实用机器学习-学习笔记
文章目录
- 3.5多层感知机
-
- 3.5.1手动提取特征到学习特征
- 3.5.2线性方法到多层感知机
- 3.5.3代码实现
- 4.2过拟合和欠拟合
-
- 4.2.1模型选择
- 4.2.2总结
- 9.1模型调参
-
- 9.1.1思考与总结
- 9.1.2 基线baseline
- 9.1.3SGD ADAM
- 9.1.4 训练代价
- 9.1.5 AUTOML
- 9.1.6 要多次调参管理
- 9.1.7复现实验的困难
- 9.2超参数的优化
-
- 9.2.1 超参数的范围
- 9.2.2超参数优化的算法 黑盒和多置信度
- 9.3网络架构搜索Neural Arcitecture Search(NAS)
-
- 9.3.1.神经网络架构搜索:深度神经网络通过算法选取架构;
- 9.3.2.早期的NAS 强化学习
- 9.3.3.实用的办法One-shot:
- 9.34更简单实用的EfficientNet
- 9.35研究方向Research directions
- 9.3.6总结
- 10.1深度神经网络架构
-
- 10.1.1批量归一化 Batch Normalization
- 10.1.2层归一化(Layer Normalization)
- 10.1.3更多normalizations
- 11.1迁移学习
-
- 11.1.1迁移学习的概念
- 11.1.2相关领域
- 11.1.3视觉中应用
- 11.1.4预训练模型
- 11.1.5 微调(fine-tunning)
- 11.1.6限制搜索空间的其他方法——固定最底层
- 11.1.7微模型地址
- 11.1.8总结
3.5多层感知机
3.5.1手动提取特征到学习特征
使用神经网络来替代人工提取特征
神经网络来提取可能对后面的线性和softmax回归效果更好
好处在于不用费心思去想提取的特征是否能够满足结果
缺点在于计算量和数量比手工提取大很多
架构
多层感知机
卷积神经网络
循环神经网络
Transformer

3.5.2线性方法到多层感知机
Dense layer: 有科学系的参数w和b
线性回归可以看成是有1个输出的全连接层
softmax回归可以看成是有m个输出加上softmax操作子


3.5.3代码实现
链接: http://d2l.ai/chapter_multilayer-perceptrons/mlp-scratch.html

4.2过拟合和欠拟合

训练误差
所谓的训练误差
就是说你这个模型在我的训练数据上你能才看到的一些错误率
你的泛化误差就表示说我这个模型在新的没有见过的数据上会怎么样
 bug那里是样本过难了可能
bug那里是样本过难了可能
 就是说你的数据的复杂度和你的模型复杂度是应该要相互匹配
就是说你的数据的复杂度和你的模型复杂度是应该要相互匹配
如果你没有匹配的话 就会发生过拟合或者欠拟合的现象
 模型越简单,训练的误差越高
模型越简单,训练的误差越高
随着模型变得复杂,训练误差变低
但是泛化误差是先升高再降低
即使是最好的模型也会存在一点点过拟合,但是不能太严重

