾经用到的InputSteam,OutputSteam,Reader,Writer等相关的API进行IO的操作都是阻塞的。阻塞模式下(包括文件IO和网络IO)
- Accept是阻塞的,只有新连接来了,Accept才会返回,主线程才能继
- Read是阻塞的,只有请求消息来了,Read才能返回,子线程才能继续处理
- Write是阻塞的,只有客户端把消息收了,Write才能返回,子线程才能继续读取下一个请求
可见阻塞模式下执行阻塞操作,会一直等在那,极大的浪费了资源。
IO流是每次处理一个或多个字节,效率很慢(字符流处理的也是字节,只是对字节进行编码和解码处理)。
NIO流是以数据块为单位来处理,缓冲区就是用于读写的数据块。缓冲区的IO操作是由底层操作系统实现的,效率很快。
我们的程序不能从channel中直接读取数据或写数据,必须通过buffer,一个buffer不仅可以读,还可以往回写
三大组件介绍
NIO支持面向缓冲区的、基于通道的IO操作并以更加高效的方式进行文件的读写操作,其核心API为Channel(通道),Buffer(缓冲区), Selector(选择器)。Channel负责传输,Buffer负责存储 。
Channel&Buffer
channel是读写数据的双向通道,表示打开IO设备的连接 ,类似io中的流。
buffer是channel的一个内存缓冲区,用来暂存从channel中读入的数据,反过来如果你想写数据则你也需要把数据先保存在buffer里,然后再写出。必须这样组合使用!

channel和传统stream的区别:
- channel是双向的,stream大多是单向的
- channel面向缓冲区(块),stream面向流
- 读写是基于缓冲区的,不能直接向channel写入或读取
- channel可以异步读写,stream只能阻塞读写
java.nio.channels.Channel包下提供了:
- FileChannel:处理本地文件
- SocketChannel:TCP网络客户端
- ServerSocketChannel:TCP网络服务端
- DatagramChannel:UDP发送端和接收端
java.nio.channels包提供了如下常用buffer:
- ByteBuffer(最常用,它是一个抽象类,实现类如下)
- MappedByteBuffer
- HeapByteBuffer
- DirectByteBuffer
- DoubleBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
Selector
Selector是Java NIO中用于管理一个或多个Channel的组件,控制决定对哪些Channel进行读写;通过使用Selector让一个单线程可以管理多个Channel甚至多个网络连接。
当Selector管理的channel发生对应事件时就会通知Selector并将该事件存储到它内部的一个列表里(SelectionKey).
先来看看Selector出现的原因:
1.早期服务器是多线程设计的,每一个客户端socket来了我服务器就给你启动一个新的Thread跟你通信,每个线程专管一个socket。弊端显而易见,客户端太多了服务器就扛不住了,因为每个线程需要一定的虚拟机栈空间,太多了占用内存极高,而且线程太多了,你服务器的核心数是有限的,也需要上下文切换来处理数据。
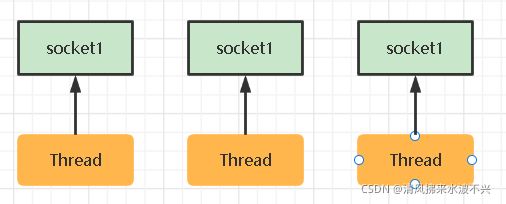
缺点:内存占用高,线程上下文切换成本高,只适合连接数少的场景
2.这时你可能会想到使用线程池来改善线程太多的缺点,这样可以限制线程的个数,使得一个线程可以处理多个客户端的连接。但是一个线程只能同时处理一个socket,且socket工作在一个阻塞的模式下,如果一个socket连接阻塞了,那你这个线程也要一直傻傻等着他,处理不了其他的线程,只有等此socket断开连接了才能去执行别的线程。
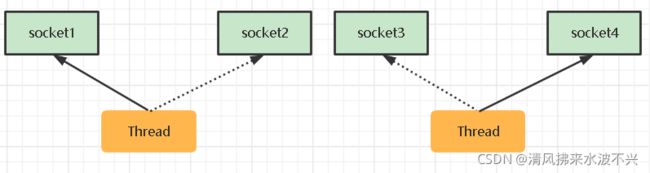
线程池版设计的缺点:阻塞模式下,线程仅能处理一个Socket连接,造成线程利用率不高,仅仅适合短连接的场景。
3.Selector版设计
selector的作用就是配合一个线程来管理多个channel,获取这些channel上发生的事件,这些channel工作在非阻塞模式下,不会让线程吊死在一个channel 上。适合连接数特别多,但流量低的场景(low traffic)。
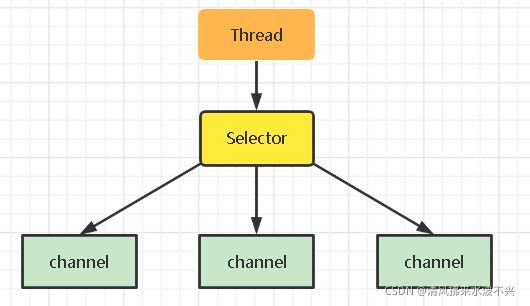
