【C语言进阶】:探索自定义类型的神秘世界 - 结构体篇
【C语言进阶】:探索自定义类型的神秘世界 - 结构体篇
- 1.什么是结构体
- 2.结构体的声明
- 3.结构体的特殊的声明
- 4.结构体的自引用
- 5.结构体的内存对齐
-
- 5.1结构体的大小的计算
- 5.2结构体类型对齐的规则
- 5.3为什么要有结构体内存对齐
- 5.4在VS上修改默认对齐数
- 6.结构体类型创建变量的方法和初始化
-
- 6.1创建变量
-
- 6.1.1方法一:直接在分号里面创建全局的结构体变量
- 6.1.2方法二:在全局或者在函数体内创建结构体变量
- 方法三:利用typedef给结构体类型起别名,然后在全局或者函数体内创建结构体变量
- 6.2结构体初始化
-
- 6.3.1方法一:定义变量的同时初始化
- 方法二:定义变量和初始化分开
- 7.结构体传参
-
- 7.1方法一:传结构体对象
- 7.2传结构体的地址
- 7.3两种传参方式的效率比较

博客主页: 小镇敲码人
热门专栏:C语言进阶
欢迎关注:点赞 留言 收藏
任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。
❤️ 什么?你问我答案,少年你看,下一个十年又来了
1.什么是结构体
结构体是C语言里面的一种自定义类型,它是一组值的集合,这些值可以是不同的类型。
2.结构体的声明
我们通常可以这样来声明一个结构体
struct tag
{
member-list(这里面是结构体的成员变量)
}variable-list(变量列表);
例如如果你想用结构体来声明一个学生类型,你可以这样做:
struct Student
{
char name[20];//名字
char id[20];//学号
int age;//年龄
char sex[5];//性别
};
注意分号一定不能丢。
3.结构体的特殊的声明
请看下面一段代码:
struct
{
int a;
int b;
}x;
struct
{
int a;
int b;
}q,*ptr;
直接在结构体分号里面声明一个变量,如果前面有*就声明的是一个没有初始化的结构体指针。
上面那两个结构体的关键字struct后面没有对应的结构体类型名称,我们称这种特殊的结构体声明叫做匿名结构体,匿名结构体的应用不多但是我们还是要了解这个语法。
思考这样一个问题,上面那两个匿名结构体在编译器看来是同一个类型吗,我们可以将ptr = &x来看一下:
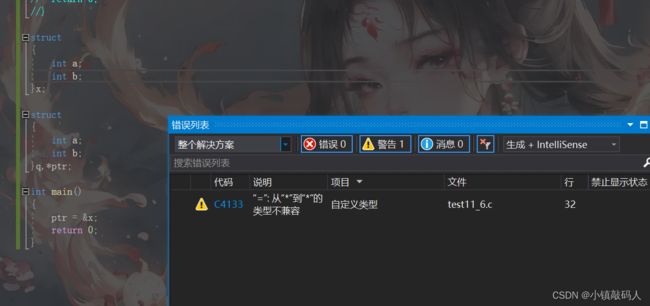
可以看到虽然编译器没有报错,但是报了类型不兼容的警告,说明编译器认为上面的两个匿名结构体是两种不同的类型。
注意:匿名结构体只能在分号里面定义该类型的结构体变量,其它地方由于结构体没有名字所以定义不了,tydepef是可以的,但是我们还是建议给结构体取一个易识别的名字。
此时我们给匿名结构体起个叫x的别名就可以在;外面定义这个匿名结构体类型了。
4.结构体的自引用
在结构体里面如果我们想要定义一个它自己的类型变量该怎么办呢?我们先看看下面这种方式是否可行:
struct tag
{
int a;
int b;
struct tag c;
};
int main()
{
printf("%d", sizeof(struct tag));
return 0;
}
这种方式显然是有问题的,如果我们想要计算这个结构体类型的大小,它里面有个同类型的结构体变量,我们本来就不知道这个结构体类型的大小,该如何计算呢?
