Python之文件与文件夹操作及 pytest 测试习题
目录
-
- 1、文本文件读写基础。编写程序,在 当前目录下创建一个文本文件 test.txt,并向其中写入字符串 hello world。
- 2、编写一个程序 demo.py,要求运行该程序后,生成 demo_new.py 文件,其中内容与demo.py 一样,只是在每一行的后面加上行号。要求行号以#开始,并且所有行的#符号垂直对齐
- 3、编写程序,使用pickle模块将包含学生成绩的字典保存为二进制文件,然后再读取内容并显示。
- 4、计算文件 MD5 的值。MD5 是一种常用的哈希算法,不论原始信息长度如何,总是计算得到一个固定长度的二进制字符串。该算法对原文的改动非常敏感,因此该算法被用于检验信息是否被修改过,用于文件完整性检验,或者数字签名。
- 5、统计三国演义中高频词
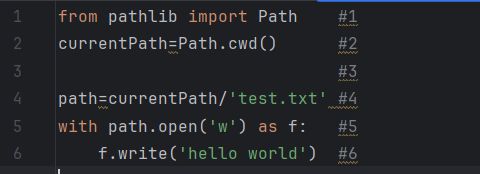
1、文本文件读写基础。编写程序,在 当前目录下创建一个文本文件 test.txt,并向其中写入字符串 hello world。
from pathlib import Path
currentPath=Path.cwd()
path=currentPath/'test.txt'
with path.open('w') as f:
f.write('hello world')

2、编写一个程序 demo.py,要求运行该程序后,生成 demo_new.py 文件,其中内容与demo.py 一样,只是在每一行的后面加上行号。要求行号以#开始,并且所有行的#符号垂直对齐
with open('demo01.py','r') as f:
content=f.readlines()
maxlength=len(max(content,key=len))
# enumerate同时列出数据和下标
# ljust返回一个原字符串左对齐
with open('demo_new.py','w') as f2:
for i,line in enumerate(content):
f2.write(line.rstrip().ljust(maxlength)+'#'+str(i+1)+'\n')
3、编写程序,使用pickle模块将包含学生成绩的字典保存为二进制文件,然后再读取内容并显示。
import pickle as p
student={'大明',10101,'二班','班长'}
# wb二进制写方式打开文件,只能写文件
# rb二进方式读取文件
# dumps读入数据并序列化
# loads以数列化数据读出
with open('student.dat','wb') as s:
data=p.dumps(student)
s.write(data)
s.close()
with open('student.dat','rb') as ss:
dirt=ss.read()
ss.close()
dirt=p.loads(dirt)
print(dirt)

4、计算文件 MD5 的值。MD5 是一种常用的哈希算法,不论原始信息长度如何,总是计算得到一个固定长度的二进制字符串。该算法对原文的改动非常敏感,因此该算法被用于检验信息是否被修改过,用于文件完整性检验,或者数字签名。
Python 标准库 hashlib 中 md5()函数可以用来计算字节串的 MD5 值。编写一个程序,
要求输入一个文件名,然后输出该文件的 MD5 值,如果文件不存在就给出相应提示
import hashlib as ha
import os
# hexdigest()用于获取哈希对象的十六进制摘要。
file=input("输入文件路径:")
if os.path.exists(file):
with open(file,'r') as f:
data=f.read()
data_md5=ha.md5(data.encode(encoding='UTF-8')).hexdigest()
print(data_md5)
else:
print("没有该文件")

5、统计三国演义中高频词
下载《三国演义》电子文本(也可从烟台大学本课程教学网站实验栏目中下载)。使用
jieba 库对文件“三国演义.txt”中的文本进行分词,并对每个词出现的次数进行统计,将词频
最高的前三个词语输出。运行效果如下。
输入:无
输出:[(934, ‘曹操’), (831, ‘孔明’), (761, ‘将军’)]
import jieba
txt = open("sanguo.txt", "r", encoding = "utf-8").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(3):
word, count = items[i]
# 第一个字符宽度10,第二个字符宽度5。格式化输出
print("{0:<10}{1:>5}".format(word, count))
