Python pandas的rank()函数
转载:关于pandas的rank()函数的一点认识
原文地址:
https://zhuanlan.zhihu.com/p/87593543
一、问题:
在一张成绩表中,有班级、姓名、成绩三列,那么如何利用Python筛选出每个班级中的排名第二的学生信息?
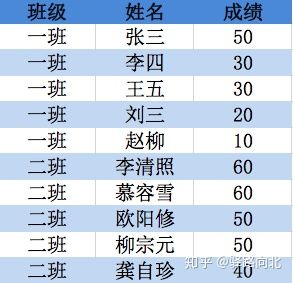
解决这个问题,有两个关键点:第一,要进行分组计算,根据班级进行分组;第二,计算排名,在每个组中计算排名,最后筛选出排名为第二的学生信息。
二、排序问题
在计算排名的场景中,对相同的成绩(例如:上图1,一班中的李四和王五同学的成绩都是30分)该如何处理它们?本人认为,一般会有三种处理方法:
(下面的介绍中,如无特别说明,均以上表中的1班的同学的成绩作为示例数据)
顺序排名,成绩相同时,谁在前,谁排名靠前(有点先到先得的意思);
图2,顺序排名中,李四和王五成绩都为30,但是李四在前,所以李四排名为2,而王五排名为3,整体的名次为1,2,3,4,5
跳跃排名,成绩相同时,排名相同,其他元素按其‘位置’排名(可参考顺序排名);
图2,跳跃排名中,李四和王五的成绩都为30,且排名都为2,但后面同学刘三、赵柳都按其出现位置进行了排名,排名分别为4和5,整体的名次,产生了跳跃,没有名次为第3的了,整体名次为:1,2,2,4,5
密集排名,成绩相同时,排名相同,其他同学依次累加(+1)。
图2,密集排名中,虽然李四和王五的成绩相同,排名相同,但后面刘三、赵柳同学都按次序依次进行了排名(+1),其整体的名次没有跳跃,变为1,2,2,3,4
示例如下:
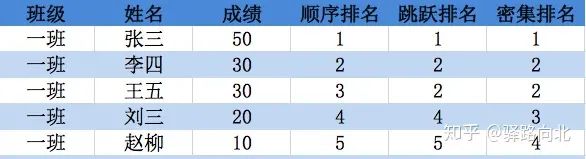
图2
那么,在Python中如何实现上述三种类型的排名,可以利用三方库pandas中的rank方法,可以通过设置rank()函数中method参数很方便的实现。
rank()函数:
DataFrame.rank(axis=0,method='average',numeric_only=None,na_option='keep',ascending=True,pct=False)
用途:沿着某个轴(0或者1)计算对象的排名
Returns:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
包含有6个参数:
axis:设置沿着哪个轴计算排名(0或者1)
numeric_only:是否仅仅计算数字型的columns,布尔值
na_option:NaN值是否参与排序及如何排序(‘keep’,‘top',’bottom')
ascending:设定升序排还是降序排
pct:是否以排名的百分比显示排名(所有排名与最大排名的百分比)
这里重点研究一下method参数 :
在本小节的开头,介绍了排名问题中的三个一般情况,即顺序排名、跳跃排名、密集排名,在rank()函数可以通过设置method的值实现上述三种排名。
method:取值可以为'average','first','min', 'max','dense',这里重点介绍一下first、min、dense
"first": 顾名思义,第一个,谁出现的位置靠前,谁的排名靠前。李四和王五的成绩都为30,但是李四出现在王五的前面,所以李四的排名靠前(当method取值为min,max,average时,都是要参考“顺序排名”的)
df['顺序排名'] = df.成绩.rank(method='first',ascending=False)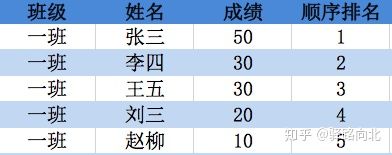
图3
"min": 当method=“min”时,成绩相同的同学,取在顺序排名中最小的那个排名作为该值的排名,李四和王五同学排名分别为2和3,那么当method为min时,取2和3的最小的那个作为第2名作为成绩30的排名。
df['跳跃排名'] = df.成绩.rank(method='min',ascending=False)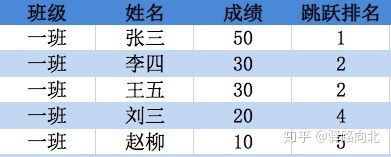
图4
"dense": 是密集的意思,即相同成绩的同学排名相同,其他依次加1即可。
df['密集排名'] = df.成绩.rank(method='dense',ascending=False)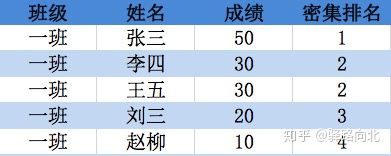
图5
备注:
关于average,成绩相同时,取顺序排名中所有名次之和除以该成绩的个数,即为该成绩的名次;比如上述排名中,30排名为2,3,那么 30的排名 = (2+3)/2=2.5,成绩为50的同学只有1个,且排名为1,那50的排名就位1/1=1。
关于max,和min一样也是跳跃排名的一种,成绩相同时取顺序排名中排名最大的作为该成绩的名次,在顺序排名中,30最大的排名为3,那么当参数为max时,30的排名=3,此时,李四和王五的排名都为第3名了。
例子:
如果不区分班级,对所有同学的成绩进行排名,不同的method值,排名情况如下:
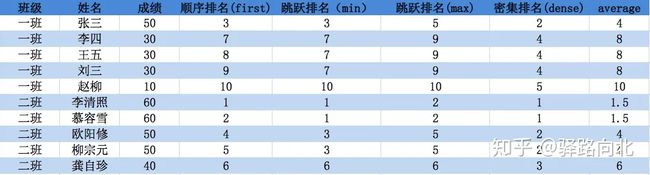
图6
三、代码
rank()函数介绍完了,怎么样利用rank()函数得到各个班级排名为第二名的学生信息呢?
这里采用密集排名,完整代码如下
def get_second(x):
return x[x.成绩.rank(method='dense', ascending=False) == 2.0]
df.groupby('班级').apply(get_second).reset_index(drop=True)
图7