我们可以看一下上面代码的运行结果:
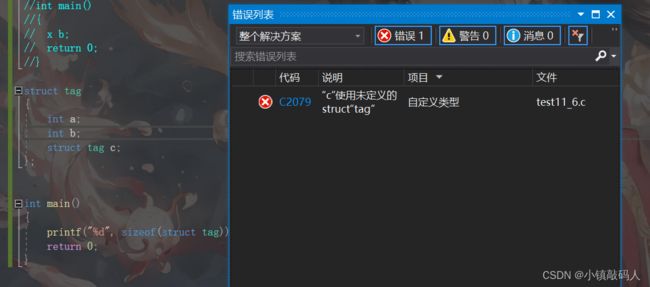
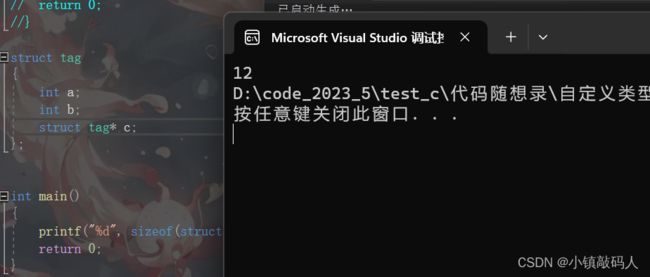
这里可以看到直接报错了,我们在进行结构体的自引用时,应该定义一个同类型的指针变量,因为指针变量的大小是确定的,这样计算结构体类型大小的时候就不会出错了,所以上面代码将结构体第三个变量变成指针变量就能成功运行了:
5.结构体的内存对齐
5.1结构体的大小的计算
我们在计算结构体的大小时,不是简单的将其里面的变量的大小相加,而是有一个内存对齐的规则在里面,如果你不信请看下面代码的运行结果:
#include按照我们之前的理解,上面代码的结果应该是结构中两个类型的大小之和,所以是 5 5 5,答案是否如此,我们拭目以待:

可以看到答案是 8 8 8,和我们预料中的不一样,这里就不得不提结构体的内存对齐了。
5.2结构体类型对齐的规则
1.规定第一个变量在偏移量为0的地址处。
2.其它的成员的偏移量要对齐到某个数字(对齐数)的整数倍地址处。
注:某个变量的对齐数是该变量自身大小和编译器默认对齐数的较小值
vs中默认对齐数是8。
Linux里面没有默认对齐数,某个变量的对齐数就是其自身的大小。
3.结构体整体的大小应该是最大对齐数(每个成员都有一个自己的对齐数)的整数倍。
4.如果结构体里面内嵌了其它类型的结构体,那么那个结构体类型的默认对齐数,就是它的最大对齐数,对齐到它自己最大对齐数的整数倍处。
下面我们来做几个题目巩固一下刚刚学的知识:
题目一:
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\n", sizeof(struct S1));
