自然语言处理(NLP)发展历程(2),什么是词嵌入(word embedding) ?
四、如何表示一个词语的意思
4.1.NLP概念术语
这里我将引入几个概念术语,便于大家理解及阅读NLP相关文章。
- 语言模型(language model,LM),简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率。
标准定义:对于语言序列 w 1 , w 2 , . . . , w n w_1,w_2,...,w_n w1,w2,...,wn语言模型就是计算该序列的概率,即:
P ( w 1 , w 2 , . . . , w n ) = P ( w 1 ) P ( w 2 ∣ w 1 ) . . . P ( w n ∣ w 1 , . . . , w n − 1 ) P(w_1,w_2,...,w_n)=P(w_1)P(w_2|w_1)...P(w_n|w_1,...,w_{n-1}) P(w1,w2,...,wn)=P(w1)P(w2∣w1)...P(wn∣w1,...,wn−1)。
用一句简单的话说,就语言模型就是计算一个句子的概率大小的这种模型。有什么意义呢?一个句子的打分概率越高,越说明他是更合乎人说出来的自然句子。就是这么简单。常见的统计语言模型有N元文法模型(N-gram Model),最常见的是unigram model、bigram model、trigram model等等。
从机器学习的角度来看:语言模型是对语句的概率分布的建模。
例如:
P ( I a m L i g h t ) > P ( L i g t h I a m ) P(I am Light) > P(Ligth I am) P(IamLight)>P(LigthIam)
 图片来自参考文章[6]
图片来自参考文章[6]
-
自回归语言模型(Autoregressive Language Modeling,AR),类似于传统的语言模型,只是在2019年再XLnet中给了明确的区分定义,AE也是在本篇paper中提出的。
AR语言模型:依据前面(或后面,注意仅使用单向的token)出现的 tokens 来预测当前时刻的 token, 代表有 ELMO, GPT 等。
优点:对生成模型友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
缺点:它只能利用单向语义而不能同时利用上下文信息。 ELMO 通过双向都做AR 模型,然后进行拼接,但从结果来看,双向LSTM参数简单的拼接处理,效果并不是太好。 -
自编码语言模型(Autoencoder LM,AE)
AE语言模型:通过上下文信息来预测被 mask 的 token, 代表有 BERT , Word2Vec(CBOW) 、XLnet。
优点:能够很好的编码上下文语义信息, 在自然语言理解相关的下游任务上表现突出。
缺点:由于训练中采用了 [MASK] 标记,导致预训练与微调阶段不一致的问题。 此外对于生成式问题, AE模型也显得捉襟见肘,这也是目前BERT待突破的领域。
新星XLnet解决了BERT预训练与微调阶段不一致的问题,因XLnet采拥了Transformer XL作为编码器,与BERT相比也仅是在阅读理解方向有较大提升,生成式问题还的靠GPT。
AE举例:
句子[我 爱 中 国],假设“爱”,“中”mask掉了,则在预测“爱”的时候,只能利用“我”、“国”这两个字,P(“爱”|“我”“国”), 而不能利用“中”,P(“爱”|“我”“中”“国”) 因为“中”被mask掉了(注意:BERT、XLnet等模型已经不需要对中文进行分词了,模型在训练时按字进行训练)。
了解了以上定义后,我们来看看如何定义“意思”的意思,英文中meaning代表人或文字想要表达的idea。这是个递归的定义,估计查询idea词典会用meaning去解释它。
中文中“意思”的意思更加有意思:
他说:“她这个人真有意思(funny)。”她说:“他这个人怪有意思的(funny)。”于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)!”她也生气了:“你们这么说是什么意思(intention)?”事后有人说:“真有意思(funny)。”也有人说:“真没意思(nonsense)”。(原文见《生活报》1994.11.13.第六版)[吴尉天,1999] ——《统计自然语言处理》
上文段子展示了,中文“意思”一词多义的复杂性,人工阅读理解都很有难度,让计算机理解“意思”的真正含义更是业界一直努力解决的方向。
4.2.one hot encoding
如果你有一点编程基础,你会用什么办法表示词语?数学表示词语的最直接的方法是one hot encoding(又名:独热编码),独热编码他是离散表示的(discrete representation),它的思想很简单,例如,你有1000个词汇,按词的顺序构造一个词典。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,…],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列。
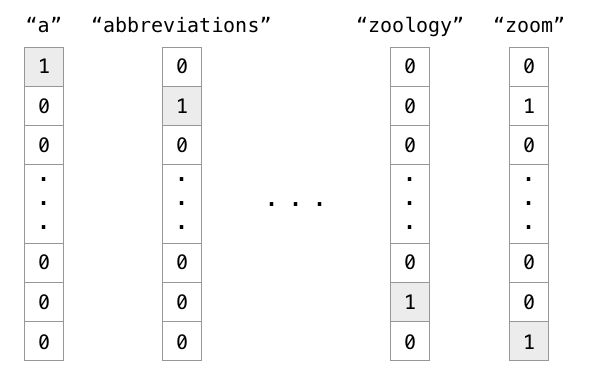
