AMD HIP并行编程语言及其矢量相加实例——一文带你快速入门
✍️写在前面:随着计算的应用场景变得日益复杂多样,为了跟上人工智能算法对算力的需求,GPU硬件架构快速走向多样化,GPU生产厂家众多,且在商业和市场等因素的影响下,GPU通用计算编程模型也日益多元化。因此,并行编程语言的种类也变得繁杂,AMD作为一家在CPU和GPU领域都有较大影响力的企业,自然有属于自己成熟的计算生态,而HIP就是一个像CUDA一样的并行编程语言,但是目前网上关于HIP的资料并不是很多,所以我决定写一篇关于HIP并行编程基础的文章,希望这篇文章可以带大家快速入门。
这里先沾上目录:
目录
概述&背景
HIP编程模型
HIP编程结构
内存和线程管理
核函数的启动和编写
基于HIP的并行程序设计步骤
HIP程序示例-基于HIP的并行矢量相加
HIP时间计时API
概述&背景
AMD 的 GPU 早期主要使用 OpenCL 来开发,后来为了提高开发效率,借鉴了很多 CUDA 的设计理念,推出了支持HIP( Heterogeneous-Computing Interface for Portability )和 OpenCL 编程的 ROCm 框架。ROCm在设计风格上类似于CUDA,提供了非常丰富的开发工具,包括 HCC编译器,性能分析工具rocProf,数学库如rocBLAS、rocFFT、rocSOLVER、rocSPARSE、rocRand、深度学习库MIopen等。
HIP 是一个C++运行时API和内核语言,使用HIP编程模型编写的异构程序可以同时在类GPU加速卡平台和 NVIDIA GPU上运行。AMD HIP API接口与CUDA API相似。如图1所示。当涉及在 NVIDIA GPU 编译时HIP充当了CUDA之上的一个精简代理层,且其 Runtime API 兼容 CUDA runtime API。 ROCm 还提供了将CUDA应用程序通过使用HIPIFY工具自动转换为HIP内核语言及运行API的功能,当然,这种转码一般还需要手动进一步调整和优化代码。
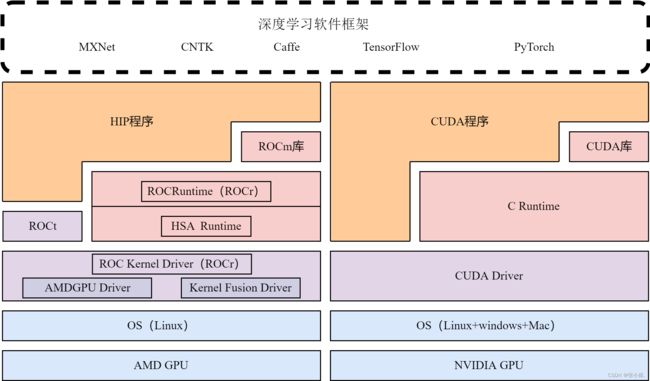
图1 HIP栈和CUDA栈的比较
其中,HIP具有以下特点:
1. 是开源的
2. 为应用程序提供 API,以利用AMD和CUDA设备的GPU加速。
3. 在语法上类似于CUDA。大多数CUDA API调用都可以就地转换:cuda -> hip
4. 支持强大的 CUDA 运行时功能子集。
HIP编程模型
HIP是一种基于AMD ROCm生态的并行计算平台和编程语言。你可以像编写C或C++语言程序一样实现算法和程序的并行性。同时,你也可以在类GPU加速平台和NVIDIA GPU上运行,本文将通过向量加法这个简单的例子来展示如何编写一个HIP程序,让你快速上手。
HIP编程结构
通常在主机(CPU)端以串行代码为主,主要控制程序的逻辑。在设备(GPU)端通常以并行代码为主,主要实现代码的快速并行计算,而在设备(GPU)端设计和开发的代码被称之为内核代码,它是运行在设备端(GPU)上的。
一个典型的HIP程序实现流程应该遵循以下模式:
- 把数据从CPU内存拷贝到GPU显存;
- 调用和核函数对储存在GPU显存中的数据进行操作;
- 将数据从GPU显存传送回CPU内存;
如图2所示。串行代码通常在主机CPU上执行,而并行代码在设备GPU上执行。用户可以将所有的代码统一的放在一个源文件中,然后通过HIP的编译器HCC为主机端和设备端生成可执行的代码。
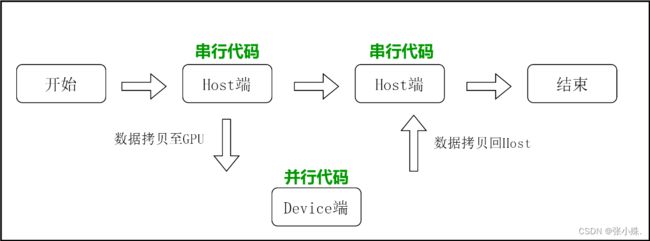
图2 HIP程序执行流程
HIP程序实现流程首先要把数据从CPU内存拷贝到GPU显存,数据在GPU操作结束后,又要将数据从GPU显存传送回CPU内存。因此首先要了解的就是内存和显存的管理,即如何将数据在主机和设备端进行传输和通信。以及内存和显存的分配方式。
内存和线程管理
HIP并行编程语言的内存分配和管理与标准C函数基本相同,只是前面需要加上hip前缀。下面具体的来看一下内存分配和释放API的一个实例,假设要为一个有N个浮点类型元素的数组分配内存,主机端和设备端的分配方式如下代码所示:
size_t size = N * sizeof(float);
float *h_A= NULL, *d_A = NULL;
float *h_A = (float *)malloc(size); //分配主机端内存h_A
hipMalloc((void **)&d_A, size); //分配设备端显存d_A
除了为主机端和设备端的数据分配内存和显存。在执行设备端代码的过程中,往往需要将主机端的数据传输到设备端预先分配好的显存之中。这一操作通过hipMemcpy进行实现,其定义如下所示:
hipError_t hipMemcpy(void *dist, const void* src,size_t count, hipMemcpyKind kind)其中此函数从src指向的源储存区复制一定数量的字节到dist指定的目标储存区,复制的方向由kind指定,其中数据传输和通信对应四种kind类型为:
| 数据通信方向 |
kind |
| 主机端到设备端 |
hipMemcpyHostToDevice |
| 设备端到主机端 |
hipMemcpyDeviceToHost |
| 主机端到主机端 |
hipMemcpyHostToHost |
| 设备端到设备端 |
hipMemcpyDeviceToDevice |
将数据从主机端传到设备端和从设备端传到主机端是不同的kind。因此在具体使用的过程中,注意不能混淆顺序。数据从主机端传到设备端和从设备端传到主机端的具体代码示例如下所示:
hipMemcpy(d_A,h_A,size,hipMemcpyHostToDevice)
hipMemcpy(h_A,d_A,size,hipMemcpyDeviceToHost);上述代码的第一句将h_A中的数据从CPU端传输到设备端的显存d_A上,而第二句将将显存中d_A的数据从GPU端传输到设备端的h_A上,通过以上的数据传输API,便可以很容易的控制数据在主机端与设备端的通信和传输。
另外,在一个并行HIP程序中,有关内存的操作除了内存分配以及数据传输,程序的最后一定不能忘记释放在程序中申请的内存和显存空间,其中,主机端内存和设备端的显存释放如下代码所示:
hipFree(d_A);
free(h_A);当你设计的内核函数在设备端进行计算时,设备中会产生大量的线程,并且每个线程都会按照之前设计好的核函数语法进行计算和控制,HIP沿用了CUDA的线程层次结构设计。将线程的层次进行抽象以便开发者组织线程。具体的,主要是一个三层的线程层次结构。从大到小依次是线程块网络,线程块,线程。其结构如图3所示。
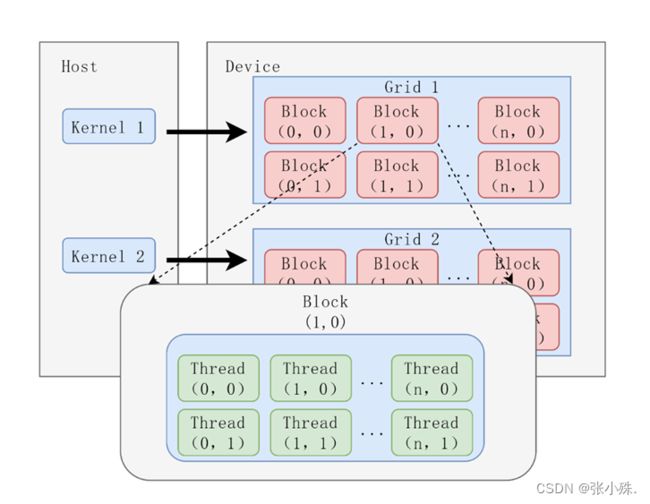
图3 HIP的线程组织结构
当启动内核函数在设备端进行计算时所产生的所有线程组成线程块网络。线程块网络中的所有线程共享相同的全局内存空间。线程块网络的维度大小由参数hipGirdDim定义。用于表示一个线程块网络中线程块的维度信息。它是一个dim3类型变量,dim3是基于uint定义的整数行向量,用来表示维度。当定义一个dim类型的变量时,所有未制定的元素都被初始化为1。Dim3类型变量中的每个组件可以通过它的x、y、z字段获得,如下所示:
- hipGirdDim.x, hipGirdDim.y, hipGirdDim.z
线程块网络是由线程块组成的。线程块的维度由hipBlockDim参数定义。用于表示一个线程块中线程的维度信息。它和girdDim一样是一个dim3类型变量,因此,对于hipBlockDim中的每个组件同样可以通过它的x、y、z字段获得,如下所示:
- bhpBlockDim.x, hipBlockDim.y, hipBlockDim.z
另外,并行程序的开发过程中通常需要确定线程块在线程网络中的位置信息,HIP为此提供了相应的API方法,它在线程块中的索引由参数hipBlockIdx决定。该坐标变量是基于uint3定义的内置的向量类型,它是一个包含三个无符号整数的结构,可以通过x、y、z三个字段来指定。即线程块在线程网络中的位置信息由以下三个变量所组合成的坐标确定:
- (hipBlockIdx.x, hipBlockIdx.y, hipBlockIdx.z)
而线程块是由多线程组成的。和参数hipBlockIdx类似,一个线程在线程块中的索引由参数hipThreadIdx决定。即线程在线程块中的位置信息由以下三个变量所组合成的坐标确定:
- (hipThreadIdx.x, hipThreadIdx.y, hipThreadIdx.z)
另外,在上述的示例中,都是以三维的网络和块进行说明。在实际并行程序开发过程中,可以根据实际情况组织二维的网络和块或一维的网络和块。
同时,在具体的并行程序开发过程中。通常需要事先指定需要开辟的线程网络的维度和大小以及线程块的维度和大小信息。可以通过以下的方式进行定义。
- dim3 blockDim(10);
- dim3 gridDim(10);
上述示例代码定义了一个一维的网络和块,共有10个Block,每个Block有10个Thread,同样的二维和三维可以通过增加()中的数据维度进行定义,例如dim3 block(10,10)表示每个Block有100个(10× 10)Thread。
核函数的启动和编写
在传统的C语言编程中,假如你定义了一个函数Function_name(argument list)。那么之后在需要用到这个函数功能的时候,只需要调用即可。调用的形式如下代码所示。
Function_name(argument list)而对于HIP来说。它是基于C语言的延伸。因此它的调用语句和C函数相似,具体如下所示。
hipLaunchKernelGGL(argument list); 其中,参数列表包括核函数名、网络和块布局、共享内存的大小以及核函数所带的参数,在上述的调用语句代码的参数列表中。需要指定girdDim、blockDim这两个参数。第1个参数是网络的维度和大小,也就是需要启动的线程块的数量。第2个参数是线程块的维度和大小,也就是需要启动的每个块中的线程的个数。正如上面提到的在进行实际的并行应用程序开发时,需要事先指定这两个参数的维度和大小。这样可以方便开发者调用和管理线程。
同一个线程块中的线程往往可以相互协作,不同块之间的线程不能协作。对于一个给定的实际问题,可以使用不同的网络和块布局来组织线程。例如。需要实现256× 4096个元素的计算。每256个元素一个块,启动4096个块。图4表明了上述配置的线程分布。以及线程组织结构中各个参数大小。
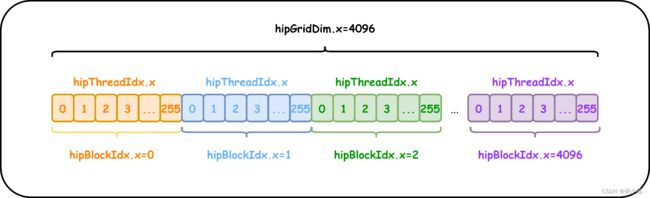 图4 线程配置和结构分布图
图4 线程配置和结构分布图
在设备端的全局内存中,因为数据是线性存储的。通常使用线程的全局索引来表示线程的全局位置,对于二维网络和块布局来说,此位置的数值可以由下式推出
- Index_x= hipBlockIdx.x* hipBlockDim.x+ hipThreadIdx.x
- Index_y= hipBlockIdx.y* hipBlockDim.y+ hipThreadIdx.y
得到上述线程的全局位置索引后,便可以使用这一索引信息来进行并行程序的算法控制。
核函数通常是在设备端运行的代码。因此在算法的设计过程中,通常将需要高度并行的相同计算操作设计成核函数。当核函数被调用时,不同的线程同步执行这一过程,从而达到提高计算效率的目的。核函数的定义通常需要用声明。同时核函数必须有一个void返回类型,如下所示:
- __global__ void KernelFunction_name (argument list)
下面来考虑一个简单的例子。假如要实现两个大小为numElements的向量相加。如果使用CPU进行串行程序设计。其代码如下所示:
void vectorAdd(float *h_A,float *h_B,float *h_C,int numElements)
{
for(int i = 0; i < numElements; i++)
h_C[i] = h_A[i] + h_B[i];
}
如果使用HIP进行并行程序设计。核函数如下所示:
__global__ void vectorAdd(float *d_A,float *d_B,float *d_C,int numElements)
{
int i = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x;
if(i观察上述两个函数的代码,可以发现在GPU上设计的核函数没有了循环体,向量的索引通过不同线程的全局索引来进行确定,另外,如向量相加GPU核代码第4行所示,当所开辟出来的线程数大于所要计算的数组元素时,需要用if语句来进行判断。否则会导致数组越界的错误。
基于HIP的并行程序设计步骤
经过上文对HIP编程模型的理解,总结一下,HIP并行程序设计主要可分为以下5个步骤:
(1)分配内存(host和device)
Host:malloc()
Device:hipMalloc ()
(2)从host将数据拷贝到device上
hipMemcpy(device_data,host_data,size_data,hipMemcpyHosttoDevice)
(3)调用Hip的核函数在device上完成指定的运算;
调用:hipLaunchKernelGGL(参数);
核函数:_global_void 核函数名(参数){函数体}
(4)将device上的运算结果拷贝到host上;
hipMemcpy(host_data,device_data, size_data,hipMemcpyDevicetoHost)
(5)释放分配的内存(device和host)
Host:free()
Device:hipFree()
HIP程序示例-基于HIP的并行矢量相加
根据前文中的内容,编写一个完整的矢量相加HIP并行代码,实现两个大小为numElements的向量相加的完整HIP并行代码。另外,由于HIP许多调用是异步进行的,所以有时可能很难确定某个错误是由哪一步的程序引起的。所以在代码开发的过程中,可以定义一个错误处理宏CHECK封装所有的HIP API调用。这可以简化错误检查的过程。编写完程序后,将程序文件命名为hip_vectorAdd.cpp,对这个代码文件进行编译和执行,具体的编译指令为hipcc hip_vectorAdd.cpp -o hip_vectorAdd。
代码如下所示:
#include
#include
#include
#include
__global__ void vectorAdd(float *d_A,float *d_B,float *d_C,int numElements)
{
int i = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x;
if(i 1e-8)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
//5.释放内存
hipFree(d_A);
hipFree(d_B);
hipFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
HIP时间计时API
最后,再提一下HIP中的异步记使API,帮助分析程序性能。在并行程序的开发中,往往需要对并行程序的运行时间进行测量从而验证和进一步开发性能,然而对于并行程序来说它是异步执行的,因此,单纯使用标准C语言的time计时往往不准确,HIP为此提供了专门的事件和计时API,HIP事件是hipEvent_t类型,通过hipEventCreate()和hipEventDestroy()进行事件的创建和销毁。事件创建后,就可以使用事件来记录并行程序的运行时间,具体有以下三个过程。
1. hipEventRecord()记录默认流事件。
2. hipEventSynchronize ()用来阻塞CPU执行直到指定的事件被记录。
3. hipEventElapsedTime()的第一个参数返回默认流事件start和默认流事件stop两个记录之间消逝的毫秒时间。
最后的最后,希望本文能为你带来帮助,如果你觉得有用,希望能三连支持,你的鼓励是我持续创作的动力!