Mysql性能优化
文章目录
- 前言
- ❤️运维方面
-
- 缓冲池配置
- redo log设置
- ❤️开发方面
-
- 表设计优化
- SQL规范
前言
在实际开发中经常遇到页面打不开,页面加载慢,尤其汇总统计页面后台请求时间都变成了秒级的了,这对用户来说是绝对不能忍的,那么怎么提高数据库的执行效率呢?本文将简单的讲解一下Mysql性能优化的内容。
❤️运维方面
首先是运维方面,这是Mysql性能优化最简单的实现方式了,效果也不能说是最差的吧,性价比最低的。硬件升级咱就不说了,这没啥意义,说一下常用的Mysql配置文件来提高Mysql性能的方法。
缓冲池配置
前面讲解Mysql架构的时候提到过,在Mysql中是有个Innodb_buffer_pool缓冲池的,这个缓冲池是在内存中的,存放有访问的数据。我们知道正常数据的读取速度是内存读取 > 磁盘IO读取的,那么是不是可以将这个缓冲池调大了,尽可能的存放更多的数据从而减少磁盘的读取操作呢。
当然这个缓冲池的大小要根据服务器实际情况调整,如果是一个只有数据库的服务器可以尝试到内存的3/4左右。其他的服务器上面还有项目或者其他软件的可以看看内存实际情况调试,别到时候别的软件内存不够用。
查看缓冲池大小命令
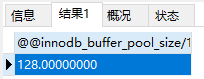
查看缓冲池的大小:
SELECT @@innodb_buffer_pool_size; 这个命令查询出来的是字节
SELECT @@innodb_buffer_pool_size/1024/1024; 经过两次1024查询出来的是M
可以看到我当前的缓冲池大小为128M。
查看缓冲池是否够用
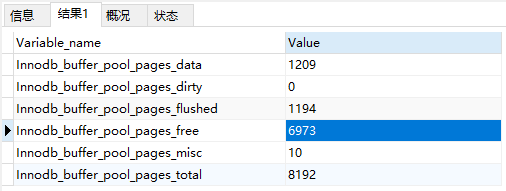
查看缓冲池是否够用要查看缓冲池中Page的使用情况,命令如下
SHOW GLOBAL STATUS LIKE ‘innodb_buffer_pool_pages%’
可以看到当前缓冲池还是够用的,当Innodb_buffer_pool_pages_free为0的时候说明缓冲池满了。
修改缓冲池大小
配置文件在 /etc/my.cnf中修改,可以看到上面配置的默认为128M。

