JavaScript面试题汇总
JavaScript 面试题汇总
1. 根据下面 ES6 构造函数的书写方式,要求写出 ES5 的
class Example {
constructor(name) {
this.name = name;
}
init() {
const fun = () => { console.log(this.name) }
fun();
}
}
const e = new Example('Hello');
e.init();
参考答案:
function Example(name) { 'use strict'; if (!new.target) { throw new TypeError('Class constructor cannot be invoked without new'); } this.name = name; } Object.defineProperty(Example.prototype, 'init', { enumerable: false, value: function () { 'use strict'; if (new.target) { throw new TypeError('init is not a constructor'); } var fun = function () { console.log(this.name); } fun.call(this); } })
解析:
此题的关键在于是否清楚 ES6 的 class 和普通构造函数的区别,记住它们有以下区别,就不会有遗漏:
ES6 中的 class 必须通过 new 来调用,不能当做普通函数调用,否则报错
因此,在答案中,加入了 new.target 来判断调用方式
ES6 的 class 中的所有代码均处于严格模式之下
因此,在答案中,无论是构造函数本身,还是原型方法,都使用了严格模式
ES6 中的原型方法是不可被枚举的
因此,在答案中,定义原型方法使用了属性描述符,让其不可枚举
原型上的方法不允许通过 new 来调用
因此,在答案中,原型方法中加入了 new.target 来判断调用方式
2. 数组去重有哪些方法?(美团 19 年)
参考答案:
// 数字或字符串数组去重,效率高 function unique(arr) { var result = {}; // 利用对象属性名的唯一性来保证不重复 for (var i = 0; i < arr.length; i++) { if (!result[arr[i]]) { result[arr[i]] = true; } } return Object.keys(result); // 获取对象所有属性名的数组 } // 任意数组去重,适配范围广,效率低 function unique(arr) { var result = []; // 结果数组 for (var i = 0; i < arr.length; i++) { if (!result.includes(arr[i])) { result.push(arr[i]); } } return result; } // 利用ES6的Set去重,适配范围广,效率一般,书写简单 function unique(arr) { return [...new Set(arr)] }
3. 描述下列代码的执行结果
foo(typeof a);
function foo(p) {
console.log(this);
console.log(p);
console.log(typeof b);
let b = 0;
}
参考答案:
报错,报错的位置在
console.log(typeof b);报错原因:ReferenceError: Cannot access ‘b’ before initialization
解析:
这道题考查的是 ES6 新增的声明变量关键字 let 以及暂时性死区的知识。let 和以前的 var 关键字不一样,无法在 let 声明变量之前访问到该变量,所以在 typeof b 的地方就会报错。
4. 描述下列代码的执行结果
class Foo {
constructor(arr) {
this.arr = arr;
}
bar(n) {
return this.arr.slice(0, n);
}
}
var f = new Foo([0, 1, 2, 3]);
console.log(f.bar(1));
console.log(f.bar(2).splice(1, 1));
console.log(f.arr);
参考答案:
[ 0 ]
[ 1 ]
[ 0, 1, 2, 3 ]
解析:
主要考察的是数组相关的知识。 f 对象上面有一个属性 arr,arr 的值在初始化的时候会被初始化为 [0, 1, 2, 3],之后就完全是考察数组以及数组方法的使用了。
5. 描述下列代码的执行结果
01 function f(count) {
02 console.log(`foo${count}`);
03 setTimeout(() => { console.log(`bar${count}`); });
04 }
05 f(1);
06 f(2);
07 setTimeout(() => { f(3); });
参考答案:
foo1
foo2
bar1
bar2
foo3
bar3
解析:
这个完全是考察的异步的知识。调用 f(1) 的时候,会执行同步代码,打印出 foo1,然后 03 行的 setTimeout 被放入到异步执行队列,接下来调用 f(2) 的时候,打印出 foo2,后面 03 行的 setTimeout 又被放入到异步执行队列。然后执行 07 行的语句,被放入到异步执行队列。至此,所有同步代码就都执行完毕了。
接下来开始执行异步代码,那么大家时间没写,就都是相同的,所以谁先被放入到异步队列,谁就先执行,所以先打印出 bar1、然后是 bar2,接下来执行之前 07 行放入到异步队列里面的 setTimeout,先执行 f 函数里面的同步代码,打印出 foo3,然后是最后一个异步,打印出 bar3
6. 描述下列代码的执行结果
var a = 2;
var b = 5;
console.log(a === 2 || 1 && b === 3 || 4);
参考答案:
true
考察的是逻辑运算符。在 || 里面,只要有一个为真,后面的直接短路,都不用去计算。所以 a === 2 得到 true 之后直接短路了,返回 true。
7. 描述下列代码的执行结果
export class ButtonWrapper {
constructor(domBtnEl, hash) {
this.domBtnEl = domBtnEl;
this.hash = hash;
this.bindEvent();
}
bindEvent() {
this.domBtnEl.addEventListener('click', this.clickEvent, false);
}
detachEvent() {
this.domBtnEl.removeEventListener('click', this.clickEvent);
}
clickEvent() {
console.log(`The hash of the button is: ${this.hash}`);
}
}
参考答案:
上面的代码导出了一个 ButtonWrapper 类,该类在被实例化的时候,实例化对象上面有两个属性,分别是 domBtnEl 和 hash,domBtnEl 是一个 DOM 节点,之后为这个 domBtnEl 绑定了点击事件,点击后打印出 The hash of the button is: hash 那句话。detachEvent 是移除点击事件,当调用实例化对象的 detachEvent 方法时,点击事件就会被移除。
8. 箭头函数有哪些特点
参考答案:
- 更简洁的语法,例如
- 只有一个形参就不需要用括号括起来
- 如果函数体只有一行,就不需要放到一个块中
- 如果 return 语句是函数体内唯一的语句,就不需要 return 关键字
- 箭头函数没有自己的 this,arguments,super
- 箭头函数 this 只会从自己的作用域链的上一层继承 this。
9. 说一说类的继承
参考答案:
继承是面向对象编程中的三大特性之一。
JavaScript 中的继承经过不断的发展,从最初的对象冒充慢慢发展到了今天的圣杯模式继承。
其中最需要掌握的就是伪经典继承和圣杯模式的继承。
很长一段时间,JS 继承使用的都是组合继承。这种继承也被称之为伪经典继承,该继承方式综合了原型链和盗用构造函数的方式,将两者的优点集中了起来。
组合继承弥补了之前原型链和盗用构造函数这两种方式各自的不足,是 JavaScript 中使用最多的继承方式。
组合继承最大的问题就是效率问题。最主要就是父类的构造函数始终会被调用两次:一次是在创建子类原型时调用,另一次是在子类构造函数中调用。
本质上,子类原型最终是要包含超类对象的所有实例属性,子类构造函数只要在执行时重写自己的原型就行了。
圣杯模式的继承解决了这一问题,其基本思路就是不通过调用父类构造函数来给子类原型赋值,而是取得父类原型的一个副本,然后将返回的新对象赋值给子类原型。
解析:该题主要考察就是对 js 中的继承是否了解,以及常见的继承的形式有哪些。最常用的继承就是组合继承(伪经典继承)和圣杯模式继承。下面附上 js 中这两种继承模式的详细解析。
下面是一个组合继承的例子:
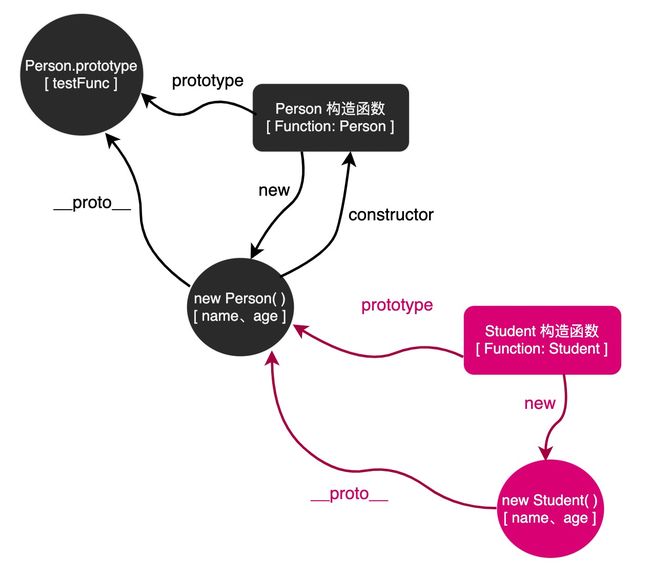
// 基类 var Person = function (name, age) { this.name = name; this.age = age; } Person.prototype.test = "this is a test"; Person.prototype.testFunc = function () { console.log('this is a testFunc'); } // 子类 var Student = function (name, age, gender, score) { Person.apply(this, [name, age]); // 盗用构造函数 this.gender = gender; this.score = score; } Student.prototype = new Person(); // 改变 Student 构造函数的原型对象 Student.prototype.testStuFunc = function () { console.log('this is a testStuFunc'); } // 测试 var zhangsan = new Student("张三", 18, "男", 100); console.log(zhangsan.name); // 张三 console.log(zhangsan.age); // 18 console.log(zhangsan.gender); // 男 console.log(zhangsan.score); // 100 console.log(zhangsan.test); // this is a test zhangsan.testFunc(); // this is a testFunc zhangsan.testStuFunc(); // this is a testStuFunc在上面的例子中,我们使用了组合继承的方式来实现继承,可以看到无论是基类上面的属性和方法,还是子类自己的属性和方法,都得到了很好的实现。
但是在组合继承中存在效率问题,比如在上面的代码中,我们其实调用了两次 Person,产生了两组 name 和 age 属性,一组在原型上,一组在实例上。
也就是说,我们在执行 Student.prototype = new Person( ) 的时候,我们是想要 Person 原型上面的方法,属性是不需要的,因为属性之后可以通过 Person.apply(this, [name, age]) 拿到,但是当你 new Person( ) 的时候,会实例化一个 Person 对象出来,这个对象上面,属性和方法都有。
圣杯模式的继承解决了这一问题,其基本思路就是不通过调用父类构造函数来给子类原型赋值,而是取得父类原型的一个副本,然后将返回的新对象赋值给子类原型。
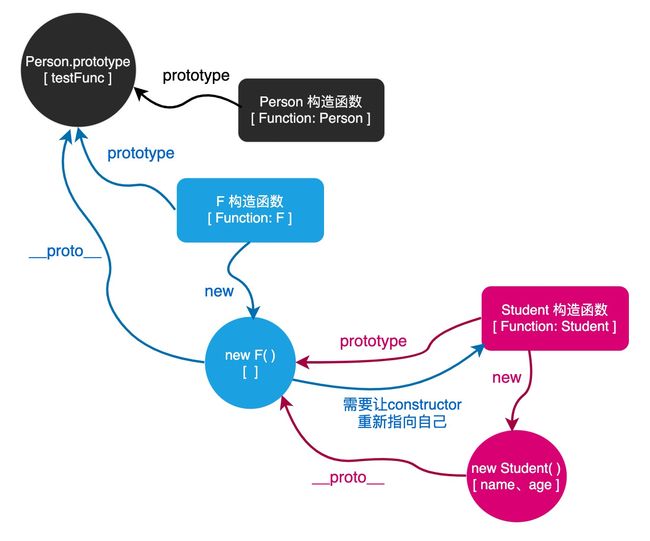
下面是一个圣杯模式的示例:
// target 是子类,origin 是基类 // target ---> Student, origin ---> Person function inherit(target, origin) { function F() { }; // 没有任何多余的属性 // origin.prototype === Person.prototype, origin.prototype.constructor === Person 构造函数 F.prototype = origin.prototype; // 假设 new F() 出来的对象叫小 f // 那么这个 f 的原型对象 === F.prototype === Person.prototype // 那么 f.constructor === Person.prototype.constructor === Person 的构造函数 target.prototype = new F(); // 而 f 这个对象又是 target 对象的原型对象 // 这意味着 target.prototype.constructor === f.constructor // 所以 target 的 constructor 会指向 Person 构造函数 // 我们要让子类的 constructor 重新指向自己 // 若不修改则会发现 constructor 指向的是父类的构造函数 target.prototype.constructor = target; } // 基类 var Person = function (name, age) { this.name = name; this.age = age; } Person.prototype.test = "this is a test"; Person.prototype.testFunc = function () { console.log('this is a testFunc'); } // 子类 var Student = function (name, age, gender, score) { Person.apply(this, [name, age]); this.gender = gender; this.score = score; } inherit(Student, Person); // 使用圣杯模式实现继承 // 在子类上面添加方法 Student.prototype.testStuFunc = function () { console.log('this is a testStuFunc'); } // 测试 var zhangsan = new Student("张三", 18, "男", 100); console.log(zhangsan.name); // 张三 console.log(zhangsan.age); // 18 console.log(zhangsan.gender); // 男 console.log(zhangsan.score); // 100 console.log(zhangsan.test); // this is a test zhangsan.testFunc(); // this is a testFunc zhangsan.testStuFunc(); // this is a testStuFunc在上面的代码中,我们在 inherit 方法中创建了一个中间层,之后让 F 的原型和父类的原型指向同一地址,再让子类的原型指向这个 F 的实例化对象来实现了继承。
这样我们的继承,属性就不会像之前那样实例对象上一份,原型对象上一份,拥有两份。圣杯模式继承是目前 js 继承的最优解。
最后我再画个图帮助大家理解,如下图:
组合模式(伪经典模式)下的继承示意图:
圣杯模式下的继承示意图:
10. new 操作符都做了哪些事?
参考答案:
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。
new 关键字会进行如下的操作:
步骤 1:创建一个空的简单 JavaScript 对象,即 { } ;
步骤 2:链接该对象到另一个对象(即设置该对象的原型对象);
步骤 3:将步骤 1 新创建的对象作为 this 的上下文;
步骤 4:如果该函数没有返回对象,则返回 this。
11. call、apply、bind 的区别 ?
参考答案:
call 和 apply 的功能相同,区别在于传参的方式不一样:
- fn.call(obj, arg1, arg2, …) 调用一个函数, 具有一个指定的 this 值和分别地提供的参数(参数的列表)。
- fn.apply(obj, [argsArray]) 调用一个函数,具有一个指定的 this 值,以及作为一个数组(或类数组对象)提供的参数。
bind 和 call/apply 有一个很重要的区别,一个函数被 call/apply 的时候,会直接调用,但是 bind 会创建一个新函数。当这个新函数被调用时,bind( ) 的第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数。
12. 事件循环机制(宏任务、微任务)
参考答案:
在 js 中任务会分为同步任务和异步任务。
如果是同步任务,则会在主线程(也就是 js 引擎线程)上进行执行,形成一个执行栈。但是一旦遇到异步任务,则会将这些异步任务交给异步模块去处理,然后主线程继续执行后面的同步代码。
当异步任务有了运行结果以后,就会在任务队列里面放置一个事件,这个任务队列由事件触发线程来进行管理。
一旦执行栈中所有的同步任务执行完毕,就代表着当前的主线程(js 引擎线程)空闲了,系统就会读取任务队列,将可以运行的异步任务添加到执行栈中,开始执行。
在 js 中,任务队列中的任务又可以被分为 2 种类型:宏任务(macrotask)与微任务(microtask)
宏任务可以理解为每次执行栈所执行的代码就是一个宏任务,包括每次从事件队列中获取一个事件回调并放到执行栈中所执行的任务。
微任务可以理解为当前宏任务执行结束后立即执行的任务。
13. 你了解 node 中的事件循环机制吗?node11 版本以后有什么改变
参考答案:
Node.js 在主线程里维护了一个事件队列,当接到请求后,就将该请求作为一个事件放入这个队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,就从线程池中拿出一个线程来处理这个事件,并指定回调函数,然后继续循环队列中的其他事件。
当线程中的 I/O 任务完成以后,就执行指定的回调函数,并把这个完成的事件放到事件队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用。 这个过程就叫 事件循环 (Event Loop)。
无论是 Linux 平台还是 Windows 平台,Node.js 内部都是通过线程池来完成异步 I/O 操作的,而 LIBUV 针对不同平台的差异性实现了统一调用。因此,Node.js 的单线程仅仅是指 JavaScript 运行在单线程中,而并非 Node.js 是单线程。
Node.JS 的事件循环分为 6 个阶段:
- timers 阶段:这个阶段执行 timer( setTimeout、setInterval )的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle、prepare 阶段:仅 Node.js 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 Node.js 将阻塞在这里
- check 阶段:执行 setImmediate( ) 的回调
- close callbacks 阶段:执行 socket 的 close 事件回调
事件循环的执行顺序为:
外部输入数据 –-> 轮询阶段( poll )-–> 检查阶段( check )-–> 关闭事件回调阶段( close callback )–-> 定时器检测阶段( timer )–-> I/O 事件回调阶段( I/O callbacks )-–>闲置阶段( idle、prepare )–->轮询阶段(按照该顺序反复运行)…
浏览器和 Node.js 环境下,微任务任务队列的执行时机不同
- Node.js 端,微任务在事件循环的各个阶段之间执行
- 浏览器端,微任务在事件循环的宏任务执行完之后执行
Node.js v11.0.0 版本于 2018 年 10 月,主要有以下变化:
- V8 引擎更新至版本 7.0
- http、https 和 tls 模块默认使用 WHESWG URL 解析器。
- 隐藏子进程的控制台窗口默认改为了 true。
- FreeBSD 10不再支持。
- 增加了多线程 Worker Threads
14. 什么是函数柯里化?
参考答案:
柯里化(currying)又称部分求值。一个柯里化的函数首先会接受一些参数,接受了这些参数之后,该函数并不会立即求值,而是继续返回另外一个函数,刚才传入的参数在函数形成的闭包中被保存起来。待到函数被真正需要求值的时候,之前传入的所有参数都会被一次性用于求值。
举个例子,就是把原本:
function(arg1,arg2) 变成 function(arg1)(arg2)
function(arg1,arg2,arg3) 变成 function(arg1)(arg2)(arg3)
function(arg1,arg2,arg3,arg4) 变成 function(arg1)(arg2)(arg3)(arg4)总而言之,就是将:
function(arg1,arg2,…,argn) 变成 function(arg1)(arg2)…(argn)
15. promise.all 方法的使用场景?数组中必须每一项都是 promise 对象吗?不是 promise 对象会如何处理 ?
参考答案:
promise.all(promiseArray) 方法是 promise 对象上的静态方法,该方法的作用是将多个 promise 对象实例包装,生成并返回一个新的 promise 实例。
此方法在集合多个 promise 的返回结果时很有用。
返回值将会按照参数内的 promise 顺序排列,而不是由调用 promise 的完成顺序决定。
promise.all 的特点
接收一个Promise实例的数组或具有Iterator接口的对象
如果元素不是Promise对象,则使用Promise.resolve转成Promise对象
如果全部成功,状态变为resolved,返回值将组成一个数组传给回调
只有有一个失败,状态就变为 rejected,返回值将直接传递给回调 *all( )*的返回值,也是新的 promise 对象
16. this 的指向哪几种 ?
参考答案:
总结起来,this 的指向规律有如下几条:
- 在函数体中,非显式或隐式地简单调用函数时,在严格模式下,函数内的 this 会被绑定到 undefined 上,在非严格模式下则会被绑定到全局对象 window/global 上。
- 一般使用 new 方法调用构造函数时,构造函数内的 this 会被绑定到新创建的对象上。
- 一般通过 call/apply/bind 方法显式调用函数时,函数体内的 this 会被绑定到指定参数的对象上。
- 一般通过上下文对象调用函数时,函数体内的 this 会被绑定到该对象上。
- 在箭头函数中,this 的指向是由外层(函数或全局)作用域来决定的。
17. JS 中继承实现的几种方式
参考答案:
JS 的继承随着语言的发展,从最早的对象冒充到现在的圣杯模式,涌现出了很多不同的继承方式。每一种新的继承方式都是对前一种继承方式不足的一种补充。
- 原型链继承
- 重点:让新实例的原型等于父类的实例。
- 特点:实例可继承的属性有:实例的构造函数的属性,父类构造函数属性,父类原型的属性。(新实例不会继承父类实例的属性!)
- 缺点:
- 1、新实例无法向父类构造函数传参。
- 2、继承单一。
- 3、所有新实例都会共享父类实例的属性。(原型上的属性是共享的,一个实例修改了原型属性,另一个实例的原型属性也会被修改!)
- 借用构造函数继承
- 重点:用 call( ) 和 apply( ) 将父类构造函数引入子类函数(在子类函数中做了父类函数的自执行(复制))
- 特点:
- 1、只继承了父类构造函数的属性,没有继承父类原型的属性。
- 2、解决了原型链继承缺点1、2、3。
- 3、可以继承多个构造函数属性(call多个)。
- 4、在子实例中可向父实例传参。
- 缺点:
- 1、只能继承父类构造函数的属性。
- 2、无法实现构造函数的复用。(每次用每次都要重新调用)
- 3、每个新实例都有父类构造函数的副本,臃肿。
- 组合模式(又被称之为伪经典模式)
- 重点:结合了两种模式的优点,传参和复用
- 特点:
- 1、可以继承父类原型上的属性,可以传参,可复用。
- 2、每个新实例引入的构造函数属性是私有的。
- 缺点:调用了两次父类构造函数(耗内存),子类的构造函数会代替原型上的那个父类构造函数。
- 寄生组合式继承(圣杯模式)
- 重点:修复了组合继承的问题
18. 什么是事件监听
参考答案:
首先需要区别清楚事件监听和事件监听器。
在绑定事件的时候,我们需要对应的书写一个事件处理程序,来应对事件发生时的具体行为。
这个事件处理程序我们也称之为事件监听器。
当事件绑定好后,程序就会对事件进行监听,当用户触发事件时,就会执行对应的事件处理程序。
关于事件监听,W3C 规范中定义了 3 个事件阶段,依次是捕获阶段、目标阶段、冒泡阶段。
捕获阶段:在事件对象到达事件目标之前,事件对象必须从 window 经过目标的祖先节点传播到事件目标。 这个阶段被我们称之为捕获阶段。在这个阶段注册的事件监听器在事件到达其目标前必须先处理事件。
目标 阶段:事件对象到达其事件目标。 这个阶段被我们称为目标阶段。一旦事件对象到达事件目标,该阶段的事件监听器就要对它进行处理。如果一个事件对象类型被标志为不能冒泡。那么对应的事件对象在到达此阶段时就会终止传播。
冒泡 阶段:事件对象以一个与捕获阶段相反的方向从事件目标传播经过其祖先节点传播到 window。这个阶段被称之为冒泡阶段。在此阶段注册的事件监听器会对相应的冒泡事件进行处理。
19. 什么是 js 的闭包?有什么作用?
参考答案:
一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。
闭包的用处:
- 匿名自执行函数
- 结果缓存
- 封装
- 实现类和继承
20. 事件委托以及冒泡原理
参考答案:
事件委托,又被称之为事件代理。在 JavaScript 中,添加到页面上的事件处理程序数量将直接关系到页面整体的运行性能。导致这一问题的原因是多方面的。
首先,每个函数都是对象,都会占用内存。内存中的对象越多,性能就越差。其次,必须事先指定所有事件处理程序而导致的 DOM 访问次数,会延迟整个页面的交互就绪时间。
对事件处理程序过多问题的解决方案就是事件委托。
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。例如,click 事件会一直冒泡到 document 层次。也就是说,我们可以为整个页面指定一个 onclick 事件处理程序,而不必给每个可单击的元素分别添加事件处理程序。
事件冒泡(event bubbling),是指事件开始时由最具体的元素(文档中嵌套层次最深的那个节点)接收,然后逐级向上传播到较为不具体的节点(文档)。
21. let const var 的区别?什么是块级作用域?如何用?
参考答案:
- var 定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问,有变量提升。
- let 定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问,无变量提升,不可以重复声明。
- const 用来定义常量,使用时必须初始化(即必须赋值),只能在块作用域里访问,而且不能修改,无变量提升,不可以重复声明。
最初在 JS 中作用域有:全局作用域、函数作用域。没有块作用域的概念。
ES6 中新增了块级作用域。块作用域由 { } 包括,if 语句和 for 语句里面的 { } 也属于块作用域。
在以前没有块作用域的时候,在 if 或者 for 循环中声明的变量会泄露成全局变量,其次就是 { } 中的内层变量可能会覆盖外层变量。块级作用域的出现解决了这些问题。
22. ES5 的方法实现块级作用域(立即执行函数) ES6 呢?
参考答案:
ES6 原生支持块级作用域。块作用域由 { } 包括,if 语句和 for 语句里面的 { } 也属于块作用域。
使用 let 声明的变量或者使用 const 声明的常量,只能在块作用域里访问,不能跨块访问。
23. ES6 箭头函数的特性
参考答案:
- 更简洁的语法,例如
- 只有一个形参就不需要用括号括起来
- 如果函数体只有一行,就不需要放到一个块中
- 如果 return 语句是函数体内唯一的语句,就不需要 return 关键字
- 箭头函数没有自己的 this,arguments,super
- 箭头函数 this 只会从自己的作用域链的上一层继承 this。
24. 箭头函数与普通函数的区别 ?
参考答案:
外形不同。箭头函数使用箭头定义,普通函数中没有
普通函数可以有匿名函数,也可以有具体名函数,但是箭头函数都是匿名函数。
**箭头函数不能用于构造函数,不能使用 new,**普通函数可以用于构造函数,以此创建对象实例。
**箭头函数中 this 的指向不同,**在普通函数中,this 总是指向调用它的对象,如果用作构造函数,this 指向创建的对象实例。
箭头函数本身不创建 this,也可以说箭头函数本身没有 this,但是它在声明时可以捕获其所在上下文的 this 供自己使用。每一个普通函数调用后都具有一个 arguments 对象,用来存储实际传递的参数。
但是箭头函数并没有此对象。取而代之用rest参数来解决。
箭头函数不能用于 Generator 函数,不能使用 yeild 关键字。
箭头函数不具有 prototype 原型对象。而普通函数具有 prototype 原型对象。
箭头函数不具有 super。
箭头函数不具有 new.target。
25. JS 的基本数据类型有哪些?基本数据类型和引用数据类型的区别
参考答案:
在 JavaScript 中,数据类型整体上来讲可以分为两大类:基本类型和引用数据类型
基本数据类型,一共有 8 种:
string,symbol,number,boolean,undefined,null,bigInt其中 symbol、bigInt 类型是在 ES6 及后续版本里面新添加的基本数据类型。
引用数据类型,就只有 1 种:
object基本数据类型的值又被称之为原始值或简单值,而引用数据类型的值又被称之为复杂值或引用值。
两者的区别在于:
原始值是表示 JavaScript 中可用的数据或信息的最底层形式或最简单形式。简单类型的值被称为原始值,是因为它们是不可细化的。
也就是说,数字是数字,字符是字符,布尔值是 true 或 false,null 和 undefined 就是 null 和 undefined。这些值本身很简单,不能够再进行拆分。由于原始值的数据大小是固定的,所以原始值的数据是存储于内存中的栈区里面的。
在 JavaScript 中,对象就是一个引用值。因为对象可以向下拆分,拆分成多个简单值或者复杂值。引用值在内存中的大小是未知的,因为引用值可以包含任何值,而不是一个特定的已知值,所以引用值的数据都是存储于堆区里面。
最后总结一下两者的区别:
访问方式
- 原始值:访问到的是值
- 引用值:访问到的是引用地址
比较方式
- 原始值:比较的是值
- 引用值:比较的是地址
动态属性
- 原始值:无法添加动态属性
- 引用值:可以添加动态属性
变量赋值
- 原始值:赋值的是值
- 引用值:赋值的是地址
26. NaN 是什么的缩写
参考答案:
NaN 的全称为 Not a Number,表示非数,或者说不是一个数。虽然 NaN 表示非数,但是它却属于 number 类型。
NaN 有两个特点:
- 任何涉及 NaN 的操作都会返回 NaN
- NaN 和任何值都不相等,包括它自己本身
27. JS 的作用域类型
参考答案:
在 JavaScript 里面,作用域一共有 4 种:全局作用域,局部作用域、函数作用域以及 eval 作用域。
**全局作用域:**这个是默认的代码运行环境,一旦代码被载入,引擎最先进入的就是这个环境。
**局部作用域:**当使用 let 或者 const 声明变量时,这些变量在一对花括号中存在局部作用域,只能够在花括号内部进行访问使用。
**函数作用域:**当进入到一个函数的时候,就会产生一个函数作用域。函数作用域里面所声明的变量只在函数中提供访问使用。
**eval 作用域:**当调用 eval( ) 函数的时候,就会产生一个 eval 作用域。
28. undefined==null 返回的结果是什么?undefined 与 null 的区别在哪?
