漫谈MySQL十二-高性能的索引的优化之道
大家好,我是王老狮,正确地创建和使用索引是实现高性能查询的基础。前面我们已经了解了索引 相关的数据结构,各种类型的索引及其对应的优缺点。现在我们一起来看看如何真正地发挥这些索引的优势,以及常用的索引创建策略有哪些吧
索引的创建策略
策略一:索引列的类型尽量小
我们在定义表结构的时候要显式的指定列的类型,以整数类型为例,有TTNYINT 、NEDUMNT 、INT 、BIGTNT 这么几种,它们占用的存储空间依次递增, 我们这里所说的类型大小指的就是该类型表示的数据范围的大小。能表示的整数 范围当然也是依次递增,如果我们想要对某个整数列建立索引的话,在表示的整 数范围允许的情况下,尽量让索引列使用较小的类型,比如我们能使用 INT 就不 要使用 BIGINT ,能使用 NEDIUMINT 就不要使用 INT ,这是因为:
- 数据类型越小,在查询时进行的比较操作越快(CPU 层次)
- 数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下 更多的记录,从而减少磁盘/0 带来的性能损耗,也就意味着可以把更多的数据 页缓存在内存中,从而加快读写效率。
这个建议对于表的主键来说更加适用,因为不仅是聚簇索引中会存储主键值, 其他所有的二级索引的节点处都会存储一份记录的主键值,如果主键适用更小的 数据类型,也就意味着节省更多的存储空间和更高效的 I/0。
策略二:索引选择性
创建索引应该选择选择性/离散性高的列。索引的选择性/离散性是指,不重 复的索引值(也称为基数,cardinality)和数据表的记录总数(N)的比值,范围从 1/N 到 1 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让 MySQL 在查找时过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
很差的索引选择性就是列中的数据重复度很高,比如性别字段,不考虑政治 正确的情况下,只有两者可能,男或女。那么我们在查询时,即使使用这个索引, 从概率的角度来说,依然可能查出一半的数据出来。
比如下面这个表:
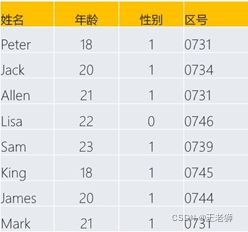
哪列做为索引字段最好?当然是姓名字段,因为里面的数据没有任何重复, 性别字段是最不适合做索引的,因为数据的重复度非常高。
怎么算索引的选择性/离散性?比如 order_exp 这个表:
select COUNT(DISTINCT order_no)/count(*) cnt from order_exp;
select COUNT(DISTINCT order_status)/count(*) cnt from order_exp;
很明显,order_no 列上的索引就比 order_status 列上的索引的选择性就要好,原 因很简单,因为 order_status 列中的值只有-1,0,1 三种。
策略三:前缀索引
有时候需要索引很长的字符列,这会让索引变得大且慢。一个策略是模拟哈希索引。
模拟哈希索引
order_exp 表中order_note 字段很长,想把它作为一个索引,我们可以增加 一个order_not_hash 字段来存储order_note 的哈希值,然后在order_not_hash 上 建立索引,相对于之前的索引速度会有明显提升,一个是对完整的 order_note 做索引,而后者则是用整数哈希值做索引,显然数字的比较比字符串的匹配要高效得多。
但是缺陷也很明显:
- 需要额外维护order_not_hash 字段;
- 哈希算法的选择决定了哈希冲突的概率,不良的哈希算法会导致重复值 很多;
- 不支持范围查找。
还可以做些什么改进呢?还可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。一般情况下我们需 要保证某个列前缀的选择性也是足够高的,以满足查询性能。(尤其对于 BLOB、 TEXT 或者很长的 VARCHAR 类型的列,应该使用前缀索引,因为 MySQL 不允许索 引这些列的完整长度)。
诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便 节约空间) 。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。换 句话说,前缀的“基数”应该接近于完整列的“基数”。为了决定前缀的合适长度,可以找到最常见的值的列表,然后和最常见的前缀列表进行比较。
首先找到最常见的值的列表:
SELECT COUNT(*) AS cnt,order_note FROM order_exp GROUP BY order_note ORDER BY cnt DESC LIMIT 20;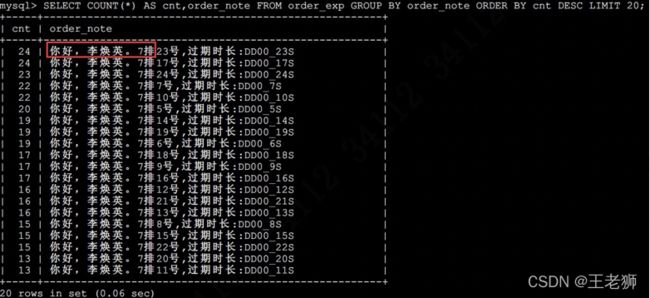
通过观察数据的分布,我们可以大胆的猜测,前 9 个字符的选择性不会太好, 从第 10 个开始应该还不错。试一试:
SELECT COUNT(DISTINCT LEFT(order_note,3))/COUNT(*) AS sel3,
COUNT(DISTINCT LEFT(order_note,4))/COUNT(*)AS sel4,
COUNT(DISTINCT LEFT(order_note,5))/COUNT(*) AS sel5,
COUNT(DISTINCT LEFT(order_note, 6))/COUNT(*) As sel6,
COUNT(DISTINCT LEFT(order_note, 7))/COUNT(*) As sel7,
COUNT(DISTINCT LEFT(order_note, 8))/COUNT(*) As sel8,
COUNT(DISTINCT LEFT(order_note, 9))/COUNT(*) As sel9,
COUNT(DISTINCT LEFT(order_note, 10))/COUNT(*) As sel10,
COUNT(DISTINCT LEFT(order_note, 11))/COUNT(*) As sel11,
COUNT(DISTINCT LEFT(order_note, 12))/COUNT(*) As sel12,
COUNT(DISTINCT LEFT(order_note, 13))/COUNT(*) As sel13,
COUNT(DISTINCT LEFT(order_note, 14))/COUNT(*) As sel14,
COUNT(DISTINCT LEFT(order_note, 15))/COUNT(*) As sel15,
COUNT(DISTINCT order_note)/COUNT(*) As total
FROM order_exp;
可以看见,从第 10 个开始选择性的增加值很高,随着前缀字符的越来越多, 选择度也在不断上升,但是增长到第 15 时,已经和第 14 没太大差别了,选择性 提升的幅度已经很小了,都非常接近整个列的选择性了。
那么针对这个字段做前缀索引的话,从第 13 到第 15 都是不错的选择,甚至 第 12 也不是不能考虑。当然不找到最常见的值的列表,直接计算前缀字符选择 性也是可以的。
在上面的示例中,已经找到了合适的前缀长度,如何创建前缀索引:
ALTER TABLE order_exp ADD KEY (order_note(14));建立前缀索引后查询语句并不需要更改:
select * from order_exp where order_note = 'xxxx' ;前缀索引是一种能使索引更小、更快的有效办法,但另一方面也有其缺点 MySQL 无法使用前缀索引做 ORDER BY 和 GROUP BY ,也无法使用前缀索引做覆 盖扫描。
有时候后缀索引 (suffix index)也有用途(例如,找到某个域名的所有电子邮 件地址) 。MySQL 原生并不支持反向索引,但是可以把字符串反转后存储,并基于此建立前缀索引。可以通过触发器或者应用程序自行处理来维护索引。
策略四:只为用于搜索、 排序或分组的列创建索引
也就是说,只为出现在 WHERE子句中的列、连接子句中的连接列创建索引, 而出现在查询列表中的列一般就没必要建立索引了,除非是需要使用覆盖索引; 又或者为出现在 ORDER BY 或 GROUP BY 子句中的列创建索引,这句话什么意思呢?比如:
SELECT * FROM order_exp ORDER BY insert_time, order_status,expire_time;查询的结果集需要先按照 insert_time 值排序,如果记录的 insert_time 值相同,则需要按照 order_status 来排序,如果 order_status 的值相同,则需要按照 expire_time 排序。回顾一下联合索引的存储结构,u_idx_day_status 索引本身就 是按照上述规则排好序的,所以直接从索引中提取数据,然后进行回表操作取出 该索引中不包含的列就好了。
当然 ORDER BY 的子句后边的列的顺序也必须按照索引列的顺序给出,如果 给出 ORDER BY order_status,expire_time, insert_time 的顺序,那也是用不了 B+树 索引的,原因不用再说了吧。
