Flink1.12 DataStream(java)常用算子示例
文章目录
- 前言
- Map算子
- FlatMap算子
- Filter算子
- KeyBy算子
- Max、Min、Sum、Reduce算子
-
- max
- min
- sum
- reduce
- Union算子
- Connect算子
-
- CoProcessFunction、CoFlatMap、CoMap
- Process 算子
- Side Outputs算子(原 split、select)
- Window算子
- CoGroup算子
- 算子链式调用
- 总结:
前言
DataStream 算子我们在开发中通常会用到例如:Map、FlatMap、Filter、keyBy、max、min、sum、reduce、Aggregation、WIndow、WindowAll、WindowApply、Join、Connect等等…
官网常用算子示意图如下:
戳我进官网
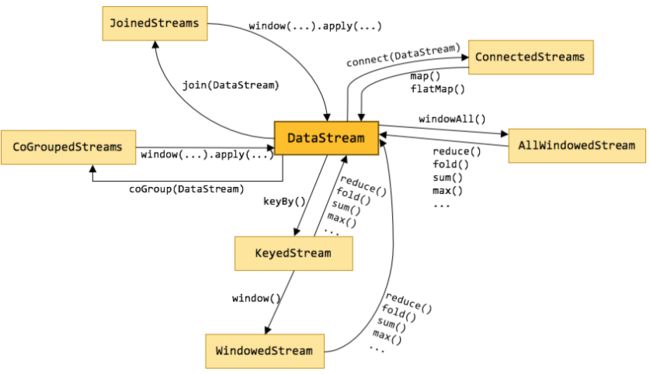
那么"Flink算子"是什么呢?
Flink算子,其实就是”数据转换算子“,对数据进行处理的方法或者程序封装就是算子
操作示例图:

说明:如果您对Java8提供的Stream操作比较熟悉的话,那么本文中flink某些算子的作用,您了解起来会事半功倍!
首先,介绍我们的Map算子
Map算子
Map算子,就是映射算子,将一个数据映射为另一个数据,与Java8 stream 流式操作中的map一致
Ex :java示例
List<String> stringList = Arrays.asList("a", "b", "c");
List<String> mapChangeList = stringList.stream().map(String::toUpperCase).collect(Collectors.toList());
// [A, B, C]
System.out.println(mapChangeList);
上方呢,便是使用Java8 Stream中的Map()进行数据映射处理,将每一个元素改变为大写并输出,我们flink程序也提供了这样的功能(算子),我们来操作一下吧?
Ex :flink示例
public static void main(String[] args) throws Exception {
List<String> stringList = Arrays.asList("a", "b", "c");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<String> stream = env.fromCollection(stringList);
// 使用map算子
SingleOutputStreamOperator<String> source = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase()+ "aa";
}
});
// Aaa Baa Caa
source.print();
env.execute();
}
FlatMap算子
FlatMap算子,可以将数据进行摊平化处理 例如 原本每一个元素都是集合或者数数组,我们使用FlatMap后,可以将(集合,数组)进行再次拆解取出其中的数据,再新组合为集合,与Java8 stream 流式操作中的Flatmap功能一致
Ex :java示例
List<String> str1 = Arrays.asList("a", "b", "c");
List<String> str2 = Arrays.asList("关羽","张飞","马超","黄忠","赵云");
List<List<String>> originalData = new ArrayList<>();
originalData.add(str1);
originalData.add(str2);
List<String> flatMapChangeList = originalData.stream().flatMap(Collection::stream).collect(Collectors.toList());
// [a, b, c, 关羽, 张飞, 马超, 黄忠, 赵云]
System.out.println(flatMapChangeList);
Ex :flink示例
public static void main(String[] args) throws Exception {
List<String> str1 = Arrays.asList("a", "b", "c");
List<String> str2 = Arrays.asList("关羽","张飞","马超","黄忠","赵云");
List<List<String>> originalData = new ArrayList<>();
originalData.add(str1);
originalData.add(str2);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<List<String>> stream = env.fromCollection(originalData);
// 使用flatMap算子
SingleOutputStreamOperator<String> source = stream.flatMap(new FlatMapFunction<List<String>, String>() {
@Override
public void flatMap(List<String> value, Collector<String> out) throws Exception {
for (String s : value) {
out.collect(s);
}
}
});
// a b c 关羽 张飞 马超 黄忠 赵云
source.print();
env.execute();
}
Filter算子
Filter为筛选(过滤)算子,可以根据条件过滤数据源中数据,例如现有数据源 1,2,3,4,5 现在要过滤大于3的数据,过滤后,数据源中仅有 4 5 数据了,与Java8 stream 流式操作中的filter功能一致
Ex :java示例
List<Integer> str1 = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
List<Integer> dataList = str1.stream().filter(e -> e > 3).collect(Collectors.toList());
// [4, 5, 6, 7, 8]
System.out.println(dataList);
上文中我们设置了过来条件为元素值大于3
Ex :flink示例
public static void main(String[] args) throws Exception {
List<Integer> str1 = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<Integer> stream = env.fromCollection(str1);
// 使用filter算子
SingleOutputStreamOperator<Integer> source = stream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value > 3;