参考答案:
返回 true。
这两个值都表示“无”的意思。
通常情况下, 当我们试图访问某个不存在的或者没有赋值的变量时,就会得到一个 undefined 值。Javascript 会自动将声明是没有进行初始化的变量设为 undifined。
而 null 值表示空,null 不能通过 Javascript 来自动赋值,也就是说必须要我们自己手动来给某个变量赋值为 null。
解析:
那么为什么 JavaScript 要设置两个表示"无"的值呢?这其实是历史原因。
1995 年 JavaScript 诞生时,最初像 Java 一样,只设置了 null 作为表示"无"的值。根据 C 语言的传统,null 被设计成可以自动转为0。
但是,JavaScript 的设计者,觉得这样做还不够,主要有以下两个原因。
- null 像在 Java 里一样,被当成一个对象。但是,JavaScript 的数据类型分成原始类型(primitive)和合成类型(complex)两大类,作者觉得表示"无"的值最好不是对象。
- JavaScript 的最初版本没有包括错误处理机制,发生数据类型不匹配时,往往是自动转换类型或者默默地失败。作者觉得,如果 null 自动转为 0,很不容易发现错误。
因此,作者又设计了一个 undefined。
这里注意:先有 null 后有 undefined 出来,undefined 是为了填补之前的坑。
JavaScript 的最初版本是这样区分的:
null 是一个表示"无"的对象(空对象指针),转为数值时为 0;
典型用法是:
作为函数的参数,表示该函数的参数不是对象。
作为对象原型链的终点。
undefined 是一个表示"无"的原始值,转为数值时为 NaN。
典型用法是:
- 变量被声明了,但没有赋值时,就等于 undefined。
- 调用函数时,应该提供的参数没有提供,该参数等于 undefined。
- 对象没有赋值的属性,该属性的值为 undefined。
- 函数没有返回值时,默认返回 undefined。
29. 写一个函数判断变量类型
参考答案:
function getType(data){ let type = typeof data; if(type !== "object"){ return type } return Object.prototype.toString.call(data).replace(/^\[object (\S+)\]$/,'$1') } function Person(){} console.log(getType(1)); // number console.log(getType(true)); // boolean console.log(getType([1,2,3])); // Array console.log(getType(/abc/)); // RegExp console.log(getType(new Date)); // Date console.log(getType(new Person)); // Object console.log(getType({})); // Object
30. js 的异步处理函数
参考答案:
在最早期的时候,JavaScript 中要实现异步操作,使用的就是 Callback 回调函数。
但是回调函数会产生回调地狱(Callback Hell)
之后 ES6 推出了 Promise 解决方案来解决回调地狱的问题。不过,虽然 Promise 作为 ES6 中提供的一种新的异步编程解决方案,但是它也有问题。比如,代码并没有因为新方法的出现而减少,反而变得更加复杂,同时理解难度也加大。
之后,就出现了基于 Generator 的异步解决方案。不过,这种方式需要编写外部的执行器,而执行器的代码写起来一点也不简单。当然也可以使用一些插件,比如 co 模块来简化执行器的编写。
ES7 提出的 async 函数,终于让 JavaScript 对于异步操作有了终极解决方案。
实际上,async 只是生成器的一种语法糖而已,简化了外部执行器的代码,同时利用 await 替代 yield,async 替代生成器的
*号。
31. defer 与 async 的区别
参考答案:
按照惯例,所有 script 元素都应该放在页面的 head 元素中。这种做法的目的就是把所有外部文件(CSS 文件和 JavaScript 文件)的引用都放在相同的地方。可是,在文档的 head 元素中包含所有 JavaScript 文件,意味着必须等到全部 JavaScript 代码都被下载、解析和执行完成以后,才能开始呈现页面的内容(浏览器在遇到 body 标签时才开始呈现内容)。
对于那些需要很多 JavaScript 代码的页面来说,这无疑会导致浏览器在呈现页面时出现明显的延迟,而延迟期间的浏览器窗口中将是一片空白。为了避免这个问题,现在 Web 应用程序一般都全部 JavaScript 引用放在 body 元素中页面的内容后面。这样一来,在解析包含的 JavaScript 代码之前,页面的内容将完全呈现在浏览器中。而用户也会因为浏览器窗口显示空白页面的时间缩短而感到打开页面的速度加快了。
有了 defer 和 async 后,这种局面得到了改善。
defer (延迟脚本)
延迟脚本:defer 属性只适用于外部脚本文件。
如果给 script 标签定义了defer 属性,这个属性的作用是表明脚本在执行时不会影响页面的构造。也就是说,脚本会被延迟到整个页面都解析完毕后再运行。因此,如果 script 元素中设置了 defer 属性,相当于告诉浏览器立即下载,但延迟执行。
async(异步脚本)
异步脚本:async 属性也只适用于外部脚本文件,并告诉浏览器立即下载文件。
但与 defer 不同的是:标记为 async 的脚本并不保证按照指定它们的先后顺序执行。
所以总结起来,两者之间最大的差异就是在于脚本下载完之后何时执行,显然 defer 是最接近我们对于应用脚本加载和执行的要求的。
defer 是立即下载但延迟执行,加载后续文档元素的过程将和脚本的加载并行进行(异步),但是脚本的执行要在所有元素解析完成之后,DOMContentLoaded 事件触发之前完成。async 是立即下载并执行,加载和渲染后续文档元素的过程将和 js 脚本的加载与执行并行进行(异步)。
32. 浏览器事件循环和任务队列
参考答案:
JavaScript 的异步机制由事件循环和任务队列构成。
JavaScript 本身是单线程语言,所谓异步依赖于浏览器或者操作系统等完成。JavaScript 主线程拥有一个执行栈以及一个任务队列,主线程会依次执行代码,当遇到函数时,会先将函数入栈,函数运行完毕后再将该函数出栈,直到所有代码执行完毕。
遇到异步操作(例如:setTimeout、Ajax)时,异步操作会由浏览器(OS)执行,浏览器会在这些任务完成后,将事先定义的回调函数推入主线程的任务队列(task queue)中,当主线程的执行栈清空之后会读取任务队列中的回调函数,当任务队列被读取完毕之后,主线程接着执行,从而进入一个无限的循环,这就是事件循环。
33. 原型与原型链 (美团 19年)
参考答案:
- 每个对象都有一个
__proto__属性,该属性指向自己的原型对象- 每个构造函数都有一个
prototype属性,该属性指向实例对象的原型对象- 原型对象里的
constructor指向构造函数本身如下图:
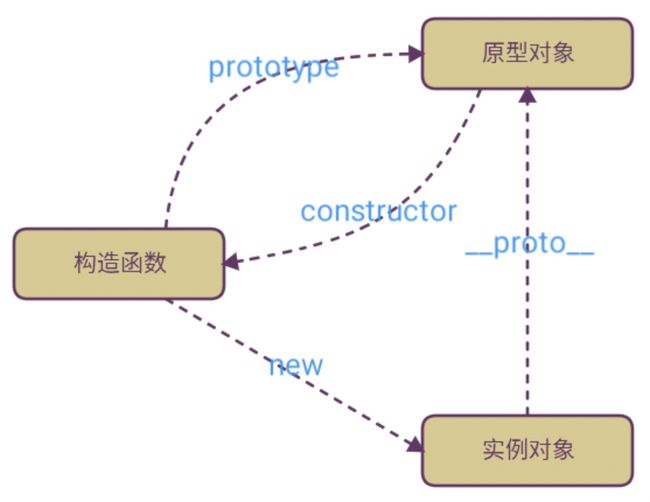
每个对象都有自己的原型对象,而原型对象本身,也有自己的原型对象,从而形成了一条原型链条。
当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索,直到找到一个名字匹配的属性或到达原型链的末尾。
34. 作用域与作用域链 (美团 19年)
参考答案:
作用域是在运行时代码中的某些特定部分中变量,函数和对象的可访问性。换句话说,作用域决定了代码区块中变量和其他资源的可见性。ES6 之前 JavaScript 没有块级作用域,只有全局作用域和函数作用域。ES6 的到来,为我们提供了块级作用域。
作用域链指的是作用域与作用域之间形成的链条。当我们查找一个当前作用域没有定义的变量(自由变量)的时候,就会向上一级作用域寻找,如果上一级也没有,就再一层一层向上寻找,直到找到全局作用域还是没找到,就宣布放弃。这种一层一层的关系,就是作用域链 。
35. 闭包及应用场景以及闭包缺点 (美团 19年)
参考答案:
闭包的应用场景:
- 匿名自执行函数
- 结果缓存
- 封装
- 实现类和继承
闭包的缺点:
因为闭包的作用域链会引用包含它的函数的活动对象,导致这些活动对象不会被销毁,因此会占用更多的内存。
36. 继承方式 (美团 19年)
参考答案:
参阅前面第 9 题以及第 18 题答案。
37. 原始值与引用值 (美团 19年)
参考答案:
原始值是表示 JavaScript 中可用的数据或信息的最底层形式或最简单形式。简单类型的值被称为原始值,是因为它们是不可细化的。
也就是说,数字是数字,字符是字符,布尔值是 true 或 false,null 和 undefined 就是 null 和 undefined。这些值本身很简单,不能够再进行拆分。由于原始值的数据大小是固定的,所以原始值的数据是存储于内存中的栈区里面的。
在 JavaScript 中,对象就是一个引用值。因为对象可以向下拆分,拆分成多个简单值或者复杂值。引用值在内存中的大小是未知的,因为引用值可以包含任何值,而不是一个特定的已知值,所以引用值的数据都是存储于堆区里面。
最后总结一下两者的区别:
访问方式
- 原始值:访问到的是值
- 引用值:访问到的是引用地址
比较方式
- 原始值:比较的是值
- 引用值:比较的是地址
动态属性
- 原始值:无法添加动态属性
- 引用值:可以添加动态属性
变量赋值
- 原始值:赋值的是值
- 引用值:赋值的是地址
38. 描述下列代码的执行结果
const first = () => (new Promise((resolve, reject) => {
console.log(3);
let p = new Promise((resolve, reject) => {
console.log(7);
setTimeout(() => {
console.log(1);
}, 0);
setTimeout(() => {
console.log(2);
resolve(3);
}, 0)
resolve(4);
});
resolve(2);
p.then((arg) => {
console.log(arg, 5); // 1 bb
});
setTimeout(() => {
console.log(6);
}, 0);
}))
first().then((arg) => {
console.log(arg, 7); // 2 aa
setTimeout(() => {
console.log(8);
}, 0);
});
setTimeout(() => {
console.log(9);
}, 0);
console.log(10);
参考答案:
3
7
10
4 5
2 7
1
2
6
9
8
39. 如何判断数组或对象(美团 19年)
参考答案:
- 通过 instanceof 进行判断
var arr = [1,2,3,1]; console.log(arr instanceof Array) // true
- 通过对象的 constructor 属性
var arr = [1,2,3,1]; console.log(arr.constructor === Array) // true
- Object.prototype.toString.call(arr)
console.log(Object.prototype.toString.call({name: "jerry"}));//[object Object] console.log(Object.prototype.toString.call([]));//[object Array]
- 可以通过 ES6 新提供的方法 Array.isArray( )
Array.isArray([]) //true
40. 对象深拷贝与浅拷贝,单独问了 Object.assign(美团 19年)
参考答案:
浅拷贝:只是拷贝了基本类型的数据,而引用类型数据,复制后也是会发生引用,我们把这种拷贝叫做浅拷贝(浅复制)
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。
深拷贝:在堆中重新分配内存,并且把源对象所有属性都进行新建拷贝,以保证深拷贝的对象的引用图不包含任何原有对象或对象图上的任何对象,拷贝后的对象与原来的对象是完全隔离,互不影响。
Object.assign 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。但是 Object.assign 方法进行的是浅拷贝,拷贝的是对象的属性的引用,而不是对象本身。
42. 说说 instanceof 原理,并回答下面的题目(美团 19年)
function A(){}
function B(){}
A.prototype = new B();
let a = new A();
console.log(a instanceof B) // true of false ?
参考答案:
答案为 true。
instanceof 原理:
instanceof 用于检测一个对象是否为某个构造函数的实例。
例如:A instanceof B
instanceof 用于检测对象 A 是不是 B 的实例,而检测是基于原型链进行查找的,也就是说 B 的 prototype 有没有在对象 A 的__proto__ 原型链上,如果有就返回 true,否则返回 false
43. 内存泄漏(美团 19 年)
参考答案:
内存泄漏(Memory Leak)是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
Javascript 是一种高级语言,它不像 C 语言那样要手动申请内存,然后手动释放,Javascript 在声明变量的时候自动会分配内存,普通的类型比如 number,一般放在栈内存里,对象放在堆内存里,声明一个变量,就分配一些内存,然后定时进行垃圾回收。垃圾回收的任务由 JavaScript 引擎中的垃圾回收器来完成,它监视所有对象,并删除那些不可访问的对象。
基本的垃圾回收算法称为**“标记-清除”**,定期执行以下“垃圾回收”步骤:
- 垃圾回收器获取根并**“标记”**(记住)它们。
- 然后它访问并“标记”所有来自它们的引用。
- 然后它访问标记的对象并标记它们的引用。所有被访问的对象都被记住,以便以后不再访问同一个对象两次。
- 以此类推,直到有未访问的引用(可以从根访问)为止。
- 除标记的对象外,所有对象都被删除。
44. ES6 新增哪些东西?让你自己说(美团 19 年)
参考答案:
ES6 新增内容众多,这里列举出一些关键的以及平时常用的新增内容:
- 箭头函数
- 字符串模板
- 支持模块化(import、export)
- 类(class、constructor、extends)
- let、const 关键字
- 新增一些数组、字符串等内置构造函数方法,例如 Array.from、Array.of 、Math.sign、Math.trunc 等
- 新增一些语法,例如扩展操作符、解构、函数默认参数等
- 新增一种基本数据类型 Symbol
- 新增元编程相关,例如 proxy、Reflect
- Set 和 Map 数据结构
- Promise
- Generator 生成器
45. weakmap、weakset(美团 19 年)
参考答案:
WeakSet 对象是一些对象值的集合, 并且其中的每个对象值都只能出现一次。在 WeakSet 的集合中是唯一的
它和 Set 对象的区别有两点:
- 与 Set 相比,WeakSet 只能是对象的集合,而不能是任何类型的任意值。
- WeakSet 持弱引用:集合中对象的引用为弱引用。 如果没有其他的对 WeakSet 中对象的引用,那么这些对象会被当成垃圾回收掉。 这也意味着 WeakSet 中没有存储当前对象的列表。 正因为这样,WeakSet 是不可枚举的。
WeakMap 对象也是键值对的集合。它的键必须是对象类型,值可以是任意类型。它的键被弱保持,也就是说,当其键所指对象没有其他地方引用的时候,它会被 GC 回收掉。WeakMap 提供的接口与 Map 相同。
与 Map 对象不同的是,WeakMap 的键是不可枚举的。不提供列出其键的方法。列表是否存在取决于垃圾回收器的状态,是不可预知的。
46. 为什么 ES6 会新增 Promise(美团 19年)
参考答案:
在 ES6 以前,解决异步的方法是回调函数。但是回调函数有一个最大的问题就是回调地狱(callback hell),当我们的回调函数嵌套的层数过多时,就会导致代码横向发展。
Promise 的出现就是为了解决回调地狱的问题。
47. ES5 实现继承?(虾皮)
参考答案:
- 借用构造函数实现继承
function Parent1(){ this.name = "parent1" } function Child1(){ Parent1.call(this); this.type = "child1"; }缺点:Child1 无法继承 Parent1 的原型对象,并没有真正的实现继承 (部分继承)。
- 借用原型链实现继承
function Parent2(){ this.name = "parent2"; this.play = [1,2,3]; } function Child2(){ this.type = "child2"; } Child2.prototype = new Parent2();缺点:原型对象的属性是共享的。
- 组合式继承
function Parent3(){ this.name = "parent3"; this.play = [1,2,3]; } function Child3(){ Parent3.call(this); this.type = "child3"; } Child3.prototype = Object.create(Parent3.prototype); Child3.prototype.constructor = Child3;
48. 科里化?(搜狗)
参考答案:
柯里化,英语全称 Currying,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
举个例子,就是把原本:
function(arg1,arg2) 变成 function(arg1)(arg2)
function(arg1,arg2,arg3) 变成 function(arg1)(arg2)(arg3)
function(arg1,arg2,arg3,arg4) 变成 function(arg1)(arg2)(arg3)(arg4)总而言之,就是将:
function(arg1,arg2,…,argn) 变成 function(arg1)(arg2)…(argn)
49. 防抖和节流?(虾皮)
参考答案:
我们在平时开发的时候,会有很多场景会频繁触发事件,比如说搜索框实时发请求,onmousemove、resize、onscroll 等,有些时候,我们并不能或者不想频繁触发事件,这时候就应该用到函数防抖和函数节流。
函数防抖(debounce),指的是短时间内多次触发同一事件,只执行最后一次,或者只执行最开始的一次,中间的不执行。
函数节流(throttle),指连续触发事件但是在 n 秒中只执行一次函数。即 2n 秒内执行 2 次… 。节流如字面意思,会稀释函数的执行频率。
50. 闭包?(好未来—探讨了 40 分钟)
参考答案:
请参阅前面第 20 题以及第 36 题答案。
51. 原型和原型链?(字节)
参考答案:
请参阅前面第 34 题答案。
52. 排序算法—(时间复杂度、空间复杂度)
参考答案:
算法(Algorithm)是指用来操作数据、解决程序问题的一组方法。对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,但在过程中消耗的资源和时间却会有很大的区别。
主要还是从算法所占用的「时间」和「空间」两个维度去考量。
- 时间维度:是指执行当前算法所消耗的时间,我们通常用「时间复杂度」来描述。
- 空间维度:是指执行当前算法需要占用多少内存空间,我们通常用「空间复杂度」来描述。
因此,评价一个算法的效率主要是看它的时间复杂度和空间复杂度情况。然而,有的时候时间和空间却又是「鱼和熊掌」,不可兼得的,那么我们就需要从中去取一个平衡点。
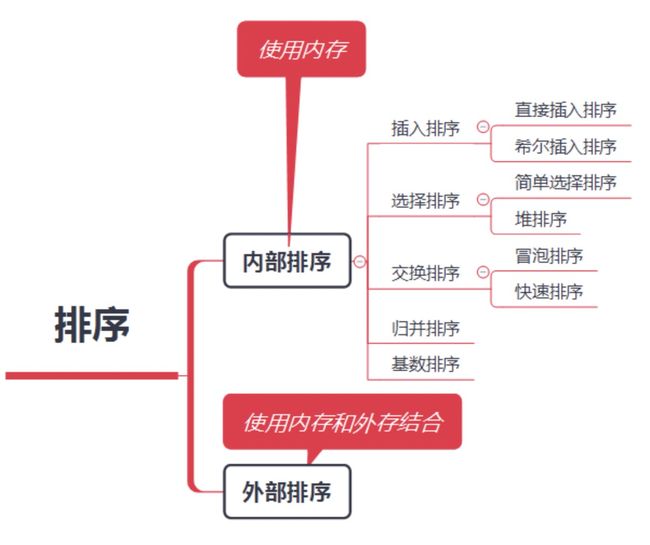
排序也称排序算法(Sort Algorithm),排序是将一组数据,依指定的顺序进行排列的过程。
排序的分类分为内部排序和外部排序法。
- 内部排序:指将需要处理的所有数据都加载到**内部存储器(内存)**中进行排序。
- 外部排序:数据量过大,无法全部加载到内存中,需要借助**外部存储(文件等)**进行排序。
53. 浏览器事件循环和 node 事件循环(搜狗)
参考答案:
- 浏览器中的 Event Loop
事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。宏任务队列可以有多个,微任务队列只有一个。
- 常见的 macro-task 比如:setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作、UI 渲染等。
- 常见的 micro-task 比如: process.nextTick、new Promise( ).then(回调)、MutationObserver(html5 新特性) 等。
当某个宏任务执行完后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,会读取宏任务队列中排在最前的任务,执行宏任务的过程中,遇到微任务,依次加入微任务队列。栈空后,再次读取微任务队列里的任务,依次类推。
- Node 中的事件循环
Node 中的 Event Loop 和浏览器中的是完全不相同的东西。Node.js 采用 V8 作为 js 的解析引擎,而 I/O 处理方面使用了自己设计的 libuv,libuv 是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的 API,事件循环机制也是它里面的实现。
Node.JS 的事件循环分为 6 个阶段:
- timers 阶段:这个阶段执行 timer( setTimeout、setInterval )的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle、prepare 阶段:仅 Node.js 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 Node.js 将阻塞在这里
- check 阶段:执行 setImmediate( ) 的回调
- close callbacks 阶段:执行 socket 的 close 事件回调
Node.js 的运行机制如下:
- V8 引擎解析 JavaScript 脚本。
- 解析后的代码,调用 Node API。
- libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
- V8 引擎再将结果返回给用户。
54. 闭包的好处
参考答案:
请参阅前面第 20 题以及第 36 题答案。
55. let、const、var 的区别
参考答案:
- var 定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问,有变量提升。
- let 定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问,无变量提升,不可以重复声明。
- const 用来定义常量,使用时必须初始化(即必须赋值),只能在块作用域里访问,而且不能修改,无变量提升,不可以重复声明。
56. 闭包、作用域(可以扩充到作用域链)
参考答案:
什么是作业域?
ES5 中只存在两种作用域:全局作用域和函数作用域。在 JavaScript 中,我们将作用域定义为一套规则,这套规则用来管理引擎如何在当前作用域以及嵌套子作用域中根据标识符名称进行变量(变量名或者函数名)查找。
什么是作用域链?
当访问一个变量时,编译器在执行这段代码时,会首先从当前的作用域中查找是否有这个标识符,如果没有找到,就会去父作用域查找,如果父作用域还没找到继续向上查找,直到全局作用域为止,,而作用域链,就是有当前作用域与上层作用域的一系列变量对象组成,它保证了当前执行的作用域对符合访问权限的变量和函数的有序访问。
闭包产生的本质
当前环境中存在指向父级作用域的引用
什么是闭包
闭包是一种特殊的对象,它由两部分组成:执行上下文(代号 A),以及在该执行上下文中创建的函数 (代号 B),当 B 执行时,如果访问了 A 中变量对象的值,那么闭包就会产生,且在 Chrome 中使用这个执行上下文 A 的函数名代指闭包。
一般如何产生闭包
- 返回函数
- 函数当做参数传递
闭包的应用场景
- 柯里化 bind
- 模块
57. Promise
参考答案:
Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理且更强大。它最早由社区提出并实现,ES6将其写进了语言标准,统一了用法,并原生提供了Promise对象。
特点
对象的状态不受外界影响 (3 种状态)
Pending 状态(进行中)
Fulfilled 状态(已成功)
Rejected 状态(已失败)
一旦状态改变就不会再变 (两种状态改变:成功或失败)
- Pending -> Fulfilled
- Pending -> Rejected
用法
var promise = new Promise(function(resolve, reject){ // ... some code if (/* 异步操作成功 */) { resolve(value); } else { reject(error); } })
58. 实现一个函数,对一个url进行请求,失败就再次请求,超过最大次数就走失败回调,任何一次成功都走成功回调
参考答案:
示例代码如下:
/** @params url: 请求接口地址; @params body: 设置的请求体; @params succ: 请求成功后的回调 @params error: 请求失败后的回调 @params maxCount: 设置请求的数量 */ function request(url, body, succ, error, maxCount = 5) { return fetch(url, body) .then(res => succ(res)) .catch(err => { if (maxCount <= 0) return error('请求超时'); return request(url, body, succ, error, --maxCount); }); } // 调用请求函数 request('https://java.some.com/pc/reqCount', { method: 'GET', headers: {} }, (res) => { console.log(res.data); }, (err) => { console.log(err); })
59. 冒泡排序
参考答案:
冒泡排序的核心思想是:
- 比较相邻的两个元素,如果前一个比后一个大或者小(取决于排序的顺序是小到大还是大到小),则交换位置。
- 比较完第一轮的时候,最后一个元素是最大或最小的元素。
- 这时候最后一个元素已经是最大或最小的了,所以下一次冒泡的时候最后一个元素不需要参与比较。
示例代码:
function bSort(arr) { var len = arr.length; // 外层 for 循环控制冒泡的次数 for (var i = 0; i < len - 1; i++) { for (var j = 0; j < len - 1 - i; j++) { // 内层 for 循环控制每一次冒泡需要比较的次数 // 因为之后每一次冒泡的两两比较次数会越来越少,所以 -i if (arr[j] > arr[j + 1]) { var temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } return arr; } //举个数组 myArr = [20, -1, 27, -7, 35]; //使用函数 console.log(bSort(myArr)); // [ -7, -1, 20, 27, 35 ]
60. 数组降维
参考答案:
数组降维就是将一个嵌套多层的数组进行降维操作,也就是对数组进行扁平化。在 ES5 时代我们需要自己手写方法或者借助函数库来完成,但是现在可以使用 ES6 新提供的数组方法 flat 来完成数组降维操作。
解析:使用 flat 方法会接收一个参数,这个参数是数值类型,是要处理扁平化数组的深度,生成后的新数组是独立存在的,不会对原数组产生影响。
flat 方法的语法如下:
var newArray = arr.flat([depth])其中 depth 指定要提取嵌套数组结构的深度,默认值为 1。
示例如下:
var arr = [1, 2, [3, 4, [5, 6]]]; console.log(arr.flat()); // [1, 2, 3, 4, [5, 6]] console.log(arr.flat(2)); // [1, 2, 3, 4, 5, 6]上面的代码定义了一个层嵌套的数组,默认情况下只会拍平一层数组,也就是把原来的三维数组降低到了二维数组。在传入的参数为 2 时,则会降低两维,成为一个一维数组。
使用 Infinity,可展开任意深度的嵌套数组,示例如下:
var arr = [1, 2, [3, 4, [5, 6, [7, 8]]]]; console.log(arr.flat(Infinity)); // [1, 2, 3, 4, 5, 6, 7, 8]在数组中有空项的时候,使用 flat 方法会将中的空项进行移除。
var arr = [1, 2, , 4, 5]; console.log(arr.flat()); // [1, 2, 4, 5]上面的代码中,数组中第三项是空值,在使用 flat 后会对空项进行移除。
61. call apply bind
参考答案:
请参阅前面第 11 题答案。
62. promise 代码题
new Promise((resolve, reject) => {
reject(1);
console.log(2);
resolve(3);
console.log(4);
}).then((res) => { console.log(res) })
.catch(res => { console.log('reject1') })
try {
new Promise((resolve, reject) => {
throw 'error'
}).then((res) => { console.log(res) })
.catch(res => { console.log('reject2') })
} catch (err) {
console.log(err)
}
参考答案:
2
4
reject1
reject2直播课或者录播课进行解析。
63. proxy 是实现代理,可以改变 js 底层的实现方式, 然后说了一下和 Object.defineProperty 的区别
参考答案:
两者的区别总结如下:
- 代理原理:Object.defineProperty的原理是通过将数据属性转变为存取器属性的方式实现的属性读写代理。而Proxy则是因为这个内置的Proxy对象内部有一套监听机制,在传入handler对象作为参数构造代理对象后,一旦代理对象的某个操作触发,就会进入handler中对应注册的处理函数,此时我们就可以有选择的使用Reflect将操作转发被代理对象上。
- 代理局限性:Object.defineProperty始终还是局限于属性层面的读写代理,对于对象层面以及属性的其它操作代理它都无法实现。鉴于此,由于数组对象push、pop等方法的存在,它对于数组元素的读写代理实现的并不完全。而使用Proxy则可以很方便的监视数组操作。
- 自我代理:Object.defineProperty方式可以代理到自身(代理之后使用对象本身即可),也可以代理到别的对象身上(代理之后需要使用代理对象)。Proxy方式只能代理到Proxy实例对象上。这一点在其它说法中是Proxy对象不需要侵入对象就可以实现代理,实际上Object.defineProperty方式也可以不侵入。
64. 使用 ES5 与 ES6 分别实现继承
参考答案:
如果是使用 ES5 来实现继承,那么现在的最优解是使用圣杯模式。圣杯模式的核心思想就是不通过调用父类构造函数来给子类原型赋值,而是取得父类原型的一个副本,然后将返回的新对象赋值给子类原型。具体代码可以参阅前面第 9 题的解析。
ES6 新增了 extends 关键字,直接使用该关键字就能够实现继承。
65. 深拷贝
参考答案:
有深拷贝就有浅拷贝。
浅拷贝就是只拷贝对象的引用,而不深层次的拷贝对象的值,多个对象指向堆内存中的同一对象,任何一个修改都会使得所有对象的值修改,因为它们共用一条数据。
深拷贝不是单纯的拷贝一份引用数据类型的引用地址,而是将引用类型的值全部拷贝一份,形成一个新的引用类型,这样就不会发生引用错乱的问题,使得我们可以多次使用同样的数据,而不用担心数据之间会起冲突。
解析:
「深拷贝」就是在拷贝数据的时候,将数据的所有引用结构都拷贝一份。简单的说就是,在内存中存在两个数据结构完全相同又相互独立的数据,将引用型类型进行复制,而不是只复制其引用关系。
分析下怎么做「深拷贝」:
- 首先假设深拷贝这个方法已经完成,为 deepClone
- 要拷贝一个数据,我们肯定要去遍历它的属性,如果这个对象的属性仍是对象,继续使用这个方法,如此往复
function deepClone(o1, o2) { for (let k in o2) { if (typeof o2[k] === 'object') { o1[k] = {}; deepClone(o1[k], o2[k]); } else { o1[k] = o2[k]; } } } // 测试用例 let obj = { a: 1, b: [1, 2, 3], c: {} }; let emptyObj = Object.create(null); deepClone(emptyObj, obj); console.log(emptyObj.a == obj.a); console.log(emptyObj.b == obj.b);递归容易造成爆栈,尾部调用可以解决递归的这个问题,Chrome 的 V8 引擎做了尾部调用优化,我们在写代码的时候也要注意尾部调用写法。递归的爆栈问题可以通过将递归改写成枚举的方式来解决,就是通过 for 或者 while 来代替递归。
66. async 与 await 的作用
参考答案:
async 是一个修饰符,async 定义的函数会默认的返回一个 Promise 对象 resolve 的值,因此对 async 函数可以直接进行 then 操作,返回的值即为 then 方法的传入函数。
await 关键字只能放在 async 函数内部, await 关键字的作用就是获取 Promise 中返回的内容, 获取的是 Promise 函数中 resolve 或者 reject 的值。
67. 数据的基础类型(原始类型)有哪些
参考答案:
JavaScript 中的基础数据类型,一共有 7 种:
string,symbol,number,boolean,undefined,null,bigInt
68. typeof null 返回结果
参考答案:
返回 object
解析:至于为什么会返回 object,这实际上是来源于 JavaScript 从第一个版本开始时的一个 bug,并且这个 bug 无法被修复。修复会破坏现有的代码。
原理这是这样的,不同的对象在底层都表现为二进制,在 JavaScript 中二进制前三位都为 0 的话会被判断为 object 类型,null 的二进制全部为 0,自然前三位也是 0,所以执行 typeof 值会返回 object。
69. 对变量进行类型判断的方式有哪些
参考答案:
常用的方法有 4 种:
- typeof
typeof 是一个操作符,其右侧跟一个一元表达式,并返回这个表达式的数据类型。返回的结果用该类型的字符串(全小写字母)形式表示,包括以下 7 种:number、boolean、symbol、string、object、undefined、function 等。
- instanceof
instanceof 是用来判断 A 是否为 B 的实例,表达式为:A instanceof B,如果 A 是 B 的实例,则返回 true,否则返回 false。 在这里需要特别注意的是:instanceof 检测的是原型。
- constructor
当一个函数 F 被定义时,JS 引擎会为 F 添加 prototype 原型,然后再在 prototype 上添加一个 constructor 属性,并让其指向 F 的引用。
- toString
toString( ) 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString( ) 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。例如:
Object.prototype.toString.call('') ; // [object String] Object.prototype.toString.call(1) ; // [object Number] Object.prototype.toString.call(true) ;// [object Boolean] Object.prototype.toString.call(Symbol());//[object Symbol] Object.prototype.toString.call(undefined) ;// [object Undefined] Object.prototype.toString.call(null) ;// [object Null]
70. typeof 与 instanceof 的区别? instanceof 是如何实现?
