Go Map底层实现原理
文章目录
- 前言
- 1. map数据结构
-
- 1.2. bucket 数据结构
- 1.2 overflow溢出桶
- 1.3 hmap extra字段
- 2. Map扩容规则
-
- 2.1 负载因子
- 2.2 map的扩容规则1翻倍扩容
- 2.3 map的扩容规则2等量扩容
-
- 2.3.1 使用了多少溢出桶就算多(使用多少溢出桶会触发等量扩容)?
- 2.3.2 什么是等量扩容?
- 2.3.3 等量扩容有啥用?
- 3. 哈希冲突
-
- 3.1 解决哈希冲突的方法
- 3.2 常用的两种方法
-
- 3.2.1 线性探测法
- 3.2.2 拉链法
- 3.3 拉链法和线性探测法的优缺点:
前言
说到键值对的存储,我们通常会想到哈希表,而哈希表通常会有一堆桶(bucket)来存储键值对,Golang的map就是使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket,而每个bucket就保存了map中的一个或一组键值对。
1. map数据结构
map类型的变量本质上是一个指针,指向 *hmap 结构体
type hmap struct {
count int // 存储的键值对数目
flags uint8
B uint8 // 桶的数目 2^B
noverflow uint16 // 溢出桶的数量
hash0 uint32
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B(桶)
oldbuckets unsafe.Pointer // 扩容阶段用于记录旧桶用到的那些溢出桶的地址
nevacuate uintptr // 记录渐进式扩容阶段下一个要迁移的旧桶编号
extra *mapextra // 指向mapextra结构体里边记录的都是溢出桶相关的信息
}
1.2. bucket 数据结构
type bmap struct {
tophash [8]uint8 // 存储hash值的高8位
data byte[1] // key valu数据
overflow *bmap // 溢出桶bucket的地址
}
- tophash:是个长度为8的数组,哈希值低位相同的键存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配
- data:一个桶里边可以放8个键值对,但是为了让内存排列更加紧凑,8个key放一起,8个value放一起,在8个key前面是8个tophash,每个tophash都是对应哈希值的高8位
- overflow:是一个指向 *bmap 的一个指针,指向一个溢出桶。溢出桶的布局与常规的桶布局相同,是为了减少扩容次数引入的。当一个桶存满了,还有可用的溢出桶时,就会在桶后边链一个溢出桶继续往里面存
如下图所示:

1.2 overflow溢出桶