图中Selector能检测到所有channel发生的事件,就像是一个监视器,监视多个channel的一举一动,channel有什么类型的请求都会被Selector监视到,Selector再告诉Thread可以处理该事件了。
调用selector的 select()会阻塞直到channel 发生了读写就绪事件,这些事件发生,select方法就会返回这些事件交给thread来处理。
这样不仅降低了线程的数目,还提高了利用率。
三大组件的使用
本节主要讲解各组件API层面的使用
ByteBuffer
配合FileChannel使用
- 传统的输入输出流或RandomAccessFile对象都有个getChannel方法获取到对应的FileChannel
- 通过ByteBuffer类的静态方法allocate(int capacity)或allocateDirect(int capacity)准备缓冲区,参数是需要划分的大小
- 从FileChannel(即hello.txt文件)读取数据并写入buffer,然后从buffer里读取数据
其中的方法请阅读注释,此段代码只是一个开胃菜,带你了解基本的使用。
//FileChannel
//1. 输入输出流 2.RandomAccessFile
//注意需要关闭流close() 这里自动关闭了
try (FileChannel channel = new FileInputStream("hello.txt").getChannel()) {
//准备缓冲区 分配10字节的缓冲区
ByteBuffer buffer=ByteBuffer.allocate(10);
//从channel读取数据,并写入buffer,如果是-1,就是末尾了
while (channel.read(buffer)!=-1) {
buffer.flip();//buffer切换至读模式
//判断buffer中是否还有剩余未读数据
while (buffer.hasRemaining()){
//buffer.get()读一个字节,指针后移
System.out.print((char)buffer.get()); //每次打印buffer里面读到的数据
}
//必须切换为写模式,才能写数据到buffer里
buffer.clear();//或compact方法
}
} catch (IOException e) {
}ByteBuffer正确姿势:
1.向buffer写入数据,其实就是通过channel读取某个文件或网络的数据再写入buffer,请不要混淆,调用channel.read(buffer)方法
2.buffer初始的状态为写模式,只能往里面写数据,如果我们需要读里面的数据则调用flip()方法,切换到读模式,反之又想往里写数据了则必须切换到写模式,调用clear()方法或者compact()方法切换到写模式,这两个方法的作用不同,等时机成熟了再讲他们的不同点。
3.重复1~2两个步骤
结构:
先看看ByteBuffer类结构和一些我标记的重要属性:
//ByteBuffer是Buffer的子类,Buffer 中有以下几个很重要的属性
public abstract class Buffer {
//记住这句源代码里的话
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
}public abstract class ByteBuffer extends Buffer implements Comparable
{
final byte[] hb; //实际是一个byte数组
final int offset;
boolean isReadOnly;
//实际创建的子实现类HeapByteBuffer对象
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
//创建直接内存DirectByteBuffer对象
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
} - position:用于标记当前的位置,读和写的位置是不一样滴
- limit:读和写的限制,读写也是不同的
- capacity:buffer的容量,永远不会变化
一开始分配10字节如下图,处于写模式,每写一个position向前加一个位置。
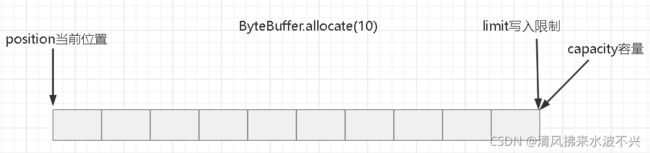
写模式下,limit等于写的限制,position不能大于limit