return 0;
}
运行结果:
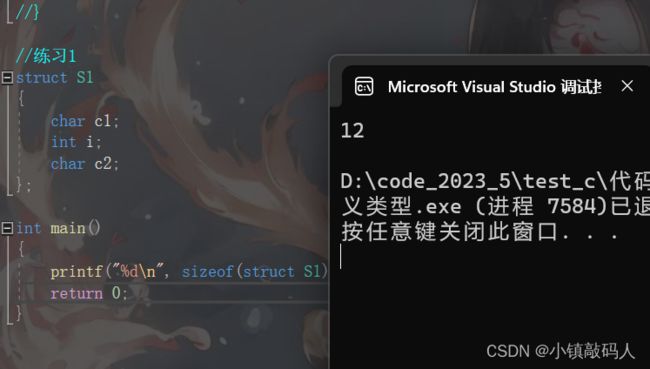
解析:我们第一个char类型的变量在偏移量为0的位置处,第二个变量int它的对齐数是4,所以应该对齐到偏移量为4的地方,就耗了8个字节的空间,此时下一个位置偏移量为8,是对齐到其对齐数 1 1 1的整数倍了的,所以最后结构体的大小就是9,但是结构体大小要是最大对齐数4的整数倍,最靠近4的整数倍的又大于9的就只有12了所以答案就是12,此后题目我们只画图,不做文字解析,画图是下面这样:
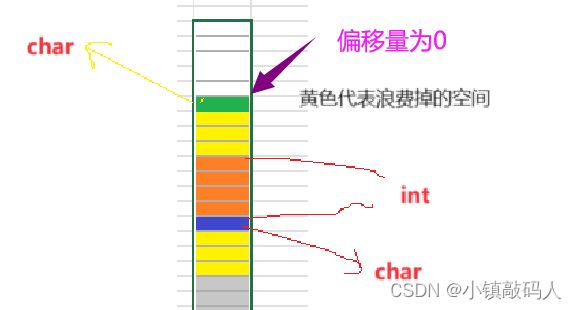
注意:我们讲对齐是一个变量的偏移量要对齐到对齐数的整数倍,并规定第一个变量的第一个字节在偏移量为0的位置,偏移量逐字节递增。而且必须先对齐,编译器才会给那个变量开空间。
第二题:
#include运行结果:
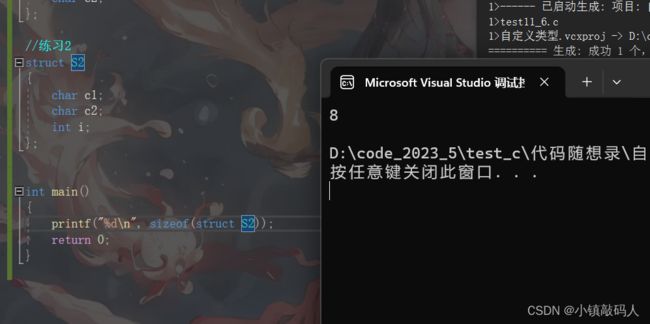
把图画出来是这样的:

第三题:
#include运行结果:
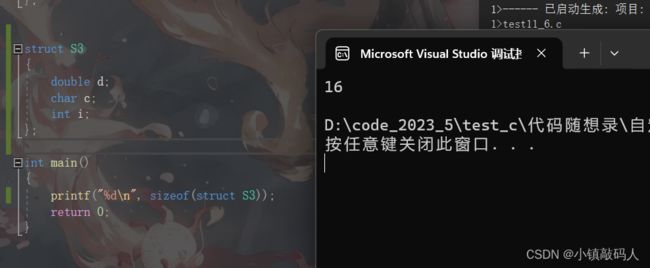
解析:

第四题:
#include运行结果:
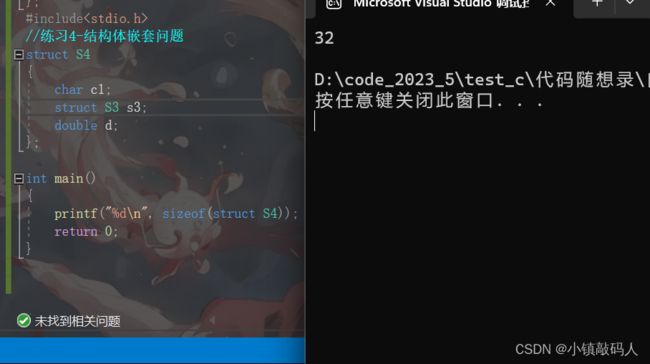
解析:
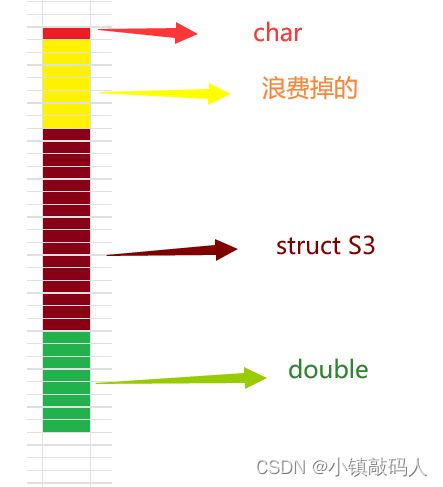
5.3为什么要有结构体内存对齐
讲完了结构体的内存对齐的规则和相应的习题之后我们是时候应该了解一下这样一个问题了,即:为什么要有结构体内存对齐呢?直接让把结构体的大小设计为每个变量的大小相加不行吗,干嘛要搞这么麻烦呢?