如果哈希表要分配的桶的数目大与 2 的 4 次方(下图为 25 ),就认为使用到溢出桶的几率较大,就会预分配 2(B-4) 个溢出桶备用,这些溢出桶与常规桶在内存中是连续的,只是前 2B 个用作常规桶。如下图:
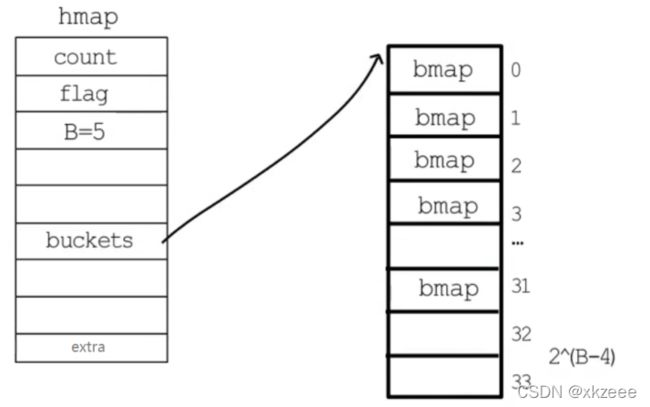
1.3 hmap extra字段
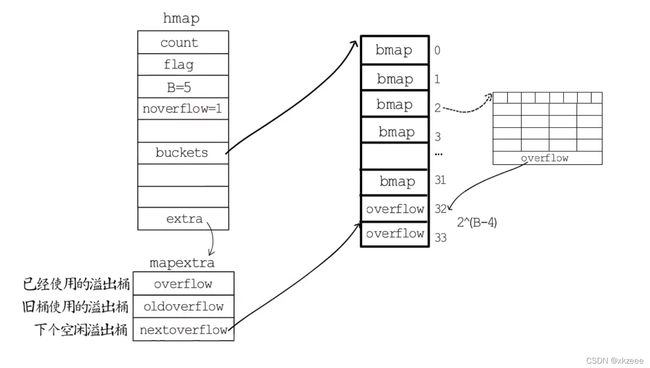
hmap 结构体最后有一个 extra,它是指向mapextra结构体,里边记录的都是溢出桶相关的信息,mapextra结构体如下:
type mapextra struct {
overflow *[]*bmap // 记录已使用的溢出桶的地址
oldoverflow *[]*bmap // 旧桶使用的溢出桶地址
nextOverflow *bmap // 指向下一个空闲溢出桶地址
}
假如编号为2的桶存满了,就会在后面链一个溢出桶指向下一个溢出桶overflow32(正在使用),nextOverflow 指向下一个空闲桶overflow33(未使用)。这时noverflow 会 +1,他是记录使用的溢出桶的数量
2. Map扩容规则
map中使用的扩容规则是渐进式扩容
如果把某个桶存满,接下来再存储新的键值对时,哈希表这时会创建溢出桶还是会发生扩容?这就要看map的扩容规则了,这里先来看一下负载因子
2.1 负载因子
负载因子 = count / bucket数量
哈希表需要将负载因子控制在合适大小,当它超过其阈值时需要进行键值对重新组织:
- 如果负载因子过小,说明空间利用率低
- 如果负载因子过大,说明哈希冲突严重,存取效率低
Go中哈希表的实现对负载因子是达到6.5时才会对键值对重新分配,而redis哈希表的实现大与1时就会对键值对重新分配,因为redis的每个bucket只能存1个键值对,而Go中的bucket可以存8个键值对
2.2 map的扩容规则1翻倍扩容
当负载因子超过6.5时就会触发翻倍扩容
公式:count/(2^b) > 6.5 ⟹ \Longrightarrow ⟹ 翻倍扩容 hmap.B++
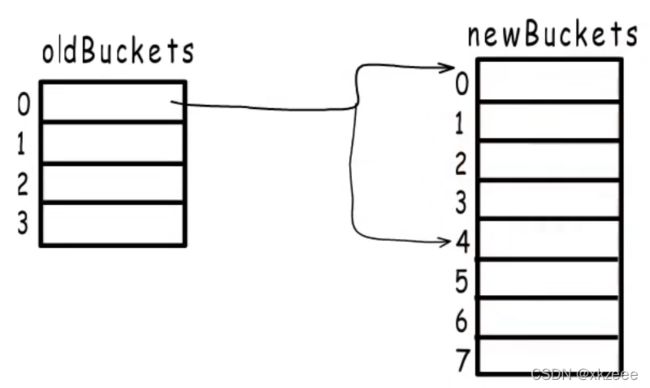
如下图所示,hmap.buckets 指向新分配的两个桶(上方的 0、1),这时 hmap.B++ 为1,hmap.oldbuckets 指向旧桶(下方的 0),hmap.nevacuate表示要迁移编号为0的旧桶(下方的 0)
旧桶中的每个键值对会采用逐步搬移策略,即每次访问map时都会触发一次搬移,每次搬移2个键值对,逐步分流到两个新桶中,直到旧桶中的键值对全部搬迁完毕后,删除oldbuckets

怎么判断选择旧桶迁移至新桶的位置?
先通过哈希函数把键处理以下,得到一个哈希值,利用这个哈希值从m个桶中选择一个,桶编号区间[0, m-1]
怎么确保运算结果落在桶编号区间[0, m-1]而不会出现空桶?
