【C++笔记】优先级队列priority_queue的模拟实现
【C++笔记】优先级队列priority_queue的模拟实现
- 一、优先级队列的介绍与使用方式
-
- 1.1、优先级队列介绍
- 1.2、优先级队列的常见使用
- 二、优先级队列的模拟实现
-
- 1.0、仿函数的介绍
- 1.1、构造函数
- 1.2、优先级队列的插入push
- 1.3、优先级队列的删除(删除堆顶元素)
- 1.4、获取堆顶元素
- 1.5、判断是否为空
- 1.6、优先级队列的大小size
一、优先级队列的介绍与使用方式
1.1、优先级队列介绍
优先级队列可能听名字就能想到它的功能,就是按优先级排的队列。可他到底是个什么呢?它的底层有时由什么实现的?
我们可以先翻翻文档看看:

从文档中我们也可以看出它其实也是一个类模板。
其中的Container这个模板参数是一个容器适配器,默认使用vector作为其底层存储数据的容器。
其实优先级队列在底层就是我们以前学过的堆,它在vector上使用了堆heap的算法将vector中元素构造堆的结构,默认情况下是大堆。
而其中的Compare这个模板参数则是能将堆灵活的转换成大堆或小堆的一个非常好的工具,在后面会对仿函数进行详细的解析。
我们再来看看它对应的接口:

从给出的接口我们也可以发现它和堆其实是非常相似的。
1.2、优先级队列的常见使用
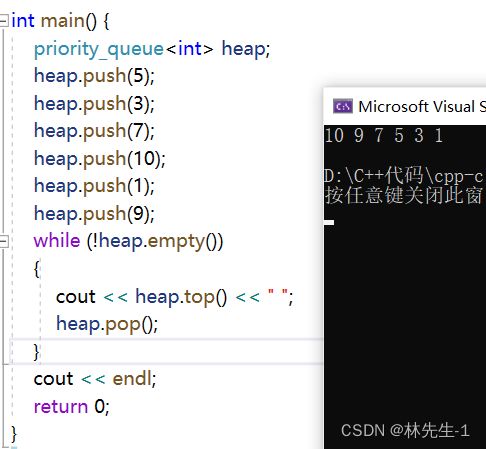
上面说过优先级队列默认是大堆,那我们就来验证一下:
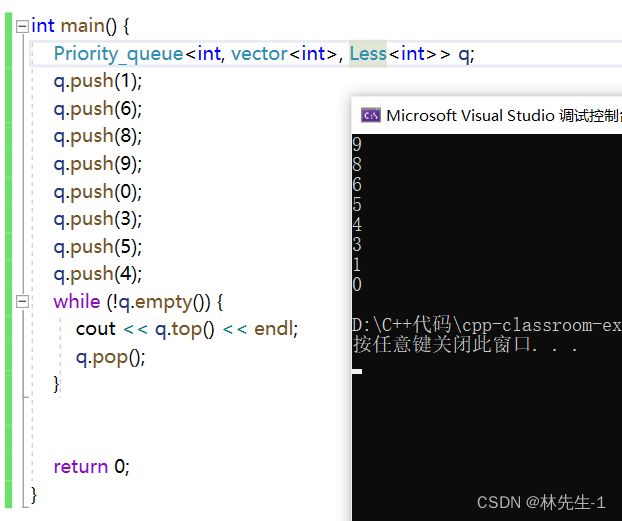
如果想要给成小堆,则要传入一个仿函数:
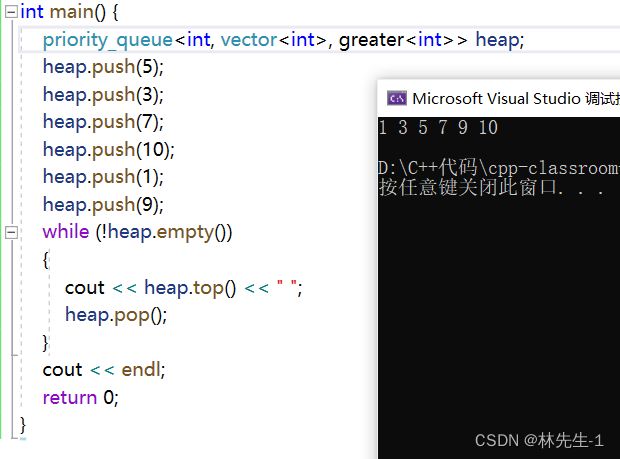
因为是缺省参数,所以一定要从左到右传完。这里的greater< int > 其实就是比较方法。
二、优先级队列的模拟实现
1.0、仿函数的介绍
仿函数,也称函数对象,是STL六大组件中的一个,他可以想其他类一样定义对象,也可以像正常函数一样调用。它其实有点像我们在C语言中学过的函数指针。