One hot encoding这种discrete representation(离散表示)虽然是种解决方案,但丢失了韵味。比如同义词的意思实际上还是有微妙的差别:adept, expert, good, practiced, proficient, skillful。
Discrete representation(离散表示)存在不少问题:
- 每个单词彼此无关、
- 主观化、
- 需要耗费大量人力去整理、
- 无法计算准确的词语相似度等。
还有一些其他问题: - 语义:girl和woman虽然用在不同年龄上,但指的都是女性。
- 复数:word和words仅仅是复数和单数的差别。
- 时态:buy和bought表达的都是“买”,但发生的时间不同。
所以用one hot representation的编码方式,上面的特性都没有被考虑到。
我们更希望用诸如“语义”,“复数”,“时态”等维度去描述一个单词。每一个维度不再是0或1,而是连续的实数,表示不同的程度。
无论是规则学派,还是统计学派,绝大多数NLP学家都将词语作为最小单位。在不同的语料中,词表大小不同。Google的1TB语料词汇量是1300万,这个向量的确太长了。
4.2.1 pytorch 实现one hot encoding
import torch as t
sentences = [ "我 喜欢 狗", "我 爱 咖啡", "我 恨 牛奶",'狗 追 兔子','我 挤 牛奶','狗 喜欢 骨头','狗 爱 骨头']
word_list= list(set(" ".join(sentences).split()))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
sen_one_hot=t.zeros(n_class,n_class).scatter_(1,t.LongTensor(range(n_class)).unsqueeze(1),1)
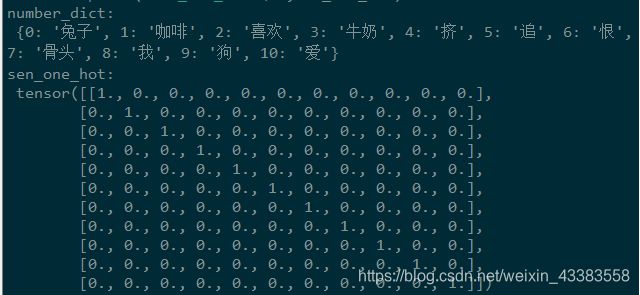
print('number_dict:\n',number_dict)
print('sen_one_hot:\n',sen_one_hot)
运行结果如下图,number_dict中的索引号就是tensor中的行号:
更简单的方法,使用numpy产生one hot encoding:
import numpy as np
np.eye(n_class)
4.3.word embedding
词的分布式表示(distributed representation)传统的独热表示( one-hot representation)仅仅将词符号化,不包含任何语义信息。如何将语义融入到词表示中?基于神经网络的分布表示一般称为词向量、词嵌入( word embedding)或分布式表示( distributed representation)。这正是本文的主角。
神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模。由于神经网络较为灵活,这类方法的最大优势在于可以表示复杂的上下文。在前面基于矩阵的分布表示方法中,最常用的上下文是词。如果使用包含词序信息的n-gram作为上下文,当n增加时,n-gram 的总数会呈指数级增长,此时会遇到维数灾难问题。而神经网络在表示 n-gram 时,可以通过一些组合方式对 n个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
通过神经网络训练语言模型可以得到词向量,那么究竟有哪些类型的神经网络语言模型呢?这里只罗列两个重要的论文:
1).NNLM(Neural Network Language Model) - Predict Next Word
Paper - A Neural Probabilistic Language Model(2003) - Yoshua Bengio
论文地址,需科学上网
2).Word2Vec(Skip-gram) - Embedding Words and Show Graph
Paper - Distributed Representations of Words and Phrases and their Compositionality(2013) - Tomas Mikolov 论文地址
4.3.1 NNLM(神经网路语言模型)
Word2Vec作为近年来比较流行的word embedding方法,它的References第一篇就是NNLM模型,你可能和我一样好奇,为什么要引用10年前的这篇文章。NLP工作者都很擅长考古,挖坟是常有的事,远古论文+新解决办法=创新论文~~
仔细阅读NNLM全文,其实Yoshua Bengio 在2003年已经间接得到了word embedding,只是他的论文目的是预测文本下一个词,word embedding只是他模型的附属产品。让我们研究一下NNLM模型。
模型的训练数据是一组词序列 w 1 . . . w T , , , w t ∈ V w_{1 }... w_{T}, ,,w_{t} \in V w1...wT,,,wt∈V,其中 V 是所有单词的集合(即词典), V i V_{i} Vi表示字典中的第 i 个单词。
NNLM的目标是训练如下模型:
f ( w t , w t − 1 , . . . , w t − n + 2 , w t − n + 1 ) = p ( w t ∣ w 1 t − 1 ) f(w_t,w_{t-1},...,w_{t-n+2},w_{t-n+1})=p(w_t|w_1^{t-1}) f(wt,wt−1,...,wt−n+2,wt−n+1)=p(wt∣w1t−1)
其中w_{t} 表示从第1个词到第t个词组成的子序列。模型需要满足的约束条件是:
f ( w t , w t − 1 , . . . , w t − n + 2 , w t − n + 1 ) > 0 f(w_t,w_{t-1},...,w_{t-n+2},w_{t-n+1})>0 f(wt,wt−1,...,wt−n+2,wt−n+1)>0
∑ i = 1 ∣ V ∣ f ( i , w t − 1 , . . . , w t − n + 2 , w t − n + 1 ) = 1 \sum_{i=1}^{|V|}f(i,w_{t-1},...,w_{t-n+2},w_{t-n+1})=1 ∑i=1∣V∣f(i,wt−1,...,wt−n+2,wt−n+1)=1
下图展示了模型的总体架构:
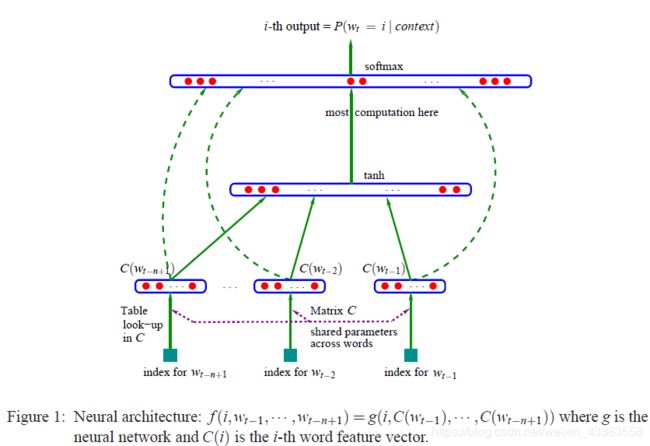
该模型可分为特征映射和计算条件概率分布两部分:
1.特征映射:
通过映射矩阵 C ∈ R ∣ V ∣ ∗ m C \in R^{|V|*m} C∈R∣V∣∗m 每个词映射为一个特征向量, C ( i ) ∈ R m C(i) \in R^m C(i)∈Rm表示词典中第i个词对应的特征向量,其中m表示特征向量的维度。
该过程将通过特征映射得到的 C ( w t − n + 1 ) , . . . , C ( w t − 1 ) C(w_{t−n+1}),...,C(w_{t−1}) C(wt−n+1),...,C(wt−1)
合并成一个 (n−1)*m 维的向量 ( C ( w t − n + 1 ) , . . . , C ( w t − 1 ) ) (C(w_{t-n+1}),...,C(w_{t-1})) (C(wt−n+1),...,C(wt−1))
2.计算条件概率分布:
通过一个函数g (g是前馈或递归神经网络)将输入的词向量序列 ( C ( w t − n + 1 ) , . . . , C ( w t − 1 ) ) (C(w_{t-n+1}),...,C(w_{t-1})) (C(wt−n+1),...,C(wt−1))转化为一个概率分布 R ∣ V ∣ R^{|V|} R∣V∣,
y中第 i 位表示词序列中第 t 个词是 V i V_{i} Vi 的概率,即:
f ( i , w t − 1 , . . . , w t − n + 2 , w t − n + 1 ) = g ( i , C ( w t − n + 1 ) , . . . , C ( w t − 1 ) ) f(i,w_{t−1},...,w_{t−n+2},w_{t−n+1})=g(i,C(w_{t−n+1}),...,C(w_{t−1})) f(i,wt−1,...,wt−n+2,wt−n+1)=g(i,C(wt−n+1),...,C(wt−1))
下面重点介绍神经网络的结构,网络输出层采用的是softmax函数,如下式所示:
p ( w t ∣ w t − 1 . . . , w t − n + 2 , w t − n + 1 ) = e y ∗ w t ∑ i e y i p(w_t∣w_{t-1}...,w _{t−n+2 },w_{t−n+1} )= \frac{e^{y*w_t}}{\sum_i e^{y_i}} p(wt∣wt−1...,wt−n+2,wt−n+1)=∑ieyiey∗wt
目标函数 y = b + W x + U t a n h ( d + H x ) y = b +Wx + Utanh(d + Hx) y=b+Wx+Utanh(d+Hx),模型的参数 θ = ( b , d , W , U , H , C ) 。 x = ( C ( w t − n + 1 ) , . . . , C ( w t − 1 ) ) \theta = (b,d,W,U,H,C)。 x=(C(w_{t-n+1}),...,C(w_{t-1})) θ=(b,d,W,U,H,C)。x=(C(wt−n+1),...,C(wt−1)) 是神经网络的输入。 W ∈ R ∣ V ∣ × ( n − 1 ) m W\in R^{|V|×(n-1)m} W∈R∣V∣×(n−1)m是可选参数,如果输入层与输出层没有直接相连(如图中绿色虚线所示),则可令W=0。 H ∈ R h × ( n − 1 ) m H \in R^{h×(n-1)m} H∈Rh×(n−1)m 是输入层到隐含层的权重矩阵,其中h表示隐含层神经元的数目。 U ∈ R ∣ V ∣ × h U\in R^{|V|×h} U∈R∣V∣×h是隐含层到输出层的权重矩阵。 d ∈ R h d\in R^{h} d∈Rh和 b ∈ R ∣ V ∣ b \in R^{|V|} b∈R∣V∣分别是隐含层和输出层的偏置参数。
3.训练过程
模型的训练目标是最大化以下似然函数:
L = 1 T ∑ t l o g f ( w t , w t − 1 , . . . , w t − n + 2 , w t − n + 1 ; θ ) + R ( θ ) L=\frac{1}{T} \sum_{t}^{ } logf(w_{t},w_{t-1},...,w_{t-n+2}, w_{t-n+1}; \theta) + R(\theta) L=T1∑tlogf(wt,wt−1,...,wt−n+2,wt−n+1;θ)+R(θ)
其中 θ \theta θ为模型的所有参数, R ( θ ) R(θ) R(θ)为正则化项使用梯度下降算法更新参数的过程如下:
θ ← θ + ϵ ∂ l o g p ( w t ∣ w t − 1 , . . . , w t − n + 2 , w t − n + 1 ) ∂ θ \theta \leftarrow \theta +\epsilon \frac{\partial logp(w_{t}|w_{t-1},...,w_{t-n+2}, w_{t-n+1}) }{\partial \theta} θ←θ+ϵ∂θ∂logp(wt∣wt−1,...,wt−n+2,wt−n+1) ,其中 ϵ \epsilon ϵ 为步长。
NNLM模型优缺点分析:
优点:使用NNLM模型生成的词向量是可以自定义维度的,维度并不会因为新扩展词而发生改变,而且这里生成的词向量能够很好的根据特征距离度量词与词之间的相似性。
缺点:计算复杂度过大,参数较多(word2vec是一种改进)。
4.3.1.1 使用pytorch实现NNLM
# 代码参考来源见引用[8]
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import numpy as np
dtype = torch.FloatTensor
sentences = [ "我 喜欢 狗", "我 爱 咖啡", "我 恨 牛奶",'狗 追 兔子','我 挤 牛奶','狗 喜欢 骨头','狗 爱 骨头']
word_list= list(set(" ".join(sentences).split()))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
# NNLM Parameter
n_step = 2 # n-1 in paper,使用前n个词预测下一个词
n_hidden = 2 # h in paper,隐藏单元数
m = 2 # m in paper,词嵌入矩阵维度
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m) # 生产词嵌入矩阵,总词数*特征m数
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype)) # 第一个隐藏层权重参数 [前n个词*特征m数,隐藏单元数h]
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype)) # 单词x的直接权重参数 [前n个词*特征m数,总单词数]
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype)) # 第一个隐藏层偏置项
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype)) # 第二个隐藏tanh权重参数[隐藏单元数h,总单词数]
self.b = nn.Parameter(torch.randn(n_class).type(dtype)) # 第二个隐藏层权重参数
def forward(self, X):
X = self.C(X)
#print('X:',X)
X = X.view(-1, n_step * m) # [batch_size, n_step * n_class]
#print('X_view:',X)
tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]
return output
def predict(self,x):
#model.C.weight[word_dict['我']]
X=torch.cat([model.C.weight[word_dict[word]] for word in x],dim=-1).unsqueeze(0)
tanh=torch.tanh(self.d+torch.mm(X,self.H))
output=self.b+torch.mm(X,self.W)+torch.mm(tanh,self.U)
return output
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
# Training
for epoch in range(20000):
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# 预测
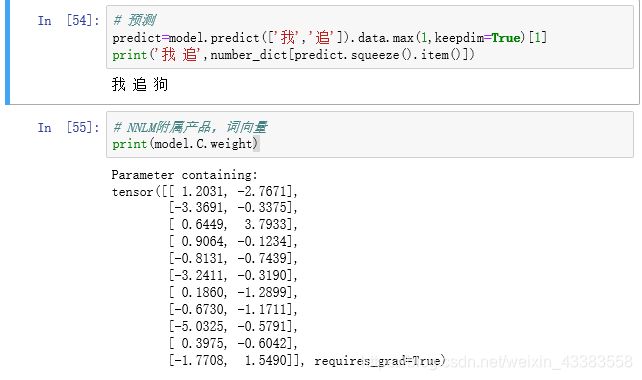
predict=model.predict(['我','追']).data.max(1,keepdim=True)[1]
print('我 追',number_dict[predict.squeeze().item()])
# NNLM附属产品,词向量
print(model.C.weight)
# NNLM词向量画图
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family']='simhei' # 用来正常显示中文 simhei SimHei
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
data=np.array(model.C.weight.tolist())
for inx,d in enumerate(data) :
plt.scatter(d[0],d[1])
plt.annotate(number_dict[inx], xy=(d[0],d[1]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
NNLM模型运行结果:
NNLM词向量画图:

4.3.2 Word2vec
词的分布式表示(distributed representation)并不是word2vec的作者Tomas Mikolov发明的,Tomas Mikolov只是提出了一种更快更好的方式来训练语言模型罢了。
两个算法:
Skip-grams (SG):预测上下文
Continuous Bag of Words (CBOW):预测目标单词
两种稍微高效一些的训练方法:
Hierarchical softmax
Negative sampling
两种算法及两种实际训练方法,组合起来有4种混合解决办法,Negative sampling实现起来更简单,更容易入门学习。实际上不加特别说明的Word2vec均指的是Skip-Gram模型,CBOW在实际生产引用中使用的较少,但它的完形填空理念被BERT等MASK语言模型所借鉴,也值得大家深入理解其理念。
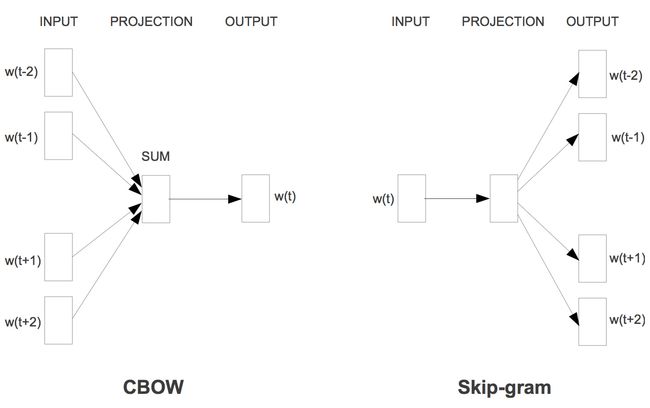
CS224n 2017 skip gram框架图。别看这张图有点乱,但其实条理很清晰,基本一图流地说明了问题。从左到右是one-hot向量,乘以center word的W于是找到词向量,乘以另一个context word的矩阵W’得到对每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。

word2vec原理推导与代码分析网上已经有很多了,这里罗列几个表较好的资源,供大家学习。
1、word2vec原理推导与代码分析 - hankcs
2、图解word2vec - 黄海广
3、理解 Word2Vec 之 Skip-Gram 模型(机器不学习)
4.3.2.1 Pytorch实现word2vec(Skip-Gram)
本文的Skip-Gram实现的比较简单(因数据量较小没有使用Hierarchical softmax或Negative sampling ),仅仅是一个三层神经网络,最终会得到W和WT两个矩阵,需要注意的是这两个矩阵都可以作为词向量使用,原作者最后是将2个矩阵拼接使用的。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family']='simhei' # 用来正常显示中文 simhei SimHei
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
dtype = torch.FloatTensor
sentences = [ '我 喜欢 狗 ', '我 喜欢 兔子 ',"我 讨厌 草", "我 爱 喝 咖啡", "我 讨厌 牛奶",'狗 追 兔子',
'我 喜欢 喝 牛奶','狗 喜欢 骨头','狗 啃 骨头','狗 和 兔子 是 朋友',
'牛 吃 草','兔子 吃 草', '牛 啃 草','狗 是 动物','兔子 是 动物','牛 是 动物',
'咖啡 是 饮料','牛奶 是 饮料 '
]
word_sequence = [sentence.split() for sentence in sentences]
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)} # 词:索引号
number_dict = {i: w for i, w in enumerate(word_list)} # 索引号: 词,这两个字典方便取数
# Word2Vec Parameter
batch_size = 20 # batch size
embedding_size = 2 # To show 2 dim embedding graph,2维的词向量,方便画图
voc_size = len(word_list) # 字典大小
# 制作随机的batch数据
def random_batch(data, size):
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(data)), size, replace=False)
for i in random_index:
random_inputs.append(np.eye(voc_size)[data[i][0]]) # target
random_labels.append(data[i][1]) # context word
return random_inputs, random_labels
# 定义Word2vec Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
# W和WT是不同矩阵,这里不存在转置关系,乘以-2,再加1,是为了得到一个比较小的起始随机数
# 原作者代码最后W和WT是拼接在一起使用的,本代码没有处理
self.W = nn.Parameter(-2 * torch.rand(voc_size, embedding_size) + 1).type(dtype) # voc_size > embedding_size Weight
self.WT = nn.Parameter(-2 * torch.rand(embedding_size, voc_size) + 1).type(dtype) # embedding_size > voc_size Weight
def forward(self, X):
# X : [batch_size, voc_size]
hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]
output_layer = torch.matmul(hidden_layer, self.WT) # output_layer : [batch_size, voc_size]
return output_layer
# 制作目标词前后1个窗口的skip gram数据
skip_grams = []
for sentence in word_sequence:
sen_len=len(sentence)
for i in range(0,sen_len ):
target = word_dict[sentence[i]]
if i-1<0: # 起始单词避免越界
skip_grams.append([target, word_dict[sentence[i + 1]]])
elif i+1>=sen_len: # 结尾单词避免越界
skip_grams.append([target, word_dict[sentence[i - 1]]])
else: # 中间的单词,可以取的前后1个窗口词
skip_grams.append([target, word_dict[sentence[i - 1]]])
skip_grams.append([target, word_dict[sentence[i + 1]]])
# 模型实例化,交叉熵损失函数,最优化方法Adam
model = Word2Vec()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
for epoch in range(50000):
input_batch, target_batch = random_batch(skip_grams, batch_size)
input_batch = Variable(torch.Tensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, voc_size], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# 画图
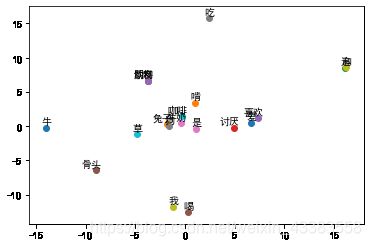
for i, label in enumerate(word_list):
W, WT = model.parameters()
x,y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x+0.05, y+0.05), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
词嵌入小结
下面对文本表示进行一个归纳,主要的词向量表示方法总结如下:
词袋模型(bag-of-words):one-hot、tf-idf、textrank;
主题模型:LSA(SVD)、pLSA、LDA;
基于词向量的固定表征:Word2vec、FastText、Glove;
基于词向量的动态表征(直到这个阶段才真正解决一词多义的问题):ELMO、GPT、BERT、XLnet;
下一篇讲讲述“特征抽取利器Transformer(Transformer XL) ?”,敬请期待!~
reference:
1、nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
2、放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 - 张俊林
3、《自然语言处理方法与应用》- 宗成庆
4、《知识指导的自然语言处理》- 刘知远
5、自然语言处理
6、从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 张俊林
7、什么是 word embedding?
8、graykode/nlp-tutorial
9、神经网络语言模型(NNLM)