Torch-张量
Tensor 的概念
张量的意思是一个多维数组,它是标量、向量、矩阵的高维扩展。标量可以称为 0 维张量,向量可以称为 1 维张量,矩阵可以称为 2 维张量,RGB 图像可以表示 3 维张量。你可以把张量看作多维数组。

参考链接
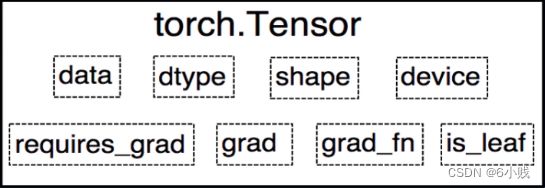
- data: 被包装的 Tensor
- grad_fn: 创建 Tensor 所使用的 Function,是自动求导的关键,因为根据所记录的函数才能计算出导数
- requires_grad: 指示是否需要梯度,并不是所有的张量都需要计算梯度
- is_leaf: 指示是否叶子节点(张量),叶子节点的概念在计算图中会用到
- dtype: 张量的数据类型
- shape: 张量的形状
- device: 张量所在设备 (CPU/GPU),GPU 是加速计算的关键
数据类型
参考链接
Torch 中定义的数据类型如下所示,CPU 和 GPU 上分别具有不同的数据类型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zqG7UVMv-

创建 Tensor
torch.tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False)
- data: 数据,可以是 list,numpy
- dtype: 数据类型,默认与 data 的一致
- device: 所在设备,cuda/cpu
- requires_grad: 是否需要梯度
- pin_memory: 是否存于锁页内存,只是针对 CPU 内存
示例:
torch.tensor([0,1])
torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
# 创建 GPU 上的 Tensor
torch.tensor([[0.11111, 0.222222, 0.3333333]],dtype=torch.float64,device=torch.device('cuda:0'))
# 创建标量 Tensor
torch.tensor(3.14159)
# 创建一个空的 Tensor
torch.tensor([])
# 创建一个全 1 Tensor
torch.ones((2,3,3))
# 创建一个全 0 Tensor
torch.zeros((2,3,3))
# 创建连续数字构成的 tensor
X = torch.arange(12,dtype=torch.float32).reshape((3,4))
# _like 根据指定的形状创建
Y = torch.zeros_like(X)
Y2 = torch.ones_like(X)
# full 填充
Z = torch.full((4,2),1.0)
Z2 = torch.full_like(X,12.2)
# 创建单位对角矩阵,默认为方阵
torch.eye(4)
# 指定 起始-终止-步长
t = torch.arange(2, 10, 2) # tensor([2, 4, 6, 8])
# 指定 起始-终止-元素个数
t2 = torch.linspace(2,10,6) # tensor([ 2.0000, 3.6000, 5.2000, 6.8000, 8.4000, 10.0000])
# 创建对数均分的 1 维张量
# 指定 起始-终止-元素个数-底数(默认10)
t3 = torch.logspace(1,20,6) # tensor([1.0000e+01, 6.3096e+04, 3.9811e+08, 2.5119e+12, 1.5849e+16, 1.0000e+20])
根据概率创建 Tensor
生成正态分布 (高斯分布)
torch.normal(mean, std, *, generator=None, out=None)
- mean 为标量,std 为标量。这时需要设置 size
- mean 为标量,std 为张量
- mean 为张量,std 为标量
- mean 为张量,std 为张量
t1 = torch.normal(0.,1.,size=(4,)) # tensor([ 1.5481, -2.6444, -0.1168, -0.0224])
mean = torch.arange(1, 5, dtype=torch.float)
std = 1
t2 = torch.normal(mean, std) # tensor([0.3120, 3.8869, 2.8768, 5.1489])
mean = torch.arange(1, 5, dtype=torch.float)
std = torch.arange(1, 5, dtype=torch.float)
t3 = torch.normal(mean, std) # tensor([-0.8261, 0.9518, 0.7300, 5.5800])
生成标准正态分布
在区间 [0, 1) 上生成均匀分布:
t1 = torch.rand((3,4))
t2 = torch.rand_like(t1)
在区间 [low, high) 上生成整数均匀分布
t1 = torch.randint(0,10,(3,3))
t2 = torch.randint_like(t1,20,100)
生成从 0 到 n-1 的随机排列
常用于生成索引。
t = torch.randperm(10)
指定概率,生成伯努利分布 (0-1 分布,两点分布)
a = torch.empty(3,3).uniform_(0,1)
t = torch.bernoulli(a)
其他操作
# 创建连续数字构成的 tensor
x = torch.arange(12)
# 查看 Tensor 每个轴上的形状
x.shape
# 查看 Tensor 的元素个数
x.numel()
# 改变 Tensor 的形状
y = x.reshape(3,4)
# cat 操作
X = torch.arange(12,dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[4.1,2.5,1.0,2],[9.0,1,2.3,5.0],[6.1,2,3.4,6.8]])
torch.cat((X,Y),dim=0),torch.cat((X,Y),dim=1)
# 利用 == 构建 bool Tensor
X == Y
运算
x = torch.tensor([1.0,2.,4,8.0])
y = torch.tensor([2.0,3.0,4.0,5.0])
x + y, x - y, x * y, x / y, x ** y # 加减乘除幂
# 按元素求自然对数的指数
torch.exp(x)
# 对 tensor 的所有元素求和
x.sum()
广播机制
即使形状不同,我们仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:
- 首先,通过适当复制元素来扩展一个或两个数组, 以便在转换之后,两个张量具有相同的形状
- 其次,对生成的数组执行按元素操作
a = torch.arange(3).reshape((3,1))
b = torch.arange(2).reshape((1,2))
a + b
索引和切片
Tensor 中的元素可以通过索引访问。 与任何 python 数组一样:第一个元素的索引是 0,最后一个元素索引是 -1; 可以指定范围以包含第一个元素和最后一个之前的元素。
X = torch.arange(12,dtype=torch.float32).reshape(3,4)
X[-1],X[1:2]
# 指定索引修改数据
X[1, 2] = 900
X[1:2,:] = 100
节省内存
运行一些操作可能会导致为新结果分配内存。 例如,如果我们用Y = X + Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
X = torch.tensor([1.2])
Y = torch.tensor([6.5])
before = id(Y)
Y = X + Y
id(Y) == before # False
我们可以使用切片表示法将操作的结果分配给先前分配的数组:
Z = torch.zeros_like(Y)
print(("id(Z):",id(Z))) # print(("id(Z):",id(Z)))
Z[:] = X + Y
print(("id(Z):",id(Z))) # print(("id(Z):",id(Z)))
如果在后续计算中没有重复使用X, 我们也可以使用 X[:] = X + Y 或 X += Y 来减少操作的内存开销:
before = id(X)
X += Y
id(X) == before # True
转换为其他 python 对象
torch tensor 和 numpy 数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量:
X = torch.tensor([1.2])
A = X.numpy()
B = torch.tensor(A)
print(type(A)) #
print(type(B)) #
A[0] = 190
X,A,B # (tensor([190.]), array([190.], dtype=float32), tensor([1.2000]))
要将大小为 1 的张量转换为 python 标量,我们可以调用 item 函数或 python 的内置函数:
a = torch.tensor([3.5])
a, a.item(), float(a), int(a) # (tensor([3.5000]), 3.5, 3.5, 3)