SELECT insert_time, order_status,expire_time,count(*) FROM order_exp GROUP BY insert_time, order_status,expire_time;这个查询语句相当于做了 3 次分组操作:
- 先把记录按照 insert_time 值进行分组,所有 insert_time 值相同的记录划分 为一组。
- 将每个 insert_time 值相同的分组里的记录再按照 order_status 的值进行分组, 将 order_status 值相同的记录放到一个小分组里。
- 再将上一步中产生的小分组按照expire_time 的值分成更小的分组。
- 然后针对最后的分组进行统计,如果没有索引的话,这个分组过程全部需要 在内存里实现,而如果有了索引的话,恰巧这个分组顺序又和我们的u_idx_day_status 索引中的索引列的顺序是一致的,而我们的 B+树索引又是按照 索引列排好序的,这不正好么,所以可以直接使用 B+树索引进行分组。
和使用 B+树索引进行排序是一个道理,分组列的顺序也需要和索引列的顺序一致。
策略五:多列索引
很多人对多列索引的理解都不够。一个常见的错误就是,为每个列创建独立的索引,或者按照错误的顺序创建多列索引。
我们遇到的最容易引起困惑的问题就是索引列的顺序。正确的顺序依赖于使 用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。反复强 调过,在一个多列 B-Tree 索引中,索引列的顺序意味着索引首先按照最左列进 行排序,其次是第二列,等等。所以,索引可以按照升序或者降序进行扫描,以 满足精确符合列顺序的 ORDER BY 、GROUP BY 和 DISTINCT 等子句的查询需求。
所以多列索引的列顺序至关重要。对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。当不需要考虑排序和分组时,将选择性最高的列放在前面通常是很好的。这时候索引的作用只是用于优化 WHERE条件的查找。在这种情况下,这样设计的索引确实能够最快地过滤出需要的行,对于 在 WHERE 子句中只使用了索引部分前缀列的查询来说选择性也更高。
然而,性能不只是依赖于索引列的选择性,也和查询条件的有关。可能需要根据那些运行频率最高的查询来调整索引列的顺序,比如排序和分组,让这种情 况下索引的选择性最高。
同时,在优化性能的时候,可能需要使用相同的列但顺序不同的索引来满足 不同类型的查询需求。
策略六:主键是很少改变的列
我们知道,行是按照聚集索引物理排序的,如果主键频繁改变(update) ,物 理顺序会改变,MySQL 要不断调整 B+树,并且中间可能会产生页面的分裂和合 并等等,会导致性能会急剧降低。
策略七:避免冗余和重复索引
MySQL 允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑, 这会影响性能。重复索引是指在相同的列上按照相同的顺序创建的相同类型的索 引。应该避免这样创建重复索引,发现以后也应该立即移除。
有时会在不经意间创建了重复索引,例如下面的代码:
CREATE TABLE test (
ID INT NOT NULL PRIMARY KEY,
A INT NOT NULL,
B INT NOT NULL,
UNIQUE(ID),
INDEX(ID)
) ENGINE=InnoDB;这里创建了一个主键,又加上唯一限制,然后再加上索引以供查询使用。事 实上,MySQL 的唯一限制和主键限制都是通过索引实现的,因此,上面的写法实 际上在相同的列上创建了三个重复的索引。通常并没有理由这样做,除非是在同 一列上创建不同类型的索引来满足不同的查询需求。
冗余索引和重复索引有一些不同。如果创建了索引(A B) ,再创建索引(A)就 是冗余索引,因为这只是前一个索引的前缀索引。因此索引(AB)也可以当作索引 (A)来使用(这种冗余只是对 B-Tree 索引来说的) 。但是如果再创建索引 (B,A) , 则不是冗余索引,索引(B)也不是,因为 B 不是索引(A,B)的最左前缀列。
已有的索引(A),扩展为(A ,ID),其中 ID 是主键,对于 InnoDB 来说主键列已 经包含在二级索引中了,所以这也是冗余的。
解决冗余索引和重复索引的方法很简单,删除这些索引就可以,但首先要做 的是找出这样的索引。可以通过写一些复杂的访问 INFORMATION_SCHEMA 表的 查询来找。
策略八:删除未使用的索引
除了冗余索引和重复索引,可能还会有一些服务器永远不用的索引。这样的 索引完全是累赘,建议考虑删除。