放开注释,将这个缓冲池的大小修改为750M,然后重启Mysql,可以查看到现在的缓冲池大小为768M。

对于大数据量的导入增大缓冲池的大小性能提升是非常可观的。
redo log设置
这一条要谨慎使用,一般为了数据安全性刷盘机制都是用的1实时刷盘,可以改redo log大小,刷盘机制慎重修改。
redo log前面说过,在Mysql中修改完数据之后不会直接写入到磁盘的,而是存放到redo log中,根据redo log的策略来进行刷盘,频繁的刷盘IO写入也会导致效率较低。
innodb_flush_log_at_trx_commit刷盘策略 1表示commit提交事务的时候刷盘,0表示每秒刷盘,2刷盘时机不确定。对于一些数据要求不太高的数据库可以设置为0或者2,同时提高redo log的大小。
同样可以在my.cnf中修改redo log的大小,增加下面的配置,一般设置为缓冲池的1/4。
innodb_log_file_size=200M
innodb_flush_log_at_trx_commit=0
❤️开发方面
开发方面的配置才与咱们实际相关,数据库配置基本修改一次就行了,开发方面注意的要时刻都注意点。
表设计优化
数据冗余设计
虽然我们不希望数据冗余,但是在很多情况下数据冗余是可以提高查询效率的。当然这里要注意的是冗余字段是不会修改的,否则后面开发数据错乱。
很多时候我们可能只需要其中某个表中的一个字段,但是不得不去连表查询,这种情况下做数据冗余是可以减少连表查询的。简单的举个例子:假设我们的某个表中的名称是新增了之后禁止修改的,如果很多情况下只用到连表查询名称,那么就可以在关联的其他表中可以增加名称字段。
数据库的设计规范只是一个标准,在某些特殊情况下可以不遵守标准达到更高的效率。
简单的说个实际项目中的情况,Mysql没有递归查询,所以在设计部门表的时候增加了部门层级字段(…爷ID,父ID,自己ID),或者直接将ID或者Code设置为具有层级关系的,但是界面上好多地方都需要展示层级关系名称,那么就可以增加字段(…爷名称/父名称/自己名称)方便后面的查询。
分表设计
某些时候我们可能看到一个表可能七八十个字段,这时候就可以根据实际字段的含义拆分成多个表。这么设计的意义一方面在于字段分表处理之后比较清晰,字段多了看都不想看,而且容易眼花,出错误的概率很大;另一方面在于很多时候的查询不需要所有字段,可能根据业务情况只需要某部分字段,这时候效率比较高。
还有一个情况是在表中有可变长度的字段,而且字段长度挺长的,这时候需要将这个或这些字段拆分出去单独一个表,因为这个字段的存在会减少Page中存放row的数量,查询效率比较低。在阿里巴巴开发规约中就有这么一条。
【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
索引设计
对于表的主键尽量使用数值类型而且有序,因为数值类型占用的空间比较小,有序新增的效率比较高,索引树的变化比较可靠,如果无序每次插入都可能导致索引树的大面积变化。
常用的主键建议使用雪花算法生成。
字段设计
我们知道表中字段越小那么Row占用的空间就越小,Page中存放的Row就越多,查询效率就越高。所以在开发中要根据实际情况设置表中字段的大小,别动不动就是varchar 32 64 的设置。
对于固定长度的字符串尽量使用char类型,不要使用varchar可变长度类型。
对于一些标志信息尽量使用数值类型,数值类型比文本类型的处理效率要高。
对于一些字段尽量设置为not null,给一个初始默认值代表空。
SQL规范
对于项目可以开启慢查询日志,来查找查询比较慢的SQL语句进行优化,开启慢查询日志的方法:
set global slow_query_log=‘ON’;
set long_query_time=3; //查询时间大于3秒的SQL认为是慢查询,这个根据实际情况设置
SQL优化是性价比最高的优化方案,是最廉价而且效果最好的
EXPLAIN解析SQL
EXPLAIN大家应该比较熟悉,咱就不再介绍了,咱就说一下EXPLAIN中避免的情况。

分析后的信息type中避免使用ALL全表扫描,全表扫描的效率是比较低的。
key是使用到的的索引,要尽量使用索引。
extra是详细说明,要避免Using filesort排序(不详细解释了,这里面有一种情况是把所有数据都取出来之后再排序,而不是直接读取的有序的数据),Using temporary临时空间,Using where数据过滤(这是查询出来数据之后又做了过滤,而不是在数据库中直根据过滤条件取出来的数据)
SQL语句优化
尽量减少非操作,像not in , != 等操作。
查询的时候不要使用SELECT *操作,一方面减少不必要的宽度消耗,另一方面使用SELECT * 可能会导致覆盖索引。
只查询一条数据的时候使用limit 1直接截断数据,limit不会做全表扫描,直接取出第一条数据。
对于表中常用的排序字段要加上索引,比如创建时间等常用排序字段会提高查询效率。
尽量少用or过滤,因为使用or的时候如果有一边没有索引最终的查询也是不走索引的。可以使用两个查询最后用union all合起来。
尽量使用union all而不是使用union,当然这是在两个查询结果没有重复数据的情况下,union会对合并的数据再进行去重排序,union all不会去重排序,所以union all 的效率是比union高的。
分页优化,对于数据量比较大的表可以使用下面SQL语句进行优化,亲测效果很客观,而且数据越到后面效果越好,几百万的数据后面的分页可以提高10倍以上效率。
select * from table where id > (select id from table limit 1000000,1) LIMIT 10;
对于like操作,如果like 'name%'是使用索引的,前面加%是不使用索引的。
在Where条件中,=前面不要使用计算,例如where date_sub(date, interval 7 day); > now(),这样是不走索引的,可以将计算放在后面改为这样 where date > date_sub(now(), interval 7 day);
联合索引要注意最左前缀原则。
经常说的一句话用小表驱动大表,尽量使用Inner JOIN 因为Inner JOIN会自动找到小表做驱动表,其他的是不会的。
尽量避免子查询操作,可以采用JOIN连表的方式查询。
尽量避免数据类型不一致的情况,比如表中使用数字,查询条件使用的字符串。
分组之后是默认有个排序规则的,可以使用Order by null来禁止排序。
in的值不宜太多,如果太多的话可以转换成连接。