C# 并发编程
C# 并发编程
前言
对于现在很多编程语言来说,多线程已经得到了很好的支持,
以至于我们写多线程程序简单,但是一旦遇到并发产生的问题就会各种尝试。
因为不是明白为什么会产生并发问题,并发问题的根本原因是什么。
接下来就让我们来走近一点并发产生的那些问题。
猜猜是多少?
public class ThreadTest_V0
{
public int count = 0;
public void Add1()
{
int index = 0;
while (index++ < 1000000)//100万次
{
++count;
}
}
public void Add2()
{
int index = 0;
while (index++ < 1000000)//100万次
{
count++;
}
}
}
结果是多少?
static void V0()
{
ThreadTest_V0 testV0 = new ThreadTest_V0();
Thread th1 = new Thread(testV0.Add1);
Thread th2 = new Thread(testV0.Add2);
th1.Start();
th2.Start();
th1.Join();
th2.Join();
Console.WriteLine($"V0:count = {testV0.count}");
}
答案:100万 到 200万之间的随机数。
为什么?
接下来我们去深入了解一下为什么会这样?
一、可见性
首先我们来到 “可见性” 这个陌生的词汇身边。
通过一番交谈了解到:
对可见性进行一下总结就是我改的东西你能同时看到。
1.1 背景
解读一下呢,就像下面这样:
CPU 内存 硬盘 ,处理速度上存在很大的差距,为了弥补这种差距,也是为了利用CPU强大计算能力。
CPU 和内存之前加入了缓存,就是我们经常听说的 寄存器缓存、L1、2、3级缓存。
应该的处理流程是这样的:读取内存数据,缓存到CPU缓存中,CPU进行计算后,从CPU缓存中写回内存。
1.2 线程切换
还有一点 我们都知道多线程其实是通过切换时间片来达到 “同时” 处理问题的假象。
线程切换

1.3 单核时代
你也发现了,对于单核来说,程序其实还是串行开发的。

单核CPU
就像是 “一个人” ,东干点,西干点,如果切换频率上再快点速度,比我们的眨眼时间还短呢?那…… 接下来,我们进入了多核时代。
1.4多核时代
顾名思义,多个CPU,也就是每个CPU核心都有自己的缓存体系,但是内存只有一份。
比如CPU就是我么们的本地缓存,而内存相当于数据库。
我们每个人的本地缓存极有可能是不一样的,如果我们拿着这些缓存直接做一些业务计算,
结果可想而知,多核时代,多线程并发也会有这样的问题 — CPU缓存的数据不一样咋办?

多核CPU
1.5 volatile
这是CLR 为我们提出的解决方案,就是在遇到可见性引发的并发问题时,使用 volatile 关键字。
就是告诉 CPU,我不想用你的缓存,所有的请求都直接读写内存。
一句话,就是禁用缓存。
看上去这样就能解决并发问题了吧?也不全是,还有下面这种枪情况。
二、有序性
字面意义就是有顺序,那么是什么有顺序呢?-- 代码
代码其实并不是我们所写的那样一五一十地执行,以C# 为例:
代码 --> IL --> Jit --> cpu 指令
代码 通过编译器的优化生成了IL
CPU也会根据自己的优化重新排列指令顺序
至少两个点会有存在调整 代码顺序/指令顺序的可能。
2.1 猜猜 Debug和Release 运行结果各是多少
public class VolatileTest
{
public int falg = 0;
}
static void VolatileTest()
{
VolatileTest volatiler = new VolatileTest();
new Thread(
p =>
{
Thread.Sleep(1000);
volatiler.falg = 255;
}).Start();
while (true)
{
if (volatiler.falg == 255)
{
break;
}
};
Console.WriteLine("OK");
}
主线程一直自旋,直到子线程将值改变就退出,显示 “OK”
- Debug 版本,执行结果:
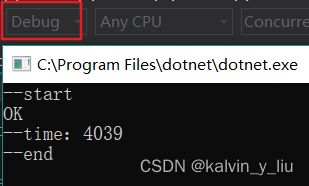
Debug
- Release 版本,执行结果:

Release
为什么会这样,因为我们的代码会经过编译器优化,CPU指令优化,
语句的顺序会发生改变,但是这样也是这种离奇bug产生的一种方式。
怎么避免它?
2.2 volatile
没错,依然是它,不仅仅是禁用cpu缓存,而且还能禁止指令和编译优化。
至少上面的那个例子我们可以再试试:
public class VolatileTest
{
public volatile int falg = 0;
}
volatile 发布版