参考答案:
- typeof
typeof 是一个操作符,其右侧跟一个一元表达式,并返回这个表达式的数据类型。返回的结果用该类型的字符串(全小写字母)形式表示,包括以下 7 种:number、boolean、symbol、string、object、undefined、function 等。
- instanceof
instanceof 是用来判断 A 是否为 B 的实例,表达式为:A instanceof B,如果 A 是 B 的实例,则返回 true,否则返回 false。 在这里需要特别注意的是:instanceof 检测的是原型。
用一段伪代码来模拟其内部执行过程:
instanceof (A,B) = { varL = A.__proto__; varR = B.prototype; if(L === R) { // A的内部属性 __proto__ 指向 B 的原型对象 return true; } return false; }从上述过程可以看出,当 A 的 __proto__ 指向 B 的 prototype 时,就认为 A 就是 B 的实例。
需要注意的是,instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
例如:[ ] instanceof Object 返回的也会是 true。
71. 引用类型有哪些,有什么特点
参考答案:
JS 中七种内置类型(null,undefined,boolean,number,string,symbol,object)又分为两大类型
两大类型:
- 基本类型:
null,undefined,boolean,number,string,symbol- 引用类型Object:
Array,Function,Date,RegExp等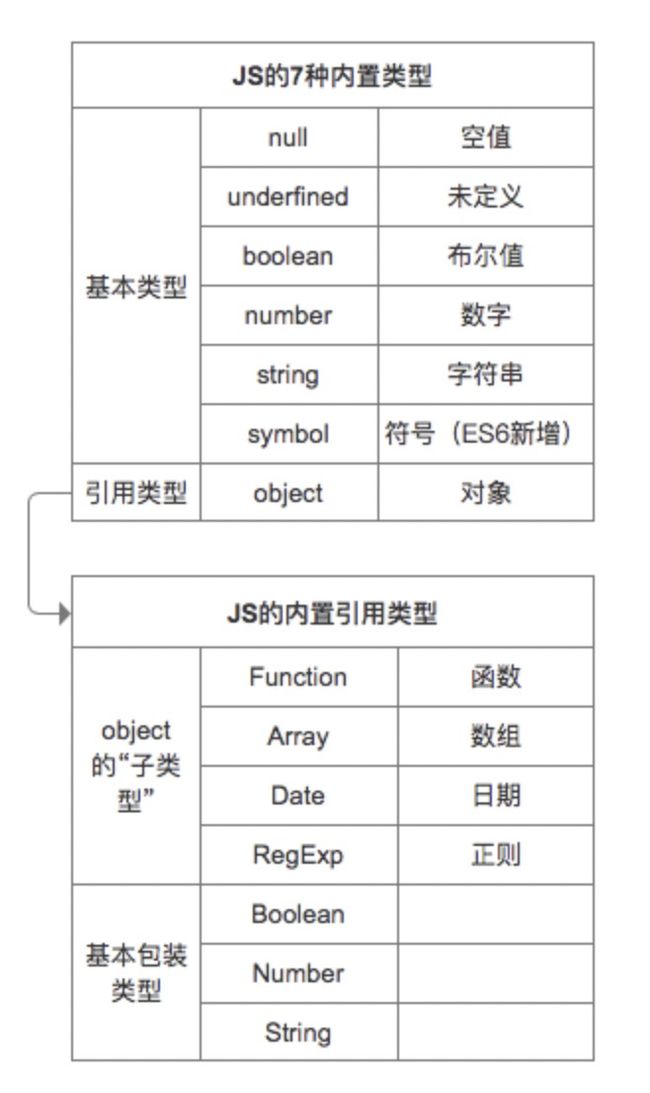
基本类型和引用类型的主要区别有以下几点:
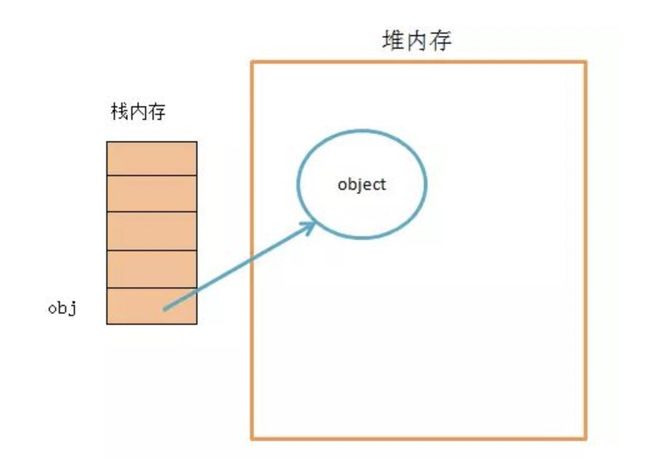
存放位置:
- 基本数据类型:基本类型值在内存中占据固定大小,直接存储在栈内存中的数据
- 引用数据类型:引用类型在栈中存储了指针,这个指针指向堆内存中的地址,真实的数据存放在堆内存里。
值的可变性:
基本数据类型: 值不可变,javascript 中的原始值(undefined、null、布尔值、数字和字符串)是不可更改的
引用数据类型:引用类型是可以直接改变其值的
比较:
基本数据类型: 基本类型的比较是值的比较,只要它们的值相等就认为他们是相等的
引用数据类型: 引用数据类型的比较是引用的比较,看其的引用是否指向同一个对象
72. 如何得到一个变量的类型—指函数封装实现
参考答案:
请参阅前面第 30 题答案。
73. 什么是作用域、闭包
参考答案:
请参阅前面第 56 题。
74. 闭包的缺点是什么?闭包的应用场景有哪些?怎么销毁闭包?
参考答案:
闭包是指有权访问另外一个函数作用域中的变量的函数。
因为闭包引用着另一个函数的变量,导致另一个函数已经不使用了也无法销毁,所以闭包使用过多,会占用较多的内存,这也是一个副作用,内存泄漏。
如果要销毁一个闭包,可以 把被引用的变量设置为null,即手动清除变量,这样下次 js 垃圾回收机制回收时,就会把设为 null 的量给回收了。
闭包的应用场景:
- 匿名自执行函数
- 结果缓存
- 封装
- 实现类和继承
75. JS的垃圾回收站机制
参考答案:
JS 具有自动垃圾回收机制。垃圾收集器会按照固定的时间间隔周期性的执行。
JS 常见的垃圾回收方式:标记清除、引用计数方式。
1、标记清除方式:
工作原理:当变量进入环境时,将这个变量标记为“进入环境”。当变量离开环境时,则将其标记为“离开环境”。标记“离开环境”的就回收内存。
工作流程:
垃圾回收器,在运行的时候会给存储在内存中的所有变量都加上标记;
去掉环境中的变量以及被环境中的变量引用的变量的标记;
被加上标记的会被视为准备删除的变量;
垃圾回收器完成内存清理工作,销毁那些带标记的值并回收他们所占用的内存空间。
2、引用计数方式:
工作原理:跟踪记录每个值被引用的次数。
工作流程:
声明了一个变量并将一个引用类型的值赋值给这个变量,这个引用类型值的引用次数就是 1;
同一个值又被赋值给另一个变量,这个引用类型值的引用次数加1;
当包含这个引用类型值的变量又被赋值成另一个值了,那么这个引用类型值的引用次数减 1;
当引用次数变成 0 时,说明没办法访问这个值了;
当垃圾收集器下一次运行时,它就会释放引用次数是0的值所占的内存。
76. 什么是作用域链、原型链
参考答案:
什么是作用域链?
当访问一个变量时,编译器在执行这段代码时,会首先从当前的作用域中查找是否有这个标识符,如果没有找到,就会去父作用域查找,如果父作用域还没找到继续向上查找,直到全局作用域为止,,而作用域链,就是有当前作用域与上层作用域的一系列变量对象组成,它保证了当前执行的作用域对符合访问权限的变量和函数的有序访问。
什么原型链?
每个对象都可以有一个原型__proto__,这个原型还可以有它自己的原型,以此类推,形成一个原型链。查找特定属性的时候,我们先去这个对象里去找,如果没有的话就去它的原型对象里面去,如果还是没有的话再去向原型对象的原型对象里去寻找。这个操作被委托在整个原型链上,这个就是我们说的原型链。
77. new 一个构造函数发生了什么
参考答案:
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。
new 关键字会进行如下的操作:
步骤 1:创建一个空的简单 JavaScript 对象,即 { } ;
步骤 2:链接该对象到另一个对象(即设置该对象的原型对象);
步骤 3:将步骤 1 新创建的对象作为 this 的上下文;
步骤 4:如果该函数没有返回对象,则返回 this。
78. 对一个构造函数实例化后. 它的原型链指向什么
参考答案:
指向该构造函数实例化出来对象的原型对象。
对于构造函数来讲,可以通过 prototype 访问到该对象。
对于实例对象来讲,可以通过隐式属性 __proto__ 来访问到。
79. 什么是变量提升
参考答案:
当 JavaScript 编译所有代码时,所有使用 var 的变量声明都被提升到它们的函数/局部作用域的顶部(如果在函数内部声明的话),或者提升到它们的全局作用域的顶部(如果在函数外部声明的话),而不管实际的声明是在哪里进行的。这就是我们所说的“提升”。
请记住,这种“提升”实际上并不发生在你的代码中,而只是一种比喻,与 JavaScript 编译器如何读取你的代码有关。记住当我们想到“提升”的时候,我们可以想象任何被提升的东西都会被移动到顶部,但是实际上你的代码并不会被修改。
函数声明也会被提升,但是被提升到了最顶端,所以将位于所有变量声明之上。
在编译阶段变量和函数声明会被放入内存中,但是你在代码中编写它们的位置会保持不变。
80. == 和 === 的区别是什么
参考答案:
简单来说: == 代表相同, === 代表严格相同(数据类型和值都相等)。
当进行双等号比较时候,先检查两个操作数数据类型,如果相同,则进行===比较,如果不同,则愿意为你进行一次类型转换,转换成相同类型后再进行比较,而 === 比较时,如果类型不同,直接就是false。
从这个过程来看,大家也能发现,某些情况下我们使用 === 进行比较效率要高些,因此,没有歧义的情况下,不会影响结果的情况下,在 JS 中首选 === 进行逻辑比较。
81. Object.is 方法比较的是什么
参考答案:
Object.is 方法是 ES6 新增的用来比较两个值是否严格相等的方法,与 === (严格相等)的行为基本一致。不过有两处不同:
- +0 不等于 -0。
- NaN 等于自身。
所以可以将Object.is 方法看作是加强版的严格相等。
82. 基础数据类型和引用数据类型,哪个是保存在栈内存中?哪个是在堆内存中?
参考答案:
在 ECMAScript 规范中,共定义了 7 种数据类型,分为 基本类型 和 引用类型 两大类,如下所示:
基本类型:String、Number、Boolean、Symbol、Undefined、Null
引用类型:Object
基本类型也称为简单类型,由于其占据空间固定,是简单的数据段,为了便于提升变量查询速度,将其存储在栈中,即按值访问。
引用类型也称为复杂类型,由于其值的大小会改变,所以不能将其存放在栈中,否则会降低变量查询速度,因此,其值存储在堆(heap)中,而存储在变量处的值,是一个指针,指向存储对象的内存处,即按址访问。引用类型除 Object 外,还包括 Function 、Array、RegExp、Date 等等。
83. 箭头函数解决了什么问题?
参考答案:
箭头函数主要解决了 this 的指向问题。
解析:
在 ES5 时代,一旦对象的方法里面又存在函数,则 this 的指向往往会让开发人员抓狂。
例如:
//错误案例,this 指向会指向 Windows 或者 undefined var obj = { age: 18, getAge: function () { var a = this.age; // 18 var fn = function () { return new Date().getFullYear() - this.age; // this 指向 window 或 undefined }; return fn(); } }; console.log(obj.getAge()); // NaN然而,箭头函数没有 this,箭头函数的 this 是继承父执行上下文里面的 this
var obj = { age: 18, getAge: function () { var a = this.age; // 18 var fn = () => new Date().getFullYear() - this.age; // this 指向 obj 对象 return fn(); } }; console.log(obj.getAge()); // 2003
84. new 一个箭头函数后,它的 this 指向什么?
参考答案:
我不知道这道题是出题人写错了还是故意为之。
箭头函数无法用来充当构造函数,所以是无法 new 一个箭头函数的。
当然,也有可能是面试官故意挖的一个坑,等着你往里面跳。
85. promise 的其他方法有用过吗?如 all、race。请说下这两者的区别
参考答案:
promise.all 方法参数是一个 promise 的数组,只有当所有的 promise 都完成并返回成功,才会调用 resolve,当有一个失败,都会进catch,被捕获错误,promise.all 调用成功返回的结果是每个 promise 单独调用成功之后返回的结果组成的数组,如果调用失败的话,返回的则是第一个 reject 的结果
promise.race 也会调用所有的 promise,返回的结果则是所有 promise 中最先返回的结果,不关心是成功还是失败。
86. class 是如何实现的
参考答案:
class 是 ES6 新推出的关键字,它是一个语法糖,本质上就是基于这个原型实现的。只不过在以前 ES5 原型实现的基础上,添加了一些 _classCallCheck、_defineProperties、_createClass等方法来做出了一些特殊的处理。
例如:
class Hello { constructor(x) { this.x = x; } greet() { console.log("Hello, " + this.x) } }"use strict"; function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } } function _defineProperties(target, props) { for (var i = 0; i < props.length; i++) { var descriptor = props[i]; descriptor.enumerable = descriptor.enumerable || false; descriptor.configurable = true; if ("value" in descriptor) descriptor.writable = true; Object.defineProperty(target, descriptor.key, descriptor); } } function _createClass(Constructor, protoProps, staticProps) { console.log("Constructor::",Constructor); console.log("protoProps::",protoProps); console.log("staticProps::",staticProps); if (protoProps) _defineProperties(Constructor.prototype, protoProps); if (staticProps) _defineProperties(Constructor, staticProps); return Constructor; } var Hello = /*#__PURE__*/function () { function Hello(x) { _classCallCheck(this, Hello); this.x = x; } _createClass(Hello, [{ key: "greet", value: function greet() { console.log("Hello, " + this.x); } }]); return Hello; }();
87. let、const、var 的区别
参考答案:
请参阅前面第 22 题答案。
88. ES6 中模块化导入和导出与 common.js 有什么区别
参考答案:
CommonJs模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化不会影响到这个值.
// common.js var count = 1; var printCount = () =>{ return ++count; } module.exports = { printCount: printCount, count: count }; // index.js let v = require('./common'); console.log(v.count); // 1 console.log(v.printCount()); // 2 console.log(v.count); // 1你可以看到明明common.js里面改变了count,但是输出的结果还是原来的。这是因为count是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动的值。将common.js里面的module.exports 改写成
module.exports = { printCount: printCount, get count(){ return count } };这样子的输出结果是 1,2,2
而在ES6当中,写法是这样的,是利用export 和import导入的
// es6.js export let count = 1; export function printCount() { ++count; } // main1.js import { count, printCount } from './es6'; console.log(count) console.log(printCount()); console.log(count)ES6 模块是动态引用,并且不会缓存,模块里面的变量绑定其所有的模块,而是动态地去加载值,并且不能重新赋值,
ES6 输入的模块变量,只是一个“符号连接符”,所以这个变量是只读的,对它进行重新赋值会报错。如果是引用类型,变量指向的地址是只读的,但是可以为其添加属性或成员。
另外还想说一个 export default
let count = 1; function printCount() { ++count; } export default { count, printCount} // main3.js import res form './main3.js' console.log(res.count)export与export default的区别及联系:
export与export default均可用于导出常量、函数、文件、模块等
你可以在其它文件或模块中通过 import + (常量 | 函数 | 文件 | 模块)名的方式,将其导入,以便能够对其进行使用
在一个文件或模块中,export、import可以有多个,export default仅有一个
通过export方式导出,在导入时要加{ },export default则不需要。
89. 说一下普通函数和箭头函数的区别
参考答案:
请参阅前面第 8、25、83 题答案。
90. 说一下 promise 和 async 和 await 什么关系
参考答案:
await 表达式会造成异步函数停止执行并且等待promise的解决,当值被resolved,异步函数会恢复执行以及返回resolved值。如果该值不是一个promise,它将会被转换成一个resolved后的promise。如果promise被rejected,await 表达式会抛出异常值。
91. 说一下你学习过的有关 ES6 的知识点
参考答案:
这种题目是开放题,可以简单列举一下 ES6 的新增知识点。( ES6 的新增知识点参阅前面第 44 题)
然后说一下自己平时开发中用得比较多的是哪些即可。
一般面试官会针对你所说的内容进行二次提问。例如:你回答平时开发中箭头函数用得比较多,那么面试官极大可能针对箭头函数展开二次提问,询问你箭头函数有哪些特性?箭头函数 this 特点之类的问题。
92. 了解过 js 中 arguments 吗?接收的是实参还是形参?
参考答案:
JS 中的 arguments 是一个伪数组对象。这个伪数组对象将包含调用函数时传递的所有的实参。
与之相对的,JS 中的函数还有一个 length 属性,返回的是函数形参的个数。
93. ES6 相比于 ES5 有什么变化
参考答案:
ES6 相比 ES5 新增了很多新特性,这里可以自己简述几个。
具体的新增特性可以参阅前面第 44 题。
94. 强制类型转换方法有哪些?
参考答案:
JavaScript 中的数据类型转换,主要有三种方式:
- 转换函数
js 提供了诸如 parseInt 和 parseFloat 这些转换函数,通过这些转换函数可以进行数据类型的转换 。
- 强制类型转换
还可使用强制类型转换(type casting)处理转换值的类型。
例如:
- Boolean(value) 把给定的值转换成 Boolean 型;
- Number(value)——把给定的值转换成数字(可以是整数或浮点数);
- String(value)——把给定的值转换成字符串。
- 利用 js 变量弱类型转换。
例如:
转换字符串:直接和一个空字符串拼接,例如:
a = "" + 数据转换布尔:!!数据类型,例如:
!!"Hello"转换数值:数据*1 或 /1,例如:
"Hello * 1"
95. 纯函数
参考答案:
一个函数,如果符合以下两个特点,那么它就可以称之为纯函数:
- 对于相同的输入,永远得到相同的输出
- 没有任何可观察到的副作用
解析:
针对上面的两个特点,我们一个一个来看。
- 相同输入得到相同输出
我们先来看一个不纯的反面典型:
let greeting = 'Hello' function greet (name) { return greeting + ' ' + name } console.log(greet('World')) // Hello World上面的代码中,greet(‘World’) 是不是永远返回 Hello World ? 显然不是,假如我们修改 greeting 的值,就会影响 greet 函数的输出。即函数 greet 其实是 依赖外部状态 的。
那我们做以下修改:
function greet (greeting, name) { return greeting + ' ' + name } console.log(greet('Hi', 'Savo')) // Hi Savo将 greeting 参数也传入,这样对于任何输入参数,都有与之对应的唯一的输出参数了,该函数就符合了第一个特点。
- 没有副作用
副作用的意思是,这个函数的运行,不会修改外部的状态。
下面再看反面典型:
const user = { username: 'savokiss' } let isValid = false function validate (user) { if (user.username.length > 4) { isValid = true } }可见,执行函数的时候会修改到 isValid 的值(注意:如果你的函数没有任何返回值,那么它很可能就具有副作用!)
那么我们如何移除这个副作用呢?其实不需要修改外部的 isValid 变量,我们只需要在函数中将验证的结果 return 出来:
const user = { username: 'savokiss' } function validate (user) { return user.username.length > 4; } const isValid = validate(user)这样 validate 函数就不会修改任何外部的状态了~
96. JS 模块化
参考答案:
模块化主要是用来抽离公共代码,隔离作用域,避免变量冲突等。
模块化的整个发展历史如下:
IIFE: 使用自执行函数来编写模块化,特点:在一个单独的函数作用域中执行代码,避免变量冲突。
(function(){ return { data:[] } })()AMD: 使用requireJS 来编写模块化,特点:依赖必须提前声明好。
define('./index.js',function(code){ // code 就是index.js 返回的内容 })CMD: 使用seaJS 来编写模块化,特点:支持动态引入依赖文件。
define(function(require, exports, module) { var indexCode = require('./index.js'); });CommonJS: nodejs 中自带的模块化。
var fs = require('fs');UMD:兼容AMD,CommonJS 模块化语法。
webpack(require.ensure):webpack 2.x 版本中的代码分割。
ES Modules: ES6 引入的模块化,支持import 来引入另一个 js 。
import a from 'a';
97. 看过 jquery 源码吗?