但是我们在这里并不能一次性讲解完它的所有内容,所以今天就仅基于priority_queue的实现来对它进程粗略的介绍。
实际上,就实现意义而言,函数对象这个名字更加贴切:一种具有函数特质的对象。但是,仿函数似乎能更加符合的描述他的行为。所以这里我们就采用仿函数这种叫法。
在学习STL之前我们就已经了解了泛型编程的概念,C++引入了模板让我们的编程能够随意的控制数据类型,现在引入了仿函数的概念,让我们能够控制逻辑。
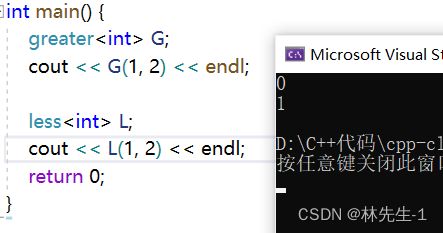
我们上面用到的greater< int>就是一个仿函数,我们也可以对应的查查文档看看:

我们再来看看它的简单应用吧:
模拟实现仿函数:
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)//less和greater需要实现的就是一个比较,所以这里的返回值是bool类型
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
其实仿函数主要是通过在类中实现一个特殊的运算符重载——operator()来达成的。
然后我们就可以将上面的测试换成我们自己写的仿函数了:
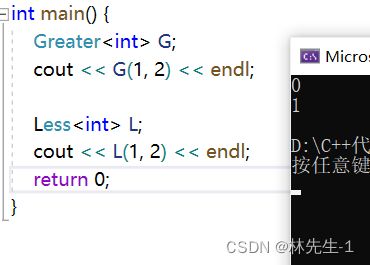
其达到的效果也是一样的。
其实仿函数之所以能像函数一样直接调用(直接对象名+括号),其实是编译器在底层做了处理,编译器在底层其实是自动调用了类中的operator(),而我们其实也可以显示的写出来:
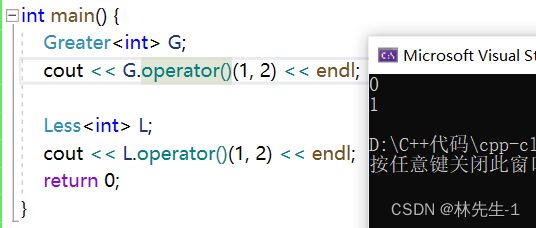
从这点我们可以看出,仿函数其实也没有多神奇,一切都是编译器的功劳。
1.1、构造函数
模板参数的设计:
首先,对于函数模板的设计,我们和库里面对其,给了三个参数,分别表示参数存入容器的参数类型,容器类型和仿函数,其中默认的仿函数是less,建大堆:
template<class T, class Container = std::vector<T>, class Compare = less<T>>
class Priority_queue
{
public:
//...