以决策树为例
x轴是树的深度
y是错误率
可以看到泛化误差会升高



当你的模型复杂度和你数据复杂度都在变化的时候会怎么办
你的x轴是你的数据的复杂度啊
Y则是我们关心的泛化的误差
就说蓝色的线表示的是简单模型
是你的线性模型
然后给定一个模型
我增加我的数据的复杂度 我会慢慢的从
Overfitting慢慢的变成一个Underfitting
就是过拟合慢慢的变成欠拟合
但是我的数据在一直增加的情况下
你通常会发现你的泛化误差是在下降的
对吧 就说你给一个模型 我增加我的数据给他的话
通常不会让你的模型变差
只说在某个地方 你会发现我增加数据的时候已经不会有
更多的泛化误差的改善
是因为在这个地方的时候
我已经达到了这个模型的上限
你再加各种数据 我的模型已经无法能够啊
去从里面抽取比较有用的信息了
比如说一个神经网络或深度神经网络
那么对他来说你会看到是说
当你数据相对来说还是比较少的时候啊
他的误差会高一些 比简单网络
是因为他在这个地方更容易过拟合
一旦他过拟合的话 他的泛化误差会变差
但是随着你的数据的复杂度的增加 你会 它也会下降 然后
在某一个点的时候 你会发现 只要数据达到某个量级的时候
你会发现复杂的网络开始超过你简单网络
而且你的下限会比较低一点
就说你复杂网络对你数据它的饱和度啊就可以
允许你给我更多的数据 然后在里面发掘更多的信息
从而得到更好的一个泛化的误差
这个也是说为什么深度神经网络很多时候比一些简单的网络
在比较大的数据上比较好一点
这个时候 你需要换一个相对来说比较复杂的模型
你一开始的时候 你对自己的情况 如果你一开始 你的样本数比较小
你一开始 你可能没有太多样本的情况下 那么很有可能
你应该去考虑先考虑比较简单的网络
更容易简单往这里啊 更容易调参而且可能效果更好
但是随着你的数据的不断增加
你的模型一旦部署了 你有新的样本进来
然后不断的标注 不断的做数据清理
你慢慢的 你在产品所能训练的模型会变得越
数据会变得越来越大的时候
你可能在某个点你发现你的模型已经
跟不上你数据的进步了
就你加很多数据 发现模型没有变化的时候
这时候你可以考虑说 啊 也许这个时候已经在这个地方了
这时候是时候开始从一个简单的模型
升级到一个相对来说比较复杂的模型了
就是说 数据的复杂度和模型的复杂度是一个要相互匹配的过程
深度神经网络在大的数据集上比较好
数据比较少的话应该先考虑简单网络
4.2.1模型选择

要选择一个合适复杂度的模型来降低你的泛化误差
4.2.2总结

就是说 数据的复杂度和模型的复杂度是一个要相互匹配的过程
深度神经网络在大的数据集上比较好
数据比较少的话应该先考虑简单网络
过拟合欠拟合直观展示

9.1模型调参
9.1.1思考与总结
1了解了baseline和调参基本原则
2了解了adams和sgd的优劣
3了解了训练树和神经网络的基本代价
4了解了autoML
5要多次调参管理
6复现试验的困难
9.1.2 基线baseline
选取一个好的超参数得到一个好的结果是比较花时间的过程
一般会从一个好的基线开始。一般工具包中都会存在极限
-
基线是什么?
-
选一个质量比较高的工具包,其中设了不错的参数,虽然可能对我们的问题不算是最好的,但是是一个不错的开始点;
-
如果要做的东西是跟某些论文相关,可以看看该论文里面的超参数是什么(有些超参数跟特定的数据集有关),这些超参数在一般的情况下都不错
-
有了比较好的起始点之后,调整超参数后再重新训练模型,再去看看验证集上的结果(精度、损失)
-
一次调一个值,多个值同时调可能会不知道谁在起贡献
-
看看模型对超参数的敏感度是什么样子【没调好一个超参数模型可能会比较差,但是调好了也只是到了还不错的范围】
9.1.3SGD ADAM
想对超参数没那么敏感的话,可以使用比较好的模型【在优化算法中使用Adam(对有些超参数没那么敏感,调参会简单很多)而不是SGD(在比较小的区域比较好)
9.1.4 训练代价

-
在小任务上很多时候已经可以用机器来做了(到最后可能都是用机器来调参【人的成本在增加】)
-
训练树模型在CPU上花10min 大概花$0.4
-
训练神经网络在GPU花1h左右 大概花$5
-
跟人比(人大概花十天左右),算法训练1000次调参数,很有可能会打败人类(90%)

9.1.5 AUTOML
-
AutoML在模型选择这一块做的比较好
-
超参数的优化(HPO)【比较通用】:通过搜索的方法,找到一个集合去调整模型的超参数
-
NAS(Neural architecture search)【专注于神经网络】:可以构造一个比较好的神经网络模型,使得能够拟合我们的任务
-
每个年代都有最大的技术痛点,当前AutoML可能是技术瓶颈。
9.1.6 要多次调参管理
-
每次调参一定要做好笔记【任何调过的东西,最好将这些实验管理好】(训练日志、超参数记录下来,这样可以与之前的实验做比较,也好做分享,与自己重复自己的实验)
-
最简单的做法是将log记录到txt上,把超参数和关键性指标(训练误差)放在excel中【适合实验没有那么多的参数】
-
Tensorboard,tensorflow开发的一个可视化工具
-
weight&kbias:允许在训练的时候用他们的API,然后把实验记录下来后上传到他们的网页上,就可以进行比较
9.1.7复现实验的困难
-
重复一个实验是非常难的
-
开发的环境:用的硬件是什么、新旧GPU可能会有点不一样;用的库的版本(Python本身也要去注意)
-
代码开发要做好版本控制(可以将每个版本的代码放在同一个地方 需求的库也放在这里)
-
要注意随机性(改变了随机种子,模型抖动比较大的话,说明代码的稳定性不是很好)【要避免换了个随机种子后,结果浮动比较大。这样的话,尝试能不能将不稳定的地方修改一下,实在不行就将多个模型做ensemble】
9.2超参数的优化
9.2.1 超参数的范围

