Java之单列集合
学习流程图

ArrayList的sort方法不传构造器默认正序排序
一.集合的引出
之前我们存放多个数据使用数,但是数组的灵活性太差
数组扩容更是麻烦

所以我们引出一个可以动态管理对象应用:集合
集合的好处
1.动态保存任意多个个对象,使用方便
2.提供一系列方便操作对象的方法
3.使用集合添加,删除新元素,简洁明了
集合体系图
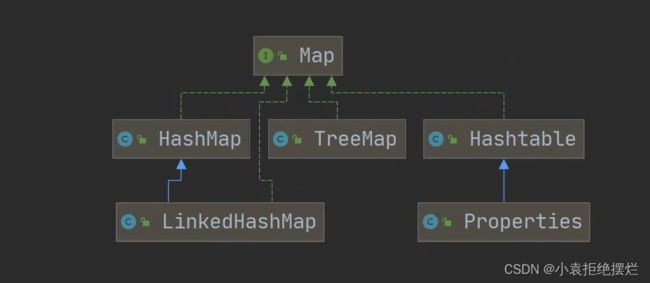
集合主要是两组(单列集合和双列集合)
单列集合
Collection接口有两个重要子接口
一个是List
一个是Set
它们的实现子类都是单列集合

双列集合
Map接口的实现子类都是双列集合
二.单列集合
Collection接口方法
1.add()
ArrayList arrayList = new ArrayList();
String s = new String("jack");
//add方法,形参是Object o(是对象就行)
//返回值是布尔值,判断添加是否成功
arrayList.add(new String(s));
arrayList.add(10);//arraylist.add(new Integer(10))
arrayList.add(1.6f);//arraylist.add(new Float(10))
arrayList.add(true);//arraylist.add(new Boolean(10))
arrayList.add("ykj");
// 参数是基本数据类型,实际上是加的是它们的包装类
System.out.println(arrayList);
2.remove()
//remove(索引/对象)方法
//删除索引返回布尔值,判断删除成功与否
//删除对象返回你删除的对象
//方法经过重载参数可以是索引或者是你想删除的对象
arrayList.remove(1);//索引形式
arrayList.remove(s);//对象形式
arrayList.remove(Integer.valueOf(10));//想要删除对象10的话,要把它转成Integer
arrayList.remove(true);//布尔值特殊可以不改
System.out.println(arrayList);
3.contains()
//contains(对象)
//查找该对象在集合中有无,有返回true,无返回false
if(arrayList.contains(Float.valueOf(1.6f))){
System.out.println("有1.6");
}
4.clear()
//clear()清空操作,清空集合中的所有对象,不返回值
System.out.println("清空前"+arrayList);
arrayList.clear();
System.out.println("清空后"+arrayList);
5.addAll()
//addAll:添加多个元素
//两种重写addAll(Collection c)添加这个集合所有元素
//addAll(int idex,Collection c)添加这个集合对应索引的元素
//返回布尔,判断成功与否
ArrayList list = new ArrayList();
list.add("红楼梦");
list.add("三国演义");
list.add("水浒传");
arrayList.addAll(list);
System.out.println("addAll后"+arrayList);
6.containsAll()
//containsAll:查找多个元素是否存在
//containsAll(Collection c)
//返回布尔值,判断有无
System.out.println( arrayList.containsAll(list));
7.removeAll()
//removeAll:删除多个元素
//removeAll(Collection c)
//删除调用集合中所有在c中存在的
arrayList.removeAll(list);
System.out.println("删除多个元素后"+arrayList);
8.size()
获取集合的长度
全代码+效果图
package com.hansp.Collection;
import java.util.ArrayList;
import java.util.Collection;
public class Collection_ {
@SuppressWarnings("all")
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
String s = new String("jack");
//add方法,形参是Object o(是对象就行)
//返回值是布尔值,判断添加是否成功
arrayList.add(new String(s));
arrayList.add(10);//arraylist.add(new Integer(10))
arrayList.add(1.6f);//arraylist.add(new Float(10))
arrayList.add(true);//arraylist.add(new Boolean(10))
arrayList.add("ykj");
// 参数是基本数据类型,实际上是加的是它们的包装类
System.out.println(arrayList);
//remove(索引/对象)方法
//删除索引返回布尔值,判断删除成功与否