}
});
// 4 5 6 7 8
source.print();
env.execute();
}
KeyBy算子
分组算子,根据数据源中元素某一特性进行分组,与Java8 stream 流式操作中的groupBy功能一致
Ex :java示例
List<Integer> str1 = Arrays.asList(22,33,44,55,22,11,33,55);
Map<Integer, List<Integer>> collect = str1.stream().collect(Collectors.groupingBy(Function.identity()));
// {33=[33, 33], 22=[22, 22], 55=[55, 55], 11=[11], 44=[44]}
System.out.println(collect);
Ex :flink示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("麻子", 35));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<User> stream = env.fromCollection(users);
// 使用filter算子
KeyedStream<User, String> keyedStream = stream.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.name;
}
});
KeyBy算子通常在拿到数据源后,执行分组在根据分组后数据进行计算才有意义,通常不会使用flink对流分组直接输出
例如:定位数据中根据车牌号分组,我们则可以对每个车进行自己的逻辑计算…
Max、Min、Sum、Reduce算子
Flink中这些算子通常需要对流数据进行分组(KeyBy)后才可进行处理(使用分组流)
计算算子示例公共对象:
@NoArgsConstructor
@AllArgsConstructor
@Data
@Builder
public static class User {
private String name;
private Integer age;
}
max
Ex :java示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
User maxAgeUser = users.stream().max(Comparator.comparingDouble(User::getAge)).orElse(null);
// SumOperator.User(name=麻子, age=35)
System.out.println(maxAgeUser);
Ex :flink示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("麻子", 35));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<User> stream = env.fromCollection(users);
// 使用KeyBy算子
KeyedStream<User, String> keyedStream = stream.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.name;
}
});
// 使用max算子
SingleOutputStreamOperator<User> age = keyedStream.max("age");
age.print("max:");
env.execute();
输出了分组后(KeyBy) 每一个分组组中年龄最大的数据
max:> SumOperator.User(name=张三, age=18)
max:> SumOperator.User(name=麻子, age=35)
max:> SumOperator.User(name=李四, age=29)
min
Ex :java示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
User maxAgeUser = users.stream().min(Comparator.comparingDouble(User::getAge)).orElse(null);
// MinOperator.User(name=张三, age=12)
System.out.println(maxAgeUser);
Ex :flink示例
public static void main(String[] args) throws Exception {
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<User> stream = env.fromCollection(users);
// 使用KeyBy算子
KeyedStream<User, String> keyedStream = stream.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.name;
}
});
使用min算子
SingleOutputStreamOperator<User> age = keyedStream.min("age");
age.print("min:");
env.execute();
}
min:> MinOperator.User(name=张三, age=12)
min:> MinOperator.User(name=麻子, age=35)
min:> MinOperator.User(name=李四, age=22)
sum
Ex :java示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
Map<String, List<User>> collect = users.stream().collect(Collectors.groupingBy(User::getName));
collect.forEach((k,v)->{
User sumAgeUser = v.parallelStream()
.reduce((user, user2) -> new User(user.name, user.age + user2.age))
.orElse(null);
System.out.println(sumAgeUser);
});
SumOperator.User(name=李四, age=51)
SumOperator.User(name=张三, age=30)
SumOperator.User(name=麻子, age=35)
Ex :flink示例
public static void main(String[] args) throws Exception {
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<User> stream = env.fromCollection(users);
// 使用KeyBy算子
KeyedStream<User, String> keyedStream = stream.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.name;