1.平台移植性好
GB/T 16260《软件工程 产品质量》中对软件可移植性的定义为:从一种环境转移到另一种环境的能力。子特性包括适应性、共存性、易替换性、易安装性。简单点说是因为有些硬件平台访问数据只支持特定地址处某些类型,否则会抛出异常,我们如果内存对齐了,当代码从这个平台转移到另外一个平台时就不会出现各种各样的不适应。
2.性能上更占有优势
我们程序员在写代码的时候创建一个个变量,它们有的大小是1个字节,有的是4个字节,但是cpu并不是这样一个变量一个变量的访问的,它们一般访问的是一块一块的内存,可能一次访问4个字节,或者一次访问8个字节,如果我们对齐cpu就只需要访问一次了,但是如果没对齐,一个数据就有可能在两个区域,就要取两次,时间上不占优。
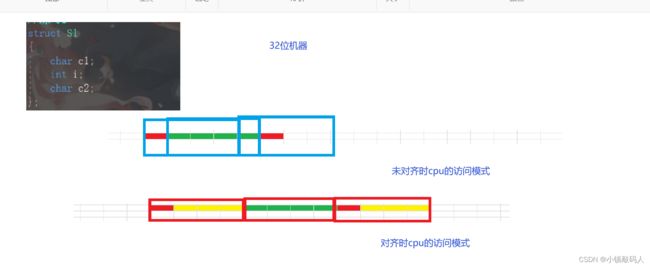
虽然同样的数据,cpu都进行三次访问,但是我们看访问效率,要看同一片空间cpu访问了多少次,很明显,未对齐时,cpu访问8字节,访问了三次,而对齐之后只需要访问两次。所以本质上结构体内存对齐是一种空间换时间的做法。
5.4在VS上修改默认对齐数
我们之前谈到过,在VS编译器上默认对齐数是8,而linux的gcc编译器则没有默认对齐数,那如果我们想要修改VS上的默认对齐数,有没有什么办法呢?答案是有的:
#pragama pack(8)//设置默认对齐数是8
那究竟可不可以修改呢?我们可以利用下面代码来看一下,如果我们将默认对齐数修改为1,那么每个类型的对齐数都是1了,那么结构体类型的大小应该就是它里面的变量的大小之和:
#include运行结果:
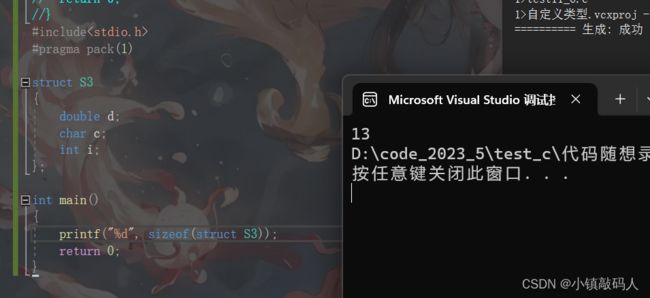
如果你认为这是巧合,那么我们也可以将默认对齐数改为2:
#include运行结果:
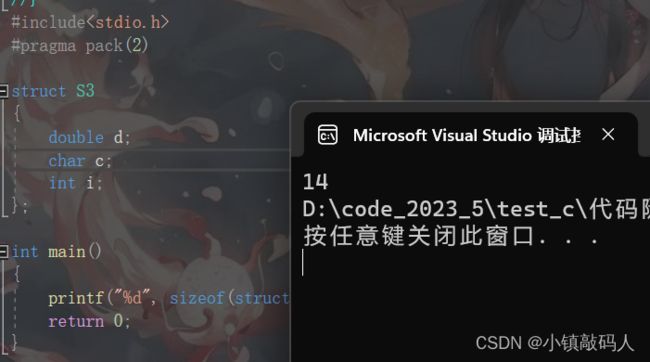
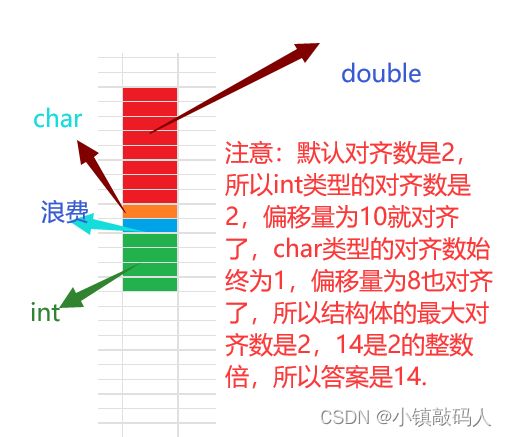
我们来画图验证一下:
6.结构体类型创建变量的方法和初始化
6.1创建变量
6.1.1方法一:直接在分号里面创建全局的结构体变量
struct tag
{
int a;
double b;
char c;
}S1,*S2;
S1是结构体变量,S2前面有*号是一个结构体指针变量。
6.1.2方法二:在全局或者在函数体内创建结构体变量
struct tag
{
int a;
double b;
char c;
};
struct tag S1;
struct tag* S2;
int main()
{
struct tag S3;
struct tag S4;
return 0;
}
方法三:利用typedef给结构体类型起别名,然后在全局或者函数体内创建结构体变量
