【mysql】逗号分割字段的行列转换,分组字符串合并
1、逗号分割字段的行列转换
由于很多业务表因为历史原因或者性能原因,都使用了违反第一范式的设计模式,即同一个列中存储了多个属性值。这种模式下,应用常常需要将这个列依据分隔符进行分割,并得到列转行的结果:这里使用substring_index函数进行处理
建表语句:
DROP table if EXISTS tbl_name;
CREATE TABLE tbl_name(
id int(11) not null auto_increment,
userName varchar(100) not null,
PRIMARY KEY(id)
)
ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
insert into tbl_name values (1,'a,aa,aaa');
insert into tbl_name values (2,'b,bb');
insert into tbl_name values (3,'c,cc');如下图: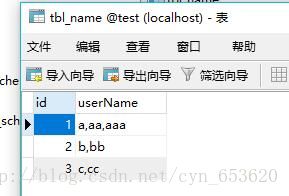
sql语句:
SELECT a.id,SUBSTRING_INDEX(SUBSTRING_INDEX(a.userName,',',b.help_topic_id+1),',',-1) as name
from tbl_name a left join mysql.help_topic b
on b.help_topic_id < (LENGTH(a.userName)-LENGTH(REPLACE(a.userName,',',''))+1)
ORDER BY a.id;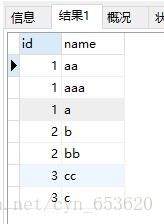
分析如下:
LENGTH(a.userName)-LENGTH(REPLACE(a.userName,',',''))+1根据id进行循环
{
判断:i 是否 <= n
{
获取最靠近第 i 个逗号之前的数据, 即 SUBSTRING_INDEX(SUBSTRING_INDEX(a.userName,',',b.help_topic_id+1),',',-1)
i = i +1
}
id = id +1
}
总结:
这种方法的缺点在于,我们需要一个拥有连续数列的独立表。并且连续数列的最大值一定要大于符合分割的值的个数。当然,mysql内部也有现成的连续数列表可用。如mysql.help_topic: help_topic_id 共有504个数值,一般能满足于大部分需求了。
作者:howtosay
出处:https://home.cnblogs.com/u/hongzm/
2 、分组字符串合并,组内排序
1.先生成排序后的表,再分组
SELECT tt.id,tt.newsID,tt.comment,tt.theTime FROM(
SELECT id,newsID,COMMENT,theTime FROM comments ORDER BY theTime DESC)
AS tt GROUP BY newsID 2.利用group_concat(comment order by theTime desc)的组内排序功能,不过要截取字符串