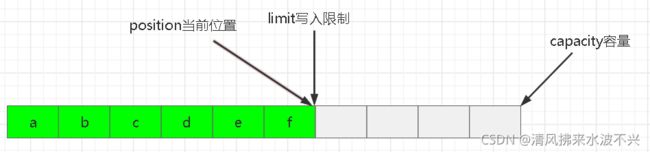
flip动作发生后,position切换为读取模式,position重新指向0,从头读,limit切换为读取限制。只能读到limit那里

读取6个字节后,状态
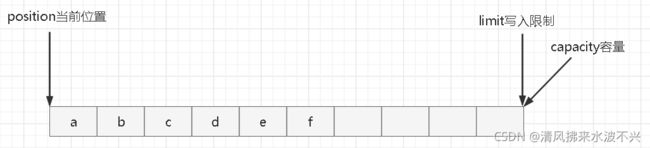
clear动作发生后,状态如下,position回到了起点,limit也到了最后,相当于回到初始状态(写模式)
compact方法,是把未读完的部分向前压缩,然后切换至写模式

另外mark()做一个标记position的位置,reset()重新回到mark的位置。跟插眼 传送一个道理
写数据:
- 调用channel的read方法
- 调用自己的put方法,该方法有四个重载方法,分别是写一个字节、在指定位置写一个字节、写一个byte数组、写一个ByteBuffer
读数据:
- 调用channel的write方法
- 调用自己的get方法
get方法会让position读指针向后走,如果想重复读取数据
- 可以调用rewind方法将position置为0
- 或调用get(int index)方法,该不会移动指针
集中写入:用buffer数组写入文件
分配空间:
- HeapByteBuffer allocate(int capacity)
- DirectByteBuffer allocateDirect(int capacity)
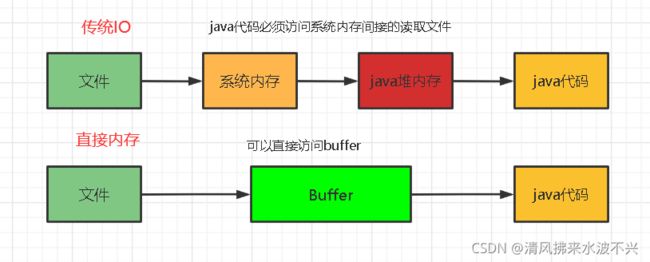
HeapByteBuffer:分配的堆空间,效率较低,每次传输数据时都会拷贝到直接内存(内核缓冲区),所以多了一次拷贝的操作。
DirectByteBuffer :直接内存,分配的内存是内核级别的空间(不在jvm里),jvm通过映射地址访问到这块空间,效率高,不受垃圾回收的影响。
数据转换的方法:
ByteBuffer到字符串的转换:
//需切换到读模式
String s=StandardCharsets.UTF_8.decode(buffer)字符串到ByteBuffer的转换:
buffer.put("wo".getBytes());
//这两种会自动转为读模式
ByteBuffer wrap = ByteBuffer.wrap("wo".getBytes());
//可以指定对应的编码
ByteBuffer buff = StandardCharsets.UTF_8.encode("wo");分散读取Scattering Reads
指的是从Channel中读取时将读取的数据写入多个buffer中。因此,Channel将从Channel中读取的数据“分散(scatter)”到多个Buffer中。
ByteBuffer buffer1 = ByteBuffer.allocate(2);
ByteBuffer buffer2 = ByteBuffer.allocate(3);
ByteBuffer buffer3 = ByteBuffer.allocate(4);
ByteBuffer[] bufferArray = new ByteBuffer[]{buffer1, buffer2, buffer3};
//文件内容为:hehasdream
try (FileChannel channel = new RandomAccessFile("hello.txt", "rw").getChannel()) {
channel.read(bufferArray);
buffer1.flip();buffer2.flip();buffer3.flip();
System.out.println(StandardCharsets.UTF_8.decode(buffer1));//he
System.out.println(StandardCharsets.UTF_8.decode(buffer2));//has
System.out.println(StandardCharsets.UTF_8.decode(buffer3));//drea
} catch (Exception e) {
e.printStackTrace();
}集中写入Gathering Writes
指在写操作时将多个buffer的数据写入同一个Channel,因此,Channel 将多个Buffer中的数据“聚集(gather)”后发送到Channel。
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("she");