参考答案:
开放题,但是需要注意的是,如果看过 jquery 源码,不要简单的回答一个“看过”就完了,应该继续乘胜追击,告诉面试官例如哪个哪个部分是怎么怎么实现的,并针对这部分的源码实现,可以发表一些自己的看法和感想。
98. 说一下 js 中的 this
参考答案:
请参阅前面第 17 题答案。
99. apply call bind 区别,手写
参考答案:
apply call bind 区别 ?
call 和 apply 的功能相同,区别在于传参的方式不一样:
- fn.call(obj, arg1, arg2, …) 调用一个函数, 具有一个指定的 this 值和分别地提供的参数(参数的列表)。
- fn.apply(obj, [argsArray]) 调用一个函数,具有一个指定的 this 值,以及作为一个数组(或类数组对象)提供的参数。
bind 和 call/apply 有一个很重要的区别,一个函数被 call/apply 的时候,会直接调用,但是 bind 会创建一个新函数。当这个新函数被调用时,bind( ) 的第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数。
实现 call 方法:
Function.prototype.call2 = function (context) { //没传参数或者为 null 是默认是 window var context = context || (typeof window !== 'undefined' ? window : global) // 首先要获取调用 call 的函数,用 this 可以获取 context.fn = this var args = [] for (var i = 1; i < arguments.length; i++) { args.push('arguments[' + i + ']') } eval('context.fn(' + args + ')') delete context.fn } // 测试 var value = 3 var foo = { value: 2 } function bar(name, age) { console.log(this.value) console.log(name) console.log(age) } bar.call2(null) // 浏览器环境: 3 undefinde undefinde // Node环境:undefinde undefinde undefinde bar.call2(foo, 'cc', 18) // 2 cc 18实现 apply 方法:
Function.prototype.apply2 = function (context, arr) { var context = context || (typeof window !== 'undefined' ? window : global) context.fn = this; var result; if (!arr) { result = context.fn(); } else { var args = []; for (var i = 0, len = arr.length; i < len; i++) { args.push('arr[' + i + ']'); } result = eval('context.fn(' + args + ')') } delete context.fn return result; } // 测试: var value = 3 var foo = { value: 2 } function bar(name, age) { console.log(this.value) console.log(name) console.log(age) } bar.apply2(null) // 浏览器环境: 3 undefinde undefinde // Node环境:undefinde undefinde undefinde bar.apply2(foo, ['cc', 18]) // 2 cc 18实现 bind 方法:
Function.prototype.bind2 = function (oThis) { if (typeof this !== "function") { // closest thing possible to the ECMAScript 5 internal IsCallable function throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable"); } var aArgs = Array.prototype.slice.call(arguments, 1), fToBind = this, fNOP = function () { }, fBound = function () { return fToBind.apply(this instanceof fNOP && oThis ? this : oThis || window, aArgs.concat(Array.prototype.slice.call(arguments))); }; fNOP.prototype = this.prototype; fBound.prototype = new fNOP(); return fBound; } // 测试 var test = { name: "jack" } var demo = { name: "rose", getName: function () { return this.name; } } console.log(demo.getName()); // 输出 rose 这里的 this 指向 demo // 运用 bind 方法更改 this 指向 var another2 = demo.getName.bind2(test); console.log(another2()); // 输出 jack 这里 this 指向了 test 对象了
100. 手写 reduce flat
参考答案:
reduce 实现:
Array.prototype.my_reduce = function (callback, initialValue) { if (!Array.isArray(this) || !this.length || typeof callback !== 'function') { return [] } else { // 判断是否有初始值 let hasInitialValue = initialValue !== undefined; let value = hasInitialValue ? initialValue : tihs[0]; for (let index = hasInitialValue ? 0 : 1; index < this.length; index++) { const element = this[index]; value = callback(value, element, index, this) } return value } } let arr = [1, 2, 3, 4, 5] let res = arr.my_reduce((pre, cur, i, arr) => { console.log(pre, cur, i, arr) return pre + cur }, 10) console.log(res)//25flat 实现:
let arr = [1, [2, 3, [4, 5, [12, 3, "zs"], 7, [8, 9, [10, 11, [1, 2, [3, 4]]]]]]]; //万能的类型检测方法 const checkType = (arr) => { return Object.prototype.toString.call(arr).slice(8, -1); } //自定义flat方法,注意:不可以使用箭头函数,使用后内部的this会指向window Array.prototype.myFlat = function (num) { //判断第一层数组的类型 let type = checkType(this); //创建一个新数组,用于保存拆分后的数组 let result = []; //若当前对象非数组则返回undefined if (!Object.is(type, "Array")) { return; } //遍历所有子元素并判断类型,若为数组则继续递归,若不为数组则直接加入新数组 this.forEach((item) => { let cellType = checkType(item); if (Object.is(cellType, "Array")) { //形参num,表示当前需要拆分多少层数组,传入Infinity则将多维直接降为一维 num--; if (num < 0) { let newArr = result.push(item); return newArr; } //使用三点运算符解构,递归函数返回的数组,并加入新数组 result.push(...item.myFlat(num)); } else { result.push(item); } }) return result; } console.time(); console.log(arr.flat(Infinity)); //[1, 2, 3, 4, 5, 12, 3, "zs", 7, 8, 9, 10, 11, 1, 2, 3, 4]; console.log(arr.myFlat(Infinity)); //[1, 2, 3, 4, 5, 12, 3, "zs", 7, 8, 9, 10, 11, 1, 2, 3, 4]; //自定义方法和自带的flat返回结果一致!!!! console.timeEnd();
101. == 隐试转换的原理?是怎么转换的
参考答案:
两个与类型转换有关的函数:valueOf()和toString()
- valueOf()的语义是,返回这个对象逻辑上对应的原始类型的值。比如说,String包装对象的valueOf(),应该返回这个对象所包装的字符串。
- toString()的语义是,返回这个对象的字符串表示。用一个字符串来描述这个对象的内容。
valueOf()和toString()是定义在Object.prototype上的方法,也就是说,所有的对象都会继承到这两个方法。但是在Object.prototype上定义的这两个方法往往不能满足我们的需求(Object.prototype.valueOf()仅仅返回对象本身),因此js的许多内置对象都重写了这两个函数,以实现更适合自身的功能需要(比如说,String.prototype.valueOf就覆盖了在Object.prototype中定义的valueOf)。当我们自定义对象的时候,最好也重写这个方法。重写这个方法时要遵循上面所说的语义。
js内部用于实现类型转换的4个函数
这4个方法实际上是ECMAScript定义的4个抽象的操作,它们在js内部使用,进行类型转换。js的使用者不能直接调用这些函数。
- ToPrimitive ( input [ , PreferredType ] )
- ToBoolean ( argument )
- ToNumber ( argument )
- ToString ( argument )
需要区分这里的 ToString() 和上文谈到的 toString(),一个是 js 引擎内部使用的函数,另一个是定义在对象上的函数。
(1)ToPrimitive ( input [ , PreferredType ] )
将 input 转化成一个原始类型的值。PreferredType参数要么不传入,要么是Number 或 String。如果PreferredType参数是Number,ToPrimitive这样执行:
- 如果input本身就是原始类型,直接返回input。
- 调用input.valueOf(),如果结果是原始类型,则返回这个结果。
- 调用input.toString(),如果结果是原始类型,则返回这个结果。
- 抛出TypeError异常。
以下是PreferredType不为Number时的执行顺序。
- 如果PreferredType参数是String,则交换上面这个过程的第2和第3步的顺序,其他执行过程相同。
- 如果PreferredType参数没有传入
- 如果input是内置的Date类型,PreferredType 视为String
- 否则PreferredType 视为 Number
可以看出,ToPrimitive依赖于valueOf和toString的实现。
(2)ToBoolean ( argument )
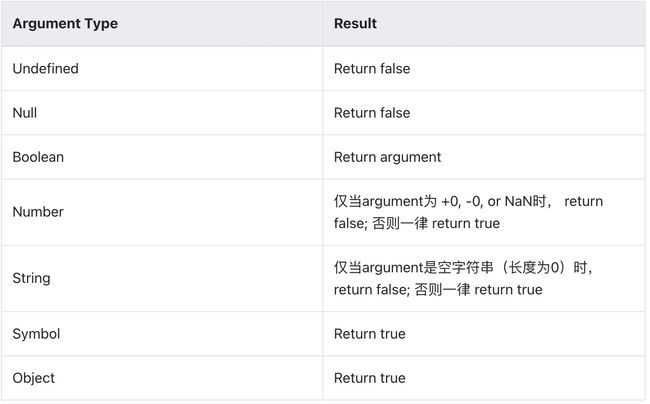
只需要记忆 0, null, undefined, NaN, “” 返回 false 就可以了,其他一律返回 true。
(3)ToNumber ( argument )
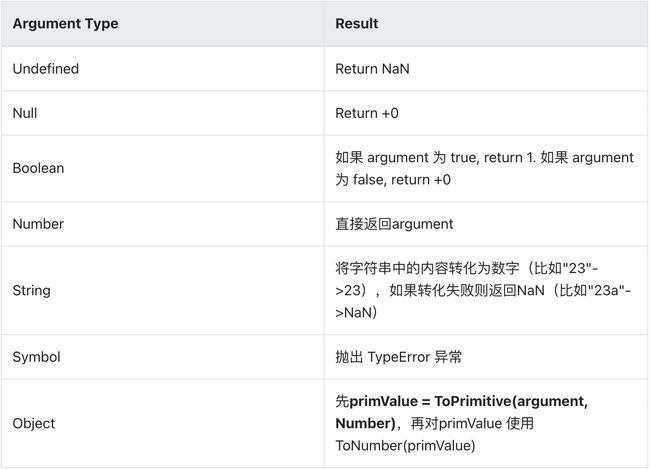
ToNumber的转化并不总是成功,有时会转化成NaN,有时则直接抛出异常。
(4)ToString ( argument )
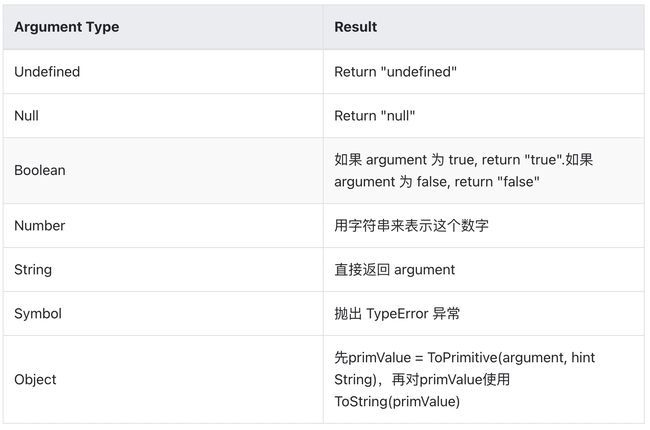
当js期望得到某种类型的值,而实际在那里的值是其他的类型,就会发生隐式类型转换。系统内部会自动调用我们前面说ToBoolean ( argument )、ToNumber ( argument )、ToString ( argument ),尝试转换成期望的数据类型。
102. [‘1’, ‘2’, ‘3’].map(parseInt) 结果是什么,为什么 (字节)
参考答案:
[1, NaN, NaN]
解析:
一、为什么会是这个结果?
- map 函数
将数组的每个元素传递给指定的函数处理,并返回处理后的数组,所以 [‘1’,‘2’,‘3’].map(parseInt) 就是将字符串 1,2,3 作为元素;0,1,2 作为下标分别调用 parseInt 函数。即分别求出 parseInt(‘1’,0), parseInt(‘2’,1), parseInt(‘3’,2) 的结果。
- parseInt 函数(重点)
概念:以第二个参数为基数来解析第一个参数字符串,通常用来做十进制的向上取整(省略小数)如:parseInt(2.7) //结果为2
特点:接收两个参数 parseInt(string,radix)
string:字母(大小写均可)、数组、特殊字符(不可放在开头,特殊字符及特殊字符后面的内容不做解析)的任意字符串,如 ‘2’、‘2w’、‘2!’
radix:解析字符串的基数,基数规则如下:
1) 区间范围介于 2~36 之间;
2 ) 当参数为 0,parseInt( ) 会根据十进制来解析;
3 ) 如果忽略该参数,默认的基数规则:
如果 string 以 “0x” 开头,parseInt() 会把 string 的其余部分解析为十六进制的整数;parseInt(“0xf”) // 15
如果 string 以 0 开头,其后的字符解析为八进制或十六进制的数字;parseInt(“08”) // 8
如果 string 以 1 ~ 9 的数字开头,parseInt() 将把它解析为十进制的整数;parseInt(“88.99f”) // 88
只有字符串中的第一个数字会被返回。parseInt(“10.33”) // 返回10;
开头和结尾的空格是允许的。parseInt(" 69 10 ") // 返回69
如果字符串的第一个字符不能被转换为数字,返回 NaN。parseInt(“f”) // 返回 NaN 而 parseInt(“f”,16) // 返回15二、parseInt 方法解析的运算过程
parseInt(‘101.55’,10); // 以十进制解析,运算过程:向上取整数(不做四舍五入,省略小数),结果为 101。
parseInt(‘101’,2); // 以二进制解析,运算过程:12的2次方+02的1次方+1*2的0次方=4+0+1=5,结果为 5。
parseInt(‘101’,8); // 以八进制解析,运算过程:18的2次方+08的1次方+1*8的0次方=64+0+1=65,结果为 65。
parseInt(‘101’,16); // 以十六进制解析,运算过程:116的2次方+016的1次方+1*16的0次方=256+0+1=257,结果为 257。
三、再来分析一下结果
[‘1’,‘2’,‘3’].map(parseInt) 即
parseInt(‘1’,0); radix 为 0,parseInt( ) 会根据十进制来解析,所以结果为 1;
parseInt(‘2’,1); radix 为 1,超出区间范围,所以结果为 NaN;
parseInt(‘3’,2); radix 为 2,用2进制来解析,应以 0 和 1 开头,所以结果为 NaN。
103. 防抖,节流是什么,如何实现 (字节)
参考答案:
我们在平时开发的时候,会有很多场景会频繁触发事件,比如说搜索框实时发请求,onmousemove、resize、onscroll 等,有些时候,我们并不能或者不想频繁触发事件,这时候就应该用到函数防抖和函数节流。
函数防抖(debounce),指的是短时间内多次触发同一事件,只执行最后一次,或者只执行最开始的一次,中间的不执行。
具体实现:
/** * 函数防抖 * @param {function} func 一段时间后,要调用的函数 * @param {number} wait 等待的时间,单位毫秒 */ function debounce(func, wait){ // 设置变量,记录 setTimeout 得到的 id let timerId = null; return function(...args){ if(timerId){ // 如果有值,说明目前正在等待中,清除它 clearTimeout(timerId); } // 重新开始计时 timerId = setTimeout(() => { func(...args); }, wait); } }函数节流(throttle),指连续触发事件但是在 n 秒中只执行一次函数。即 2n 秒内执行 2 次… 。节流如字面意思,会稀释函数的执行频率。
具体实现:
function throttle(func, wait) { let context, args; let previous = 0; return function () { let now = +new Date(); context = this; args = arguments; if (now - previous > wait) { func.apply(context, args); previous = now; } } }
104. 介绍下 Set、Map、WeakSet 和 WeakMap 的区别(字节)
参考答案:
Set
成员唯一、无序且不重复
键值与键名是一致的(或者说只有键值,没有键名)
可以遍历,方法有 add, delete,has
WeakSet
成员都是对象
成员都是弱引用,可以被垃圾回收机制回收,可以用来保存 DOM 节点,不容易造成内存泄漏
不能遍历,方法有 add, delete,has
Map
本质上是健值对的集合,类似集合
可以遍历,方法很多,可以跟各种数据格式转换
WeakMap
只接受对象作为健名(null 除外),不接受其他类型的值作为健名
键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾机制回收,此时键名是无效的
不能遍历,方法有 get、set、has、delete
105. setTimeout、Promise、Async/Await 的区别(字节)
参考答案:
事件循环中分为宏任务队列和微任务队列。
其中 setTimeout 的回调函数放到宏任务队列里,等到执行栈清空以后执行;
promise.then 里的回调函数会放到相应宏任务的微任务队列里,等宏任务里面的同步代码执行完再执行;
async 函数表示函数里面可能会有异步方法,await 后面跟一个表达式,async 方法执行时,遇到 await 会立即执行表达式,然后把表达式后面的代码放到微任务队列里,让出执行栈让同步代码先执行。
106. Promise 构造函数是同步执行还是异步执行,那么 then 方法呢?(字节)
参考答案:
promise 构造函数是同步执行的,then 方法是异步执行,then 方法中的内容加入微任务中。
107. 情人节福利题,如何实现一个 new (字节)
参考答案:
首先我们需要明白 new 的原理。关于 new 的原理,主要分为以下几步:
创建一个空对象 。
由 this 变量引用该对象 。
该对象继承该函数的原型(更改原型链的指向) 。
把属性和方法加入到 this 引用的对象中。
新创建的对象由 this 引用 ,最后隐式地返回 this
明白了这个原理后,我们就可以尝试来实现一个 new 方法,参考示例如下:
// 构造器函数 let Parent = function (name, age) { this.name = name; this.age = age; }; Parent.prototype.sayName = function () { console.log(this.name); }; //自己定义的new方法 let newMethod = function (Parent, ...rest) { // 1.以构造器的prototype属性为原型,创建新对象; let child = Object.create(Parent.prototype); // 2.将this和调用参数传给构造器执行 let result = Parent.apply(child, rest); // 3.如果构造器没有手动返回对象,则返回第一步的对象 return typeof result === 'object' ? result : child; }; //创建实例,将构造函数Parent与形参作为参数传入 const child = newMethod(Parent, 'echo', 26); child.sayName() //'echo'; //最后检验,与使用new的效果相同 console.log(child instanceof Parent)//true console.log(child.hasOwnProperty('name'))//true console.log(child.hasOwnProperty('age'))//true console.log(child.hasOwnProperty('sayName'))//false
108. 实现一个 sleep 函数(字节)
参考答案:
function sleep(delay) { var start = (new Date()).getTime(); while ((new Date()).getTime() - start < delay) { continue; } } function test() { console.log('111'); sleep(2000); console.log('222'); } test()这种实现方式是利用一个伪死循环阻塞主线程。因为 JS 是单线程的。所以通过这种方式可以实现真正意义上的 sleep。
109. 使用 sort() 对数组 [3, 15, 8, 29, 102, 22] 进行排序,输出结果 (字节)
参考答案:
sort 方法默认按照 ASCII 码来排序,如果要按照数字大小来排序,需要传入一个回调函数,如下:
[3, 15, 8, 29, 102, 22].sort((a,b) => {return a - b});
110. 实现 5.add(3).sub(2) (百度)
参考答案:
这里想要实现的是链式操作,那么我们可以考虑在 Number 类型的原型上添加 add 和 sub 方法,这两个方法返回新的数
示例如下:
Number.prototype.add = function (number) { if (typeof number !== 'number') { throw new Error('请输入数字~'); } return this.valueOf() + number; }; Number.prototype.minus = function (number) { if (typeof number !== 'number') { throw new Error('请输入数字~'); } return this.valueOf() - number; }; console.log((5).add(3).minus(2)); // 6
111. 给定两个数组,求交集
参考答案:
示例代码如下:
function intersect(nums1, nums2) { let i = j = 0, len1 = nums1.length, len2 = nums2.length, newArr = []; if (len1 === 0 || len2 === 0) { return newArr; } nums1.sort(function (a, b) { return a - b; }); nums2.sort(function (a, b) { return a - b; }); while (i < len1 || j < len2) { if (nums1[i] > nums2[j]) { j++; } else if (nums1[i] < nums2[j]) { i++; } else { if (nums1[i] === nums2[j]) { newArr.push(nums1[i]); } if (i < len1 - 1) { i++; } else { break; } if (j < len2 - 1) { j++; } else { break; } } } return newArr; }; // 测试 console.log(intersect([3, 5, 8, 1], [2, 3]));
112. 为什么普通 for 循环的性能远远高于 forEach 的性能,请解释其中的原因。
参考答案:
for 循环按顺序遍历,forEach 使用 iterator 迭代器遍历
下面是一段性能测试的代码:
let arrs = new Array(100000); console.time('for'); for (let i = 0; i < arrs.length; i++) { }; console.timeEnd('for'); console.time('forEach'); arrs.forEach((arr) => { }); console.timeEnd('forEach'); for: 2.263ms forEach: 0.254ms在10万这个级别下,
forEach的性能是for的十倍for: 2.263ms forEach: 0.254ms在100万这个量级下,
forEach的性能是和for的一致for: 2.844ms forEach: 2.652ms在1000万级以上的量级上 ,
forEach的性能远远低于for的性能for: 8.422ms forEach: 30.328m我们从语法上面来观察:
arr.forEach(callback(currentValue [, index [, array]])[, thisArg])可以看到 forEach 是有回调的,它会按升序为数组中含有效值的每一项执行一次 callback,且除了抛出异常以外,也没有办法中止或者跳出 forEach 循环。那这样的话执行就会额外的调用栈和函数内的上下文。
而 for 循环则是底层写法,不会产生额外的消耗。
在实际业务中没有很大的数组时,for 和 forEach 的性能差距其实很小,forEach 甚至会优于 for 的时间,且更加简洁,可读性也更高,一般也会优先使用 forEach 方法来进行数组的循环处理。
113. 实现一个字符串匹配算法,从长度为 n 的字符串 S 中,查找是否存在字符串 T,T 的长度是 m,若存在返回所在位置。
参考答案:
// 完全不用 API var getIndexOf = function (s, t) { let n = s.length; let m = t.length; if (!n || !m || n < m) return -1; for (let i = 0; i < n; i++) { let j = 0; let k = i; if (s[k] === t[j]) { k++; j++; while (k < n && j < m) { if (s[k] !== t[j]) break; else { k++; j++; } } if (j === m) return i; } } return -1; } // 测试 console.log(getIndexOf("Hello World", "rl"))
114. 使用 JavaScript Proxy 实现简单的数据绑定
参考答案:
示例代码如下:
<body> hello,world <input type="text" id="model"> <p id="word"></p> </body> <script> const model = document.getElementById("model") const word = document.getElementById("word") var obj= {}; const newObj = new Proxy(obj, { get: function(target, key, receiver) { console.log(`getting ${key}!`); return Reflect.get(target, key, receiver); }, set: function(target, key, value, receiver) { console.log('setting',target, key, value, receiver); if (key === "text") { model.value = value; word.innerHTML = value; } return Reflect.set(target, key, value, receiver); } }); model.addEventListener("keyup",function(e){ newObj.text = e.target.value }) </script>
115. 数组里面有 10 万个数据,取第一个元素和第 10 万个元素的时间相差多少(字节)
参考答案:
消耗时间几乎一致,差异可以忽略不计
解析:
- 数组可以直接根据索引取的对应的元素,所以不管取哪个位置的元素的时间复杂度都是 O(1)
- JavaScript 没有真正意义上的数组,所有的数组其实是对象,其“索引”看起来是数字,其实会被转换成字符串,作为属性名(对象的 key)来使用。所以无论是取第 1 个还是取第 10 万个元素,都是用 key 精确查找哈希表的过程,其消耗时间大致相同。
116. 打印出 1~10000 以内的对称数
参考答案:
function isSymmetryNum(start, end) { for (var i = start; i < end + 1; i++) { var iInversionNumber = +(i.toString().split("").reverse().join("")); if (iInversionNumber === i && i > 10) { console.log(i); } } } isSymmetryNum(1, 10000);
117. 简述同步和异步的区别
参考答案:
同步意味着每一个操作必须等待前一个操作完成后才能执行。
异步意味着操作不需要等待其他操作完成后才开始执行。
在 JavaScript 中,由于单线程的特性导致所有代码都是同步的。但是,有些异步操作(例如:XMLHttpRequest或setTimeout)并不是由主线程进行处理的,他们由本机代码(浏览器 API)所控制,并不属于程序的一部分。但程序中被执行的回调部分依旧是同步的。加分回答:
- JavaScript 中的同步任务是指在主线程上排队执行的任务,只有前一个任务执行完成后才能执行后一个任务;异步任务是指进入任务队列(task queue)而非主线程的任务,只有当任务队列通知主线程,某个异步任务可以执行了,该任务才会进入主线程中进行执行。
- JavaScript 的并发模型是基于 “event loop”。
- 像
alert这样的方法回阻塞主线程,以致用户关闭他后才能继续进行后续的操作。- JavaScript 主要用于和用户互动及操作 DOM,多线程的情况和异步操作带来的复杂性相比决定了他单线程的特性。
- Web Worker 虽然允许 JavaScript 创建多个线程,但子线程完全受主线程控制,且不能操作 DOM。因此他还是保持了单线程的特性。
118. 怎么添加、移除、复制、创建、和查找节点
参考答案:
1)创建新节点
createDocumentFragment( ) // 创建一个DOM 片段
createElement( ) // 创建一个具体的元素
createTextNode( ) // 创建一个文本节点
(2)添加、移除、替换、插入
appendChild( )
removeChild( )
replaceChild( )
insertBefore( ) // 在已有的子节点前插入一个新的子节点
(3)查找
getElementsByTagName( ) //通过标签名称
getElementsByName( ) // 通过元素的 Name 属性的值
getElementById( ) // 通过元素 Id,唯一性
querySelector( ) // 用于接收一个 CSS 选择符,返回与该模式匹配的第一个元素
querySelectorAll( ) // 用于选择匹配到的所有元素
119. 实现一个函数 clone 可以对 Javascript 中的五种主要数据类型(Number、string、 Object、Array、Boolean)进行复制
参考答案:
示例代码如下:
/** * 对象克隆 * 支持基本数据类型及对象 * 递归方法 */ function clone(obj) { var o; switch (typeof obj) { case "undefined": break; case "string": o = obj + ""; break; case "number": o = obj - 0; break; case "boolean": o = obj; break; case "object": // object 分为两种情况 对象(Object)或数组(Array) if (obj === null) { o = null; } else { if (Object.prototype.toString.call(obj).slice(8, -1) === "Array") { o = []; for (var i = 0; i < obj.length; i++) { o.push(clone(obj[i])); } } else { o = {}; for (var k in obj) { o[k] = clone(obj[k]); } } } break; default: o = obj; break; } return o; }
120. 如何消除一个数组里面重复的元素
参考答案:
请参阅前面第 2 题。
121. 写一个返回闭包的函数
参考答案:
function foo() { var i = 0; return function () { console.log(i++); } } var f1 = foo(); f1(); // 0 f1(); // 1 f1(); // 2
122. 使用递归完成 1 到 100 的累加
参考答案:
function add(x, y){ if(x === y){ return x; } else { return y + add(x, y-1); } } console.log(add(1, 100))
123. Javascript 有哪几种数据类型
参考答案:
请参阅前面第 26 题。
124. 如何判断数据类型
参考答案:
请参阅前面第 69 题。
125. console.log(1+‘2’)和 console.log(1-‘2’)的打印结果
参考答案:
第一个打印出 ‘12’,是一个 string 类型的值。
第二个打印出 -1,是一个 number 类型的值
126. JS 的事件委托是什么,原理是什么
参考答案:
事件委托,又被称之为事件代理。在 JavaScript 中,添加到页面上的事件处理程序数量将直接关系到页面整体的运行性能。导致这一问题的原因是多方面的。
首先,每个函数都是对象,都会占用内存。内存中的对象越多,性能就越差。其次,必须事先指定所有事件处理程序而导致的 DOM 访问次数,会延迟整个页面的交互就绪时间。
对事件处理程序过多问题的解决方案就是事件委托。
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。例如,click 事件会一直冒泡到 document 层次。也就是说,我们可以为整个页面指定一个 onclick 事件处理程序,而不必给每个可单击的元素分别添加事件处理程序。
127. 如何改变函数内部的 this 指针的指向
参考答案:
可以通过 call、apply、bind 方法来改变 this 的指向,关于 call、apply、bind 方法的具体使用,请参阅前面 102 题
128. JS 延迟加载的方式有哪些?
参考答案:
- defer 属性
- async 属性
- 使用 jQuery 的 getScript( ) 方法
- 使用 setTimeout 延迟方法
- 把 JS 外部引入的文件放到页面底部,来让 JS 最后引入
129. 说说严格模式的限制
参考答案:
什么是严格模式?
严格模式对 JavaScript 的语法和行为都做了一些更改,消除了语言中一些不合理、不确定、不安全之处;提供高效严谨的差错机制,保证代码安全运行;禁用在未来版本中可能使用的语法,为新版本做好铺垫。在脚本文件第一行或函数内第一行中引入"use strict"这条指令,就能触发严格模式,这是一条没有副作用的指令,老版的浏览器会将其作为一行字符串直接忽略。
例如:
"use strict";//脚本第一行 function add(a,b){ "use strict";//函数内第一行 return a+b; }进入严格模式后的限制
- 变量必须声明后再赋值
- 不能有重复的参数名,函数的参数也不能有同名属性
- 不能使用with语句
- 不能对只读属性赋值
- 不能使用前缀 0表示八进制数
- 不能删除不可删除的属性
- eval 不会在它的外层作用域引入变量。
- eval和arguments不能被重新赋值
- arguments 不会自动反应函数的变化
- 不能使用 arguments.callee
- 不能使用 arguments.caller
- 禁止 this 指向全局对象
- 不能使用 fn.caller 和 fn.arguments 获取函数调用的堆栈
- 增加了保留字
130. attribute 和 property 的区别是什么?
参考答案:
property 和 attribute 非常容易混淆,两个单词的中文翻译也都非常相近(property:属性,attribute:特性),但实际上,二者是不同的东西,属于不同的范畴。
- property是DOM中的属性,是JavaScript里的对象;
- attribute是HTML标签上的特性,它的值只能够是字符串;
简单理解,Attribute就是dom节点自带的属性,例如html中常用的id、class、title、align等。
而Property是这个DOM元素作为对象,其附加的内容,例如childNodes、firstChild等。
131. ES6 能写 class 么,为什么会出现 class 这种东西?
参考答案:
在 ES6 中,可以书写 class。因为在 ES6 规范中,引入了 class 的概念。使得 JS 开发者终于告别了直接使用原型对象模仿面向对象中的类和类继承时代。
但是 JS 中并没有一个真正的 class 原始类型, class 仅仅只是对原型对象运用语法糖。
之所以出现 class 关键字,是为了使 JS 更像面向对象,所以 ES6 才引入 class 的概念。
132. 常见兼容性问题
参考答案:
常见的兼容性问题很多,这里列举一些:
- 关于获取行外样式 currentStyle 和 getComputedStyle 出现的兼容问题
我们都知道 JS 通过 style 不可以获取行外样式,如果我们需要获取行外样式就会使用这两种
IE 下:currentStyle
chrome、FF 下:getComputedStyle 第二个参数的作用是获取伪类元素的属性值
- 关于“索引”获取字符串每一项出现的兼容性的问题
对于字符串也有类似于数组这样通过下标索引获取每一项的值
var str = 'abcd'; console.log(str[2]);但是低版本的浏览器 IE6、7 不兼容
- 关于使用 firstChild、lastChild 等,获取第一个/最后一个元素节点是产生的问题
- IE6-8下: firstChild,lastChild,nextSibling,previousSibling 获取第一个元素节点
- 高版本浏览器IE9+、FF、Chrome:获取的空白文本节点
- 关于使用 event 对象,出现兼容性问题
在 IE8 及之前的版本浏览器中,event 事件对象是作为 window 对象的一个属性。
所以兼容的写法如下:
function(event){ event = event || window.event; }
- 关于事件绑定的兼容性问题
IE8 以下用: attachEvent(‘事件名’,fn);
FF、Chrome、IE9-10 用: attachEventLister(‘事件名’,fn,false);
- 关于获取滚动条距离而出现的问题
当我们获取滚动条滚动距离时:
IE、Chrome: document.body.scrollTop
FF: document.documentElement.scrollTop
兼容处理:
var scrollTop = document.documentElement.scrollTop||document.body.scrollTop
133. 函数防抖节流的原理
参考答案:
请参阅前面第 49、106 题。
134. 原始类型有哪几种?null 是对象吗?