1.模型
2.学习率:学习率的区间是【1e-6~1e-1】,把它做loguniform操作,loguniform是指把这个值先做log,这个值就变成了-6到-1,在-6和-1之间均匀的随机取,取完了再做指数回去,
loguniform好处,可以在很大的区间里面选取一个随机数,要不然e-6~e-1这个区间太小了,e-6值太小了,采样采不到它取的值不好
3.小批量大小:小批量随机梯度下降那个小批量
一般取2的某个次方
4.momentum,一个参数,在0.85-0.95之间随机取
5.一个值,loguniform用这个取最后一行是目标检测时选哪个算法,超参数的搜索空间要适中,不能太大或太小
9.2.2超参数优化的算法 黑盒和多置信度

HPO算法
黑盒:适用任何算法
挑一组超参数,训练,每一次都完成训练,取结果,选好的
好处:使用任何算法
Multi-fidelity:只关心哪一个超参数比其他超参数好,做各个超参数的排序
fidelity:置信
1.对数据集采样
2.把模型变小,例如把rest256变成restnet18,训练的超参数放在256上
3.不用训练那么多遍训练,训练几遍就可以停止了
总结就是通过便宜的方法对超参数排序

这两类中具体的的算法

左面:这个是暴力穷举,保证能找到最好,但是开销太大

右面:随机搜索
随机搜索挺好用的,没有好的办法的时候就选这个
随机搜索:最多试验n次,有一个search-space,每一个在这里面随机选一个config
n是自己选的,到n了就停了

在结果已经没有太大的变化时停止

贝叶斯优化
AutoML常用这个
其他用的不多
从一个hp(超参数)它会学一个从一个超参数到训练出的模型的精度的评估
的函数
咋学:得到n个数据点,然后拟合出函数曲线
在选下一个超参数时,根据之前的情况去评估
x:超参数的空间
y:目标函数
实现:真实值
虚线 :预测值的均值
蓝色的区域:置信度,就是对这个结果的自信息

这个中间的黄色的就是模型拟合的不那么好的地方,这个地方就需要再采样以个点
一般不需要采样许多点

怎么获取下一个要采样的点:
获取函数:另外一个模型,下一个点要采样谁
获取函数:对每个超参数预测一个值,值越大,就越不置信
下一个就是获取函数值最大的点
然后不停的采样
下面的绿色的那个就是获取函数的值
一开始的时候和随机采样差不多,后期比随机搜索好
和随机的比较:前期没有随机好,因为前期随机是没有超参数要调的,而且是并行的,BO是需要调整超参数,而且是顺序的,下一个采样点的选取依赖上一个点
大家用随机搜索多一点

思想:不用把所有的超参数都训练完,训练不好的就放弃,如图,n:超参数的组数,m:扫了多少遍
例如第一轮取16组超参数,扫25遍,然后把最好的一半留下,剩下的一般丢掉,下次再丢一半
缺点:n和m不好取,接下来的算法对他改进