就要限制桶的个数 m 必须是 2 的整数次幂,这样 m 的二进制表示一定只有一位为 1,m-1 的二进制表示一定是低于这一位的所有位均为 1
m=4 00000100
m-1 00000011
如果桶的个数不是2的整数次幂,就有可能出现有些桶绝对不会被选中的情况
m=5 00000101
m-1 00000100
[1, 3] 注定是空桶
在回归正题,怎么判断选择旧桶迁移至新桶的位置?
如果旧桶数量为4,那么新桶的数量就为 8,如果一个哈希值选择 0 号桶,那么哈希值的二进制低两位一定为 0 ,所以选择新桶的结果只有两种,取决于哈希值的第三位是 0还是 1,结合下面例子和图为例进行说明:
例子: 使用与运算法hash & (m-1),把旧桶迁移到新桶上,用这个旧桶的hash值跟扩容后的桶的个数 m-1 的值相与(&),得几就在哪个位置上,以下为 0 和为 1 的情况和图片示例
如果第三位为0:选择编号为0的新桶
xxxxx000
&00000111 迁移到
————— ⟹ \Longrightarrow ⟹ ⟹ \Longrightarrow ⟹ ⟹ \Longrightarrow ⟹ newBuckets[0]
00000000
如果第三位为1:就选择编号为4的新桶,桶的数量一定是2的整数次幂
xxxxx100
&00000111 迁移到
————— ⟹ \Longrightarrow ⟹ ⟹ \Longrightarrow ⟹ ⟹ \Longrightarrow ⟹ newBuckets[4]
00000100
2.3 map的扩容规则2等量扩容
如果负载因子没有达到 6.5 ,但是使用的溢出桶比较多,也会出发扩容,这次的扩容是等量扩容
2.3.1 使用了多少溢出桶就算多(使用多少溢出桶会触发等量扩容)?
如果常规桶的数目小于等于215 , 使用的溢出桶大与2B就是多了
B <= 15,noverflow >= 2^B^
如果常规桶的数目大于215 , 使用的溢出桶大与2B就是多了
B > 15, noverflow >= 2^15
2.3.2 什么是等量扩容?
创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中
2.3.3 等量扩容有啥用?
在什么情况下负载因子会没有超过上限,却使用了很多溢出桶?
很多键值对被删除的情况下,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行翻倍扩容的情况
迁移来迁移去的等量扩容存在的意义:
同样数目的键值对,迁移到新桶中会把松散的键值对重新排列一次,使其排列的更加紧凑,进而保证更快的存取,这就是等量扩容的意义所在。
3. 哈希冲突
当有两个或两个以上的键被哈希存到了同一个bucket中时,就会发生哈希冲突。
3.1 解决哈希冲突的方法
有四种解决方法:
- 线性探测法(开放地址法)
- 拉链法
- 线性补偿探测法
- 随机探测法
3.2 常用的两种方法
3.2.1 线性探测法
按照顺序来,从冲突的下标处开始往后探测,到达数组末尾时,从数组开始处探测,直到找到一个空位置存储这个key,当数组都找不到的情况下回扩容;查找某一个key的时候,找到key对应的下标,比较key是否相等,如果相等直接取出来,否则按照顺寻探测直到碰到一个空位置,说明key不存在
3.2.2 拉链法
拉链就是链表,当key的hash冲突时,在冲突位置的元素上形成一个链表,通过指针互连,当查找时,发现key冲突,顺着链表一直往下找,直到链表的尾节点,找不到则返回空
3.3 拉链法和线性探测法的优缺点:
- 拉链法比线性探测处理简单
- 拉链存储了指针,所以空间上会比线性探测占用多一点
- 拉链是动态申请存储空间的,所以更适合链长不确定的
- 线性探测查找是会被拉链法会更消耗时间
- 线性探测会更加容易导致扩容,而拉链不会
好啦到这里就讲解完了,扩容的地方讲解的有点乱但都是按照顺序并举例子来的,以上如有不正确的地方,请大佬批评指出~~❄️