参考答案:
在 JavaScript 中,数据类型整体上来讲可以分为两大类:基本类型和引用数据类型
基本数据类型,一共有 7 种:
string,symbol,number,boolean,undefined,null,bigInt其中 symbol 类型是在 ES6 里面新添加的基本数据类型。
引用数据类型,就只有 1 种:
object基本数据类型的值又被称之为原始值或简单值,而引用数据类型的值又被称之为复杂值或引用值。
关于原始类型和引用类型的区别,可以参阅第 26 题。
null 表示空,但是当我们使用 typeof 来进行数据类型检测的时候,得到的值是 object。
具体原因可以参阅前面第 68 题。
135. 为什么 console.log(0.2+0.1==0.3) // false
参考答案:
因为浮点数的计算存在 round-off 问题,也就是浮点数不能够进行精确的计算。并且:
- 不仅 JavaScript,所有遵循 IEEE 754 规范的语言都是如此;
- 在 JavaScript 中,所有的 Number 都是以 64-bit 的双精度浮点数存储的;
- 双精度的浮点数在这 64 位上划分为 3 段,而这 3 段也就确定了一个浮点数的值,64bit 的划分是“1-11-52”的模式,具体来说:
- 就是 1 位最高位(最左边那一位)表示符号位,0 表示正,1 表示负;
- 11 位表示指数部分;
- 52 位表示尾数部分,也就是有效域部分
136. 说一下 JS 中类型转换的规则?
参考答案:
类型转换可以分为两种,隐性转换和显性转换。
1. 隐性转换
当不同数据类型之间进行相互运算,或者当对非布尔类型的数据求布尔值的时候,会发生隐性转换。
预期为数字的时候:算术运算的时候,我们的结果和运算的数都是数字,数据会转换为数字来进行计算。
类型 转换前 转换后 number 4 4 string “1” 1 string “abc” NaN string “” 0 boolean true 1 boolean false 0 undefined undefined NaN null null 0 预期为字符串的时候:如果有一个操作数为字符串时,使用
+符号做相加运算时,会自动转换为字符串。预期为布尔的时候:前面在介绍布尔类型时所提到的 9 个值会转为 false,其余转为 true
2. 显性转换
所谓显性转换,就是只程序员强制将一种类型转换为另外一种类型。显性转换往往会使用到一些转换方法。常见的转换方法如下:
转换为数值类型:
Number(),parseInt(),parseFloat()转换为布尔类型:
Boolean()转换为字符串类型:
toString(),String()当然,除了使用上面的转换方法,我们也可以通过一些快捷方式来进行数据类型的显性转换,如下:
转换字符串:直接和一个空字符串拼接,例如:
a = "" + 数据转换布尔:!!数据类型,例如:
!!"Hello"转换数值:数据*1 或 /1,例如:
"Hello * 1"
137. 深拷贝和浅拷贝的区别?如何实现
参考答案:
浅拷贝:只是拷贝了基本类型的数据,而引用类型数据,复制后也是会发生引用,我们把这种拷贝叫做浅拷贝(浅复制)
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。
深拷贝:在堆中重新分配内存,并且把源对象所有属性都进行新建拷贝,以保证深拷贝的对象的引用图不包含任何原有对象或对象图上的任何对象,拷贝后的对象与原来的对象是完全隔离,互不影响。
浅拷贝方法
- 直接赋值
- Object.assign 方法:可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。当拷贝的 object 只有一层的时候,是深拷贝,但是当拷贝的对象属性值又是一个引用时,换句话说有多层时,就是一个浅拷贝。
- ES6 扩展运算符,当 object 只有一层的时候,也是深拷贝。有多层时是浅拷贝。
- Array.prototype.concat 方法
- Array.prototype.slice 方法
- jQuery 中的 . e x t e n d ∗ :在 ∗ j Q u e r y ∗ 中, ∗ .extend*:在 *jQuery* 中,* .extend∗:在∗jQuery∗中,∗.extend(deep,target,object1,objectN) 方法可以进行深浅拷贝。deep 如过设为 true 为深拷贝,默认是 false 浅拷贝。
深拷贝方法
- $.extend(deep,target,object1,objectN),将 deep 设置为 true
- JSON.parse(JSON.stringify):用 JSON.stringify 将对象转成 JSON 字符串,再用 JSON.parse 方法把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。这种方法虽然可以实现数组或对象深拷贝,但不能处理函数。
- 手写递归
示例代码如下:
function deepCopy(oldObj, newobj) { for (var key in oldObj) { var item = oldObj[key]; // 判断是否是对象 if (item instanceof Object) { if (item instanceof Function) { newobj[key] = oldObj[key]; } else { newobj[key] = {}; //定义一个空的对象来接收拷贝的内容 deepCopy(item, newobj[key]); //递归调用 } // 判断是否是数组 } else if (item instanceof Array) { newobj[key] = []; //定义一个空的数组来接收拷贝的内容 deepCopy(item, newobj[key]); //递归调用 } else { newobj[key] = oldObj[key]; } } }
138. 如何判断 this?箭头函数的 this 是什么
参考答案:
有关如何判断 this,可以参阅前面 17 题。
有关箭头函数的 this 指向,可以参阅前面 24、25 题
139. call、apply 以及 bind 函数内部实现是怎么样的
参考答案:
请参阅前面 102 题。
140. 为什么会出现 setTimeout 倒计时误差?如何减少
参考答案:
定时器是属于宏任务(macrotask) 。如果当前执行栈所花费的时间大于定时器时间,那么定时器的回调在宏任务(macrotask) 里,来不及去调用,所有这个时间会有误差。
141. 谈谈你对 JS 执行上下文栈和作用域链的理解
参考答案:
什么是执行上下文?
简而言之,执行上下文是评估和执行 JavaScript 代码的环境的抽象概念。每当 Javascript 代码在运行的时候,它都是在执行上下文中运行。
执行上下文的类型
JavaScript 中有三种执行上下文类型。
- 全局执行上下文 — 这是默认或者说基础的上下文,任何不在函数内部的代码都在全局上下文中。它会执行两件事:创建一个全局的 window 对象(浏览器的情况下),并且设置
this的值等于这个全局对象。一个程序中只会有一个全局执行上下文。- 函数执行上下文 — 每当一个函数被调用时, 都会为该函数创建一个新的上下文。每个函数都有它自己的执行上下文,不过是在函数被调用时创建的。函数上下文可以有任意多个。每当一个新的执行上下文被创建,它会按定义的顺序(将在后文讨论)执行一系列步骤。
- Eval 函数执行上下文 — 执行在
eval函数内部的代码也会有它属于自己的执行上下文。调用栈
调用栈是解析器(如浏览器中的的javascript解析器)的一种机制,可以在脚本调用多个函数时,跟踪每个函数在完成执行时应该返回控制的点。(如什么函数正在执行,什么函数被这个函数调用,下一个调用的函数是谁)
- 当脚本要调用一个函数时,解析器把该函数添加到栈中并且执行这个函数。
- 任何被这个函数调用的函数会进一步添加到调用栈中,并且运行到它们被上个程序调用的位置。
- 当函数运行结束后,解释器将它从堆栈中取出,并在主代码列表中继续执行代码。
- 如果栈占用的空间比分配给它的空间还大,那么则会导致“栈溢出”错误。
作用域链
当访问一个变量时,编译器在执行这段代码时,会首先从当前的作用域中查找是否有这个标识符,如果没有找到,就会去父作用域查找,如果父作用域还没找到继续向上查找,直到全局作用域为止,,而作用域链,就是有当前作用域与上层作用域的一系列变量对象组成,它保证了当前执行的作用域对符合访问权限的变量和函数的有序访问。
142. new 的原理是什么?通过 new 的方式创建对象和通过字面量创建有什么区别?
参考答案:
关于 new 的原理,主要分为以下几步:
创建一个空对象 。
由 this 变量引用该对象 。
该对象继承该函数的原型(更改原型链的指向) 。
把属性和方法加入到 this 引用的对象中。
新创建的对象由 this 引用 ,最后隐式地返回 this,过程如下:
var obj = {}; obj.__proto__ = Base.prototype; Base.call(obj);通过 new 的方式创建对象和通过字面量创建的对象,区别在于 new 出来的对象的原型对象为
构造函数.prototype,而字面量对象的原型对象为Object.prototype示例代码如下:
function Computer() {} var c = new Computer(); var d = {}; console.log(c.__proto__ === Computer.prototype); // true console.log(d.__proto__ === Object.prototype); // true
143. prototype 和 __proto__ 区别是什么?
参考答案:
prototype 是构造函数上面的一个属性,指向实例化出来对象的原型对象。
__proto__ 是对象上面的一个隐式属性,指向自己的原型对象。
144. 使用 ES5 实现一个继承?
参考答案:
请参阅第 47 题。
145. 取数组的最大值(ES5、ES6)
参考答案:
var arr = [3, 5, 8, 1]; // ES5 方式 console.log(Math.max.apply(null, arr)); // 8 // ES6 方式 console.log(Math.max(...arr)); // 8
146. ES6 新的特性有哪些?
参考答案:
请参阅前面第 44 题。
147. Promise 有几种状态, Promise 有什么优缺点 ?
参考答案:
Promise 有三种状态:
pending、fulfilled、rejected(未决定,履行,拒绝),同一时间只能存在一种状态,且状态一旦改变就不能再变。Promise 是一个构造函数,promise 对象代表一项有两种可能结果(成功或失败)的任务,它还持有多个回调,出现不同结果时分别发出相应回调。
- 初始化状态:pending
- 当调用 resolve(成功) 状态:pengding=>fulfilled
- 当调用 reject(失败) 状态:pending=>rejected
Promise 的优点是解决了回调地狱,缺点是代码并没有因为新方法的出现而减少,反而变得更加复杂,同时理解难度也加大。所以后面出现了 async/await 的异步解决方案。
148. Promise 构造函数是同步还是异步执行,then 呢 ? Promise 如何实现 then 处理 ?
参考答案:
promise 构造函数是同步执行的,then 方法是异步执行,then 方法中的内容加入微任务中。
接下来我们来看 promise 如何实现 then 的处理。
我们知道 then 是用来处理 resolve 和 reject 函数的回调。那么首先我们来定义 then 方法。
1、then方法需要两个参数,其中onFulfilled代表resolve成功的回调,onRejected代表reject失败的回调。
then(onFulfilled,onRejected){}2、我们知道promise的状态是不可逆的,在状态发生改变后,即不可再次更改,只有状态为FULFILLED才会调用onFulfilled,状态为REJECTED调用onRejected
then(onFulfilled, onRejected){ if (this.status == Promise.FULFILLED) { onFulfilled(this.value) } if (this.status == Promise.REJECTED) { onRejected(this.value) } }3、then方法的每个方法都不是必须的,所以我们要处理当没有传递参数时,应该设置默认值
then(onFulfilled,onRejected){ if(typeof onFulfilled !=='function'){ onFulfilled = value => value; } if(typeof onRejected !=='function'){ onRejected = value => value; } if(this.status == Promise.FULFILLED){ onFulfilled(this.value) } if(this.status == Promise.REJECTED){ onRejected(this.value) } }4、在执行then方法时,我们要考虑到传递的函数发生异常的情况,如果函数发生异常,我们应该让它进行错误异常处理,统一交给onRejected来处理错误
then(onFulfilled,onRejected){ if(typeof onFulfilled !=='function'){ onFulfilled = value => value; } if(typeof onRejected !=='function'){ onRejected = value => value; } if(this.status == Promise.FULFILLED){ try{onFulfilled(this.value)}catch(error){ onRejected(error) } } if(this.status == Promise.REJECTED){ try{onRejected(this.value)}catch(error){ onRejected(error) } } }5、但是现在我们自己封装的promise有个小问题,我们知道原生的promise中then方法都是异步执行,在一个同步任务执行之后再调用,而我们的现在的情况则是同步调用,因此我们要使用setTimeout来将onFulfilled和onRejected来做异步宏任务执行。
if(this.status=Promise.FULFILLED){ setTimeout(()=>{ try{onFulfilled(this.value)}catch(error){onRejected(error)} }) } if(this.status=Promise.REJECTED){ setTimeout(()=>{ try{onRejected(this.value)}catch(error){onRejected(error)} }) }现在then方法中,可以处理status为FULFILLED和REJECTED的情况,但是不能处理为pedding的情况,接下来进行几处修改。
6、在构造函数中,添加callbacks来保存pending状态时处理函数,当状态改变时循环调用
constructor(executor) { ... this.callbacks = []; ... }7、在then方法中,当status等于pending的情况时,将待执行函数存放到callbacks数组中。
then(onFulfilled,onRejected){ ... if(this.status==Promise.PENDING){ this.callbacks.push({ onFulfilled:value=>{ try { onFulfilled(value); } catch (error) { onRejected(error); } } onRejected: value => { try { onRejected(value); } catch (error) { onRejected(error); } } }) } ... }8、当执行resolve和reject时,在堆callacks数组中的函数进行执行
resolve(vale){ if(this.status==Promise.PENDING){ this.status = Promise.FULFILLED; this.value = value; this.callbacks.map(callback => { callback.onFulfilled(value); }); } } reject(value){ if(this.status==Promise.PENDING){ this.status = Promise.REJECTED; this.value = value; this.callbacks.map(callback => { callback.onRejected(value); }); } }9、then方法中,关于处理pending状态时,异步处理的方法:只需要将resolve与reject执行通过setTimeout定义为异步任务
resolve(value) { if (this.status == Promise.PENDING) { this.status = Promise.FULFILLED; this.value = value; setTimeout(() => { this.callbacks.map(callback => { callback.onFulfilled(value); }); }); } } reject(value) { if (this.status == Promise.PENDING) { this.status = Promise.REJECTED; this.value = value; setTimeout(() => { this.callbacks.map(callback => { callback.onRejected(value); }); }); } }到此,promise的then方法的基本实现就结束了。
149. Promise 和 setTimeout 的区别 ?
参考答案:
JavaScript 将异步任务分为 MacroTask(宏任务) 和 MicroTask(微任务),那么它们区别何在呢?
- 依次执行同步代码直至执行完毕;
- 检查MacroTask 队列,若有触发的异步任务,则取第一个并调用其事件处理函数,然后跳至第三步,若没有需处理的异步任务,则直接跳至第三步;
- 检查MicroTask队列,然后执行所有已触发的异步任务,依次执行事件处理函数,直至执行完毕,然后跳至第二步,若没有需处理的异步任务中,则直接返回第二步,依次执行后续步骤;
- 最后返回第二步,继续检查MacroTask队列,依次执行后续步骤;
- 如此往复,若所有异步任务处理完成,则结束;
Promise 是一个微任务,主线程是一个宏任务,微任务队列会在宏任务后面执行
setTimeout 返回的函数是一个新的宏任务,被放入到宏任务队列
所以 Promise 会先于新的宏任务执行
150. 如何实现 Promise.all ?
参考答案:
Promise.all接收一个promise对象的数组作为参数,当这个数组里的所有promise对象全部变为resolve或 有reject状态出现的时候,它才会去调用.then方法,它们是并发执行的。总结
promise.all的特点1、接收一个
Promise实例的数组或具有Iterator接口的对象,2、如果元素不是
Promise对象,则使用Promise.resolve转成Promise对象3、如果全部成功,状态变为
resolved,返回值将组成一个数组传给回调4、只要有一个失败,状态就变为
rejected,返回值将直接传递给回调
all()的返回值也是新的Promise对象实现
Promise.all方法function promiseAll(promises) { return new Promise(function (resolve, reject) { if (!isArray(promises)) { return reject(new TypeError('arguments must be an array')); } var resolvedCounter = 0; var promiseNum = promises.length; var resolvedValues = new Array(promiseNum); for (var i = 0; i < promiseNum; i++) { (function (i) { Promise.resolve(promises[i]).then(function (value) { resolvedCounter++ resolvedValues[i] = value if (resolvedCounter == promiseNum) { return resolve(resolvedValues) } }, function (reason) { return reject(reason) }) })(i) } }) }
151. 如何实现 Promise.finally ?
参考答案:
finally 方法是 ES2018 的新特性
finally 方法用于指定不管 Promise 对象最后状态如何,都会执行的操作,执行 then 和 catch 后,都会执行 finally 指定的回调函数。
方法一:借助 promise.prototype.finally 包
npm install promise-prototype-finallyconst promiseFinally = require('promise.prototype.finally'); // 向 Promise.prototype 增加 finally() promiseFinally.shim(); // 之后就可以按照上面的使用方法使用了方法二:实现 Promise.finally
Promise.prototype.finally = function (callback) { let P = this.constructor; return this.then( value => P.resolve(callback()).then(() => value), reason => P.resolve(callback()).then(() => { throw reason }) ); };
152. 如何判断 img 加载完成
参考答案:
- 为 img DOM 节点绑定 load 事件
- readystatechange 事件:readyState 为 complete 和 loaded 则表明图片已经加载完毕。测试 IE6-IE10 支持该事件,其它浏览器不支持。
- img 的 complete 属性:轮询不断监测 img 的 complete 属性,如果为 true 则表明图片已经加载完毕,停止轮询。该属性所有浏览器都支持。
153. 如何阻止冒泡?
参考答案:
// 方法一:IE9+,其他主流浏览器 event.stopPropagation() // 方法二:火狐未实现 event.cancelBubble = true; // 方法三:不建议滥用,jq 中可以同时阻止冒泡和默认事件 return false;
154. 如何阻止默认事件?
参考答案:
// 方法一:全支持 event.preventDefault(); // 方法二:该特性已经从 Web 标准中删除,虽然一些浏览器目前仍然支持它,但也许会在未来的某个时间停止支持,请尽量不要使用该特性。 event.returnValue=false; // 方法三:不建议滥用,jq 中可以同时阻止冒泡和默认事件 return false;
155. 如何用原生 js 给一个按钮绑定两个 onclick 事件?
参考答案:
使用 addEventListener 方法来绑定事件,就可以绑定多个同种类型的事件。
156. 拖拽会用到哪些事件
参考答案:
在以前,书写一个拖拽需要用到 mousedown、mousemove、mouseup 这 3 个事件。
HTML5 推出后,新推出了一组拖拽相关的 API,涉及到的事件有 dragstart、dragover、drop 这 3 个事件。
157. document.write 和 innerHTML 的区别
参考答案:
document.write 是直接写入到页面的内容流,如果在写之前没有调用 document.open, 浏览器会自动调用 open。每次写完关闭之后重新调用该函数,会导致页面全部重绘。
innerHTML 则是 DOM 页面元素的一个属性,代表该元素的 html 内容。你可以精确到某一个具体的元素来进行更改。如果想修改 document 的内容,则需要修改 document.documentElement.innerElement。
innerHTML 很多情况下都优于 document.write,其原因在于不会导致页面全部重绘。
158. jQuery 的事件委托方法 bind 、live、delegate、one、on 之间有什么区别?
参考答案:
这几个方法都可以实现事件处理。其中 on 集成了事件处理的所有功能,也是目前推荐使用的方法。
one 是指添加的是一次性事件,意味着只要触发一次该事件,相应的处理方法执行后就自动被删除。
bind 是较早版本的绑定事件的方法,现在已被 on 替代。
live 和 delegate 主要用来做事件委托。live 的版本较早,现在已被废弃。delegate 目前仍然可用,不过也可用 on 来替代它。
159. $(document).ready 方法和 window.onload 有什么区别?
参考答案:
主要有两点区别:
- 执行时机
window.onload 方法是在网页中的所有的元素(包括元素的所有关联文件)都完全加载到浏览器之后才执行。而通过 jQuery 中的
$(document).ready方法注册的事件处理程序,只要在 DOM 完全就绪时,就可以调用了,比如一张图片只要标签完成,不用等这个图片加载完成,就可以设置图片的宽高的属性或样式等。其实从二者的英文字母可以大概理解上面的话,onload 即加载完成,ready 即 DOM 准备就绪。
- 注册事件
$(document).ready方法可以多次使用而注册不同的事件处理程序,而 window.onload 一次只能保存对一个函数的引用,多次绑定函数只会覆盖前面的函数。
160. jquery 中 . g e t ( ) 提交和 .get()提交和 .get()提交和.post()提交有区别吗?
参考答案:
相同点:都是异步请求的方式来获取服务端的数据
不同点:
- 请求方式不同:
$.get()方法使用 GET 方法来进行异步请求的。$.post()方法使用 POST 方法来进行异步请求的。- 参数传递方式不同: GET 请求会将参数跟在 URL 后进行传递,而 POST 请求则是作为 HTTP 消息的实体内容发送给 Web 服务器 的,这种传递是对用户不可见的。
- 数据传输大小不同: GET 方式传输的数据大小不能超过 2KB 而 POST 要大的多
- 安全问题: GET 方式请求的数据会被浏览器缓存起来,因此有安全问题。
161. await async 如何实现 (阿里)
参考答案:
async 函数只是 promise 的语法糖,它的底层实际使用的是 generator,而 generator 又是基于 promise 的。实际上,在 babel 编译 async 函数的时候,也会转化成 generatora 函数,并使用自动执行器来执行它。
实现代码示例:
function asyncToGenerator(generatorFunc) { return function() { const gen = generatorFunc.apply(this, arguments) return new Promise((resolve, reject) => { function step(key, arg) { let generatorResult try { generatorResult = gen[key](arg) } catch (error) { return reject(error) } const { value, done } = generatorResult if (done) { return resolve(value) } else { return Promise.resolve(value).then(val => step('next', val), err => step('throw', err)) } } step("next") }) } }关于代码的解析,可以参阅:https://blog.csdn.net/xgangzai/article/details/106536325
162. clientWidth,offsetWidth,scrollWidth 的区别
参考答案:
clientWidth = width+左右 padding
offsetWidth = width + 左右 padding + 左右 boder
scrollWidth:获取指定标签内容层的真实宽度(可视区域宽度+被隐藏区域宽度)。
163. 产生一个不重复的随机数组
参考答案:
示例代码如下:
// 生成随机数 function randomNumBoth(Min, Max) { var Range = Max - Min; var Rand = Math.random(); var num = Min + Math.round(Rand * Range); //四舍五入 return num; } // 生成数组 function randomArr(len, min, max) { if ((max - min) < len) { //可生成数的范围小于数组长度 return null; } var hash = []; while (hash.length < len) { var num = randomNumBoth(min, max); if (hash.indexOf(num) == -1) { hash.push(num); } } return hash; } // 测试 console.log(randomArr(10, 1, 100));在上面的代码中,我们封装了一个 randomArr 方法来生成这个不重复的随机数组,该方法接收三个参数,len、min 和 max,分别表示数组的长度、最小值和最大值。randomNumBoth 方法用来生成随机数。
164. continue 和 break 的区别
参考答案:
- break:用于永久终止循环。即不执行本次循环中 break 后面的语句,直接跳出循环。
- continue:用于终止本次循环。即本次循环中 continue 后面的代码不执行,进行下一次循环的入口判断。
165. 如何在 jquery 上扩展插件,以及内部原理(腾讯)
参考答案:
通过 $.extend(object); 为整个 jQuery 类添加新的方法。
例如:
$.extend({ sayHello: function(name) { console.log('Hello,' + (name ? name : 'World') + '!'); }, showAge(){ console.log(18); } }) // 外部使用 $.sayHello(); // Hello,World! 无参调用 $.sayHello('zhangsan'); // Hello,zhangsan! 带参调用通过 $.fn.extend(object); 给 jQuery 对象添加方法。
例如:
$.fn.extend({ swiper: function (options) { var obj = new Swiper(options, this); // 实例化 Swiper 对象 obj.init(); // 调用对象的 init 方法 } }) // 外部使用 $('#id').swiper();extend 方法内部原理
jQuery.extend( target [, object1 ] [, objectN ] )对后一个参数进行循环,然后把后面参数上所有的字段都给了第一个字段,若第一个参数里有相同的字段,则进行覆盖操作,否则就添加一个新的字段。
解析如下:
// 为与源码的下标对应上,我们把第一个参数称为第0个参数,依次类推 jQuery.extend = jQuery.fn.extend = function() { var options, name, src, copy, copyIsArray, clone, target = arguments[0] || {}, // 默认第0个参数为目标参数 i = 1, // i表示从第几个参数凯斯想目标参数进行合并,默认从第1个参数开始向第0个参数进行合并 length = arguments.length, deep = false; // 默认为浅度拷贝 // 判断第0个参数的类型,若第0个参数是boolean类型,则获取其为true还是false // 同时将第1个参数作为目标参数,i从当前目标参数的下一个 // Handle a deep copy situation if ( typeof target === "boolean" ) { deep = target; // Skip the boolean and the target target = arguments[ i ] || {}; i++; } // 判断目标参数的类型,若目标参数既不是object类型,也不是function类型,则为目标参数重新赋值 // Handle case when target is a string or something (possible in deep copy) if ( typeof target !== "object" && !jQuery.isFunction(target) ) { target = {}; } // 若目标参数后面没有参数了,如$.extend({_name:'wenzi'}), $.extend(true, {_name:'wenzi'}) // 则目标参数即为jQuery本身,而target表示的参数不再为目标参数 // Extend jQuery itself if only one argument is passed if ( i === length ) { target = this; i--; } // 从第i个参数开始 for ( ; i < length; i++ ) { // 获取第i个参数,且该参数不为null, // 比如$.extend(target, {}, null);中的第2个参数null是不参与合并的 // Only deal with non-null/undefined values if ( (options = arguments[ i ]) != null ) { // 使用for~in获取该参数中所有的字段 // Extend the base object for ( name in options ) { src = target[ name ]; // 目标参数中name字段的值 copy = options[ name ]; // 当前参数中name字段的值 // 若参数中字段的值就是目标参数,停止赋值,进行下一个字段的赋值 // 这是为了防止无限的循环嵌套,我们把这个称为,在下面进行比较详细的讲解 // Prevent never-ending loop if ( target === copy ) { continue; } // 若deep为true,且当前参数中name字段的值存在且为object类型或Array类型,则进行深度赋值 // Recurse if we're merging plain objects or arrays if ( deep && copy && ( jQuery.isPlainObject(copy) || (copyIsArray = jQuery.isArray(copy)) ) ) { // 若当前参数中name字段的值为Array类型 // 判断目标参数中name字段的值是否存在,若存在则使用原来的,否则进行初始化 if ( copyIsArray ) { copyIsArray = false; clone = src && jQuery.isArray(src) ? src : []; } else { // 若原对象存在,则直接进行使用,而不是创建 clone = src && jQuery.isPlainObject(src) ? src : {}; } // 递归处理,此处为2.2 // Never move original objects, clone them target[ name ] = jQuery.extend( deep, clone, copy ); // deep为false,则表示浅度拷贝,直接进行赋值 // 若copy是简单的类型且存在值,则直接进行赋值 // Don't bring in undefined values } else if ( copy !== undefined ) { // 若原对象存在name属性,则直接覆盖掉;若不存在,则创建新的属性 target[ name ] = copy; } } } } // 返回修改后的目标参数 // Return the modified object return target; };
166. async/await 如何捕获错误
参考答案:
可以使用 try…catch 来进行错误的捕获
示例代码:
async function test() { try { const res = await test1() } catch (err) { console.log(err) } console.log("test") }
167. Proxy 对比 Object.defineProperty 的优势
参考答案:
Proxy 的优势如下:
- Object.defineProperty 只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历,而 Proxy 可以直接监听对象而非属性;
- Object.defineProperty 无法监控到数组下标的变化,而 Proxy 可以直接监听数组的变化;
- Proxy 有多达 13 种拦截方法;
- Proxy 作为新标准将受到浏览器厂商重点持续的性能优化;
168. 原型链,可以改变原型链的规则吗?