到这里应该就可以了吧,volatile 真好用,一个关键字就搞定。
正如你所想,依然没有结束。
三、原子性
我们平时经常遇到要给一段代码区域加上锁,比如这样:
lock (lockObj)
{
count++;
}
我么们为什么要加锁呢?你说为了线程同步,为什么加锁就能保证线程同步而不是其他方式?
3.1count++
说到这里,我们需要再了解一个问题:count++
我们经常写这样的代码,那么count++ 最终转换成cpu指令会是什么样子呢?
指令1: 从内存中读取 count
指令2:将 count +1
指令3:将新计算的count值,写回内存
我们将这个count++ 操作和线程切换进行结合
count++ 线程切换
这里才是真正解答了最开始为什么是 100万到200之间的随机数。
解决 原子性问题的方法有很多,比如锁

3.2 lock
加锁这个代码我就暂且忽略,因为lock我们并不陌生。
但是需要明白一点,lock() 是微软提供给我们的语法糖,其实最终使用的是 Monitor,并且做了异常和资源处理。

lock
CLR 锁原理

多个线程访问同一个实例下的共享变量,同时将同步块索引从 -1 改成CLR维护的同步块数组,
用完就会将实例的同步快变成-1
3.3 Monitor
上面提到了隐姓埋名的Monitor,其实我们也可以抛头露面地使用Monitor
这里也不具体细说。具体使用可以参照上面图片。
3.4 System.Threading.Interlocked
官方定义:原子性的简单操作,累加值,改变值等
区区 count++ 使用lock 有点浪费,我们使用更加轻量级的 Interlocked,
为我们的 count ++ 保驾护航。
public class ThreadTest_V3
{
public volatile int count = 0;
public void Add1()
{
int index = 0;
while (index++ < 1000000)//100万次
{
Interlocked.Add(ref count, 1);
}
}
public void Add2()
{
int index = 0;
while (index++ < 1000000)//100万次
{
Interlocked.Add(ref count, 1);
}
}
}
结果不多说,依然稳稳的 200万。
3.5 System.Threading.SpinLock结构
自旋锁结构,可以这样理解。
多线程访问共享资源时,只有一个线程可以拿到锁,其他线程都在原地等待,
直到这个锁被释放,原地等待的资源又一次进行抢占,以此类推。
在具体使用 System.Threading.SpinLock结构 之前,我们根据刚刚讲过的 System.Threading.Interlocked,进行一下改造:
public struct Spin
{
private int m_lock;//0=unlock ,1=lock
public void Enter()
{
while (System.Threading.Interlocked.Exchange(ref m_lock, 1) != 0)
{
//可以限制自旋次数和时间,自动断开退出
}
}
public void Exit()
{
System.Threading.Interlocked.Exchange(ref m_lock, 0);
}
}
public class ThreadTest_V4
{
private Spin spin = new Spin();
public volatile int count = 0;
public void Add1()
{
int index = 0;
while (index++ < 1000000)//100万次
{
spin.Enter();
count++;
spin.Exit();
}
}
public void Add2()
{
int index = 0;
while (index++ < 1000000)//100万次
{
spin.Enter();
count++;
spin.Exit();
}
}
}
Enter() , m_lock 从0到1,就是加锁;
锁的是共享资源 count;
其他线程原地自旋等待(循环)
Exit(),m_lock 从1到0,就是解锁;
System.Threading.SpinLock 结构和以上实现思想类似。
后面的内容就简单提一下定义和应用场景,有必要的就可以单独细查。
3.6 System.Threading.SpinWait结构
提供了基于自旋等待支援。
在线程必须等待发出事件信号或满足条件时方可使用.
3.7 System.Threading.ReaderWriterLockSlim类
授予独占访问共享资源的写作,
并允许多个线程同时访问资源进行读取。
3.8 CAS
cas 核心思想:
将 count 从内存读取出来并赋值给一个局部变量,叫做 originalData;
然后这个局部变量 +1 并赋值给新值,叫做 newData;
再次从内存中将count读取出来,如果originalData ==count,
说明没有线程修改内存中count值,可以将新值存储到内存中。
反之则可以选择自旋或者其他策略。
当然还有进程之间的同步,这里就不一一展开说了。
总结一下:
并发三要素 可见性、有序性、原子性
几种锁原理和CAS操作