}
});
SingleOutputStreamOperator<User> age = keyedStream.max("age");
age.print("sum:");
env.execute();
}
sum:> SumOperator.User(name=张三, age=18)
sum:> SumOperator.User(name=麻子, age=35)
sum:> SumOperator.User(name=李四, age=29)
reduce
reduce 有归约的意思,也可以将数据进行求和以及其余汇总处理,我这里,就还是根据Name分组 然后对 age进行求和
Ex :java示例
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
Map<String, List<User>> collect = users.stream().collect(Collectors.groupingBy(User::getName));
collect.forEach((k,v)->{
User sumAgeUser = v.parallelStream()
.reduce((user, user2) -> new User(user.name, user.age + user2.age))
.orElse(null);
System.out.println(sumAgeUser);
});
Ex :flink示例
public static void main(String[] args) throws Exception {
List<User> users = Arrays.asList(new User("张三", 12), new User("张三", 18),
new User("李四", 22), new User("李四", 29), new User("麻子", 35));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1 (1个线程执行,以便观察)
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 加载数据源
DataStreamSource<User> stream = env.fromCollection(users);
// 使用KeyBy算子
KeyedStream<User, String> keyedStream = stream.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.name;
}
});
// 使用reduce算子
SingleOutputStreamOperator<User> source = keyedStream.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User value1, User value2) throws Exception {
return new User(value1.name, value1.age + value2.age);
}
});
source.print("reduce:");
env.execute();
}
reduce:> ReduceOperator.User(name=张三, age=30)
reduce:> ReduceOperator.User(name=麻子, age=35)
reduce:> ReduceOperator.User(name=李四, age=51)
Union算子
union :联合算子, 使用此算子,可对多个数据源进行合并操作(数据源数据必须类型必须相同),其可合并多个,合并后可直接对数据进行处理 (计算或输出)

Ex :flink示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStreamSource<String> source = env.fromElements("zs", "li", "we");
DataStreamSource<String> source2 = env.fromElements("zs2", "li2", "we2");
DataStreamSource<String> source3 = env.fromElements("zs3", "li3", "we3");
//此操作将 source 、source2 、source3 三个数据源的数据联合起来了
DataStream<String> union = source.union(source2, source3);
SingleOutputStreamOperator<String> streamOperator = union.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
});
streamOperator.print("union").setParallelism(1);
env.execute();
}
Connect算子
connect与union算子一样,都可以进行数据源合并处理,但与union不同的是,connect 可以合并不同类型的数据源,但最多只能合并两个数据流,且合并后无法直接操作(计算 输出),需要对连接流进行数据处理(选择最终合并后的数据类型,不符合最终数据类型的转换)
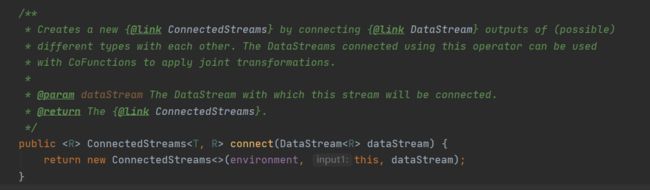
例如:现有两个数据源 一个为String 类型,一个为Integer类型,现在使用connect后,必须对两个数据源中数据分别进行处理,使其最终变为一个类型的数据源, 可String类型源 向Integer类型靠,可Integer类型源向String类型源靠,也可以生成一个新的类型源。
DataStreamSource<String> source = env.fromElements("zs", "li", "we");
DataStreamSource<Integer> source2 = env.fromElements(1, 2, 3, 4, 5, 6, 7);
进行连接
ConnectedStreams<String, Integer> connect = source.connect(source2);
连接后,DataStream类型变为ConnectedStreams ,里边的泛型为合并前两个数据源类型
ConnectedStreams在操作时,需要对两个泛型元素各自进行处理,选择最终的数据类型
两个元素为输入,处理后,统一输出为一种类型
以下是ConnectedStreams 类型特有算子示例:
CoProcessFunction、CoFlatMap、CoMap



Ex :flink示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStreamSource<String> source = env.fromElements("zs", "li", "we");
DataStreamSource<Integer> source2 = env.fromElements(1, 2, 3, 4, 5, 6, 7);
ConnectedStreams<String, Integer> connect = source.connect(source2);
// 我这里是将最终合并类型定为String.