ByteBuffer buffer2 = StandardCharsets.UTF_8.encode("has");
ByteBuffer buffer3 = StandardCharsets.UTF_8.encode("dream");
ByteBuffer[] bufferArray = new ByteBuffer[]{buffer1, buffer2, buffer3};
try (FileChannel channel = new RandomAccessFile("hello.txt", "rw").getChannel()) {
//集中写入,内容为shehasdream
channel.write(bufferArray);
} catch (Exception e) {
e.printStackTrace();
}用处:经常用于需要将传输的数据分开处理的场合,例如传输一个由消息头和消息体组成的消息,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
FileChannel
该文件Channel只做了解即可,重点是网络Channel
FileChannel只能工作在阻塞模式下。 不能和Seloctor配合使用
获取:
不能直接打开FileChannel,必须通过FilelnputStream、FileOutputStream或者RandomAccessFile来获取FileChannel,它们都有getChannel方法。
- 通过FilelnputStream获取的只能读
- FileOutputStream获取的只能写
- RandomAccessFile获取的根据对应的模式决定
读取:
会从channel读取数据填充ByteBuffer,返回值表示读到了多少字节,-1表示到达了文件的末尾
int len=channel.read(buffer);写入:
ByteBuffer buffer = ...;
buffer.put(....);//存入数据
buffer.flip(); //切换模式
//因为channel写入能力有上限,不能保证一次把所有的数据都写到channel里,所以需要判断
while(buffer.hasRemaining()){
channel.write(buffer);
}关闭:
channel必须关闭,不过调用了FilelnputStream、FileOutputStream或者RandomAccessFile 的close方法会间接地调用channel 的close方法
强制写入:
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用force(true)方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
文件拷贝:此方法比传统的IO流更快,代码更简洁,底层引用了零拷贝优化。
零拷贝( zero-copy )技术可以有效地改善数据传输的性能,在内核驱动程序(比如网络堆栈或者磁盘存储驱动程序)处理 I/O 数据的时候,零拷贝技术可以在某种程度上减少甚至完全避免不必要 CPU 数据拷贝操作。
计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
参考:8张图了解零拷贝_Sola Komorebi的博客-CSDN博客
try (
FileChannel from = new FileInputStream("hello.txt").getChannel();
FileChannel to = new FileOutputStream("hello3.txt").getChannel();
) {
//效率高,底层利用操作系统的零拷贝
//size(),FileChannel独有的方法,获取文件大小
from.transferTo(0, from.size(), to);
} catch (IOException e) {
e.printStackTrace();
}transferTo一次最多传输2G的数据,如果文件大于2G,需要更换里面的代码,使用循环。
//获取要拷贝的文件大小
long size=from.size();
//rest表示还剩多少数据没传
for(long rest=size;rest>0;){
//每次从size-left开始传,返回值为实际传输的大小,再用rest减去它,得到还剩多少没传……
rest-=from.transferTo(size-rest, rest, to);
}