private:
Container _con;
Compare _cmp;
};
无参构造函数:
无参构造函数我们其实可以不写的,因为我们使用容器适配器的好处就是我们可以直接使用其他容器的无参构造函数,但是因为后面的一些原因(调用可能存在歧义),我们还得将它写上。
其实我们只需将它写出来即可,我们什么都不用做:
// 无参构造函数
Priority_queue() {
}
迭代器区间构造:
因为我们这里使用的是vector来适配,vector中也有迭代器区间构造,所以我们也很轻松,直接调用vector的即可:
// 迭代器区间构造函数
template <class InputIterator>
Priority_queue(InputIterator first, InputIterator last)
:_con(first, last)
{
}
1.2、优先级队列的插入push
既然有限就队列的底层是一个堆,那它的插入也和堆一样,建堆使用的是向上调整算法,我们先来简单的回顾一下:
以小堆为例:
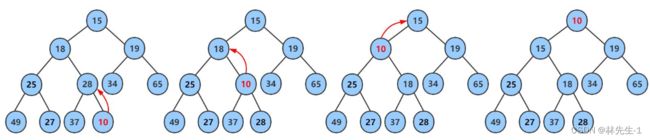
建小堆我们的向上调整算法需要做的就是,从指定的孩子节点位置开始,和父节点比较,判断是否满足堆结构,如果不满足,就交换父子节点,然后原来的父节点编程子节点,再次进行上述操作,直到满足堆结构为止。
以下是代码实现:
// 向上调整算法
void adjust_up(size_t child) {
size_t parent = (child - 1) / 2;
while (child > 0) {
if (_cmp(_con[parent], _con[child])) {
swap(_con[parent], _con[child]);
}
else {
break;
}
child = parent;
parent = (child - 1) / 2;
}
}
然后我们的插入接口就像堆一样,每插入一个节点就向上调整一次即可:
// 插入
void push(const T& x) {
_con.push_back(x);
adjust_up(_con.size() - 1);
}
1.3、优先级队列的删除(删除堆顶元素)
删除pop使用的是向下调整算法,我们还是先来简单的回顾一下:
还是以小堆为例:

如上图,向下调整算法我们要做的是找到两个孩子中较小的,然后与父节点比较大小,如果父节点大于子节点就执行交换,然后原来的子节点成为新的父节点,再次进行上述步骤。直到符合堆的结构。
这是代码实现:
// 向下调整算法
void adjust_down(size_t parent) {
size_t child = 2 * parent + 1;
while (child < _con.size()) {
if (child + 1 < _con.size() && _cmp(_con[child], _con[child + 1])) {
child++;
}
if (_cmp(_con[parent], _con[child])) {
swap(_con[parent], _con[child]);
}
parent = child;
child = 2 * parent + 1;
}
}
我们堆中的删除是使用了一个巧妙的方式来节省开销,先将顶部的元素与最后一个元素位置互换,然后再删除最后一个元素,再堆顶部元素进行向下调整:
// 弹出
void pop() {
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
1.4、获取堆顶元素
其实堆最主要的接口就上面这两个,实现了上面的两个接口,其他的接口就很简单了,简直不用动脑。
获取顶部元素,我们直接返回_con.front()即可:
// 顶部元素
T& top() {
return _con.front();
}
1.5、判断是否为空
因为vector本身就又判空接口,所以没的说,也是复用:
// 判空
bool empty() {
return _con.empty();
}
1.6、优先级队列的大小size
这个也一样:
// 长度
size_t size() {
return _con.size();
}
测试结果:
小堆:
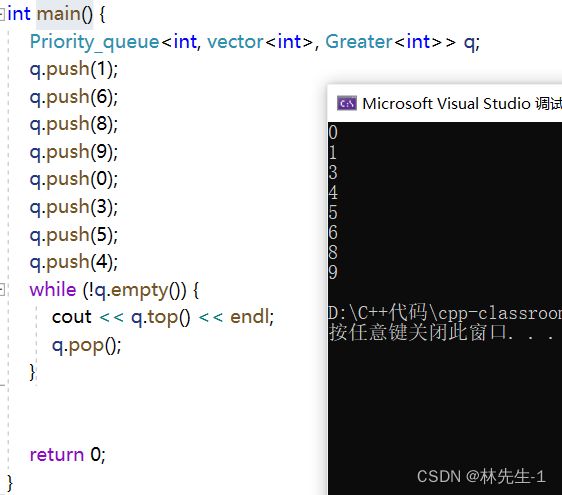
大堆: