爬取全国天气网,天气信息不用愁
本文介绍一个爬取全国天气网,天气信息不用愁的案例,以期阐明网络爬虫的基本方法,加深对网络爬虫的理解。
一、数据网站介绍
中央气象台网站提供了1-7天的各要素天气预报和分时段天气预报、生活指数预报信息。该网站通过气象观测数据和数值模型分析,提供了全国范围内各地区未来几天的天气预报和生活指数。用户可以通过该网站获取准确的天气预报,以便做出相应的气象决策和安排。无论是个人还是专业人士,都可以在中央气象台网站上获取可靠的天气预报信息,以帮助其日常生活或工作中的气象需求。
武汉7天天气预报和分时段天气预报
武汉7天天气预报和生活指数
二、天气预报信息爬虫的基本流程
首先对网站发起请求,获取相应内容,对返回的内容进行解析,最后就保存数据。

爬虫的基本流程图
三、爬虫相关模块安装
本案例涉及到下面几个模块,安装命令如下:
pip install requests
pip install bs4也可以使用mamba install package安装,有不明白的地方,可以参考本人已经发表的文章。
四、实现过程
第一步:导入库
import requests
from bs4 import BeautifulSoup第二步:获取网页源代码
# 2 获取网页内容
# 发送请求,获取响应
url = 'http://www.weather.com.cn/weather/101200101.shtml'
response = requests.get(url)
# 从响应中获取数据
page = response.content.decode()第三步:解析网页
1.查找天气预报信息的节点
通过分析网站返回的内容,天气预报有效信息都在 id="7d",天气预报信息的节点内。如图所示:

2.html5lib方式解析天气信息
我们使用BeautifulSoup模块对网页内容,进行html5lib方式的解析。(BeautifulSoup模块具体使用,后面有时间整理出来分享给粉丝)
查找标签:id='7d',获取标签内容,forecast_text就包含了7天天气预报和分时段天气预报)。
# 2 提取天气预报信息
# 构建bs对象
soup = BeautifulSoup(page, 'html5lib')
# print(soup)
# 查找标签
id_text = soup.find(id='7d')
# 获取标签内容
forecast_text = id_text.text3.分析forecast_text的具体天气预报信息
分析forecast_text的内容,发现7天的天气预报内容很有规律。从第7行开始,就包含第一天天气预报的内容,每个17行重复,直到7天气预报的内容展示完毕。代码实例如下:
#提取天气预报的内容
lines = forecast_text.split('\n')
for i in range(7):
ii = 6+i*17
day = lines[ii]
ii = ii + 3
ww = lines[ii]
ii = ii + 2
tt = lines[ii]
ii = ii + 7
ff = lines[ii]
print(day, ww, tt ,ff )运行后,结果如下:
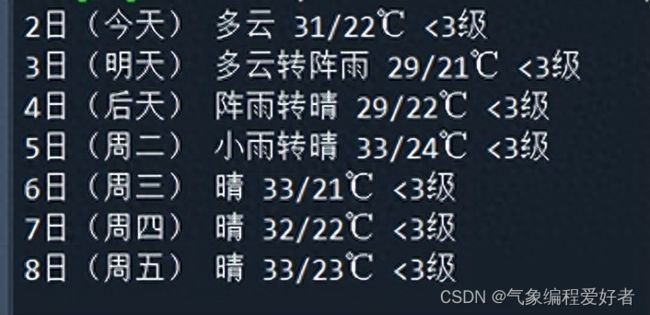
看到结果,是不是很兴奋。网络爬虫,也没有想象中的那么高大上,那么高深的理论。
4.天气预报信息的保存
获取了天气预报的结论,你想怎么保存,就按照的业务场景的需求进行保存。可参考考本人以前的发表文章,对这部分的知识有一定的讲解。保存可以保存到文件,电子表格,数据库。下面的示例是保存到文件。
file = open('day7_weather.txt','w',encoding='UTF-8')
#提取天气预报的内容
lines = forecast_text.split('\n')
for i in range(7):
ii = 6+i*17
day = lines[ii]
ii = ii + 3
ww = lines[ii]
ii = ii + 2
tt = lines[ii]
ii = ii + 7
ff = lines[ii]
print(day, ww, tt ,ff )
ww_str = day + ' '+ ww +' ' + tt + ' ' + ff + '\n'
file.write(ww_str)
file.close() 
保存的文件的截图
最后,由于平台规则,只有当您跟我有更多互动的时候,才会被认定为铁粉。如果您喜欢我的文章,可以点个“关注”,成为铁粉后能第一时间收到文章推送。