SingleOutputStreamOperator<String> streamOperator = connect.map(new CoMapFunction<String, Integer, String>() {
@Override
public String map1(String value) {
return value + "是字符串类型,直接加后缀";
}
@Override
public String map2(Integer value) {
return "原本是Integer类型:" + value + "现在也变为String";
}
});
streamOperator.print("connect");
env.execute();
}
执行结果:

Process 算子
process 过程函数,又叫低阶处理函数 (后续与window对比讲解),数据流中的每一个元素都会经过process
注:本文仅展示简单demo,后续会有Process专栏文章
Ex :flink示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStreamSource<String> source = env.fromElements("zs", "li", "we");
SingleOutputStreamOperator<String> result = source.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
out.collect(value.toUpperCase() + ">>>");
}
});
result.print("process");
env.execute();
}
process中,功能还是比较丰富的,我们甚至可以实现定时器,后续讲解…

Side Outputs算子(原 split、select)
Side Outputs: 侧面输出
Split就是将一个流分成多个流
Select就是获取分流后对应的数据
注意:1.12中 split函数已过期并移除,已采用 Side Outputs结合 process方法处理
Side Outputs核心功能便是将一个流 分为多个流
数据源拆分步骤说明:
(1)定义拆分后的侧面输出标识 (名字 和元素类型)
(2)原数据使用Process(过程函数)进行处理 (自定义逻辑,选择将元素归于哪个输出标识中 类似于分组)
(3)原数据 获取侧面输出数据(需要传入侧面输出标识对象参数)
Ex :flink示例
package com.leilei;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* @author lei
* @version 1.0
* @date 2021/3/11 20:32
* @desc 数据分流 1.12之前是 split 和select 现在为 Side Outputs
*/
public class SideOutPutOperator {
public static final String JON = "jon";
public static final String LUCY = "lucy";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
// 原始流
DataStreamSource<String> ds = env.fromElements("jon.a", "jon.b", "lucy.zs", "lucy.ls");
// 定义拆分后的侧面输出标识 (名字 和元素类型)
OutputTag<String> jonTag = new OutputTag<>(JON, TypeInformation.of(String.class));
// 定义拆分后的侧面输出标识 (名字 和元素类型)
OutputTag<String> lucyTag = new OutputTag<>(LUCY, TypeInformation.of(String.class));
//将一个流切分为多个流
SingleOutputStreamOperator<String> source = ds.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, Context ctx, Collector<String> out) {
// 自定义数据归属判断 ex:以jon 打头数据则输出到jonTag ;以lucy打头数据则输出到lucyTag
if (value.startsWith(JON)) {
ctx.output(jonTag , value);
}
if (value.startsWith(LUCY)) {
ctx.output(lucyTag, value);
}
}
});
// 获取侧面输出数据 传入侧面输出标识.即可从原始流数据源中获取拆分后的数据,形成一个全新的数据流
DataStream<String> jonStream = source.getSideOutput(jonTag);
DataStream<String> lucyStream = source.getSideOutput(lucyTag);
jonStream.print(JON);
lucyStream.print(LUCY);
env.execute("side-process");
}
}
结果展示:
jon> jon.a
jon> jon.b
lucy> lucy.zs
lucy> lucy.ls
Window算子
window 窗口 算子 ,其实际作用与Process作用类似,但相比Process(process 每个元素都会执行处理),window对数据处理时机选择更加丰富 例如可以根据时间触发数据处理,根据事件时间触发数据处理,根据数量触发数据处理…window的详细说明以及使用,放在window专题讲解,本文仅演示简单demo示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
// 从 1-10 加载数据 ,共十个元素
DataStreamSource source = env.fromSequence(1, 10);
// 每两个元素 计算一次结果
AllWindowedStream windowedStream = source.countWindowAll(2);
SingleOutputStreamOperator result = windowedStream.apply(new RichAllWindowFunction() {
@Override
public void apply(GlobalWindow window, Iterable values, Collector out) {
Long sum = StreamSupport.stream(values.spliterator(), false)
.reduce(Long::sum).orElse(99999L);
out.collect(sum);
}
});
result.print("window");
env.execute();
}
window> 3
window> 7