typedef struct tag
{
int a;
double b;
char c;
}tag;
tag S1;
tag* S2;
int main()
{
tag S3;
tag S4;
return 0;
}
注意:这个别名tag不能在结构体自引用的时候使用,因为编译器编译是从上至下有顺序的,这个时候编译器还没有给struct tag起别名,我们可以来验证一下:
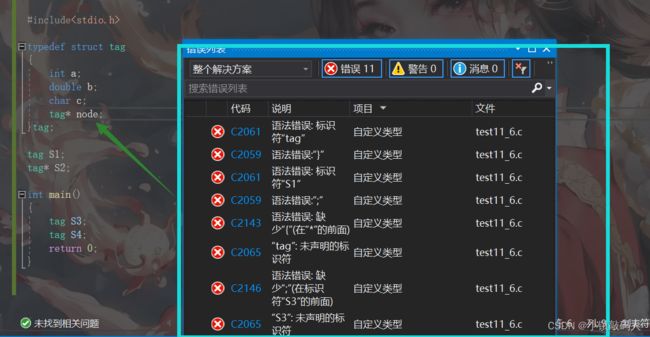
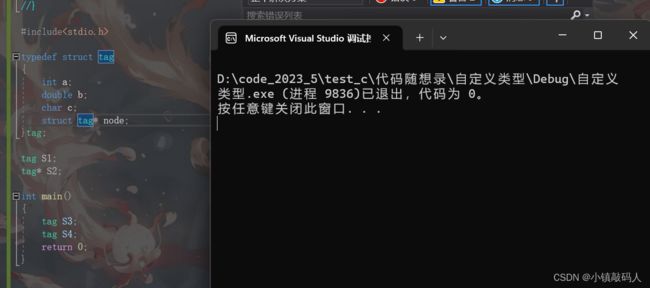
可以看到编译器抛出了很多错误,如果我们正常使用结构体类型名就不会出错:
6.2结构体初始化
6.3.1方法一:定义变量的同时初始化
1.普通结构体类型
struct tag
{
int a;
double b;
char c;
}S1 = {4,1.1,'e'};
struct tag S2 = {5,2.2,'b'};
- 嵌套结构体类型
struct tag
{
int a;
double b;
char c;
struct tag* d;
}S1 = {4,1.1,'e',NULL};
struct tag S2 = {5,2.2,'b',NULL};
方法二:定义变量和初始化分开
- 普通类型
struct tag
{
int a;
double b;
char c;
}S1;
struct tag S2;
int main()
{
S1.a = 1;
S1.b = 2.2;
S1.c = 'a';
S2.a = 4;
S2.b = 1.2;
S2.c = 'b';
return 0;
}
- 注意:如果你没有在直接定义变量的时候初始化,再初始化的化只能一个数据一个数据的初始化了,而且只能在函数体里面初始化,否则就会报错。 结构体嵌套定义和初始化分开就是多加一个赋值
NULL,这里不再阐述。
7.结构体传参
7.1方法一:传结构体对象
#include这里就相当于我们内置类型里的传值拷贝,编译器需要在栈上面开一个和这个结构体一样大的空间,然后把S1的值赋值给形参S,注意在Fun函数里面改变S的值并不会影响S1。
7.2传结构体的地址
#include这里S是一个指针变量,保存着结构体变量S1的地址,通过S改变其数据的值是会影响到S的,结构体指针访问数据可以先对其解引用在使用.操作符,也可以直接使用->操作符访问。
7.3两种传参方式的效率比较
#include运行结果:
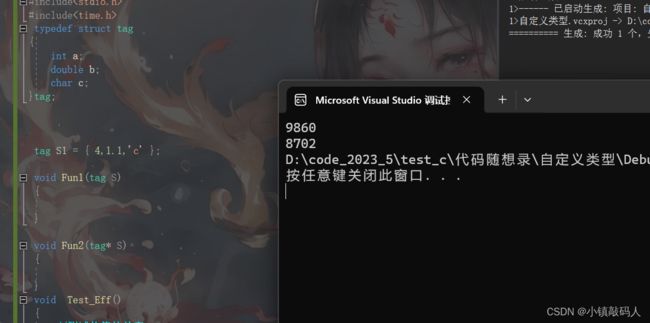
可以看到传址调用的效率还是更快,可能是因为结构体不是很复杂所以效果不明显,但是还是建议为了减少空间和时间上的开销使用结构体指针进行传参。