Java集合之单列集合
分类
集合分为单列集合(Collection)和双列集合(Map)
单列集合的体系结构

List集合和Set集合的区别
- List系列集合:添加元素是有序的(添加的顺序,而非数据的大小顺序)、可重复、有索引
- Set系列集合:添加的元素是无序的(添加的顺序,而非数据的大小顺序,并且是可能不是有序的)、不可重复、无索引
contains方法细节
- 底层是依赖equals方法进行判断自定义对象是否存在的
- 要想通过contains方法判断自定义对象是否存在集合中,就必须在自定义对象类中重写equals方法,因为如果自定义类中没有重写equals方法,它会默认使用Object类中的equals方法进行判断,而Object类中的equals方法是通过地址值进行判断的。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals( name, student.name );
}public class Test01 {
public static void main(String[] args) {
Student stu = new Student( "来一沓Java", 18 );
Collection coll = new ArrayList();
coll.add( stu );
Student stu1 = new Student( "来一沓Java", 18 );
boolean b = coll.contains( stu1 );
System.out.println(b);//true
}
} 集合遍历方式
Collection的通用遍历方式有四三种,增强for循环遍历、迭代器遍历、Lambda表达式遍历
迭代器遍历
迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式
Collection集合获取迭代器
Iterator
iterator():返回迭代器对象,默认指向当前集合的0索引
Iterator中常用的方法
Boolean hasNext():判断当前位置是否有元素,有返回true,没有返回false
E next():获取当前位置的元素,并将迭代器对象移向下一个位置
public class Test01 {
public static void main(String[] args) {
Collection col = new ArrayList<>();
col.add( "今" );
col.add( "天" );
col.add( "学" );
col.add( "习" );
col.add( "了" );
col.add( "吗" );
col.add( "?" );
Iterator iterator = col.iterator();//获取迭代器对象
while (iterator.hasNext()){//判断当前位置是否有元素
String s = iterator.next();//获取当前位置的元素
System.out.print( s);
}
}
} 细节注意
- 如果迭代器已经指向最后的位置且没有元素,还要强行调用next方法获取元素,就会报NoSuchElementException
- 迭代器遍历完毕后,指针是不会复位的
- 循环中只能调用一次next方法
- 迭代器遍历时,不能用集合的方法进行增加或删除元素
增强for遍历
- 增强for的底层就是一个迭代器,为了简化迭代器的代码书写的
- 它是JDK5之后出现的,内部原理就是一个Iterator迭代器
- 所有的单列集合和数组才能用增强for进行遍历
public class Test02 {
public static void main(String[] args) {
Collection col = new ArrayList<>();
col.add( "今" );
col.add( "天" );
col.add( "学" );
col.add( "习" );
col.add( "了" );
col.add( "吗" );
col.add( "?" );
for (String s : col) {
System.out.print(s);
}
}
} 注意细节
修改增强for中的变量,是不会改变集合原来的数据
Lambda表达式遍历
JDK8开始出现的,是一种简单直接的遍历集合的方式
public class Test03 {
public static void main(String[] args) {
Collection col = new ArrayList<>();
col.add( "今" );
col.add( "天" );
col.add( "学" );
col.add( "习" );
col.add( "了" );
col.add( "吗" );
col.add( "?" );
//forEach方法底层原理:其实也会自己遍历,一次得到每一个元素,把得到的元素,传递给下面的accept方法
//col.forEach( new Consumer() {
//@Override
//public void accept(String s) {
//System.out.print(s);
// }
//} );
col.forEach( s -> System.out.print(s) );
}
} List系列集合
List集合特有的方法
- void add(int index,E element):在集合的指定位置插入元素,原来索引处后面的元素一次往后移动
- E remove(int index):删除指定位置的元素并返回
- E set(int index,E element):修改指定位置的元素,返回被修改的元素
- E get(int index):返回指定位置的元素
细节注意
- 调用方式的时候,如果方法出现了重载现象,会优先调用形参和实参类型一致的那个方法
List集合的遍历方式
List集合遍历方法有五种,迭代器遍历、增强for、普通for循环、Lambda表达式、列表迭代器
迭代器遍历
public class Test01 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add( 1 );
list.add( 2 );
list.add( 3 );
Iterator it = list.iterator();
while (it.hasNext()){
Integer next = it.next();
System.out.print(next);
}
}
} 增强for遍历
public class Test02 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add( 1 );
list.add( 2 );
list.add( 3 );
for (Integer integer : list) {
System.out.print(integer);
}
}
} 普通for遍历
public class Test03 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add( 1 );
list.add( 2 );
list.add( 3 );
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get( i ));
}
}
} Lambda表达式遍历
public class Test04 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add( 1 );
list.add( 2 );
list.add( 3 );
list.forEach( integer -> System.out.print(integer) );
}
} 列表迭代器遍历
public class Test05 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add( 1 );
list.add( 2 );
list.add( 3 );
//获取一个列表迭代器对象,里面的指针默认指向0索引
//列表迭代器中额外添加了一个方法,在遍历的时候,可以添加元素
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()){
Integer next = listIterator.next();
System.out.print(next);
}
}
} 五种方式对比
- 在遍历过程中需要删除元素,用迭代器
- 在遍历过程中需要添加元素,用列表迭代器
- 在遍历过程中不做任何操作,使用增强for或Lambda表达式
- 遍历过程中需要用到索引,使用普通for遍历
数据结构(栈、队列、数组、链表)
- 是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。
- 数据结构的学习思路:每种数据结构长啥样子-->如何添加数据-->如何删除数据。
栈
特点:先进后出,后进先出
队列
特点:先进先出,后进后出
数组【查询快,增删慢】
- 查询速度快:通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中连续存储的)。
- 删除效率低:要删除元素的同时,后面的元素一次往前挪。
- 添加效率极低:添加位置后的每一个元素都要往后移,在添加元素。
单向链表【查询慢、增删快】
- 每一个节点都有两个空间,第一个存储只是需要存储的值,第二个存储的是下一个节点的地址
- 链表中的节点是独立的对象,在内存中是不连续的,每一个节点包含数值和下一个节点的地址
双向链表
- 每一个节点都有三个空间,第一个存储的是前一个节点的地址,第二个存储的是真实需要存储的值,第三个存储的是下一个节点的地址
- 链表中的节点是独立的对象,在内存中是不连续的,每一个节点包含前一个节点的地址、需要存储的数值和下一个节点的地址
ArrayList源码分析
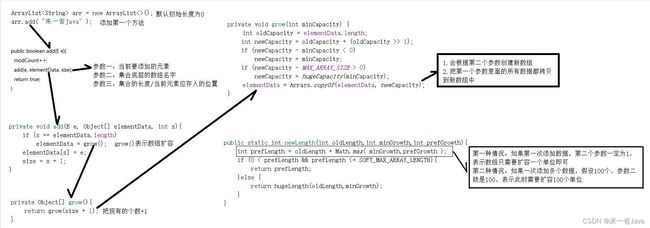
ArrayList集合底层原理
- 利用空参创建的集合,在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- 当存满时,会创建一个长度是原来数组的1.5倍,把元数组中的数据拷贝到新数组中,再将新数组赋值给原来的数组【存满时,会扩容1.5倍】
- 如果一次添加多个元素,1.5倍不够放,新创建的数组的长度以实际长度为准
分析图
LinkedList集合源码分析
底层数据结构是双向链表,查询慢,增删快,但是如果操作的是首尾相连元素,速度就很快了。
LinkedList集合特有方法
- public void addFirst(E e):在该列表开头插入指定元素
- public void addLast(E e):将指定的元素追加到列表的末尾
- public E getFirst():返回列表中的第一个元素
- public E getLast():返回列表中的最后一个元素
- public E removeFirst():删除列表中的第一个元素并返回
- public E removeLast():删除列表中的最后一个元素并返回
源码分析
public class Test01 {
public static void main(String[] args) {
LinkedList lk = new LinkedList<>();
lk.add( "aaa" );
lk.add( "bbb" );
lk.add( "ccc" );
}
} public boolean add(E e) {//参数e表示现在要添加的元素
linkLast(e);
return true;
} void linkLast(E e) {//参数e表示现在要添加的元素
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} 下面代码表示链表中的一个节点
private static class Node {
E item;//存储的数据
Node next;//前一个结点的地址
Node prev;//后一个节点的地址
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 当第一次添加元素时,会调用第三段代码,会把 last(null)【一个节点当中存储下一个节点地址的值】 赋值给 l ,然后new Node<>(l,e,null)创建一个新节点,然后再把新节点赋值给 last 后,判断 l 是否为空,如果为空,就把新节点赋值给 first ,否则就把新节点的地址赋值给 l.next;
当不是第一次添加元素时,会把同一个LinkedList集合最后一次添加的数据所在的节点赋值给 l ,后new Node<>(l,e,null)创建新节点,后再把新节点赋值给 last ,判断 l 是否为空,显然不为空,就将新节点的地址赋值给 l.next。
迭代器源码分析
public class Test01 {
public static void main(String[] args) {
ArrayList list = new ArrayList<>();
list.add( "aaa" );
list.add( "bbb" );
list.add( "ccc" );
list.add( "ddd" );
//在底层就是创建一个内部类的对象,这个内部类表示是ArrayList的迭代器,所以多次调用这个方法时,相当于创建多个迭代器的对象
Iterator iterator = list.iterator();
while (iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
}
} public Iterator iterator() {
return new Itr();
} private class Itr implements Iterator {
int cursor; // 下一个要返回的元素的索引,相当于指针,指向要返回的数据索引
int lastRet = -1; // 最后一次操作的索引
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
public E next() {
checkForComodification();
int i = cursor;//记录当前指针指向的索引位置
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
} 当调用iterator()方法时,会创建一个Itr的内部类对象,进入循环以后,判断cursor是否等于集合的长度,如果不是,hasNext()方法返回true,循环继续,当调用next()方法时,将cursor的值赋值给 i ,判断 i 是否大于等于集合长度,如果大于等于,就抛出异常,如果不是,cursor等于 i + 1【将当前的指针向后移动一位】,然后将 i 的值赋值给lastRet,并返回数组elementData中lastRet索引处的元素。
modCount:表示集合变化的次数,每add或remove一次,modCount都会自增,当创建迭代器的时候,就会把变化的次数告诉迭代器。而checkForComodification();就是校验传入迭代器的次数与当前变化次数是否相同,不同报并发修改异常。
Set系列集合
- 无序:存取顺序不一致
- 不重复:数据有唯一性,可以利用数据去重
- 无索引:没有带索引的方法,所以不能通过索引来操作集合
- Set系列集合的方法基本上和Collection的API一致
HashSet
- 无序、不重复、无索引
底层
- HashSet集合底层是通过哈希表【一种对于数据增删查改性能比较好的结构,JDK8之前由数组和链表组成,JDK8开始由数组、链表和红黑树组成】存储数据
- 开始会创建一个默认长度为16,默认加载因子为0.75【扩容时机,当数组中存了 数组长度 x 0.75 个元素时,就会扩容到原来的2倍;JDK8之后,当链表长度大于8且数组长度大于等于64,链表会自动转成红黑树】的数组table
- 根据元素的哈希值跟数组的长度计算出应存入的位置
- 判断当前位置是否有元素,没有元素直接存入
- 如果有元素,会调用equals方法比较属性
- 如果属性值一样就不存入,如果不一样,存入数组,形成链表【JDK8以前:新元素存入数组,老元素挂在新元素下面 JDK8后:新元素直接挂在老元素的下面】
对象哈希值的特点
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果重写hashCode方法,不同对象只要属性值相同,计算出的哈希值就是一样的
- 部分情况下,不同属性值或不同地址值计算出来的哈希值可能是一样的【哈希碰撞】
哈希值
- 根据hashCode方法计算出的int类型的整数
- 该方法定义在Object类中,所有对象都可调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
LinkedHashSet
- 有序、不重复、无索引
LinkedHashSet底层原理
- 底层数据结构依旧是哈希表,只是每个元素又额外多了一个双链表机制记录存储的顺序
- 当添加第二个元素之后,第一个元素会记录第二元素地址值,第二个元素也会记录第一个元素的地址值,依次往后
- 如果后面添加的元素哈希值相同的情况下,新元素会以双向链表的形式直接挂在老元素的下面,在该元素之后添加的一个数据,如果不产生哈希冲突,就存入数组,和该元素形成双向链表
TreeSet
- 可排序、不重复、无索引
- TreeSet底层基于红黑树的数据结构实现排序,增删查改性能较好
TreeSet集合默认排序规则
- 数值类型:Integer、Double,默认从小到大排序
- 字符、字符串:按照字符在ASCII码中数字升序进行排序
TreeSet集合比较方式一
- 默认排序/自然排序:javabean类中实现Comparable接口指定比较规则
public class Student implements Comparable{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
return this.getAge()-o.getAge();
}
} public class Test02 {
public static void main(String[] args) {
Student s1 = new Student( "wi", 18 );
Student s2 = new Student( "xn", 19 );
Student s3 = new Student( "xg", 17 );
TreeSet set = new TreeSet<>();
set.add( s1 );
set.add( s2 );
set.add( s3 );
System.out.println( set );
}
} TreeSet集合比较方式二
- 比较器排序:创建TreeSet的时候,传递比较器Comparator指定规则,默认使用第一种,当第一种不满足时,就使用第二种比较方式
public class Test03 {
//"c","ab","df","java",四个字符串按照长度比较,如果一样长的按照首字母顺序排序
public static void main(String[] args) {
TreeSet set = new TreeSet<>( new Comparator() {
@Override
public int compare(String o1, String o2) {
int i = o1.length() - o2.length();
i = i == 0 ? o1.compareTo( o2 ) : i;
return i;
}
} );
set.add( "c" );
set.add( "ab" );
set.add( "df" );
set.add( "java" );
System.out.println( set );
}
}