参考答案:
每个对象都可以有一个原型__proto__,这个原型还可以有它自己的原型,以此类推,形成一个原型链。查找特定属性的时候,我们先去这个对象里去找,如果没有的话就去它的原型对象里面去,如果还是没有的话再去向原型对象的原型对象里去寻找。这个操作被委托在整个原型链上,这个就是我们说的原型链。
我们可以通过手动赋值的方式来改变原型链所对应的原型对象。
169. 讲一讲继承的所有方式都有什么?手写一个寄生组合式继承
参考答案:
可以参阅前面第 9、18、47 题答案。
其中圣杯模式就是寄生组合式继承。
170. JS 基本数据类型有哪些?栈和堆有什么区别,为什么要这样存储。(快手)
参考答案:
关于 JS 基本数据类型有哪些这个问题,可以参阅前面 26 题。
栈和堆的区别在于堆是动态分配内存,内存大小不一,也不会自动释放。栈是自动分配相对固定大小的内存空间,并由系统自动释放。
在 js 中,基本数据都是直接按值存储在栈中的,每种类型的数据占用的内存空间的大小是确定的,并由系统自动分配和自动释放。这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
js 中其他类型的数据被称为引用类型的数据(如对象、数组、函数等),它们是通过拷贝和 new 出来的,这样的数据存储于堆中。其实,说存储于堆中,也不太准确,因为,引用类型的数据的地址指针是存储于栈中的,当我们想要访问引用类型的值的时候,需要先从栈中获得对象的地址指针,然后,在通过地址指针找到堆中的所需要的数据。
171. setTimeout(() => {}, 0) 什么时候执行
参考答案:
因为 setTimeout 是异步代码,所以即使后面的时间为 0,也要等到同步代码执行完毕后才会执行。
172. js 有函数重载吗(网易)
参考答案:
所谓函数重载,是方法名称进行重用的一种技术形式,其主要特点是“方法名相同,参数的类型或个数不相同”,在调用时会根据传递的参数类型和个数的不同来执行不同的方法体。
在 JS 中,可以通过在函数内容判断形参的类型或个数来执行不同的代码块,从而达到模拟函数重载的效果。
173. 给你一个数组,计算每个数出现的次数,如果每个数组返回的数都是独一无二的就返回 true 相反则返回的 flase
参考答案:
输入:arr = [1,2,2,1,1,3]
输出:true
解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
代码示例:
function uniqueOccurrences(arr) { let uniqueArr = [...new Set(arr)] let countArr = [] for (let i = 0; i < uniqueArr.length; i++) { countArr.push(arr.filter(item => item == uniqueArr[i]).length) } return countArr.length == new Set(countArr).size }; // 测试 console.log(uniqueOccurrences([1, 2, 2, 1, 1, 3])); // true console.log(uniqueOccurrences([1, 2, 2, 1, 1, 3, 2])); // false
174. 封装一个能够统计重复的字符的函数,例如 aaabbbdddddfff 转化为 3a3b5d3f
参考答案:
function compression(str) { if (str.length == 0) { return 0; } var len = str.length; var str2 = ""; var i = 0; var num = 1; while (i < len) { if (str.charAt(i) == str.charAt(i + 1)) { num++; } else { str2 += num; str2 += str.charAt(i); num = 1; } i++; } return str2; } // 测试: console.log(compression('aaabbbdddddfff')); // 3a3b5d3f
175. 写出代码的执行结果,并解释为什么?
function a() {
console.log(1);
}
(function() {
if (false) {
function a() {
console.log(2);
}
}
console.log(typeof a);
a();
})()
参考答案:
会报错,a is not a function。
因为立即执行函数里面有函数 a,a 会被提升到该函数作用域的最顶端,但是由于判断条件是 false,所以不会进入到条件语句里面, a 也就没有值。所以 typeof 打印出来是 undefined。而后面在尝试调用方法,自然就会报错。
176. 写出代码的执行结果,并解释为什么?
alert(a);
a();
var a = 3;
function a() {
alert(10);
};
alert(a);
a = 6;
a();
参考答案:
首先打印 function a() {alert(10);};
然后打印 10
最后打印 3
解析:
首先 a 变量会被提升到该全局作用域的最顶端,然后值为对应的函数,所以第一次打印出来的是函数。
接下来调用这个 a 函数,所以打印出 10
最后给这个 a 赋值为 3,然后又 alert,所以打印出 3。
之后 a 的值还会发生改变,但是由于没有 alert,说明不会再打印出其他值了。
177. 写出下面程序的打印顺序,并简要说明原因
setTimeout(function () {
console.log("set1");
new Promise(function (resolve) {
resolve();
}).then(function () {
new Promise(function (resolve) {
resolve();
}).then(function () {
console.log("then4");
})
console.log('then2');
})
});
new Promise(function (resolve) {
console.log('pr1');
resolve();
}).then(function () {
console.log('then1');
});
setTimeout(function () {
console.log("set2");
});
console.log(2);
new Promise(function (resolve) {
resolve();
}).then(function () {
console.log('then3');
})
参考答案:
打印结果为:
pr1
2
then1
then3
set1
then2
then4
set2
178. javascript 中什么是伪数组?如何将伪数组转换为标准数组
参考答案:
在 JavaScript 中,arguments 就是一个伪数组对象。关于 arguments 具体可以参阅后面 250 题。
可以使用 ES6 的扩展运算符来将伪数组转换为标准数组
例如:
var arr = [...arguments];
179. array 和 object 的区别
参考答案:
数组表示有序数据的集合,对象表示无序数据的集合。如果数据顺序很重要的话,就用数组,否则就用对象。
180. jquery 事件委托
参考答案:
在 jquery 中使用 on 来绑定事件的时候,传入第二个参数即可。例如:
$("ul").on("click","li",function () { alert(1); })
181. JS 基本数据类型
参考答案:
请参阅前面第 26 题
182. 请实现一个模块 math,支持链式调用math.add(2,4).minus(3).times(2);
参考答案:
示例代码:
class Math { constructor(value) { let hasInitValue = true; if (value === undefined) { value = NaN; hasInitValue = false; } Object.defineProperties(this, { value: { enumerable: true, value: value, }, hasInitValue: { enumerable: false, value: hasInitValue, }, }); } add(...args) { const init = this.hasInitValue ? this.value : args.shift(); const value = args.reduce((pv, cv) => pv + cv, init); return new Math(value); } minus(...args) { const init = this.hasInitValue ? this.value : args.shift(); const value = args.reduce((pv, cv) => pv - cv, init); return new Math(value); } times(...args) { const init = this.hasInitValue ? this.value : args.shift(); const value = args.reduce((pv, cv) => pv * cv, init); return new Math(value); } divide(...args) { const init = this.hasInitValue ? this.value : args.shift(); const value = args.reduce((pv, cv) => pv / cv, init); return new Math(value); } toJSON() { return this.valueOf(); } toString() { return String(this.valueOf()); } valueOf() { return this.value; } [Symbol.toPrimitive](hint) { const value = this.value; if (hint === 'string') { return String(value); } else { return value; } } } export default new Math();
183. 请简述 ES6 代码转成 ES5 代码的实现思路。
参考答案:
说到 ES6 代码转成 ES5 代码,我们肯定会想到 Babel。所以,我们可以参考 Babel 的实现方式。
那么 Babel 是如何把 ES6 转成 ES5 呢,其大致分为三步:
- 将代码字符串解析成抽象语法树,即所谓的 AST
- 对 AST 进行处理,在这个阶段可以对 ES6 代码进行相应转换,即转成 ES5 代码
- 根据处理后的 AST 再生成代码字符串
184. 下列代码的执行结果
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function () {
console.log('setTimeout');
}, 0);
async1();
new Promise(function (resolve) {
console.log('promise1');
resolve();
}).then(function () {
console.log('promise2');
});
console.log('script end');
参考答案:
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeout
解析:
在此之前我们需要知道以下几点:
- setTimeout 属于宏任务
- Promise 本身是同步的立即执行函数,Promise.then 属于微任务
- async 方法执行时,遇到 await 会立即执行表达式,表达式之后的代码放到微任务执行
第一次执行:执行同步代码
Tasks(宏任务):run script、 setTimeout callback Microtasks(微任务):await、Promise then JS stack(执行栈): script Log: script start、async1 start、async2、promise1、script end第二次执行:执行宏任务后,检测到微任务队列中不为空、一次性执行完所有微任务
Tasks(宏任务):run script、 setTimeout callback Microtasks(微任务):Promise then JS stack(执行栈): await Log: script start、async1 start、async2、promise1、script end、async1 end、promise2第三次执行:当微任务队列中为空时,执行宏任务,执行
setTimeout callback,打印日志。Tasks(宏任务):null Microtasks(微任务):null JS stack(执行栈):setTimeout callback Log: script start、async1 start、async2、promise1、script end、async1 end、promise2、setTimeout
185. JS 有哪些内置对象?
参考答案:
数据封装类对象:String,Boolean,Number,Array 和 Object
其他对象:Function,Arguments,Math,Date,RegExp,Error
186. DOM 怎样添加、移除、移动、复制、创建和查找节点
参考答案:
请参阅前面 121 题。
187. eval 是做什么的?
参考答案:
此函数可以接受一个字符串 str 作为参数,并把此 str 当做一段 javascript 代码去执行,如果 str 执行结果是一个值则返回此值,否则返回 undefined。如果参数不是一个字符串,则直接返回该参数。
例如:
eval("var a=1");//声明一个变量a并赋值1。 eval("2+3");//5执行加运算,并返回运算值。 eval("mytest()");//执行mytest()函数。 eval("{b:2}");//声明一个对象。
188. null 和 undefined 的区别?
参考答案:
请参阅前面第 29 题。
189. new 操作符具体干了什么呢?
参考答案:
- 创建一个空对象 。
- 由 this 变量引用该对象 。
- 该对象继承该函数的原型(更改原型链的指向) 。
- 把属性和方法加入到 this 引用的对象中。
- 新创建的对象由 this 引用 ,最后隐式地返回 this,过程如下:
var obj = {}; obj.__proto__ = Base.prototype; Base.call(obj);
190. 去除字符串中的空格
参考答案:
方法一:replace正则匹配方法
代码示例:
- 去除字符串内所有的空格:
str = str.replace(/\s*/g,"");- 去除字符串内两头的空格:
str = str.replace(/^\s*|\s*$/g,"");- 去除字符串内左侧的空格:
str = str.replace(/^\s*/,"");- 去除字符串内右侧的空格:
str = str.replace(/(\s*$)/g,"");方法二:字符串原生 trim 方法
trim 方法能够去掉两侧空格返回新的字符串,不能去掉中间的空格
191. 常见的内存泄露,以及解决方案
参考答案:
内存泄露概念
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
内存泄漏通常情况下只能由获得程序源代码和程序员才能分析出来。然而,有不少人习惯于把任何不需要的内存使用的增加描述为内存泄漏,即使严格意义上来说这是不准确的。
JS 垃圾收集机制
JS 具有自动回收垃圾的机制,即执行环境会负责管理程序执行中使用的内存。在C和C++等其他语言中,开发者的需要手动跟踪管理内存的使用情况。在编写 JS 代码的时候,开发人员不用再关心内存使用的问题,所需内存的分配 以及无用的回收完全实现了自动管理。
Js中最常用的垃圾收集方式是标记清除(mark-and-sweep)。当变量进入环境(例如,在函数中声明一个变量)时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占的内存,因为只要执行流进入相应的环境,就可能用到它们。而当变量离开环境时,这将其 标记为“离开环境”。
常见内存泄漏以及解决方案
- 意外的全局变量
Js处理未定义变量的方式比较宽松:未定义的变量会在全局对象创建一个新变量。在浏览器中,全局对象是window。
function foo(arg) { bar = "this is a hidden global variable"; //等同于window.bar="this is a hidden global variable" this.bar2= "potential accidental global";//这里的this 指向了全局对象(window),等同于window.bar2="potential accidental global" }解决方法:在 JavaScript 程序中添加,开启严格模式’use strict’,可以有效地避免上述问题。
注意:那些用来临时存储大量数据的全局变量,确保在处理完这些数据后将其设置为null或重新赋值。与全局变量相关的增加内存消耗的一个主因是缓存。缓存数据是为了重用,缓存必须有一个大小上限才有用。高内存消耗导致缓存突破上限,因为缓 存内容无法被回收。
- 循环引用
在js的内存管理环境中,对象 A 如果有访问对象 B 的权限,叫做对象 A 引用对象 B。引用计数的策略是将“对象是否不再需要”简化成“对象有没有其他对象引用到它”,如果没有对象引用这个对象,那么这个对象将会被回收 。
let obj1 = { a: 1 }; // 一个对象(称之为 A)被创建,赋值给 obj1,A 的引用个数为 1 let obj2 = obj1; // A 的引用个数变为 2 obj1 = 0; // A 的引用个数变为 1 obj2 = 0; // A 的引用个数变为 0,此时对象 A 就可以被垃圾回收了但是引用计数有个最大的问题: 循环引用。
function func() { let obj1 = {}; let obj2 = {}; obj1.a = obj2; // obj1 引用 obj2 obj2.a = obj1; // obj2 引用 obj1 }当函数 func 执行结束后,返回值为 undefined,所以整个函数以及内部的变量都应该被回收,但根据引用计数方法,obj1 和 obj2 的引用次数都不为 0,所以他们不会被回收。要解决循环引用的问题,最好是在不使用它们的时候手工将它们设为空。上面的例子可以这么做:
obj1 = null; obj2 = null;
- 被遗忘的计时器和回调函数
let someResource = getData(); setInterval(() => { const node = document.getElementById('Node'); if(node) { node.innerhtml = JSON.stringify(someResource)); } }, 1000);上面的例子中,我们每隔一秒就将得到的数据放入到文档节点中去。
但在 setInterval 没有结束前,回调函数里的变量以及回调函数本身都无法被回收。那什么才叫结束呢?
就是调用了 clearInterval。如果回调函数内没有做什么事情,并且也没有被 clear 掉的话,就会造成内存泄漏。
不仅如此,如果回调函数没有被回收,那么回调函数内依赖的变量也没法被回收。上面的例子中,someResource 就没法被回收。同样的,setTiemout 也会有同样的问题。所以,当不需要 interval 或者 timeout 时,最好调用 clearInterval 或者 clearTimeout。
- DOM 泄漏
在 JS 中对DOM操作是非常耗时的。因为JavaScript/ECMAScript引擎独立于渲染引擎,而DOM是位于渲染引擎,相互访问需要消耗一定的资源。 而 IE 的 DOM 回收机制便是采用引用计数的,以下主要针对 IE 而言的。
a. 没有清理的 DOM 元素引用
var refA = document.getElementById('refA'); document.body.removeChild(refA); // refA 不能回收,因为存在变量 refA 对它的引用。将其对 refA 引用释放,但还是无法回收 refA。解决办法:refA = null;
b. 给 DOM 对象添加的属性是一个对象的引用
var MyObject = {}; document.getElementById('mydiv').myProp = MyObject;解决方法:
在 window.onunload 事件中写上: document.getElementById(‘mydiv’).myProp = null;c. DOM 对象与 JS 对象相互引用
function Encapsulator(element) { this.elementReference = element; element.myProp = this; } new Encapsulator(document.getElementById('myDiv'));解决方法: 在 onunload 事件中写上: document.getElementById(‘myDiv’).myProp = null;
d. 给 DOM 对象用 attachEvent 绑定事件
function doClick() {} element.attachEvent("onclick", doClick);解决方法: 在onunload事件中写上: element.detachEvent(‘onclick’, doClick);
e. 从外到内执行 appendChild。这时即使调用 removeChild 也无法释放
var parentDiv = document.createElement("div"); var childDiv = document.createElement("div"); document.body.appendChild(parentDiv); parentDiv.appendChild(childDiv);解决方法: 从内到外执行 appendChild:
var parentDiv = document.createElement("div"); var childDiv = document.createElement("div"); parentDiv.appendChild(childDiv); document.body.appendChild(parentDiv);
- JS 的闭包
闭包在 IE6 下会造成内存泄漏,但是现在已经无须考虑了。值得注意的是闭包本身不会造成内存泄漏,但闭包过多很容易导致内存泄漏。闭包会造成对象引用的生命周期脱离当前函数的上下文,如果闭包如果使用不当,可以导致环形引用(circular reference),类似于死锁,只能避免,无法发生之后解决,即使有垃圾回收也还是会内存泄露。
- console
控制台日志记录对总体内存配置文件的影响可能是许多开发人员都未想到的极其重大的问题。记录错误的对象可以将大量数据保留在内存中。注意,这也适用于:
(1) 在用户键入 JavaScript 时,在控制台中的一个交互式会话期间记录的对象。
(2) 由 console.log 和 console.dir 方法记录的对象。
192. 箭头函数和普通函数里面的 this 有什么区别
参考答案:
请参阅前面第 24、25 题
193. 设计⼀个⽅法(isPalindrom)以判断是否回⽂(颠倒后的字符串和原来的字符串⼀样为回⽂)
参考答案:
示例代码如下:
function isPalindrome(str) { if (typeof str !== 'string') { return false } return str.split('').reverse().join('') === str } // 测试 console.log(isPalindrome('HelleH')); // true console.log(isPalindrome('Hello')); // false
194. 设计⼀个⽅法(findMaxDuplicateChar)以统计字符串中出现最多次数的字符
参考答案:
示例代码如下:
function findMaxDuplicateChar(str) { let cnt = {}, //用来记录所有的字符的出现频次 c = ''; //用来记录最大频次的字符 for (let i = 0; i < str.length; i++) { let ci = str[i]; if (!cnt[ci]) { cnt[ci] = 1; } else { cnt[ci]++; } if (c == '' || cnt[ci] > cnt[c]) { c = ci; } } console.log(cnt); // { H: 1, e: 1, l: 3, o: 2, ' ': 1, W: 1, r: 1, d: 1 } return c; } // 测试 console.log(findMaxDuplicateChar('Hello World')); // l
195. 设计⼀段代码,使得通过点击按钮可以在 span 中显示⽂本框中输⼊的值
参考答案:
示例代码如下:
<body> <span id="showContent">在右侧输入框中输入内容span> <input type="text" name="content" id="content"> <button id="btn">更新内容button> <script> btn.onclick = function(){ var content = document.getElementById('content').value; if(content){ document.getElementById('showContent').innerHTML = content; } } script> body>
196. map 和 forEach 的区别?
参考答案:
两者区别
forEach()方法不会返回执行结果,而是undefined。也就是说,
forEach()会修改原来的数组。而map()方法会得到一个新的数组并返回。适用场景
forEach适合于你并不打算改变数据的时候,而只是想用数据做一些事情 – 比如存入数据库或则打印出来。
map()适用于你要改变数据值的时候。不仅仅在于它更快,而且返回一个新的数组。这样的优点在于你可以使用复合(composition)(map, filter, reduce 等组合使用)来玩出更多的花样。
197. Array 的常用方法
参考答案:
Array 的常用方法很多,挑选几个自己在实际开发中用的比较多的方法回答即可。
更多 Array 相关用法可以参阅:https://www.w3school.com.cn/jsref/jsref_obj_array.asp
198. 数组去重的多种实现方式
参考答案:
请参阅前面第 2 题答案。
199. 什么是预解析(预编译)
参考答案:
所谓的预解析(预编译)就是:在当前作用域中,JavaScript 代码执行之前,浏览器首先会默认的把所有带 var 和 function 声明的变量进行提前的声明或者定义。
另外,var 声明的变量和 function 声明的函数在预解析的时候有区别,var 声明的变量在预解析的时候只是提前的声明,function 声明的函数在预解析的时候会提前声明并且会同时定义。也就是说 var 声明的变量和 function 声明的函数的区别是在声明的同时有没有同时进行定义。
200. 原始值类型和引用值类型的区别是什么?