n:探索的过程
m:每一个参数跑的时间有多久
m*n是每一个训练的轮次的训练时间
一开始选大的n,小的m,慢慢的把n变小,m变大

缺点:一开始淘汰掉的参数,有可能在后面表现是好的,解决方法:最后多留下几个剩下的超参数

总结:
黑盒:随机搜索(常用),贝叶斯
HPO:采样,不训练完,训练的不好的就淘汰掉
存在 top performers,不论在哪个数据集上的表现都是很好的。先去挑这种的试,也就是选取比较好的基线
9.3网络架构搜索Neural Arcitecture Search(NAS)
9.3.1.神经网络架构搜索:深度神经网络通过算法选取架构;
神经网络有许多类型的超参数:
架构:
resnet
mobilenet
层数
具体某一层:
核窗口大小kernel_size
输出通道channels
隐藏单元个数hidden_outputs
NAS可以自动化从零开始涉及生成整个网络,或者在某个空间里选取出一个好的网络,与超参数搜索HPO相似,关注【搜索空间】【搜索策略】【衡量标准】。
9.3.2.早期的NAS 强化学习
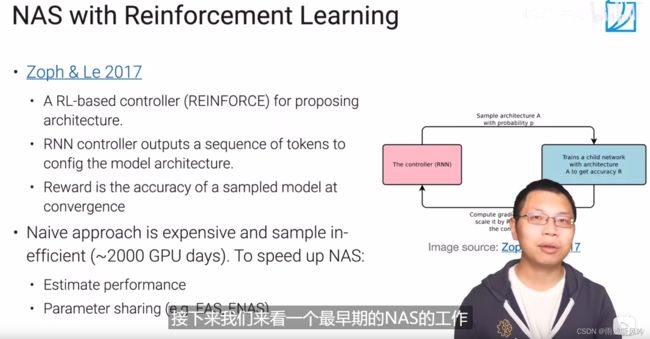
核心思想:
如果把整个神经网络的超参数表示成一段文本,可以用循环神经网络生成想要的结果,类似语言模型。生成模型以后通过训练得到accuracy结果反馈,调整参数再次训练(强化学习)。
优点:通用,任何框架都适用;
局限:贵,需要成千上万次的实验。
后续优化:
不需要训练整个完整的网络;
遇到相似的模型,参数可以复用,不随机训练;
9.3.3.实用的办法One-shot:

核心思想:
既学习网络架构也学习模型里的超参数;
训练一个非常大的模型,大模型包含了很多我考虑的模型架构,只要训练一遍,对于每个考虑的子模型,模型性能和参数都能拿到。只关心各个子模型的排行rank,而不关注在数据上的具体精度。选出好的架构(不一定是最好的)再重新训练一遍得到精度。
局限:模型巨大,可能放不进GPU内存,而且贵
实例模型1:可微架构搜索Differentiable Architecture Search

通过softmax进行子路线的选择:
第一层的C1、C2、C3的输出赋予权重加权求和,把求和结果复制三分放入第二层的C1、C2、C3 计算;每层的计算最优解赋予权重趋向于1,其他的权重趋向于0。
拓展:DARTS算法,3个GPU天能训练到不错的精度。
9.34更简单实用的EfficientNet
核心思想:
有三种办法调节卷积神经网络的复杂度:
a.层数
b.宽度:输出通道
c.输入大小
EfficientNet是同时调整三个因素,因为计算复杂度是层数宽度的平方输入分辨率的平方,所以一般调整大小为αβ²γ²≈2,使得计算复杂度增加一倍,只需要调整系数,便可控制计算复杂度;
局限:只对于一小部分的神经网络使用。
9.35研究方向Research directions

搜索结果的可解释性
寻找更适用于边缘设备(手机)上的神经网络
如何让机器学习的整个流程变得更加自动化
9.3.6总结

NAS是一个搜索神经网络的架构,可以有一个定制化的目标,比如精度或者是延迟时长的需求;
目前NAS用的比较多,如同时调整深度、宽度、输入分辨率的EfficientNet,以及特别大的架构通过softmax来选择路径的one-hot;
10.1深度神经网络架构

深度神经网络是一种编程语言,用于表达我们对数据、结构以及设计理念上的理解,不同的是网络里的很多值后续通过数据学习得到,学习是指整个语言是可导的,对于给定的损失函数,通过误差反转传递进行权重的更新;
有很多设计模式;
本节课主讲其中三种模式:批量和层的归一化、残差连接和注意力机制;
10.1.1批量归一化 Batch Normalization

将数据标准化:均值为0,方差为1,可以使得损失函数更加平滑,可以使用更大的学习率,使得线性模型的学习更加简单;
标准化但是不能用于整个神经网络,因为标准化只能直接作用于标准化的X,只能作用于线性函数;
批量归一化就是对第一层的输入或者中间某些层的输入做标准化,让训练更加容易更快;

