Java---Collection单列集合详解
目录
一、单列集合的介绍
二、单列集合的使用
1:关于Collection
(1)迭代器遍历
(2)增强for循环遍历
(3)Lambda表达式遍历
2:List的使用
(1)ArrayList的使用
(2)LinkedList的使用
2:Set的使用
(1)HashSet的使用
(2)LinkedHashSet的使用
(3)TreeSet的使用
一、单列集合的介绍
单列集合我们可以把它理解成是一个储存数据的容器,任何类型都可以。单列集合包括有两大类。一个是Set,,一个是List。它们共同继承了Collection接口,并且在他们之下还有ArraryList,LinkedList,Vector,HashSet和TreeSet子类。总的来说它们就是帮我们存储数据的容器而已。
List的特点:有序,可重复,有索引
Set的特点:无序,不重复,无索引
二、单列集合的使用
1:关于Collection
因为单列集合四是继承了Collection接口的,所以Collection的方法单列集合都是可以使用的。
Collection方法:
add(E e) 在末尾添加元素,返回值是boolean型,添加成功返回true
remove(E e) 删除指定的元素,注意是元素,而不是下标,返回值是boolean型,删除成功返回true
isEmpty() 判断集合是否为空,返回值是boolean型
clear() 清空集合,void类型无返回值
size() 返回集合大小,返回值是int型
contains(E e) 判断元素是否存在于集合中,返回值是boolean型
我们知道了Set集合是无索引的,但是List集合是有索引的,遍历的话List可以通过索引,那么Set该如何遍历呢?所以我们就要学习通用的Collection遍历了。
Colletion的三种遍历方式:
(1)迭代器遍历
迭代器,什么是迭代器呢?如果学过C语言的话就可以将它理解成是指针。没学过的话不要紧,之前不是说集合就相当于是个容器吗,那么集合就是一个很大的容器,其中的元素我们当成是一个一个的小容器,放在大容器中。那么现在我们想找到其中一个小容器,这时候迭代器就有用处了,它就相当于是一个箭头,指着某一个小容器,当我们获取迭代器时,我们就可以获得迭代器指向的该小容器获得元素,想要遍历只要控制好迭代器就好了。
package article;
import java.util.Collection;
import java.util.*;
public class first {
public static void main(String[] args) {
Collection s=new ArrayList<>();
s.add("123");
s.add("jkjk");
s.add("iuiui");
s.add("klk");
System.out.println(s);
System.out.println("遍历----------------");
Iterator it=s.iterator();//创建迭代器对象
while(it.hasNext()) {
String h=it.next();//
System.out.println(h);
}
}
}

这里创建了Iterator的对象之后,我们遍历时用到了它的两种方法
hasNext() 判断当前迭代器指向的位置是否有元素
next() 获取迭代器当前指向的元素,并将迭代器往后移动一个位置
注意啊,使用迭代器遍历时是不能对集合进行增添和删除的(2)增强for循环遍历
增强for循环就是固定格式,大家记住就行了
package article;
import java.util.Collection;
import java.util.*;
public class first {
public static void main(String[] args) {
Collection s=new ArrayList<>();
s.add("123");
s.add("jkjk");
s.add("iuiui");
s.add("klk");
System.out.println(s);
System.out.println("遍历----------------");
for(String h:s) {
//这里的s就是集合,而h就是一个替换的,也就是说将s集合中的每个元素都给了h
System.out.println(h);
}
}
}

(3)Lambda表达式遍历
Lambda也是固定格式,使用的是匿名内部类形式
package article;
import java.util.Collection;
import java.util.*;
public class first {
public static void main(String[] args) {
Collection s=new ArrayList<>();
s.add("123");
s.add("jkjk");
s.add("iuiui");
s.add("klk");
System.out.println(s);
System.out.println("遍历----------------");
s.forEach(h->System.out.println(h));
}
}

2:List的使用
List继承了Collection,包括他的方法,当然我们也有一些List常用的方法来掌握
List中常见的方法:
void add(int index,E e) 在集合中指定的下标处添加元素
E remove(int intdex)删除指定下标处的元素,并返回
E set(int index,E e)修改指定下标出的元素,返回被修改的元素
E get(int index)返回指定下标处的元素package article;
import java.util.Collection;
import java.util.*;
public class first {
public static void main(String[] args) {
List s=new ArrayList<>();
s.add("123");
s.add("opop");
s.add("sdsds");
System.out.println(s);
s.add(1,"mmmmmm");
System.out.println(s);
String ss=s.remove(3);
System.out.println("删除的元素是"+ss+" 现在集合:"+s);
s.set(2,"klklkkkkk");
System.out.println(s);
for(int i=0;i 
(1)ArrayList的使用
在之前我已经写过了关于ArrayList的文章:ArrayList的详解 。
使用ArrayList只要会用Collection的方法就够了
package article;
import java.util.Collection;
import java.util.*;
public class first {
public static void main(String[] args) {
Collection s=new ArrayList<>();
s.add("123");
s.add("jkjk");
s.add("iuiui");
s.add("klk");
System.out.println("该集合的大小="+s.size());
System.out.println(s);
//boolean b=s.remove("123");
//System.out.println("删除:"+b);
System.out.println(s);
boolean bb=s.contains("123");
System.out.println("包含:"+bb);
}
}

(2)LinkedList的使用
LinkedList顶层是双链表实现的(其中学过数据结构的同学应该更加了解,一个节点中有元素值同时还有前后节点的地址值,这就是它增删改快的原因),查找慢,但是删增改快。因此它也出现了一些特有的方法
void addFirst(E e) 在该链表开头插入指定的元素
void addLast(E e) 将指定的元素插入到末尾
E getFirst() 获取当前链表中的第一个元素
E getLast() 获取当前链表中的最后一个元素
E removeFirst() 删除该链表中的第一个元素,并返回
E removeLast() 删除该链表中的最后一个元素,并返回package article;
import java.util.Collection;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
LinkedList s=new LinkedList<>();
s.add("122");
s.add("shdj");
s.add(">>>>>>>");
s.addFirst("<<<<<<<-----");
System.out.println(s.getFirst());
}
}

2:Set的使用
Set集合的特点不要忘记了,无序(取出顺序和拿出顺序不一致),无索引(不可再用索引的方法遍历了),不重复(重复的元素,会去除)。Set的基本方法也是和Collection的方法是一致的(原因就是继承啊)
Set的实现类:
(1)HashSet:底层实现结构是哈希表,无序不重复,无索引
(2)LinkedHashSet:有序,不重复,无索引
(3)TreeSet:可排序,不重复,无索引
(1)HashSet的使用
关于HanshSet的特点在强调一遍是无序,不重复,无索引。因为它是无索引的,所以遍历可以用Collection的三种方法来遍历。
package article;
import java.util.Collection;
import java.util.function.Consumer;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
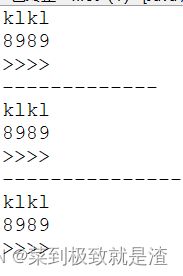
Set s=new HashSet<>();
s.add("8989");
s.add("klkl");
s.add(">>>>");
Iterator it=s.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
System.out.println("-------------");
//增强for
for(String h:s) {
System.out.println(h);
}
System.out.println("---------------");
//Lambda表达式
s.forEach(new Consumer() {
public void accept(String st) {
System.out.println(st);
}
});
}
}
如果添加的类型是自写的,在自写类中需要重写equals和HashCode方法,因为equals比较的是地址值。
package article;
import java.util.Objects;
public class student {
String name;
int age;
public student(String name,int age) {
this.age=age;
this.name=name;
}
public void setname(String name) {
this.name=name;
}
public void setage(int age) {
this.age=age;
}
public String getname() {
return name;
}
public int getage() {
return age;
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
student other = (student) obj;
return age == other.age && Objects.equals(name, other.name);
}
}
package article;
import java.util.Collection;
import java.util.function.Consumer;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
Set s=new HashSet<>();
student s1=new student("uiu",190);
student s2=new student("opop",200);
student s3=new student("klkl",1000);
student s4=new student("opop",200);
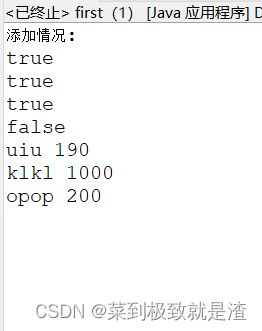
System.out.println("添加情况:");
System.out.println(s.add(s1));
System.out.println(s.add(s2));
System.out.println(s.add(s3));
System.out.println(s.add(s4));
//迭代器遍历
Iterator it=s.iterator();
while(it.hasNext()) {
student ss=it.next();
System.out.println(ss.getname()+" "+ss.getage());
}
}
}
(2)LinkedHashSet的使用
LinkedHashSet的特点:有序,无重复,无索引。有序的话它的遍历输出就和放进去的元素是一样的,数据结构中的队列差不多吧。使用方法和前面说到的HahsSet是一样的。
package article;
import java.util.Collection;
import java.util.function.Consumer;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
Set s=new LinkedHashSet<>();
s.add("klkl");
s.add("99999");
s.add(">>>");
s.add("+++++");
s.forEach(new Consumer(){
public void accept(String ss) {
System.out.println(ss);
}
});
}
}
 ()
()
(3)TreeSet的使用
TreeSet的特点:可排序,无重复,无索引。TreeSet的使用方法和其他集合还是一样的,不过最大的不同就是它可排序,它的底层是基于红黑树实现的,所以对于它,我们着重学习如何排序。它的排序方法有两种。一种是用Comparaable接口实现,一种是使用比较器进行排序。当然它是有着默认排序的,对于数字按照升序,对于字母按照ASCII升序。
1:Comparable接口排序:
这里的o代表的就是当前准备插入的元素,不明白排序规则,记住this在前就是升序就可以了
package article;
import java.util.Objects;
public class student implements Comparable{
String name;
int age;
public student(String name,int age) {
this.age=age;
this.name=name;
}
public void setname(String name) {
this.name=name;
}
public void setage(int age) {
this.age=age;
}
public String getname() {
return name;
}
public int getage() {
return age;
}
@Override
public int compareTo(student o) {
// TODO 自动生成的方法存根
int t=this.name.compareTo(o.name);//先按年龄升序,相同按照年龄升序
if(t==0) {
return this.age-o.age;
}
return t;
}
}
package article;
import java.util.Collection;
import java.util.function.Consumer;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
Set s=new TreeSet<>();
student s1=new student("abc",20);
student s2=new student("abk",30);
student s3=new student("dec",10);
student s4=new student("dbc",29);
student s5=new student("abc",30);
student s6=new student("abc",40);
s.add(s1);
s.add(s2);
s.add(s3);
s.add(s4);
s.add(s5);
s.add(s6);
s.forEach(new Consumer() {
@Override
public void accept(student t) {
// TODO 自动生成的方法存根
System.out.println(t.getname()+" "+t.getage());
}
});
}
}

2:比较器排序
这里的排序规则可以理解成o1在前就是升序,o2在前就是降序
package article;
import java.util.Collection;
import java.util.function.Consumer;
import java.util.*;
import java.util.*;
public class first {
public static void main(String[] args) {
Set s=new TreeSet<>(new Comparator() {
@Override
public int compare(student o1, student o2) {
// TODO 自动生成的方法存根
//先按照名字升序,相同则按照年龄降序
int t=o1.name.compareTo(o2.name);
if(t==0) {
return o2.age-o1.age;
}
return t;
}
});
student s1=new student("abc",20);
student s2=new student("abk",30);
student s3=new student("dec",10);
student s4=new student("dbc",29);
student s5=new student("abc",30);
student s6=new student("abc",40);
s.add(s1);
s.add(s2);
s.add(s3);
s.add(s4);
s.add(s5);
s.add(s6);
s.forEach(new Consumer() {
@Override
public void accept(student t) {
// TODO 自动生成的方法存根
System.out.println(t.getname()+" "+t.getage());
}
});
}
}