参考答案:
可以参阅前面第 26 题
201. 冒泡排序的思路,不用 sort
参考答案:
示例代码如下:
var examplearr = [8, 94, 15, 88, 55, 76, 21, 39]; function sortarr(arr) { for (i = 0; i < arr.length - 1; i++) { for (j = 0; j < arr.length - 1 - i; j++) { if (arr[j] > arr[j + 1]) { var temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } return arr; } sortarr(examplearr); console.log(examplearr); // [8, 15, 21, 39, 55, 76, 88, 94]
202. symbol 用途
参考答案:
可以用来表示一个独一无二的变量防止命名冲突。但是面试官问还有吗?我没想出其他的用处就直接答我不知道了,还可以利用 symbol 不会被常规的方法(除了 Object.getOwnPropertySymbols 外)遍历到,所以可以用来模拟私有变量。
主要用来提供遍历接口,布置了 symbol.iterator 的对象才可以使用 for···of 循环,可以统一处理数据结构。调用之后回返回一个遍历器对象,包含有一个 next 方法,使用 next 方法后有两个返回值 value 和 done 分别表示函数当前执行位置的值和是否遍历完毕。
Symbol.for() 可以在全局访问 symbol
203. 什么是函数式编程,应用场景是什么
参考答案:
函数式编程和面向对象编程一样,是一种编程范式。强调执行的过程而非结果,通过一系列的嵌套的函数调用,完成一个运算过程。
它主要有以下几个特点:
- 函数是"一等公民":函数优先,和其他数据类型一样。
- 只用"表达式",不用"语句":通过表达式(expression)计算过程得到一个返回值,而不是通过一个语句(statement)修改某一个状态。
- 无副作用:不污染变量,同一个输入永远得到同一个数据。
- 不可变性:前面一提到,不修改变量,返回一个新的值。
函数式编程的概念其实出来也已经好几十年了,我们能在很多编程语言身上看到它的身影。比如比较纯粹的 Haskell,以及一些语言开始逐渐成为多范式编程语言,比如 Swift,还有 Kotlin,Java,Js 等都开始具备函数式编程的特性。
函数式编程在前端的应用场景
- Stateless components:React 在 0.14 之后推出的无状态组件
- Redux
函数式编程在后端的应用场景
- Lambda 架构
204. 事件以及事件相关的兼容性问题
参考答案:
事件最早是在 IE3 和 Navigator2 中出现的,当时是作为分担服务器运算负担的一种手段。要实现和网页的互动,就需要通过 JavaScript 里面的事件来实现。
每次用户与一个网页进行交互,例如点击链接,按下一个按键或者移动鼠标时,就会触发一个事件。我们的程序可以检测这些事件,然后对此作出响应。从而形成一种交互。
当我们绑定事件时,需要遵循事件三要素
- 事件源:是指那个元素引发的事件。比如当你点击图标的时候,会跳转到百度首页。那么这个图标就是事件源。
- 事件:事件是指执行的动作。例如,点击,鼠标划过,按下键盘,获得焦点。
- 事件驱动程序:事件驱动程序即执行的结果。例如,当你点击图标的时候,会跳转到百度首页。那么跳转到百度首页就是事件的处理结果。
事件源.事件 = function() { 事件处理函数 }常见的兼容问题,可以参阅前面 135 题。
205. JS 小数不精准,如何计算
参考答案:
方法一:指定要保留的小数位数(0.1+0.2).toFixed(1) = 0.3;这个方法toFixed是进行四舍五入的也不是很精准,对于计算金额这种严谨的问题,不推荐使用,而且不同浏览器对toFixed的计算结果也存在差异。
方法二:把需要计算的数字升级(乘以10的n次幂)成计算机能够精确识别的整数,等计算完毕再降级(除以10的n次幂),这是大部分编程语言处理精度差异的通用方法。
206. 写一个 mySetInterVal(fn, a, b),每次间隔 a,a+b,a+2b 的时间,然后写一个 myClear,停止上面的 mySetInterVal
参考答案:
该题的思路就是每一次在定时器中重启定时器并且在时间每一次都加 b,并且要把定时器返回回来,可以作为myClear的参数。
代码如下:
var mySetInterVal = function (fn, a, b) { var timer = null; var settimer = function (fn, a, b) { timer = setTimeout(() => { fn(); settimer(fn, a + b, b); }, a); } settimer(fn, a, b); return timer; } var timer = mySetInterVal(() => { console.log('timer') }, 1000, 1000); var myClear = function (timer) { timer && clearTimeout(timer); }
207. 合并二维有序数组成一维有序数组,归并排序的思路
参考答案:
示例代码如下:
function merge(left, right) { let result = [] while (left.length > 0 && right.length > 0) { if (left[0] < right[0]) { result.push(left.shift()) } else { result.push(right.shift()) } } return result.concat(left).concat(right) } function mergeSort(arr) { if (arr.length === 1) { return arr } while (arr.length > 1) { let arrayItem1 = arr.shift(); let arrayItem2 = arr.shift(); let mergeArr = merge(arrayItem1, arrayItem2); arr.push(mergeArr); } return arr[0] } let arr1 = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6]]; let arr2 = [[1, 4, 6], [7, 8, 10], [2, 6, 9], [3, 7, 13], [1, 5, 12]]; console.log(mergeSort(arr1)) console.log(mergeSort(arr2))
208. 给定一个字符串,请你找出其中不含有重复字符的最长子串的长度。
参考答案:
首先,我们肯定需要封装一个函数,而这个函数接收一个字符串作为参数,返回不含有重复字符的子串长度。来看下面的示例:
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。示例代码:
var lengthOfLongestSubstring = function (s) { var y = []; var temp = []; var maxs = 0; if (s == "") { return 0; } if (s.length == 1) { return 1; } for (var i = 0; i < s.length; i++) { if (temp.includes(s[i])) { y.push(temp.length); temp.shift(); continue; } else { temp.push(s[i]) y.push(temp.length); } } for (var j = 0; j < y.length; j++) { if (maxs <= y[j]) { maxs = y[j] } } return maxs; }; // 测试 console.log(lengthOfLongestSubstring('abcabcbb')); // 3 console.log(lengthOfLongestSubstring('bbbbb')); // 1 console.log(lengthOfLongestSubstring('pwwkew')); // 3
209. 有一堆整数,请把他们分成三份,确保每一份和尽量相等(11,42,23,4,5,6 4 5 6 11 23 42 56 78 90)(滴滴 2020)
参考答案:
本道题目是一道考察算法的题目,主要是考察编程基本功和一定的想像力。
具体的实现如下:
function fun(total, n) { //先对整个数组进行排序 total.sort((a, b) => a - b); //求和 var sum = 0; for (var i = 0; i < total.length; i++) { sum += total[i]; } var avg = Math.ceil(sum / n); //结果数组 var result = []; //长度为n for (var i = 0; i < n; i++) { result[i] = [total.pop()]; result[i].sum = result[i][0]; //组成一个分数组 while (result[i].sum < avg && total.length > 0) { for (var j = 0; j < total.length; j++) { if (result[i].sum + total[j] >= avg) { result[i].push(total[j]); result[i].sum += total[j]; break; } } if (j == total.length) { result[i].push(total.pop()); result[i].sum += result[i][result[i].length - 1]; } else { //从数组中移除此元素 total.splice(j, 1); } } sum -= result[i].sum; avg = Math.ceil(sum / (n - 1 - i)); } return result; } // 测试 var arr = [11, 42, 23, 4, 5, 6, 4, 5, 6, 11, 23, 42, 56, 78, 90]; console.log(fun(arr, 3)); // [ // [ 90, 56, sum: 146 ], // [ 78, 42, 11, sum: 131 ], // [ 42, 23, 23, 11, 6, 6, 5, 5, 4, 4, sum: 129 ] // ]
210. 手写发布订阅(头条2020)
参考答案:
示例代码如下:
<body> <div id="app"> <p>this is a testp> {{msg}}<input type="text" v-model="msg">{{msg}} div> <script src="./index.js">script> <script> const vm = new Vue({ el : '#app', data : { msg : '' } }); script> body>/* 1. 创建 Vue 构造函数 在 Vue 构造函数中,调用了 observer 函数,该函数的作用就是对数据进行劫持 劫持具体要做的事儿:复制一份数据,但是不是单纯的复制,而是增加了 getter、setter 2. 书写 compile 函数。该函数主要作用于模板,从模板里面要提取信息 提取的东西主要有两个:{{}} 和 v-model 3. 创建发布者 Dep 的构造函数,如果数据发生变化,发布者就会遍历内部的数组(花名册),通知订阅者修改数据 4. 创建订阅者 Watcher 的构造函数,如果有数据的变化,发布者就会通知订阅者,订阅者上面存在 update 方法,会进行修改 */ function Vue(options){ // this 代表 Vue 的实例对象,本例中就是 vm // options.data 这就是实际的数据 {msg : 'xiejie'} observer(this,options.data); this.$el = options.el; compile(this); } // 用于对模板进行信息提取,主要提取 {{}} 和 v-model,然后进行一些操作 // {{ }} 会成为观察者,v-model 所对应的控件来绑定事件 function compile(vm){ var el = document.querySelector(vm.$el); // el 所对应的值为...var documentFragment = document.createDocumentFragment(); // 创建了一个空的文档碎片 var reg = /\{\{(.*)\}\}/; // 创建正则表达式 匹配 {{ }} while(el.childNodes[0]){ var child = el.childNodes[0]; // 将第一个子节点存储到 child if(child.nodeType == 1){ // 如果能够进入此 if,说明该节点是一个元素节点 for(var key in child.attributes){ // 遍历该元素节点的每一个属性,拿到的就是 type="text" v-model="msg" var attrName = child.attributes[key].nodeName; // 获取属性名 type、v-model if(attrName === 'v-model'){ var vmKey = child.attributes[key].nodeValue; // 先获取属性值,也就是 msg // 为该节点,也就是 绑定一个 input 事件 child.addEventListener('input', function (event) { vm[vmKey] = event.target.value; // 获取用户输入的值,然后改变 vm 里面的 msg 属性对应的值,注意这里会触发 setter }) } } } if(child.nodeType == 3){ // 如果能进入此 if,说明该节点是一个文本节点 if(reg.test(child.nodeValue)){ // 如果能够进入到此 if,说明是 {{ }},然后我们要让其成为订阅者 var vmKey = RegExp.$1; // 获取正则里面的捕获值,也就是 msg // 实例化一个 Watcher(订阅者),接收 3 个参数:Vue 实例,该文本节点,捕获值 msg new Watcher(vm, child, vmKey); } } documentFragment.appendChild(el.childNodes[0]); // 将第一个子节点添加到文档碎片里面 } // 将文档碎片中节点重新添加到 el,也就是 下面 el.appendChild(documentFragment); } // 新建发布者构造函数 function Dep() { // 将观察者添加到发布者内部的数组里面 // 这样以便于通知所有的观察者去更新数据 this.subs = []; } Dep.prototype = { // 将 watcher 添加到发布者内置的数组里面 addSub: function (sub) { this.subs.push(sub); }, // 遍历数组里面所有的 watcher,通知它们去更新数据 notify: function () { this.subs.forEach(function (sub) { sub.update(); }) } } // 新建观察者 Watcher 构造函数 // 接收 3 个参数:Vue 实例,文本节点 {{ msg }} 以及捕获内容 msg function Watcher(vm, child, vmKey) { this.vm = vm; // vm this.child = child; // {{ msg }} this.vmKey = vmKey; // msg Dep.target = this; // 将该观察者实例对象添加给 Dep.target this.update(); // 执行节点更新方法 Dep.target = null; // 最后清空 Dep.target } Watcher.prototype = { // 节点更新方法 update: function () { // 相当于:{{ msg }}.nodeValue = this.vm['msg'] // 这样就更新了文本节点的值,由于这里在获取 vm.msg,所以会触发 getter this.child.nodeValue = this.vm[this.vmKey]; } } // 该函数的作用是用于数据侦听 function observer(vm,obj){ var dep = new Dep(); // 新增一个发布者:发布者的作用是告诉订阅者数据已经更改 // 遍历数据 for(var key in obj){ // 将数据的每一项添加到 vm 里面,至此,vm 也有了每一项数据 // 但是不是单纯的添加,而是设置了 getter 和 setter // 在获取数据时触发 getter,在设置数据时触发 setter Object.defineProperty(vm, key, { get() { console.log("触发get了"); // 触发 getter 时,将该 watcher 添加到发布者维护的数组里面 if (Dep.target) { dep.addSub(Dep.target); // 往发布者的数组里面添加订阅者 } console.log(dep.subs); return obj[key]; }, set(newVal) { console.log("触发set了"); obj[key] = newVal; dep.notify(); // 发布者发出消息,通知订阅者修改数据 } }); } }
211. 手写用 ES6proxy 如何实现 arr[-1] 的访问(滴滴2020)
参考答案:
示例代码如下:
const proxyArray = arr => { const length = arr.length; return new Proxy(arr, { get(target, key) { key = +key; while (key < 0) { key += length; } return target[key]; } }) }; var a = proxyArray([1, 2, 3, 4, 5, 6, 7, 8, 9]); console.log(a[1]); // 2 console.log(a[-10]); // 9 console.log(a[-20]); // 8
212. 下列代码执行结果
console.log(1);
setTimeout(() => {
console.log(2);
process.nextTick(() => {
console.log(3);
});
new Promise((resolve) => {
console.log(4);
resolve();
}).then(() => {
console.log(5);
});
});
new Promise((resolve) => {
console.log(7);
resolve();
}).then(() => {
console.log(8);
});
process.nextTick(() => {
console.log(6);
});
setTimeout(() => {
console.log(9);
process.nextTick(() => {
console.log(10);
});
new Promise((resolve) => {
console.log(11);
resolve();
}).then(() => {
console.log(12);
});
});
参考答案:
1
7
6
8
2
4
3
5
9
11
10
12
213. Number() 的存储空间是多大?如果后台发送了一个超过最大自己的数字怎么办
参考答案:
Math.pow(2, 53) ,53 为有效数字,会发生截断,等于 JS 能支持的最大数字。
214. 事件是如何实现的?(字节2020)
参考答案:
基于发布订阅模式,就是在浏览器加载的时候会读取事件相关的代码,但是只有实际等到具体的事件触发的时候才会执行。
比如点击按钮,这是个事件(Event),而负责处理事件的代码段通常被称为事件处理程序(Event Handler),也就是「启动对话框的显示」这个动作。
在 Web 端,我们常见的就是 DOM 事件:
- DOM0 级事件,直接在 html 元素上绑定 on-event,比如 onclick,取消的话,dom.onclick = null,同一个事件只能有一个处理程序,后面的会覆盖前面的。
- DOM2 级事件,通过 addEventListener 注册事件,通过 removeEventListener 来删除事件,一个事件可以有多个事件处理程序,按顺序执行,捕获事件和冒泡事件
- DOM3级事件,增加了事件类型,比如 UI 事件,焦点事件,鼠标事件
215. 下列代码执行结果
Promise.resolve().then(() => {
console.log(0);
return Promise.resolve(4);
}).then((res) => {
console.log(res)
})
Promise.resolve().then(() => {
console.log(1);
}).then(() => {
console.log(2);
}).then(() => {
console.log(3);
}).then(() => {
console.log(5);
}).then(() =>{
console.log(6);
})
参考答案:
0
1
2
3
4
5
6
解析:
照着代码,我们先来看初始任务。
(初始任务)第一部分 Promise.resolve() 返回 「Promise { undefined }」。
(同任务,下同)继续调用 then,then 发现「Promise { undefined }」已解决,直接 enqueue 包含 console.log(0);return Promise.resolve(4) 的任务,之后返回新的「Promise {
}」(设为 promise0)。被 enqueue 的任务之后会引发 promise0 的 resolve/reject,详见 追加任务一 的 2. 3. 。 继续调用 promise0 上的 then,第二个 then 发现 promise0 还在 pending,因此不能直接 enqueue 新任务,而是将包含 console.log(res) 回调追加到 promise0 的 PromiseFulfillReactions 列表尾部,并返回新的「Promise { }」(设为 promiseRes)(该返回值在代码中被丢弃,但不影响整个过程)。
第二部分 Promise.resolve().then… 同理,只有包含 console.log(1) 的任务被 enqueue。中间结果分别设为 promise1(=Promise.resolve().then(() => {console.log(1);})), promise2, promise3, promise5, promise6。当前任务执行完毕。
此时,任务列队上有两个新任务,分别包含有 console.log(0);return Promise.resolve(4) 和 console.log(1) 。我们用 「Job { ??? }」来指代。
接下来,「Job { console.log(0);return Promise.resolve(4) }」先被 enqueue,所以先运行「Job { console.log(0);return Promise.resolve(4) }」。
(追加任务一)此时「0」被 console.log(0) 输出。Promise.resolve(4) 返回已解决的「Promise { 4 }」,然后 return Promise.resolve(4) 将这个「Promise { 4 }」作为最开始的 Promise.resolve().then(对应 promise0)的 onfulfill 处理程序(即 then(onfulfill, onreject) 的参数 onfulfill)的返回值返回。
(同任务,下同)onfulfill 处理程序返回,触发了 promise0 的 Promise Resolve Function(以下简称某 promise(实例)的 resolve)。所谓触发,其实是和别的东西一起打包到「Job { console.log(0);return Promise.resolve(4) }」当中,按流程执行,onfulfill 返回后自然就到它了。(onfulfill 抛异常的话会被捕获并触发 reject,正常返回就是 resolve。)
promise0 的 resolve 检查 onfulfill 的返回值,发现该值包含可调用的「then」属性。这是当然的,因为是「Promise { 4 }」。无论该 Promise 实例是否解决,都将 enqueue 一个新任务包含调用该返回值的 then 的任务(即规范中的 NewPromiseResolveThenableJob(promiseToResolve, thenable, then))。而这个任务才会触发后续操作,在本例中,最终会将 promise0 的 PromiseFulfillReactions (其中有包含 console.log(res) 回调)再打包成任务 enqueue 到任务列队上。当前任务执行完毕。
此时,任务列队上还是有两个任务(一进一出),「Job { console.log(1) }」和「NewPromiseResolveThenableJob(promise0, 「Promise { 4 }」, 「Promise { 4 }」.then)」。接下来执行「Job { console.log(1) }」。
(追加任务二)「1」被输出。
(同任务,下同)onfulfill 处理程序返回 undefined。(JavaScript 的函数默认就是返回 undefined。)
promise1 的 resolve 发现 undefined 连 Object 都不是,自然不会有 then,所以将 undefined 作为 promise1 的解决结果。即 promise1 从「Promise {
}」变为 「Promise { undefined }」(fulfill)。 resolve 继续查看 promise1 的 PromiseFulfillReactions。(reject 则会查看 PromiseRejectReactions。)有一个之前被 promise1.then 调用追加上的包含 console.log(2) 的回调。打包成任务入列。(如有多个则依次序分别打包入列。)当前任务执行完毕。
此时,任务列队上仍然有两个任务(一进一出)。「NewPromiseResolveThenableJob(…)」和 「Job { console.log(2) }」。执行「NewPromiseResolveThenableJob(…)」。
(追加任务三)调用 「Promise { 4 }」的 then。这个调用的参数(处理程序 onfulfill 和 onreject) 用的正是 promise0 的 resolve 和 reject。
由于「Promise { 4 }」的 then 是标准的,行为和其他的 then 一致。(可参见初始任务的步骤 2. 。)它发现「Promise { 4 }」已解决,结果是 4。于是直接 enqueue 包含 promise0 的 resolve 的任务,参数是 4。理论上同样返回一个「Promise { }」,由于是在内部,不被外部观察,也不产生别的影响。)当前任务执行完毕。
此时,任务列队上依旧有两个任务(一进一出)。「Job { console.log(2) }」和 「Job { promise0 的 resolve }」。执行「Job { console.log(2) }」。
- (追加任务四)过程类似「Job { console.log(1) }」的执行。「2」被输出。「Job { console.log(3) }」入列。其余不再赘述。当前任务执行完毕。
此时,任务列队上依然有两个任务(一进一出)。「Job { promise0 的 resolve }」和「Job { console.log(3) }」。执行「Job { promise0 的 resolve }」。
- (追加任务五)promise0 的 resolve 查看 PromiseFulfillReactions 发现有被 promise0.then 追加的回调。打包成任务入列。该任务包含 console.log(res),其中传递 promise0 解决结果 4 给参数 res。当前任务执行完毕。
此时,任务列队上还是两个任务(一进一出)。「Job { console.log(3) }」和「Job { console.log(res) }」。
- (追加任务六)输出「3」。「Job { console.log(5) }」入列。
此时,任务列队上还是两个任务(一进一出)。「Job { console.log(res) }」和「Job { console.log(5) }」。
- (追加任务七)输出「4」。由于 promiseRes 没有被 then 追加回调。就此打住。
此时,任务列队上终于不再是两个任务了。下剩「Job { console.log(5) }」。
- (追加任务八)输出「5」。「Job { console.log(6) }」入列。
最后一个任务(追加任务九)输出「6」。任务列队清空。
因此,输出的顺序是「0 1 2 3 4 5 6」。
总结一下,除去初始任务,总共 enqueue 了 9 个任务。其中,第一串 Promise + then… enqueue 了 4 个。第二串 Promise + then… enqueue 了 5 个。分析可知,每增加一个 then 就会增加一个任务入列。
而且,第一串的 return Promise.resolve(4) 的写法额外 enqueue 了 2 个任务,分别在 promise0 的 resolve 时(追加任务一 3.)和调用「Promise { 4 }」的 then 本身时(追加任务三 2.)。
根据规范,它就该这样。说不上什么巧合,可以算是有意为之。处理程序里返回 thenable 对象就会导致增加两个任务入列。
216. 判断数组的方法,请分别介绍它们之间的区别和优劣
参考答案:
方法一:instanceof 操作符判断
用法:arr instanceof Array
instanceof 主要是用来判断某个实例是否属于某个对象
let arr = []; console.log(arr instanceof Array); // true缺点:instanceof是判断类型的prototype是否出现在对象的原型链中,但是对象的原型可以随意修改,所以这种判断并不准确。并且也不能判断对象和数组的区别
方法二:对象构造函数的 constructor判断
用法:arr.constructor === Array
Object的每个实例都有构造函数 constructor,用于保存着用于创建当前对象的函数
let arr = []; console.log(arr.constructor === Array); // true方法三:Array 原型链上的 isPrototypeOf
用法:Array.prototype.isPrototypeOf(arr)
Array.prototype 属性表示 Array 构造函数的原型
其中有一个方法是 isPrototypeOf() 用于测试一个对象是否存在于另一个对象的原型链上。
let arr = []; console.log(Array.prototype.isPrototypeOf(arr)); // true方法四:Object.getPrototypeOf
用法:Object.getPrototypeOf(arr) === Array.prototype
Object.getPrototypeOf() 方法返回指定对象的原型
所以只要跟Array的原型比较即可
let arr = []; console.log(Object.getPrototypeOf(arr) === Array.prototype); // true方法五:Object.prototype.toString
用法:Object.prototype.toString.call(arr) === ‘[object Array]’
虽然Array也继承自Object,但js在Array.prototype上重写了toString,而我们通过toString.call(arr)实际上是通过原型链调用了。
let arr = []; console.log(Object.prototype.toString.call(arr) === '[object Array]'); // true缺点:不能精准判断自定义对象,对于自定义对象只会返回[object Object]
方法六:Array.isArray
用法:Array.isArray(arr)
ES5中新增了Array.isArray方法,IE8及以下不支持
Array.isArray ( arg )
isArray 函数需要一个参数 arg,如果参数是个对象并且 class 内部属性是 “Array”, 返回布尔值 true;否则它返回 false。let arr = []; console.log(Array.isArray(arr)); // true缺点:Array.isArray是ES 5.1推出的,不支持IE6~8,所以在使用的时候需要注意兼容性问题。
217. JavaScript 中的数组和函数在内存中是如何存储的?
参考答案:
在 JavaScript 中,数组不是以一段连续的区域存储在内存中,而是一种哈希映射的形式存储在堆内容里面。它可以通过多种数据结构实现,其中一种是链表。如下图所示:
JavaScript 中的函数是存储在堆内存中的,具体的步骤如下:
- 开辟堆内存(16 进制得到内存地址)
- 声明当前函数的作用域(函数创建的上下文才是他的作用域,和在那执行的无关)
- 把函数的代码以字符串的形式存储在堆内存中(函数再不执行的情况下,只是存储在堆内存中的字符串)
- 将函数堆的地址,放在栈中供变量调用(函数名)
218. JavaScript 是如何运行的?解释型语言和编译型语言的差异是什么?
参考答案:
关于第一个问题,这不是三言两语或者几行文字就能够讲清楚的,这里放上一篇博文地址:
https://segmentfault.com/a/1190000019530109
之后在直播课或者录屏课进行详细的讲解
第二个问题:解释型语言和编译型语言的差异是什么?
电脑能认得的是二进制数,不能够识别高级语言。所有高级语言在电脑上执行都需要先转变为机器语言。但是高级语言有两种类型:编译型语言和解释型语言。常见的编译型语言语言有C/C++、Pascal/Object 等等。常见的解释性语言有python、JavaScript等等。
编译型语言先要进行编译,然后转为特定的可执行文件,这个可执行文件是针对平台的(CPU类型),可以这么理解你在PC上编译一个C源文件,需要经过预处理,编译,汇编等等过程生成一个可执行的二进制文件。当你需要再次运行改代码时,不需要重新编译代码,只需要运行该可执行的二进制文件。优点,编译一次,永久执行。还有一个优点是,你不需要提供你的源代码,你只需要发布你的可执行文件就可以为客户提供服务,从而保证了你的源代码的安全性。但是,如果你的代码需要迁移到linux、ARM下时,这时你的可执行文件就不起作用了,需要根据新的平台编译出一个可执行的文件。这也就是多个平台需要软件的多个版本。缺点是,跨平台能力差。
解释型语言需要一个解释器,在源代码执行的时候被解释器翻译为一个与平台无关的中间代码,解释器会把这些代码翻译为及其语言。打个比方,编译型中的编译相当于一个翻译官,它只能翻译英语,而且中文文章翻译一次就不需要重新对文章进行二次翻译了,但是如果需要叫这个翻译官翻译德语就不行了。而解释型语言中的解释器相当于一个会各种语言的机器人,而且这个机器人回一句一句的翻译你的语句。对于不同的国家,翻译成不同的语言,所以,你只需要带着这个机器人就可以。解释型语言的有点是,跨平台,缺点是运行时需要源代码,知识产权保护性差,运行效率低。
219. 列举你所了解的编程范式?
参考答案:
编程范式 Programming paradigm 是指计算机中编程的典范模式或方法。
常见的编程范式有:函数式编程、程序编程、面向对象编程、指令式编程等。
不同的编程语言也会提倡不同的“编程范型”。一些语言是专门为某个特定的范型设计的,如 Smalltalk 和 Java 支持面向对象编程。而 Haskell 和 Scheme 则支持函数式编程。现代编程语言的发展趋势是支持多种范型,例如 ES 支持函数式编程的同时也支持面向对象编程。
220. 什么是面向切面(AOP)的编程?
参考答案:
什么是AOP?
AOP(面向切面编程)的主要作用是把一些跟核心业务逻辑模块无关的功能抽离出来,这些跟业务逻辑无关的功能通常包括日志统计、安全控制、异常处理等。把这些功能抽离出来之后, 再通过“动态织入”的方式掺入业务逻辑模块中。
AOP能给我们带来什么好处?
AOP的好处首先是可以保持业务逻辑模块的纯净和高内聚性,其次是可以很方便地复用日志统计等功能模块。
JavaScript实现AOP的思路?
通常,在 JavaScript 中实现 AOP,都是指把一个函数“动态织入”到另外一个函数之中,具体的实现技术有很多,下面我用扩展 Function.prototype 来做到这一点。
主要就是两个函数,在Function的原型上加上before与after,作用就是字面的意思,在函数的前面或后面执行,相当于无侵入把一个函数插入到另一个函数的前面或后面,应用得当可以很好的实现代码的解耦,js中的代码实现如下:
//Aop构造器 function Aop(options){ this.options = options } //业务方法执行前钩子 Aop.prototype.before = function(cb){ cb.apply(this) } //业务方法执行后钩子 Aop.prototype.after = function(cb){ cb.apply(this) } //业务方法执行器 Aop.prototype.execute = function(beforeCb,runner,afterCb){ this.before(beforeCb) runner.apply(this) this.after(afterCb) } var aop = new Aop({ afterInfo:'执行后', runnerInfo:'执行中', beforeInfo:'执行前' }) var beforeCb = function(){ console.log(this.options.beforeInfo) } var afterCb = function(){ console.log(this.options.afterInfo) } var runnerCb = function(){ console.log(this.options.runnerInfo) } aop.execute(beforeCb,runnerCb,afterCb)应用的一些例子:
- 为 window.onload 添加方法,防止 window.onload 被二次覆盖
- 无侵入统计某个函数的执行时间
- 表单校验
- 统计埋点
- 防止 csrf 攻击
221. JavaScript 中的 const 数组可以进行 push 操作吗?为什么?
参考答案:
可以进行 push 操作。虽然 const 表示常量,但是当我们把一个数组赋值给 const 声明的变量时,实际上是把这个数组的地址赋值给该变量。而 push 操作是在数组地址所指向的堆区添加元素,地址本身并没有发生改变。
示例代码:
const arr = [1]; arr.push(2); console.log(arr); // [1, 2]
222. JavaScript 中对象的属性描述符有哪些?分别有什么作用?
参考答案:
从ES5开始,添加了对对象属性描述符的支持。现在JavaScript中支持 4 种属性描述符:
- configurable: 当且仅当该属性的configurable键值为true时,该属性的描述符才能够被改变,同时该属性也能从对应的对象上被删除。
- enumerable: 当且仅当该属性的enumerable键值为true时,该属性才会出现在对象的枚举属性中。
- value: 该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。
- writable: 当且仅当该属性的writable键值为true时,属性的值,也就是上面的value,才能被赋值运算符改变。
223. JavaScript 中 console 有哪些 api ?
参考答案:
console.assert(expression, object[, object…])
接收至少两个参数,第一个参数的值或返回值为
false的时候,将会在控制台上输出后续参数的值。console.count([label])
输出执行到该行的次数,可选参数 label 可以输出在次数之前。
console.dir(object)
将传入对象的属性,包括子对象的属性以列表形式输出。
console.error(object[, object…])
用于输出错误信息,用法和常见的
console.log一样,不同点在于输出内容会标记为错误的样式,便于分辨。console.group
这是个有趣的方法,它能够让控制台输出的语句产生不同的层级嵌套关系,每一个
console.group()会增加一层嵌套,相反要减少一层嵌套可以使用console.groupEnd()方法。console.info(object[, object…])
此方法与之前说到的
console.error一样,用于输出信息,没有什么特别之处。console.table()
可将传入的对象,或数组以表格形式输出,相比传统树形输出,这种输出方案更适合内部元素排列整齐的对象或数组,不然可能会出现很多的 undefined。
console.log(object[, object…])
输入一段 log 信息。
console.profile([profileLabel])
这是个挺高大上的东西,可用于性能分析。在 JS 开发中,我们常常要评估段代码或是某个函数的性能。在函数中手动打印时间固然可以,但显得不够灵活而且有误差。借助控制台以及
console.profile()方法我们可以很方便地监控运行性能。console.time(name)
计时器,可以将成对的console.time()和console.timeEnd()之间代码的运行时间输出到控制台上,name参数可作为标签名。console.trace()
console.trace()用来追踪函数的调用过程。在大型项目尤其是框架开发中,函数的调用轨迹可以十分复杂,console.trace()方法可以将函数的被调用过程清楚地输出到控制台上。console.warn(object[, object…])
输出参数的内容,作为警告提示。
224. 简单对比一下 Callback、Promise、Generator、Async 几个异步 API 的优劣?
参考答案:
请参阅前面第 31 题答案。
225. Object.defineProperty 有哪几个参数?各自都有什么作用
参考答案:
在 JavaScript 中,通过 Object.defineProperty 方法可以设置对象属性的特性,选项如下:
- get:一旦目标属性被访问时,就会调用相应的方法
- set:一旦目标属性被设置时,就会调用相应的方法
- value:这是属性的值,默认是 undefined
- writable:这是一个布尔值,表示一个属性是否可以被修改,默认是 true
- enumerable:这是一个布尔值,表示在用 for-in 循环遍历对象的属性时,该属性是否可以显示出来,默认值为 true
- configurable:这是一个布尔值,表示我们是否能够删除一个属性或者修改属性的特性,默认值为 true
226. Object.defineProperty 和 ES6 的 Proxy 有什么区别?
参考答案:
1、Object.defineproperty
可以用于监听对象的数据变化
语法: Object.defineproperty(obj, key, descriptor)
let obj = { age: 11 } let value = 'xiaoxiao'; //defineproperty 有 gettter 和 setter Object.defineproperty(obj, 'name', { get() { return value }, set(newValue) { value = newValue } }) obj.name = 'pengpeng';此外 还有以下配置项 :
- configurable
- enumerable
- value
缺点:
无法监听数组变化
只能劫持对象的属性,属性值也是对象那么需要深度遍历
2、proxy :可以理解为在被劫持的对象之前 加了一层拦截
let proxy = new Proxy({}, { get(obj, prop) { return obj[prop] }, set(obj, prop, val) { obj[prop] = val } })
- proxy 返回的是一个新对象, 可以通过操作返回的新的对象达到目的
- proxy 有多达 13 种拦截方法
总结:
- Object.defineProperty 无法监控到数组下标的变化,导致通过数组下标添加元素,不能实时响应
- Object.defineProperty 只能劫持对象的属性,从而需要对每个对象,每个属性进行遍历,如果,属性值是对象,还需要深度遍历。Proxy 可以劫持整个对象,并返回一个新的对象。
- Proxy 不仅可以代理对象,还可以代理数组。还可以代理动态增加的属性。
227. intanceof 操作符的实现原理及实现
参考答案:
instanceof 主要作用就是判断一个实例是否属于某种类型
例如:
let Dog = function(){} let tidy = new Dog() tidy instanceof Dog //trueintanceof 操作符实现原理
function wonderFulInstanceOf(instance, constructorFn) { let constructorFnProto = constructorFn.prototype; // 取右表达式的 prototype 值,函数构造器指向的function instanceProto = instance.__proto__; // 取左表达式的__proto__值,实例的__proto__ while (true) { if (instanceProto === null) { return false; } if (instanceProto === constructorFnProto) { return true; } instanceProto = instanceProto.__proto__ } }其实 instanceof 主要的实现原理就是只要 constructorFn 的 prototype 在instance的原型链上即可。
因此,instanceof 在查找的过程中会遍历左边变量的原型链,直到找到右边变量的 prototype,如果查找失败,则会返回 false,告诉我们左边变量并非是右边变量的实例。
228. 强制类型转换规则?
参考答案:
首先需要参阅前面第 104 题答案。了解隐式转换所调用的函数。
当程序员显式调用 Boolean(value)、Number(value)、String(value) 完成的类型转换,叫做显示类型转换。
当通过 new Boolean(value)、new Number(value)、new String(value) 传入各自对应的原始类型的值,可以实现“装箱”,将原始类型封装成一个对象。
其实这三个函数不仅仅可以当作构造函数,它们可以直接当作普通的函数来使用,将任何类型的参数转化成原始类型的值:
Boolean('sdfsd'); // true Number("23"); // 23 String({a:24}); // "[object Object]"其实这三个函数用于类型转换的时候,调用的就是 js 内部的 ToBoolean ( argument )、ToNumber ( argument )、ToString ( argument ) 方法,从而达到显式转换的效果。
229. Object.is( ) 与比较操作符 “=”、“” 的区别
参考答案:
== (或者 !=) 操作在需要的情况下自动进行了类型转换。=== (或 !==)操作不会执行任何转换。
=在比较值和类型时,可以说比更快。
而在ES6中,Object.is( ) 类似于 ===,但在三等号判等的基础上特别处理了 NaN 、-0 和 +0 ,保证 -0 和 +0 不再相同,但 Object.is(NaN, NaN) 会返回 true。
230. + 操作符什么时候用于字符串的拼接?
参考答案:
在有一边操作数是字符串时会进行字符串拼接。
示例代码:
console.log(5 + '5', typeof (5 + '5')); // 55 string
231. object.assign 和扩展运算法是深拷贝还是浅拷贝
参考答案:
这两个方式都是浅拷贝。
在拷贝的对象只有一层时是深拷贝,但是一旦对象的属性值又是一个对象,也就是有两层或者两层以上时,就会发现这两种方式都是浅拷贝。
232. const 对象的属性可以修改吗
参考答案:
可以修改,具体原因可以参阅前面第 231 题。
233. 如果 new 一个箭头函数的会怎么样
参考答案:
会报错,因为箭头函数无法作为构造函数。
234. 扩展运算符的作用及使用场景
参考答案:
扩展运算符是三个点(…),主要用于展开数组,将一个数组转为参数序列。
扩展运算符使用场景:
- 代替数组的 apply 方法
- 合并数组
- 复制数组
- 把 arguments 或 NodeList 转为数组
- 与解构赋值结合使用
- 将字符串转为数组
235. Proxy 可以实现什么功能?
参考答案:
Proxy 是 ES6 中新增的一个特性。Proxy 让我们能够以简洁易懂的方式控制外部对对象的访问。其功能非常类似于设计模式中的代理模式。
Proxy 在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截。
使用 Proxy 的好处是对象只需关注于核心逻辑,一些非核心的逻辑(如:读取或设置对象的某些属性前记录日志;设置对象的某些属性值前,需要验证;某些属性的访问控制等)可以让 Proxy 来做。从而达到关注点分离,降级对象复杂度的目的。
Proxy 的基本语法如下:
var proxy = new Proxy(target, handler);通过构造函数来生成 Proxy 实例,构造函数接收两个参数。target 参数是要拦截的目标对象,handler 参数也是一个对象,用来定制拦截行为。
Vue 3.0 主要就采用的 Proxy 特性来实现响应式,相比以前的 Object.defineProperty 有以下优点:
- 可以劫持整个对象,并返回一个新的对象
- 有 13 种劫持操作
236. 对象与数组的解构的理解
参考答案:
解构是 ES6 的一种语法规则,可以将一个对象或数组的某个属性提取到某个变量中。
解构对象示例:
// var/let/const{属性名}=被解构的对象 const user = { name: "abc", age: 18, sex: "男", address: { province: "重庆", city: "重庆" } } let { name, age, sex, address} = user; console.log(name, age, sex, address);解构数组示例:
const [a, b, c] = [1, 2, 3];
237. 如何提取高度嵌套的对象里的指定属性?
参考答案:
一般会使用递归的方式来进行查找。下面是一段示例代码:
function findKey(data, field) { let finding = ''; for (const key in data) { if (key === field) { finding = data[key]; } if (typeof (data[key]) === 'object') { finding = findKey(data[key], field); } if (finding) { return finding; } } return null; } // 测试 console.log(findKey({ name: 'zhangsan', age: 18, stuInfo: { stuNo: 1, classNo: 2, score: { htmlScore: 100, cssScore: 90, jsScore: 95 } } }, 'cssScore')); // 90
238. Unicode、UTF-8、UTF-16、UTF-32 的区别?
参考答案:
Unicode 为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 110 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:“马”的 Unicode 是 U+9A6C。
Unicode 就相当于一张表,建立了字符与编号之间的联系。
Unicode 本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
那我们可以直接把 Unicode 编号直接转换成二进制进行存储,怎么对应到二进制表示呢?
Unicode 可以使用的编码有三种,分别是:
- UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
239. 为什么函数的 arguments 参数是类数组而不是数组?如何遍历类数组?
参考答案:
首先了解一下什么是数组对象和类数组对象。
数组对象:使用单独的变量名来存储一系列的值。从 Array 构造函数中继承了一些用于进行数组操作的方法。
例如:
var mycars = new Array(); mycars[0] = "zhangsan"; mycars[1] = "lisi"; mycars[2] = "wangwu";类数组对象:对于一个普通的对象来说,如果它的所有 property 名均为正整数,同时也有相应的length属性,那么虽然该对象并不是由Array构造函数所创建的,它依然呈现出数组的行为,在这种情况下,这些对象被称为“类数组对象”。
两者区别
一个是对象,一个是数组
数组的length属性,当新的元素添加到列表中的时候,其值会自动更新。类数组对象的不会。
设置数组的length属性可以扩展或截断数组。
数组也是Array的实例可以调用Array的方法,比如push、pop等等
所以说arguments对象不是一个 Array 。它类似于Array,但除了length属性和索引元素之外没有任何Array属性。
可以使用 for…in 来遍历 arguments 这个类数组对象。
240. escape、encodeURI、encodeURIComponent 的区别
参考答案:
escape 除了 ASCII 字母、数字和特定的符号外,对传进来的字符串全部进行转义编码,因此如果想对 URL 编码,最好不要使用此方法。
encodeURI 用于编码整个 URI,因为 URI 中的合法字符都不会被编码转换。
encodeURIComponent 方法在编码单个URIComponent(指请求参数)应当是最常用的,它可以讲参数中的中文、特殊字符进行转义,而不会影响整个 URL。
241. use strict 是什么意思 ? 使用它区别是什么?
参考答案:
use strict 代表开启严格模式,这种模式使得 Javascript 在更严格的条件下运行,实行更严格解析和错误处理。
开启“严格模式”的优点:
- 消除 Javascript 语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的 Javascript 做好铺垫。
242. for…in 和 for…of 的区别
参考答案:
JavaScript 原有的 for…in 循环,只能获得对象的键名,不能直接获取键值。ES6 提供 for…of 循环,允许遍历获得键值。
例如:
var arr = ['a', 'b', 'c', 'd']; for (let a in arr) { console.log(a); // 0 1 2 3 } for (let a of arr) { console.log(a); // a b c d }
243. ajax、axios、fetch 的区别
参考答案:
ajax 是指一种创建交互式网页应用的网页开发技术,并且可以做到无需重新加载整个网页的情况下,能够更新部分网页,也叫作局部更新。
使用 ajax 发送请求是依靠于一个对象,叫 XmlHttpRequest 对象,通过这个对象我们可以从服务器获取到数据,然后再渲染到我们的页面上。现在几乎所有的浏览器都有这个对象,只有 IE7 以下的没有,而是通过 ActiveXObject 这个对象来创建的。
Fetch 是 ajax 非常好的一个替代品,基于 Promise 设计,使用 Fetch 来获取数据时,会返回给我们一个 Pormise 对象,但是 Fetch 是一个低层次的 API,想要很好的使用 Fetch,需要做一些封装处理。
下面是 Fetch 的一些缺点
- Fetch 只对网络请求报错,对 400,500 都当做成功的请求,需要封装去处理
- Fetch 默认不会带 cookie,需要添加配置项。
- Fetch 不支持 abort,不支持超时控制,使用 setTimeout 及 Promise.reject 的实现超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费。
- Fetch 没有办法原生监测请求的进度,而 XHR 可以。
Vue2.0 之后,axios 开始受到更多的欢迎了。其实 axios 也是对原生 XHR 的一种封装,不过是 Promise 实现版本。它可以用于浏览器和 nodejs 的 HTTP 客户端,符合最新的 ES 规范。
244. 下面代码的输出是什么?( D )
function sayHi() {
console.log(name);
console.log(age);
var name = "Lydia";
let age = 21;
}
sayHi();
- A: Lydia 和 undefined
- B: Lydia 和 ReferenceError
- C: ReferenceError 和 21
- D: undefined 和 ReferenceError
分析:
在 sayHi 函数内部,通过 var 声明的变量 name 会发生变量提升,var name 会提升到函数作用域的顶部,其默认值为 undefined。因此输出 name 时得到的值为 undefined;
let 声明的 age 不会发生变量提升,在输出 age 时该变量还未声明,因此会抛出 ReferenceError 的报错。
245. 下面代码的输出是什么?( C )
for (var i = 0; i < 3; i++) {
setTimeout(() => console.log(i), 1);
}
for (let i = 0; i < 3; i++) {
setTimeout(() => console.log(i), 1);
}
- A: 0 1 2 和 0 1 2
- B: 0 1 2 和 3 3 3
- C: 3 3 3 和 0 1 2
分析:
JavaScript 中的执行机制,setTimeout 为异步代码,因此在 setTimeout 执行时,for 循环已经执行完毕。
第一个 for 循环中的变量 i 通过 var 声明, 为全局变量,因此每一次的 i++ 都会将全局变量 i 的值加 1,当第一个 for 执行完成后 i 的值为 3。所以再执行 setTimeout 时,输出 i 的值都为 3;
第二个 for 循环中的变量 i 通过 let 声明,为局部变量,因此每一次 for 循环时都会产生一个块级作用域,用来存储本次循环中新产生的 i 的值。当循环结束后,setTimeout 会沿着作用域链去对应的块级作用域中寻找对应的 i 值。
246. 下面代码的输出是什么?( B )
const shape = {
radius: 10,
diameter() {
return this.radius * 2;
},
perimeter: () => 2 * Math.PI * this.radius
};
shape.diameter();
shape.perimeter();
- A: 20 和 62.83185307179586
- B: 20 和 NaN
- C: 20 和 63
- D: NaN 和 63
分析:
diameter 作为对象的方法,其内部的 this 指向调用该方法的对象,因此 this.raduus 获取到的是 shape.radius 的值 10,再乘以 2 输出的值即为 20;
perimeter 是一个箭头函数,其内部的 this 应该继承声明时所在上下文中的 this,在这里即继承全局的 this,因此 this.radius 值的为 undefined,undefined 与数值相乘后值为 NaN。
247. 下面代码的输出是什么?( A )
+true;
!"Lydia";
- A: 1 和 false
- B: false 和 NaN
- C: false 和 false
分析:
一元加号会将数据隐式转换为 number 类型,true 转换为数值为 1;
非运算符 ! 会将数据隐式转换为 boolean 类型后进行取反,“Lydia” 转换为布尔值为 true,取反后为 false。
248. 哪个选项是不正确的?( A )
const bird = {
size: "small"
};
const mouse = {
name: "Mickey",
small: true
};
- A: mouse.bird.size
- B: mouse[bird.size]
- C: mouse[bird[“size”]]
- D: 以上选项都对
分析:
mouse 对象中没有 bird 属性,当访问一个对象不存在的属性时值为 undefined,因此 mouse.bird 的值为 undefined,而 undefined 作为原始数据类型没有 size 属性,因此再访问 undefined.size 时会报错。
249. 下面代码的输出是什么?( A )
let c = { greeting: "Hey!" };
let d;
d = c;
c.greeting = "Hello";
console.log(d.greeting);
- A: Hello
- B: undefined
- C: ReferenceError
- D: TypeError
分析:
在 JavaScript 中,复杂类型数据在进行赋值操作时,进行的是「引用传递」,因此变量 d 和 c 指向的是同一个引用。当 c 通过引用去修改了数据后,d 再通过引用去访问数据,获取到的实际就是 c 修改后的数据。
250. 下面代码的输出是什么?( C )
let a = 3;
let b = new Number(3);
let c = 3;
console.log(a == b);
console.log(a === b);
console.log(b === c);
- A: true false true
- B: false false true
- C: true false false
- D: false true true
分析:
new Number() 是 JavaScript 中一个内置的构造函数。变量 b 虽然看起来像一个数字,但它并不是一个真正的数字:它有一堆额外的功能,是一个对象。
== 会触发隐式类型转换,右侧的对象类型会自动转换为 Number 类型,因此最终返回 true。
=== 不会触发隐式类型转换,因此在比较时由于数据类型不相等而返回 false。
251. 下面代码的输出是什么?( D )
class Chameleon {
static colorChange(newColor) {
this.newColor = newColor;
}
constructor({ newColor = "green" } = {}) {
this.newColor = newColor;
}
}
const freddie = new Chameleon({ newColor: "purple" });
freddie.colorChange("orange");
- A: orange
- B: purple
- C: green
- D: TypeError
分析:
colorChange 方法是静态的。 静态方法仅在创建它们的构造函数中存在,并且不能传递给任何子级。 由于 freddie 是一个子级对象,函数不会传递,所以在 freddie 实例上不存在 colorChange 方法:抛出TypeError。
252. 下面代码的输出是什么?( A )
let greeting;
greetign = {}; // Typo!
console.log(greetign);
- A: {}
- B: ReferenceError: greetign is not defined
- C: undefined
分析:
控制台会输出空对象,因为我们刚刚在全局对象上创建了一个空对象!
当我们错误地将 greeting 输入为 greetign 时,JS 解释器实际上在浏览器中将其视为 window.greetign = {}。
253. 当我们执行以下代码时会发生什么?( A )
function bark() {
console.log("Woof!");
}
bark.animal = "dog";
- A 什么都不会发生
- B: SyntaxError. You cannot add properties to a function this way.
- C: undefined
- D: ReferenceError
分析:
因为函数也是对象!(原始类型之外的所有东西都是对象)
函数是一种特殊类型的对象,我们可以给函数添加属性,且此属性是可调用的。
254. 下面代码的输出是什么?( A )
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
const member = new Person("Lydia", "Hallie");
Person.getFullName = () => this.firstName + this.lastName;
console.log(member.getFullName());
- A: TypeError
- B: SyntaxError
- C: Lydia Hallie
- D: undefined undefined
分析:
Person.getFullName 是将方法添加到了函数身上,因此当我们通过实例对象 member 去调用该方法时并不能找到该方法。
255. 下面代码的输出是什么?( A )
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
const lydia = new Person("Lydia", "Hallie");
const sarah = Person("Sarah", "Smith");
console.log(lydia);
console.log(sarah);
- A: Person { firstName: “Lydia”, lastName: “Hallie” } 和 undefined
- B: Person { firstName: “Lydia”, lastName: “Hallie” } 和 Person { firstName: “Sarah”, lastName: “Smith” }
- C: Person { firstName: “Lydia”, lastName: “Hallie” } 和 {}
- D: Person { firstName: “Lydia”, lastName: “Hallie” } 和 ReferenceError
分析:
lydia 是调用构造函数后得到的实例对象,拥有 firstName 和 lastName 属性;
sarah 是调用普通函数后得到的返回值,而 Person 作为普通函数没有返回值;
256. 事件传播的三个阶段是什么?( D )
- A: 目标 > 捕获 > 冒泡
- B: 冒泡 > 目标 > 捕获
- C: 目标 > 冒泡 > 捕获
- D: 捕获 > 目标 > 冒泡
257. 下面代码的输出是什么?( C )
function sum(a, b) {
return a + b;
}
sum(1, "2");
- A: NaN
- B: TypeError
- C: “12”
- D: 3
分析:
任意数据类型在跟 String 做 + 运算时,都会隐式转换为 String 类型。
即 a 所对应的 Number 值 1,被隐式转换为了 String 值 “1”,最终字符串拼接的到 “12”。
258. 下面代码的输出是什么?( C )
let number = 0;
console.log(number++);
console.log(++number);
console.log(number);
- A: 1 1 2
- B: 1 2 2
- C: 0 2 2
- D: 0 1 2
分析:
++ 后置时,先输出,后加 1;++ 前置时,先加 1,后输出;
第一次输出的值为 0,输出完成后 number 加 1 变为 1。
第二次输出,number 先加 1 变为 2,然后输出值 2。
第三次输出,number 值没有变化,还是 2。
259. 下面代码的输出是什么?( B )
function getPersonInfo(one, two, three) {
console.log(one);
console.log(two);
console.log(three);
}
const person = "Lydia";
const age = 21;
getPersonInfo`${person} is ${age} years old`;
- A: Lydia 21 [“”, “is”, “years old”]
- B: [“”, “is”, “years old”] Lydia 21
- C: Lydia [“”, “is”, “years old”] 21
分析:
如果使用标记的模板字符串,则第一个参数的值始终是字符串值的数组。 其余参数获取传递到模板字符串中的表达式的值!
260. 下面代码的输出是什么?( C )
function checkAge(data) {
if (data === { age: 18 }) {
console.log("You are an adult!");
} else if (data == { age: 18 }) {
console.log("You are still an adult.");
} else {
console.log(`Hmm.. You don't have an age I guess`);
}
}
checkAge({ age: 18 });
- A: You are an adult!
- B: You are still an adult.
- C: Hmm… You don’t have an age I guess
分析:
在比较相等性时,原始类型通过它们的值进行比较,而对象通过它们的引用进行比较。
data 和条件中的 { age: 18 } 两个不同引用的对象,因此永远都不相等。
261. 下面代码的输出是什么?( C )
function getAge(...args) {
console.log(typeof args);
}
getAge(21);
- A: “number”
- B: “array”
- C: “object”
- D: “NaN”
分析:
ES6 中的不定参数(…args)返回的是一个数组。
typeof 检查数组的类型返回的值是 object。
262. 下面代码的输出是什么?( C )
function getAge() {
"use strict";
age = 21;
console.log(age);
}
getAge();
- A: 21
- B: undefined
- C: ReferenceError
- D: TypeError
分析:
“use strict” 严格模式中,使用未声明的变量会引发报错。
263. 下面代码的输出是什么?( A )
const sum = eval("10*10+5");
- A: 105
- B: “105”
- C: TypeError
- D: “10*10+5”
分析:
eval 方法会将字符串当作 JavaScript 代码进行解析。
264. cool_secret 可以访问多长时间?( B )
sessionStorage.setItem("cool_secret", 123);
- A:永远,数据不会丢失。
- B:用户关闭选项卡时。
- C:当用户关闭整个浏览器时,不仅是选项卡。
- D:用户关闭计算机时。
分析:
sessionStorage 是会话级别的本地存储,当窗口关闭,则会话结束,数据删除。
265. 下面代码的输出是什么?( B )
var num = 8;
var num = 10;
console.log(num);
- A: 8
- B: 10
- C: SyntaxError
- D: ReferenceError
分析:
var 声明的变量允许重复声明,但后面的值会覆盖前面的值。
266. 下面代码的输出是什么?( C )
const obj = { 1: "a", 2: "b", 3: "c" };
const set = new Set([1, 2, 3, 4, 5]);
obj.hasOwnProperty("1");
obj.hasOwnProperty(1);
set.has("1");
set.has(1);
- A: false true false true
- B: false true true true
- C: true true false true
- D: true true true true
267. 下面代码的输出是什么?( C )
const obj = { a: "one", b: "two", a: "three" };
console.log(obj);
- A: { a: “one”, b: “two” }
- B: { b: “two”, a: “three” }
- C: { a: “three”, b: “two” }
- D: SyntaxError
分析:
如果对象有两个具有相同名称的键,则后面的将替前面的键。它仍将处于第一个位置,但具有最后指定的值。
268. 下面代码的输出是什么?( C )
for (let i = 1; i < 5; i++) {
if (i === 3) continue;
console.log(i);
}
- A: 1 2
- B: 1 2 3
- C: 1 2 4
- D: 1 3 4
分析:
当 i 的值为 3 时,进入 if 语句执行 continue,结束本次循环,立即进行下一次循环。
269. 下面代码的输出是什么?( A )
String.prototype.giveLydiaPizza = () => {
return "Just give Lydia pizza already!";
};
const name = "Lydia";
name.giveLydiaPizza();
- A: “Just give Lydia pizza already!”
- B: TypeError: not a function
- C: SyntaxError
- D: undefined
分析:
String 是一个内置的构造函数,我们可以为它添加属性。 我们给它的原型添加了一个方法。 原始类型的字符串自动转换为字符串对象,由字符串原型函数生成。 因此,所有字符串(字符串对象)都可以访问该方法!
当使用基本类型的字符串调用 giveLydiaPizza 时,实际上发生了下面的过程:
- 创建一个 String 的包装类型实例
- 在实例上调用 substring 方法
- 销毁实例
270. 下面代码的输出是什么?( B )
const a = {};
const b = { key: "b" };
const c = { key: "c" };
a[b] = 123;
a[c] = 456;
console.log(a[b]);
- A: 123
- B: 456
- C: undefined
- D: ReferenceError
分析:
当 b 和 c 作为一个对象的键时,会自动转换为字符串,而对象自动转换为字符串化时,结果都为 [Object object]。因此 a[b] 和 a[c] 其实都是同一个属性 a[“Object object”]。
对象同名的属性后面的值会覆盖前面的,因此最终 a[“Object object”] 的值为 456。
271. 下面代码的输出是什么?( B )
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"));
const baz = () => console.log("Third");
bar();
foo();
baz();
- A: First Second Third
- B: First Third Second
- C: Second First Third
- D: Second Third First
分析:
bar 函数中执行的是一段异步代码,按照 JavaScript 中的事件循环机制,主线程中的所有同步代码执行完成后才会执行异步代码。因此 “Second” 最后输出。
272. 单击按钮时 event.target 是什么?( C )
<div onclick="console.log('first div')">
<div onclick="console.log('second div')">
<button onclick="console.log('button')">
Click!
button>
div>
div>
- A: div 外部
- B: div 内部
- C: button
- D: 所有嵌套元素的数组
分析:
event.target 指向的是事件目标,即触发事件的元素。因此点击 触发事件的也就是 。
273. 单击下面的 html 片段打印的内容是什么?( A )
<div onclick="console.log('div')">
<p onclick="console.log('p')">
Click here!
p>
div>
- A: p div
- B: div p
- C: p
- D: div
分析:
onclick 绑定的事件为冒泡型事件。因此当点击 p 标签时,事件会从事件目标开始依次往外触发。
274. 下面代码的输出是什么?( D )
const person = { name: "Lydia" };
function sayHi(age) {
console.log(`${this.name} is ${age}`);
}
sayHi.call(person, 21);
sayHi.bind(person, 21);
- A: undefined is 21 Lydia is 21
- B: function function
- C: Lydia is 21 Lydia is 21
- D: Lydia is 21 function
分析:
call 和 bind 都可以修改 this 的指向,但区别在于 call 方法会立即执行,而 bind 会返回一个修改后的新函数。
275. 下面代码的输出是什么?( B )
function sayHi() {
return (() => 0)();
}
typeof sayHi();
- A: “object”
- B: “number”
- C: “function”
- D: “undefined”
分析:
return 后是一个 IIFE,其返回值是 0,因此 sayHi 函数中返回的是一个 0。typeof 检测 sayHi 返回值类型即为 number。
276. 下面这些值哪些是假值?( A )
0;
new Number(0);
("");
(" ");
new Boolean(false);
undefined;
- A: 0 “” undefined
- B: 0 new Number(0) “” new Boolean(false) undefined
- C: 0 “” new Boolean(false) undefined
- D: 所有都是假值。
分析:
JavaScript 中假值只有 6 个:false、“”、null、undefined、NaN、0
278. 下面代码的输出是什么?( B )
console.log(typeof typeof 1);
- A: “number”
- B: “string”
- C: “object”
- D: “undefined”
分析:
typeof 1 返回 “number”,typeof “number” 返回 “string”
279. 下面代码的输出是什么?( C )
const numbers = [1, 2, 3];
numbers[10] = 11;
console.log(numbers);
- A: [1, 2, 3, 7 x null, 11]
- B: [1, 2, 3, 11]
- C: [1, 2, 3, 7 x empty, 11]
- D: SyntaxError
分析:
当你为数组中的元素设置一个超过数组长度的值时,JavaScript 会创建一个名为“空插槽”的东西。 这些位置的值实际上是 undefined,但你会看到类似的东西:
[1, 2, 3, 7 x empty, 11]这取决于你运行它的位置(每个浏览器有可能不同)。
280. 下面代码的输出是什么?( A )
(() => {
let x, y;
try {
throw new Error();
} catch (x) {
(x = 1), (y = 2);
console.log(x);
}
console.log(x);
console.log(y);
})();
- A: 1 undefined 2
- B: undefined undefined undefined
- C: 1 1 2
- D: 1 undefined undefined
分析:
catch 块接收参数 x。当我们传递参数时,这与变量的 x 不同。这个变量 x 是属于 catch 作用域的。
之后,我们将这个块级作用域的变量设置为 1,并设置变量 y 的值。 现在,我们打印块级作用域的变量 x,它等于 1。
在catch 块之外,x 仍然是 undefined,而 y 是 2。 当我们想在 catch 块之外的 console.log(x) 时,它返回undefined,而 y 返回 2。
281. JavaScript 中的所有内容都是…( A )
- A:原始或对象
- B:函数或对象
- C:技巧问题!只有对象
- D:数字或对象
分析:
JavaScript 只有原始类型和对象。
282. 下面代码的输出是什么?
[[0, 1], [2, 3]].reduce(
(acc, cur) => {
return acc.concat(cur);
},
[1, 2]
);
- A: [0, 1, 2, 3, 1, 2]
- B: [6, 1, 2]
- C: [1, 2, 0, 1, 2, 3]
- D: [1, 2, 6]
分析:
[1,2] 是我们的初始值。 这是我们开始执行 reduce 函数的初始值,以及第一个 acc 的值。 在第一轮中,acc 是 [1,2],cur 是 [0,1]。 我们将它们连接起来,结果是 [1,2,0,1]。
然后,acc 的值为 [1,2,0,1],cur 的值为 [2,3]。 我们将它们连接起来,得到 [1,2,0,1,2,3]。
283. 下面代码的输出是什么?( B )
!!null;
!!"";
!!1;
- A: false true false
- B: false false true
- C: false true true
- D: true true false
分析:
null 是假值。 !null 返回 true。 !true 返回 false。
“” 是假值。 !“” 返回 true。 !true 返回 false。
1 是真值。 !1 返回 false。 !false 返回 true。
284. setInterval 方法的返回值什么?( A )
setInterval(() => console.log("Hi"), 1000);
- A:一个唯一的 id
- B:指定的毫秒数
- C:传递的函数
- D:undefined
分析:
它返回一个唯一的 id。 此 id 可用于使用 clearInterval() 函数清除该定时器。
285. 下面代码的返回值是什么?( A )
[..."Lydia"];
- A: [“L”, “y”, “d”, “i”, “a”]
- B: [“Lydia”]
- C: [[], “Lydia”]
- D: [[“L”, “y”, “d”, “i”, “a”]]
分析:
字符串是可迭代的。 扩展运算符将迭代的每个字符映射到一个元素。
286. document.write 和 innerHTML 有哪些区别?
参考答案:
document.write 和 innerHTML 都能将 HTML 字符串解析为 DOM 树,再将 DOM 树插入到某个位置,但两种在执行细节上还是有许多不同。
1)write() 方法存在于 Document 对象中,innerHTML 属性存在于 Element 对象中;
2)document.write 会将解析后的 DOM 树插入到文档中调用它的脚本元素的位置,而 innerHTML 会将 DOM 树插入到指定的元素内;
3)document.write 会将多次调用的字符串参数自动连接起来,innerHTML 要用赋值运算符 “+=” 拼接;
4)只有当文档还在解析时,才能使用 document.write,否则 document.write 的值会将当前文档覆盖掉,而 innerHTML 属性则没有这个限制;
注:也可以参阅前面第 157 题答案
287. 假设有两个变量 a 和 b,他们的值都是数字,如何在不借用第三个变量的情况下,将两个变量的值对调?
参考答案:
方法一:
a = a + b; b = a - b; a = a - b;方法二(ES6 中的解构):
[a, b] = [b, a]
288. 前端为什么提倡模块化开发?
参考答案:
模块化能将一个复杂的大型系统分解成一个个高内聚、低耦合的简单模块,并且每个模块都是独立的,用于完成特定的功能。模块化后的系统变得更加可控、可维护、可扩展,程序代码也更简单直观,可读性也很高,有利于团队协作开发。ES6 模块化的出现,使得前端能更容易、更快速的实现模块化开发。
289. 请解释 JSONP 的原理,并用代码描述其过程。
参考答案:
*JSONP(JSON with padding)*是一种借助