批量归一化包括4步:
把不是2D的输入数据变成2D;
标准化Normalize:减去均值再除以方差;
还原Recovery:对标准化的数据还原,以满足对于偏差和方差的需求;
输出Output:将2D的输出变形为输入数据变形前的维度;
代码实现: http://d2l.ai/chapter_convolutional-modern/batch-norm.html
具体
批量归一化可以拆解为四步:
- 变形(Reshape):如果输入是2维的矩阵就不用改变,不是的话就要改成2维的【举个例子,假设输入是个卷积(一般是四维的,n(批量大小维)、c(RGB 通道或卷积的输出通道)、w(宽)、h(高)),我们会在这一步将其变化为2维的矩阵,由n * c * w * h变为nwh * c ,就是把通道维拉到最后,把nwh这三个维度合并在一起,可以这么理解 c 在CNN中表示的是一个识别出特征,而nwh则是样本的数据】
- 标准化(Normalization):具体来说是对每一列标准化,也就是对变形后的矩阵的一列 减去 这一列的均值 再除以这一列的方差,;
- 还原(Recover):用我们标准化后的矩阵y 对它的一列乘上 这一列对应的γ 加上这一列对应的β,在这个地方是说虽然我们对数据减了均值后再除了方差,但是我们还是有点想要数据有一点偏差,那么这个步骤就允许这个还原回去【如果γ为方差,β为均值,那么将会还原回去】,在这里γ与β是可以学习的, 神经网络会根据需求去找谁会更好一点;
- 最后就是将处理后的变形矩阵给变回去

10.1.2层归一化(Layer Normalization)

主要用在RNN里面
切片的方式不同,BN对特征归一化,LN对样本归一化
均值和方差属于样本的均值和方差

层归一化主要是用在循环神经网络(RNN)里面,因为将BN用于RNN中时,每一个时间步骤都得用自己得均值方差,甚至是学到得γ与β,在每一时间步中最好不要共享这些均值与方差(在不同的时间步中,这些数值变化还是很大的,而BN需要一个比较稳定的均值方差的估计,抖动比较大的均值与方差就失去了做标准化的意义)
层归一化到底是在做什么:在变形的步骤上对输入矩阵做转置(2维就普通转置,4维就把cwh放在一起再做转置),其他的步骤与BN相同;如果是RNN的输入矩阵(N * P * t)的话,就把P与t放在一起
其实这就是标准化每一个样本到当前的时间步骤,这样做的好处是说在做预测时不需要存均值方差这种全局的东西
在CNN上的效果一般,在RNN特别是在Transformer上效果非常好
10.1.3更多normalizations

Summary

11.1迁移学习
本节课ppt:https://c.d2l.ai/stanford-cs329p/_static/pdfs/cs329p_slides_14_1.pdf
11.1.1迁移学习的概念

能在一个任务上学习一个模型,然后用其来解决相关的别的任务,这样我们在一个地方花的时间,学习的一些知识,研究的一些看法可以在另外一个地方被使用到;
迁移学习是在深度学习出圈的,因为在深度学习中需要训练很多的深层神经网络,需要很多的数据,代价也很高;
迁移学习的途径:
- 做好一个模型将其做成一个特征提取的模块(Word2Vec【在文本上做训练一个单层神经网络,在训练好之后,每一个词对应一个特征,然后用这个特征去别的事情】,ResNet【对图片做特征,然后用这个特征来对作为另一个模型的输入,这样假设效果非常好,那么就可以代替人工去抽取特征】,I3D【用来对视频做特征】);
- 在一个相关的任务上训练一个模型,然后在另一个任务上直接用它;(之后的单元会讲到)
- 训练好一个模型,然后在一个新的任务上对其做微调,使模型能更好的适应新的任务;
11.1.2相关领域
- 半监督学习:利用没有标号的数据,让有标号的数据变得好
- 在极端的条件下,可以做zero-shot(一个任务有很多的类别但不会告诉你样本)或few-shot(一个任务就给你一些样本) learning。
- Multi-task learning(多任务学习):每一个任务都有它自己的数据,但是数据不是很够,可是任务之间相关,那么可以将所有的数据放在一起,然后同时训练多个任务出来,这样我们希望能从别的任务之中获益
11.1.3视觉中应用

