Clickhouse学习笔记(9)—— 语法优化
ClickHouse 的 SQL 优化规则是基于 RBO(Rule Based Optimization)实现的
官方数据集的使用
为了方便测试CK的语法优化规则,尝试使用官方提供的数据集;
需要使用的数据集是visits_v1和hints_v1:
Anonymized Web Analytics Data | ClickHouse Docs
hits_v1 表有 130 多个字段,880 多万条数据
visits_v1 表有 180 多个字段,160 多万条数据
使用步骤如下:
1.将下载的数据集上传到服务器
2.将数据集解压到clickhouse 数据路径下:/var/lib/clickhouse(权限不够的话切换root用户)
sudo tar -xvf hits_v1.tar -C /var/lib/clickhouse
sudo tar -xvf visits_v1.tar -C /var/lib/clickhouse可以看到数据集的文件目录:

解压之后会和clickhouse文件夹下的相应目录合并:
3.修改数据集所属用户
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/data/datasets
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/metadata/datasets4.查看是否导入成功

在/var/lib/clickhouse/data路径下可以看到导入的datasets数据库
则导入成功
COUNT优化
在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则会直接使用 system.tables 的 total_rows
EXPLAIN SELECT count()FROM visits_v1;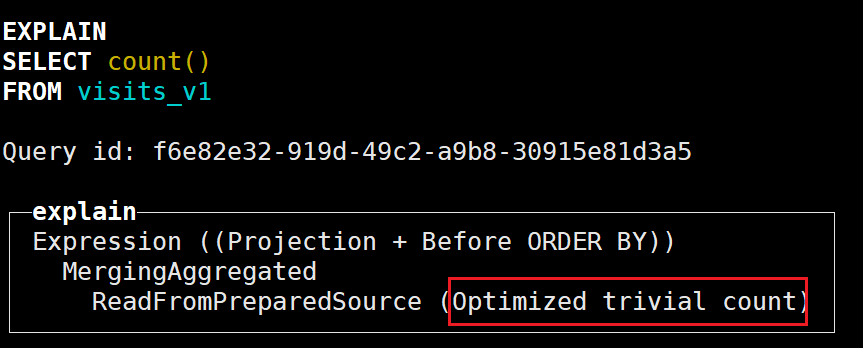
可以看到对count进行了优化;
但如果是count(UserID),则没有优化效果:

消除重复字段
消除子查询重复字段
EXPLAIN SYNTAX SELECT
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM
hits_v1 AS a
LEFT JOIN (
SELECT
UserID,
UserID as HaHa,
VisitID
FROM visits_v1) AS b
USING (UserID)
limit 3;重复的字段会被消除:
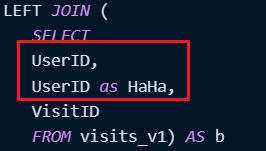
,即使是重命名也不可以
删除重复的 order by key
EXPLAIN SYNTAX
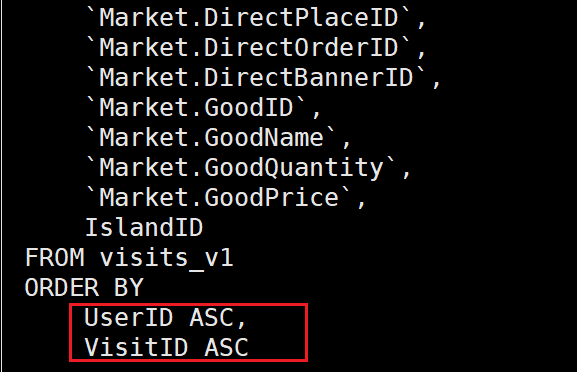
SELECT *
FROM visits_v1
ORDER BY
UserID ASC,
UserID ASC,
VisitID ASC,
VisitID ASC优化后的语法:
删除重复的 limit by key
有关limit by的用法:
LIMIT BY Clause | ClickHouse Docs
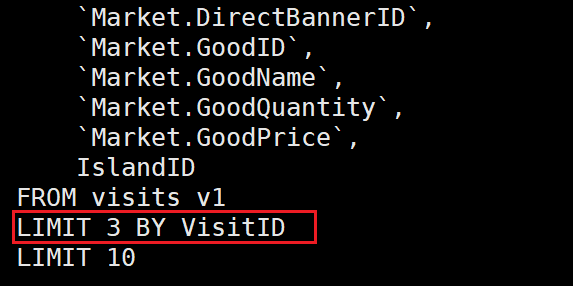
EXPLAIN SYNTAX
SELECT *
FROM visits_v1
LIMIT 3 BY
VisitID,
VisitID
LIMIT 10优化后的语法:
删除重复的 USING Key
EXPLAIN SYNTAX
SELECT
a.UserID,
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM hits_v1 AS a
LEFT JOIN visits_v1 AS b USING (UserID, UserID)优化后的语法:
SELECT
UserID,
UserID,
VisitID,
URL,
b.UserID
FROM hits_v1 AS a
ALL LEFT JOIN visits_v1 AS b USING (UserID)谓词下推
简单来说就是提前过滤条件
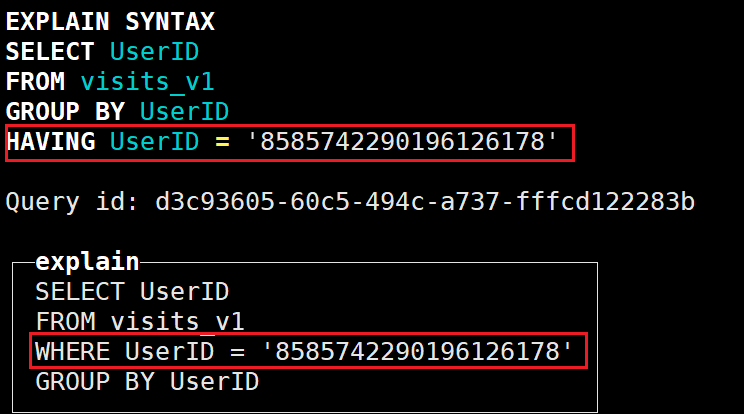
EXPLAIN SYNTAX SELECT UserID FROM visits_v1 GROUP BY UserID HAVING UserID = '8585742290196126178';原sql中是先分组,再根据having的条件过滤,但优化后的sql是先通过where过滤,再分组:
谓词下推同样适用于复杂的查询语句,以子查询为例:
EXPLAIN SYNTAX
SELECT *
FROM
(
SELECT UserID
FROM visits_v1
)
WHERE UserID = '8585742290196126178'会将where过滤提前到子查询内部去执行:
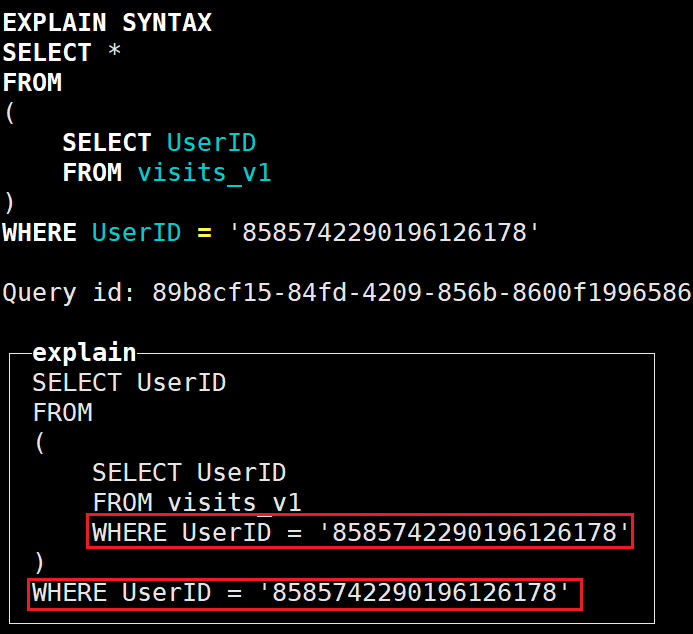
但不会删除原位置的where语句;
聚合计算外推
聚合函数内的计算会外推
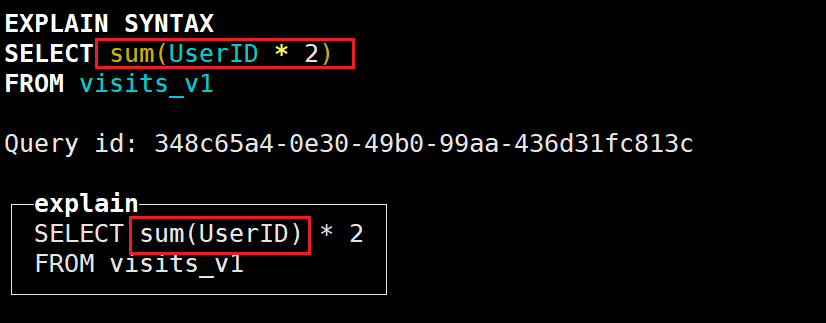
EXPLAIN SYNTAX
SELECT sum(UserID * 2)
FROM visits_v1会首先将UserID加和,再×2:
聚合函数消除
如果对聚合键,也就是 group by key 使用 min、max、any 聚合函数,则将函数消除
EXPLAIN SYNTAX
SELECT
max(UserID),
min(UserID),
any(UserID),
avg(UserID),
sum(UserID)
FROM visits_v1
GROUP BY UserID;可以看到:

因为对于分组的key来说,同一组的数据key相同,因此对其求最大、最小值等操作无意义;
标量替换
如果子查询只返回一行数据,在被引用的时候用标量替换
EXPLAIN SYNTAX
WITH
(
SELECT sum(bytes)
FROM system.parts
WHERE active
) AS total_disk_usage
SELECT
(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10;优化后:
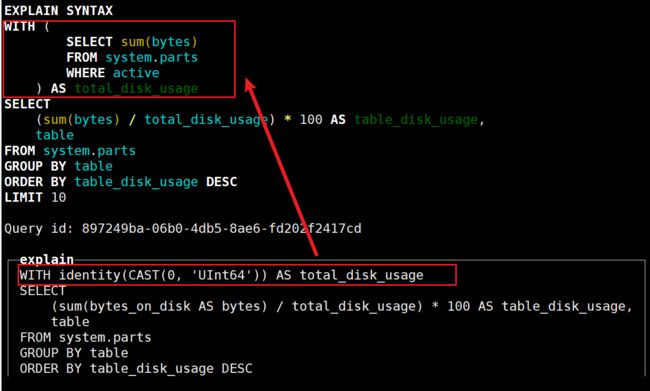
由于with中sum(bytes)的结果为0,因此使用标量来进行替换;
identity:标识函数
Other Functions | ClickHouse Docs
cast:类型转换函数(cast(x,T))