//删除对象返回你删除的对象
//方法经过重载参数可以是索引或者是你想删除的对象
arrayList.remove(1);//索引形式
arrayList.remove(s);//对象形式
arrayList.remove(Integer.valueOf(10));//想要删除对象10的话,要把它转成Integer
arrayList.remove(true);//布尔值特殊可以不改
System.out.println(arrayList);
//contains(对象)
//查找该对象在集合中有无,有返回true,无返回false
if(arrayList.contains(Float.valueOf(1.6f))){
System.out.println("有1.6");
}
//clear()清空操作,清空集合中的所有对象,不返回值
System.out.println("清空前"+arrayList);
arrayList.clear();
System.out.println("清空后"+arrayList);
//addAll:添加多个元素
//两种重写addAll(Collection c)添加这个集合所有元素
//addAll(int idex,Collection c)添加这个集合对应索引的元素
//返回布尔,判断成功与否
ArrayList list = new ArrayList();
list.add("红楼梦");
list.add("三国演义");
list.add("水浒传");
arrayList.addAll(list);
System.out.println("addAll后"+arrayList);
//containsAll:查找多个元素是否存在
//containsAll(Collection c)
//返回布尔值,判断有无
System.out.println( arrayList.containsAll(list));
//removeAll:删除多个元素
//removeAll(Collection c)
//删除调用集合中所有在c中存在的
arrayList.removeAll(list);
System.out.println("删除多个元素后"+arrayList);
}
}
接口遍历
Inerator()迭代器
简介
所有实现了Collection接口的集合类,都有一个iterator()方法
可以返回一个实现了Iterator的对象,即迭代器
Iterator用于遍历集合,本身不存放对象
执行原理
注意
刚开始没有指向集合中的元素
进行一次next()才指向集合中的第一个元素
通过
迭代器的方法遍历集合
iterator.next()返回下一个迭代器中对应的对象(Object类型)
iterator.hasNext()判断有没有对应集合中有没有下一个对象
没有返回false有返回true
一般两个方法要搭配使用
应用及效果图
package com.hansp.Collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Iterator_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection c=new ArrayList();
c.add("三国");
c.add("红楼梦");
c.add("西游记");
Iterator a=c.iterator();
while (a.hasNext()){
System.out.println(a.next());
}
}
}

多次迭代遍历
当while循环结束后
迭代器已经指向最后元素
再用next会出异常
如果希望再次遍历
需要重置迭代器
直接再赋一遍值即可
Iterator a=c.iterator();
//...,结束玩循环
a=c.iterator();//这样就又指向第一个元素的上面了
集合增强for
简介
增强for循环可替代迭代器
就是简化版的iterator,只能访问遍历集合和数组

代码展示
public class Iterator_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("三国");
c.add("红楼梦");
c.add("西游记");
//使用增强for循环
//底部还是用迭代器
//快捷键I
for(Object String:c){
System.out.println(String);
}
//增强for也可以直接在数组使用
int []nums={1,5,8,9,6,7,3,4};
for (int i:nums
) {
System.out.println(i);
}
}
}
List接口方法
add()
List list = new ArrayList();
list.add("小袁");
list.add("无语");
//add(int index,Obiect ele)
//在索引index插入,ele元素
list.add(2,"大");
list.add(1,"小");

addAll()
//addAll(int index,Collection ele)
//从索引index位置开始,将ele所有元素加进来
ArrayList arrayList = new ArrayList();
arrayList.add("努力");
arrayList.add("加油");
list.addAll(1,arrayList);
System.out.println(list);

get()
//Object get(int index)
//获取索引index位置的元素
System.out.println(list.get(1));
注意返回的是Object对象,想调用你存储的类的方法需要向下转型

indexOf()
//int indexOf(Object obj):返回obj在集合中首次出现的位置
System.out.println(list.indexOf("无语"));

lastIndexOf()
//int lastIndexOf(Object obj):返回obj在集合中最后一次出现的位置
System.out.println(list.lastIndexOf("无语"));
remove()
//Object remove(int index):移除指定index位置的元素,并返回此元素
System.out.println(list.remove(1));
System.out.println(list);
set()
//Object set(int index,Object ele):将index处的元素替换为ele
list.set(0,"AI");
System.out.println(list);
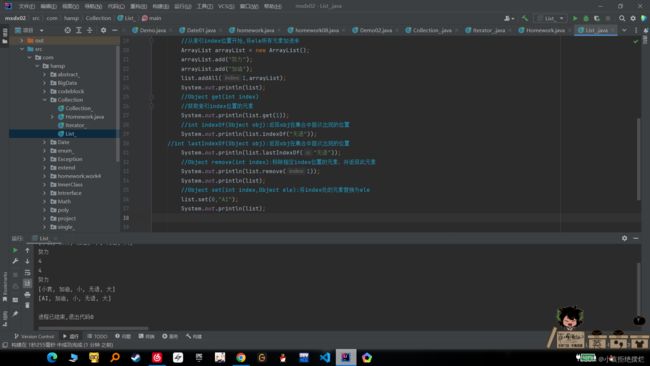
subList
//List subList(int formIndex,int toIndex)
//返回从formIndex到toIndex位置的子集合[formIndex,toIndex)
System.out.println(list.subList(0,2));
List接口遍历方法
可以使用前面的Collection接口两种遍历方法
增加一种普通for遍历方法
for(i=0,i
Object object=list.get(i);
System.out.println(object)
}
例题,集合排序
题目
解答
package com.hansp.Collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
@SuppressWarnings({"all"})
public class List_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add(new Book("红楼梦", 100, "曹雪芹"));
arrayList.add(new Book("西游记", 80, "吴承恩"));
arrayList.add(new Book("红楼梦", 50, "三国演义"));
sort(arrayList);
System.out.println(arrayList);
}
public static void sort(List c){
for (int i = 0; i < c.size()-1; i++) {
for (int j = 0; j <c.size()-1; j++) {
Object o = c.get(j);
Object p = c.get(j+1);
Book a=(Book)o;
Book b=(Book)p;
if(a.price> b.price){
c.set(j,p);
c.set(j+1,o);
}
}
}
}
}
class Book{ private String bookname;
public double price;
private String author;
public String getBookname() {
return bookname;
}
public void setBookname(String bookname) {
this.bookname = bookname;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {
return "Book{" +
"bookname='" + bookname + '\'' +
", price=" + price +
", author='" + author + '\'' +
'}';
}
public Book(String bookname, double price, String author) {
this.bookname = bookname;
this.price = price;
this.author = author;
}
}
效果图
ArrayList
简介
ArrayList可以存储所有对象,包括null,可以同时存储多个null
ArrayList是由数组实现数据存储的
ArrayList基本等同于Vector
不过ArrayList线程不安全(指向效率高),多线程用Vector
底层结构(结论)
先说结论:
1.ArrayList中维护了一个Object类型的数组elementData
transient Object[] elementData
transient修饰的属性不会被序列化
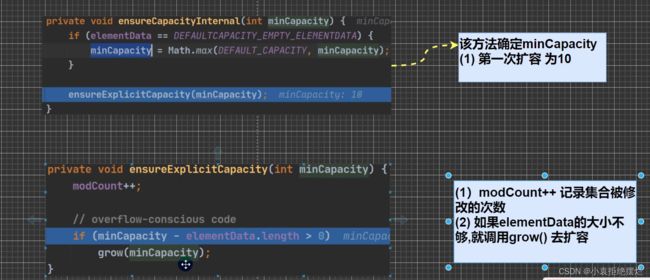
2.当创建ArrayList对象时,如果使用的是无参构造,则初始elementData的容量为0
第一次添加,则扩容elementData为10,如需再次扩容则扩容elemrntData为1.5倍
3.若使用有参构造,则初始elementData容量为指定大小,如需要扩容,则直接扩容elementData为1.5倍
源码分析
无参时


有参时其实和无参区别不大
基本上只有进入构造器的方法
还有if的条件的符合有差别
中间的过程是差不多的

Vector
简介
Vector的大多数的方法和arrayList相同
底层也是protected Object[] elementData一个数组
Vector是线程同步的,线程安全
Vector类的操作方法都有synchronized
开发中需要线程同步安全时使用Vector
底层结构与arrayList相比

源码分析
基本和arrayList源码差不多
这里的grow()扩容机制
有所更改
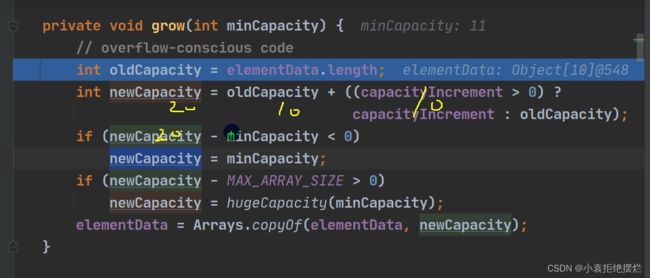
这里的capacityIncrement是0所以三位运算符返回OldCapacity所以相当于二倍
关于capacityIncrement的问题,这个参数是你自己设定的,就是每次扩容扩容的长度
默认是0,执行二倍操作,如果你赋值了,每次就是扩容你赋的值的长度
一位弹幕的解释
我刚刚去看了下源码,因为老韩用的是无参构造器。其实还有有参构造器,用了这个capacityIncrement,为了照顾那个构造器,方法里多了这个。无惨构造器,这个数据就是0
还有无参构造
直接是调用的有参构造

分配十个空间
有参构造,指定空间
还有一个构造器,就是指定capacityIncrement的大小
Vector(10,5)
刚开始赋10个空间
每次需要扩容,扩容五个空间,就不是默认的二倍了
LinkedList
简单介绍

底层结构

双向链表增加或者删除数据之需要改变指定位置的数据存放(指向),运行起来小路很高
想添加位置1 添加元素为2 想添加位置前一位3
图中比如想添加元素可以直让想添加位置3的next直接=2的item然后让2的prve=3的item
然后添加的元素和前一位元素的关系确定好了
确定一下与后一位的关系
让2的next=1的item,1的pre指向2的item
就完成了增加
效果图
数组就要一个个变比链表麻烦
源码分析
LinkedList中的add()
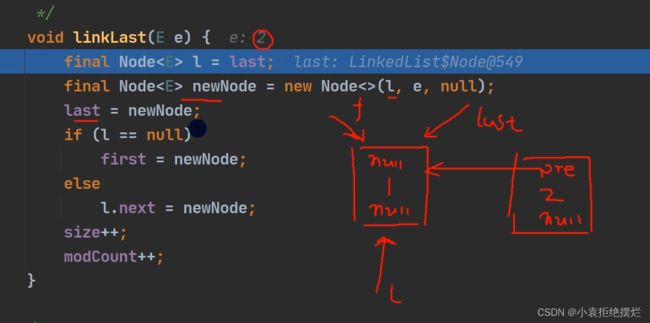
第一次创的话
new Linkedlist();
会创建一个Linkedlist对象此时
first和last(两个Node对象)都是空(null)
会走if的第一条语句
让首节点和尾结点都指向第一个add的元素
如果是第二个,l=last,l就变为了last指向的对象(即第一个元素)
然后指向第二句让last指向第二个元素
然后l操作是吧第一个元素的next指向第二个元素
到了第三个的话同样操作
l负责前一个next指向后一个元素
last就一直等于新创建的对象
LinkedList中的remove
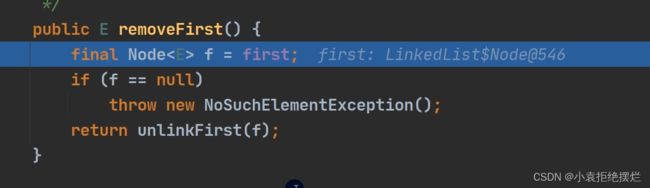
f指向first,如果有first有指向实行unLinkFirst(f)方法

f还是代表第一个元素
next代表第二个元素
List集合选择(对比)
Set
Set简介
1.无序,添加和去除的顺序不一致没有索引
2.不允许重复元素所以至多添加一个null
3.继承关系
Set接口方法
Set接口和List接口一样实现了Collection接口,因此常用方法和Collection接口一样
以实现Set的HashSet类对象来演示
添加取出顺序不一致,但是取出顺序是有一个算法(顺序是固定的)
Set接口遍历方式
和Collection接口遍历一样
不同于List接口的普通for用索引来循环
Set接口只有
迭代器和增强for循环
HashSet
简单介绍
对于不能有重复元素理解(面试)
new Dog(“s”)
new Dog(“s”)
可以存放着两个元素,因为实际指向不同,不是同一个
但是new String(“s”)和new String(“s”)
这两个不能存储在一个HashSet对象中
具体的看源码分析
数组链表模拟
HashMap的底层是
数组+链表+红黑树
所以我们先了解下数组链表
package com.hansp.Collection;
public class Demo02 {
public static void main(String[] args) {
Node[] nodes = new Node[18];
Node jack = new Node("jack", null);
Node mike = new Node("Mike", null);
jack.next=mike;//把mike挂载到jack上了
nodes[3]=jack;
System.out.println("结束");
}
}
class Node{
String item;
Node next;
public Node(String item, Node next) {
this.item = item;
this.next = next;
}
}

对应的table[3],看起来之存储了一个Node对象但是Node.next还有一个Node对象
形成了一个链表
对此每个索引其实都能对应一个链表这就叫数组链表
HashSet(HashMap)底层添加结构(结论)
add()添加机制
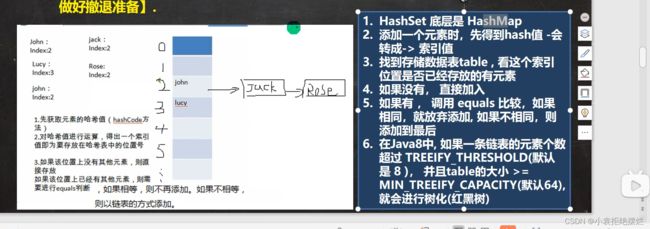
2.找到hash值通过对应算法找到对应数组索引,然后看该索引下有没有元素
如果没有元素直接加,有的话调用重写的equals(也是为什么new String(“s”))不能存储两个的原因,然后一个个对链表中的Node元素对比,有相同的就不添加了,如果没有就放到链表的最后
源码分析

分为第一次add
第二次add
和第一次重复add
第一次add分析
1.new HashSet对象
public HashSet() {
map = new HashMap<>();
}//HashSet的构造器,可以看出底层是HashMap
2.执行add方法
final static PRESENT=new Object();//就一个占位用的,一个属性
public boolean add(E e) {
return map.put(e, PRESENT)==null;
//添加完返回一个null,然后add方法返回了true代表添加成功
}//HashSet的add方法
3.add内部的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//返回空,转2
}
4.put内部的hash和putVal方法
先看hash,得到算法后的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//当传入的对象是一个null添加到对应数组索引的0处,再查找有没有null,没有放到链表最后
//如果不是null返回是对象的哈希值和h算数右移16位的异或
具体可以看[h = key.hashCode()) ^ (h >>> 16) 详细解读以及为什么要将hashCode值右移16位并且与原来的hashCode值进行异或操作](http://t.csdn.cn/AjrEB)这篇文章
再看putVal巨难
在下面开一个专区哦
再看putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//辅助变量
if ((tab = table) == null || (n = tab.length) == 0)
//table是HashMap的一个属性,类型是一个Node数组,如果table属性=null或者里面没有东西
n = (tab = resize()).length;//执行resize方法
请转到5.resize()
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//上面两步操作,是根据传入对象(key)的hash值来确定放在table(Node数组)哪个索引下
//并且把这个位置的对象赋给辅助变量p,再进行判断如果p为null
//表示还没有存放过元素,就创建一个Node(key(传入对象),value(那个属性PRESENT))
//然后放在tab[i]位置
//
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//第一个添加从上面的if直接到这里
if (++size > threshold)//扩容的判断,如果数据大小超过哪个临界值就扩容
resize();
afterNodeInsertion(evict);
//对于HashMap,这个是一个空方法
//主要是由它的子类实现,然后做操作
return null;//返回null
转到3put方法
}
5.resize()
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;//前面的代码都简单
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//第一次添加值走这条语句
newCap = DEFAULT_INITIAL_CAPACITY;//DEFAULT_INITIAL_CAPACITY默认为16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
//DEFAULT_LOAD_FACTOR为临界因子,0.75,然后newThr应该为12
//当你用的容量到了临界因子,就会开始扩容(防止操作量大,没有缓冲)
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//关键语句
table = newTab;
//上面两条语句给table赋了16个Node空间
看到这里,我们可以返回putVal了(return返回的是newTab)
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
第二次add分析
主要看和第一次不同的
前面基本相同
putVal看
1.看putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//辅助变量
if ((tab = table) == null || (n = tab.length) == 0)//第一个add执行,第二个以及不符合了
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//执行本条语句看hash和n的值的异或来找对应索引
//如果对应索引没有元素,则直接把我们的元素加入,也就是下面那条语句
添加完成后,直接到了++modCount那条语句
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//直接到这里
if (++size > threshold)//不进入,够用
resize();
afterNodeInsertion(evict);
return null;
}
第一次相同()add分析包含putVal全局解析
这个也是哦,主要看不同的地方
1.看putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//辅助变量
if ((tab = table) == null || (n = tab.length) == 0)//第一个add执行,第三个以及不符合了
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//这里的话,因为原来就有一个java了
//所以i索引值肯定和前面那个java相同,相同的话已经有元素了,所以不符合
tab[i] = newNode(hash, key, value, null);
else {//执行本条语句
Node<K,V> e; K k;
if (p.hash == hash &&//如果当前索引位置对应链表的第一个元素和准备加入的元素的hash值一样
((k = p.key) == key || (key != null && key.equals(k))))
//并且满足下面条件之一
//(1)准备加入的key和p指向Node节点的key是同一个对象
//(2)不是同一个对象,但是内容相同(equals方法返回真,equals已重写)
注意:这个只是判断了索引链表的第一个元素和传入的元素
e = p;
else if (p instanceof TreeNode)
//如果上面的是假,判断p是不是一颗红黑树,如果是按照红黑树的方式比较
//调用putTreeVal进行添加,这里不做探究
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果对应的索引以及是一个链表了,执行
//这里是判断对应索引第一个元素后面的链表和传进来的有没有重复,进行循环比较
//如果没有就会直接挂到对应索引链表的最后
//有的话放弃添加
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//如果一直没有相同执行到了null
//就直接添加到null的位置,那个位置就是链表最末尾
//你单独添加的null和这个索引肯定不一样
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//添加过后直接判断链表的节点是否大于大于8个
//如果大于等于8,而且,对这个链表进行树化
//这里其实一个链表里最多存十个数据,第一次到9的时候会先扩容到32个(没到12)
//然后第9个数据存放进链表,然后存放第10个的时候扩容到64个
//第10个存放进去,11个数据运行这个语句由于条件都满足了
//所以进行树化,一个链表最多放十个元素
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;//有相同break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;//最后返回这个,没有返回null,代表失败
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashSet扩容机制
注意当我们在一个链表中加入Node元素
其实是算所有的
就是只要你add()元素
就会size++
尽管他没有占用
所有的比如Table[1]没有元素
但是Table[1]之外的元素,包含链表里的,只要打到了临界值就会扩容
!!!
不是说你所有的Table[0]到Table[12]每个都有元素才扩容
只要加进去的元素有12个就扩容,不管是假到链表上,还是第一个位置上
table的size值一旦达到11,马上就树化

对应树化
如果说一个链表太多元素大于8个了
不会马上进行树化,会先扩容,然后那个数据继续在那个链表存着
其实一个链表里最多存十个数据,第一次到9的时候会先扩容到32个
然后第9个数据存放进链表,然后存放第10个的时候扩容到64个
第10个存放进去,11个数据运行这个语句由于数化的条件都满足了
所以进行树化,一个链表最多放十个元素
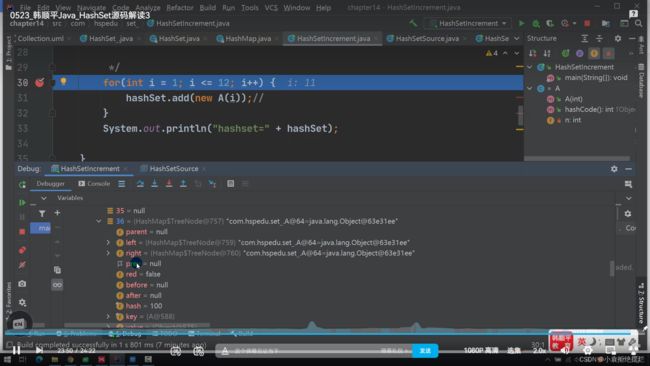
Hash的应用实例(怎么才算相同元素,equals重写)
例题
需要相同的hash值(保证在同一个索引下)和equals方法判断(保证不能加入)

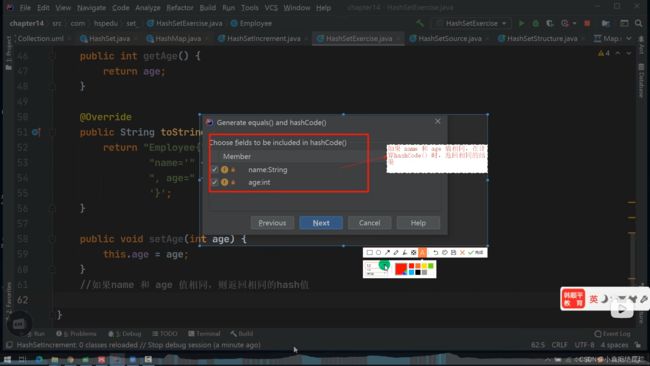
重写equals和hashCode

如果naem和age相同hashCode相同
到统一索引
再比较equals
相同的话放弃
不同挂到末位
LinkedHashSet
简介

可以认为是一个有序的HashSet
加入和取出的顺序一样
链表是按照添加元素一个个链表起来的
不是说只有一个索引下的的是一个链表
不同索引的两个元素也可以链接
所以取出的顺序和加入的顺序一样(不同于HashSet)
底层机制
放在不同索引上,不过还是双向链表,按添加顺序来指向
第二个添加的和第一个和第三个互相指向
源码分析





第一个new String问题
看了源码后
就知道只要hasCode和equals相同就会判断相同进行替换
恰好String重写了这两个方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
从源码看就知道为什么new 的也算相同了
因为返回的hasCode和equals都相同