window> 11
window> 15
window> 19
CoGroup算子
将两个流进行关联,关联不上的数据仍会保留下来
![]()
说明:此为关联数据处理,当两个流关联不上时,仍会进入此方法中,要么first无数据,要么second无数据,需要自行判断,然后进行数据处理
package com.leilei;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
* @author lei
* @version 1.0
* @date 2021/4/11 14:05
* @desc 数据关联 ,关联不上的数据仍会保留下来
*/
public class CoGroupOperator {
public static void main(String[] args) throws Exception {
List<User> users = Arrays.asList(new User("张三", 12),
new User("李四", 13), new User("王五", 14));
List<Student> students = Arrays.asList(new Student("张三", "小三"),
new Student("李四", "小四"),new Student("赵六", "小六子"));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<User> userStream = env.fromCollection(users);
DataStreamSource<Student> studentStream = env.fromCollection(students);
// 对两个数据源进行关联
DataStream<Tuple3<String, String, Integer>> result = userStream.coGroup(studentStream)
// 关联条件 user中 name 要等于 student中name
.where(u -> u.name).equalTo(t -> t.name)
// 这里示意是使用时间滚动窗口 1秒计算一次
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
// 数据处理 需注意,并非where满足才会执行,where不满足(未关联上)也会调用,只是某一只迭代器无数据罢了,需要自己处理
.apply(new CoGroupFunction<User, Student, Tuple3<String, String, Integer>>() {
@Override
public void coGroup(Iterable<User> first, Iterable<Student> second, Collector<Tuple3<String, String, Integer>> out) throws Exception {
Iterator<User> users = first.iterator();
Iterator<Student> students = second.iterator();
if (users.hasNext() && students.hasNext()) {
User user = users.next();
Student student = students.next();
out.collect(Tuple3.of(user.name, student.nickName, user.age));
} else if (users.hasNext() || students.hasNext()) {
if (users.hasNext()) {
while (users.hasNext()) {
User user = users.next();
out.collect(Tuple3.of(user.name, "无昵称", user.age));
}
}
if (students.hasNext()) {
while (students.hasNext()) {
Student student = students.next();
out.collect(Tuple3.of(student.name, student.nickName, -1));
}
}
}
}
});
result.print("coGroup");
env.execute();
}
@NoArgsConstructor
@AllArgsConstructor
@Data
@Builder
public static class User {
private String name;
private Integer age;
}
@NoArgsConstructor
@AllArgsConstructor
@Data
@Builder
public static class Student {
private String name;
private String nickName;
}
}
结果展示:
coGroup> (王五,无昵称,14) //没关联上
coGroup> (张三,小三,12)
coGroup> (李四,小四,13)
coGroup> (赵六,小六子,-1) //没关联上
注:算子并非一个数据源只能用一次,每次只能用一个,其是支持链式编程的哈,即数据源可以同一个算子链不断反复的地对元素进行操作计算,一直到最后收集(输出)
算子链式调用
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
DataStreamSource<String> streamSource = env.socketTextStream("xx", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = streamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
for (String s1 : s.split(",")) {
collector.collect(s1);
}
}
}).filter(s -> !s.equals("sb"))
.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return s.toUpperCase();
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
}).keyBy(tp -> tp.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> stringIntegerTuple2, Tuple2<String, Integer> t1) throws Exception {
return Tuple2.of(t1.f0, t1.f1 + stringIntegerTuple2.f1);
}
});
result.print();
env.execute();
}
总结:
Flink算子非常非常多,本文就暂时先讲到这里…合理使用算子,可极大提高我们计算生产力!