- 在CV中存在了很多大规模标好的数据集(特别是分类问题,因为标号容易);
- 在CV的迁移学习,我们是希望存在 很多数据的一些应用上比较好的模型,能将它的知识拓展到我们自己的任务上去;
- 通常你自己任务的数据集会比大的数据集(ImageNet)要小很多(一开始不会花太多钱去标注很多的数据,正常是,标好了一些看看模型效果怎么样,然后好的话再继续投入进去,这样是一个迭代的过程),然后我们想要快速的迭代,看看能不能用比较大的数据集来将一些学到的东西迁移到我们自己的任务上面去;
11.1.4预训练模型

- 可以将神经网络分成两块,一块编码器(特征提取器,将原始图片的原始像素转化在一个语义空间中可以线性可分的一些特征(浅表示或语义特征表示)),一块解码器(简单的线性分类器,将编码器的表示映射成想要的标号,或者做一些决策);
- 预训练模型(Pre-train):在一个比较大的数据上训练好的一个模型,会具有一定的泛化能力(放到新模型上或新的数据集上,这个模型还是有效果的)【虽然是用于图片分类但是也可以试试目标检测】;
11.1.5 微调(fine-tunning)

- 将预训练好的模型用在新任务上叫fine-tuning(微调)【通常在深度学习里面,微调能带来最好的效果,但是也有一定的开销】
- 微调是怎么做的:
在新的任务上构建一个新的模型,新的模型的架构要更预训练的模型的架构是一样的; - 在找到合适的预训练模型之后要初始化我们的模型(将预训练模型的除了最后一层之外(特征提取器)的权重都复制给我们的模型,最后一层的解码器用的还是随机的权重【因为我们的标号和预训练模型的标号是不一样的】);
- 在初始化之后,就可以开始学习了,这步跟我们平常的学习没有什么不同的;
- 有一点点小做法是,限制fine-tune后的学习率。因为我们初始的结果已经比较好了,已经在想要解的附近了,限制学习率可以使得我们可以不会走太远【一般是用1e-3】;另外是说不要训练太长的时间;这些做法都是为了缩小搜索空间;
- 限制搜索空间的原因:

11.1.6限制搜索空间的其他方法——固定最底层

- 神经网络通常有一个层次化的,最底层一般是学习了底层的特征,上层的更与语义相关,所以一般来说底层与上面层没有太多的关系,在换了数据集之后泛化性都很好;
- 最后一层还是随机初始化学习,然后只对某一些层进行改动,最下面那些层在微调时就不去动了(可以说是学习率为0);
- 固定住多少层是要根据应用来看的,假设应用与预训练模型差别比较大的话,可以多训练一些层;
11.1.7微模型地址

首先要去找有没有我们想要的预训练模型,然后是看它是在什么样的数据集上训练好的;
可以去的途径(ModelHub、ModelZoom之类的):
Tensorflow Hub: https://tfhub.dev/;(允许用户去提交模型)
TIMM(把pytorch上能找到的各种代码实现弄过来): https://github.com/rwightman/pytorch-image-models;(ross 自己维护的一个包【文档不错,模型性能暂时一般般】)
TIMM使用代码介绍:
 ## 11.1.7fine-tuning的一些应用
## 11.1.7fine-tuning的一些应用

在大的数据集上训练好模型再微调到自己的应用上在CV领域上广泛的应用;
新的任务包含 目标检测、语义分割等(图片类似但是目标不一样);
在医疗领域等(同样的任务但是图片大相径庭);
现在的观点是微调加速了收敛(微调让初始的点不再试一个随机的点而是一个离最终的目标比较近的点,使得损失比较平滑),但是不一定可以提升精度(一般不会让精度变低,因为它只是改变初始值而已,跟随机初始化没区别,只要走的足够远也能摆脱初始值的影响);
11.1.8总结

- 通常我们会在大数据上训练预训练好的模型,这种任务通常是图片分类;
- 然后在关心的任务上把模型的权重初始化成预训练好的模型的权重,当然最后一层也就是解码器是要随机初始化的;
- 微调一般用一个小一点的学习率进行细微的调整,这样通常会加速收敛,有时可以提升精度但通常不会变差;(所以通常在CV中是经常被推荐的做法)