MySQL 索引
MySQL 索引
1、参考资料
https://www.bilibili.com/video/BV1QE411A79s
2、索引本质
索引的本质
- 索引是帮助MySQL高效获取数据的排好序的数据结构
- 索引的数据结构:
- 二叉树(树的不平衡导致查找效率超级低)
- 红黑树(虽然树平衡了,但树的度为 2,导致树的高度很高,需进行多次 I/O)
- Hash 表(虽然好,但不适合范围查找)
- B-Tree(虽然好,但不适合范围查找)
- B+Tree(这才是大佬)
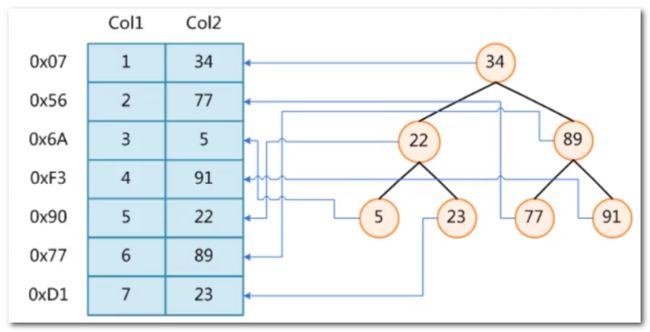
select *from t where col2=89查询语句的执行过程- 如果没有建立索引,MySQL 会进行全表扫描,逐行查找
- 假设我们使用二叉树承载了表的索引,该二叉树节点存储两个信息:索引列的值和该行在磁盘(或者内存)中的地址,排序二叉树的查找类似于二分查找,我们通过二分查找找到关键字信息
col2=89,拿到磁盘地址后,去磁盘进行查找即可
3、红黑树
数据结构演示网址
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉树的缺陷:不平衡、树的深度高
假设我将上述的 col1 字段设置为索引,并建立二叉树承载此索引
二叉树存在不平衡的现象,导致树的高度过高,极端情况下左(或右)子节点都为空,看着就和单链表一样,由于二叉树每次都会查找其左右子节点,这种情况下,二叉树的查找性能比单链表还低

红黑树的优势:平衡;红黑树的缺陷:树的深度高
红黑树通过着色机制,保证树的平衡,红黑树其实就是一颗平衡二叉树
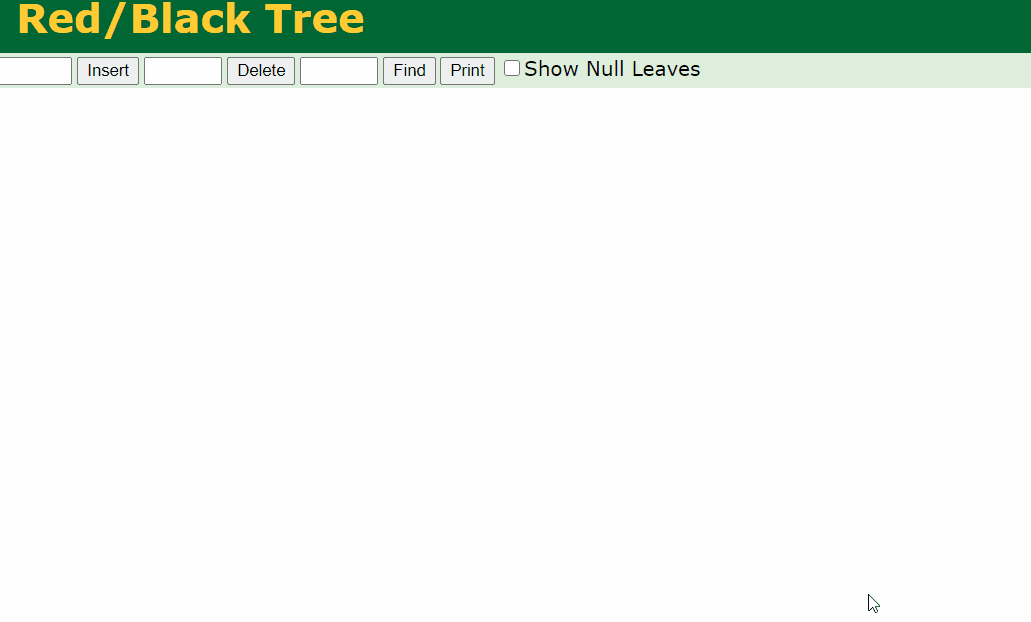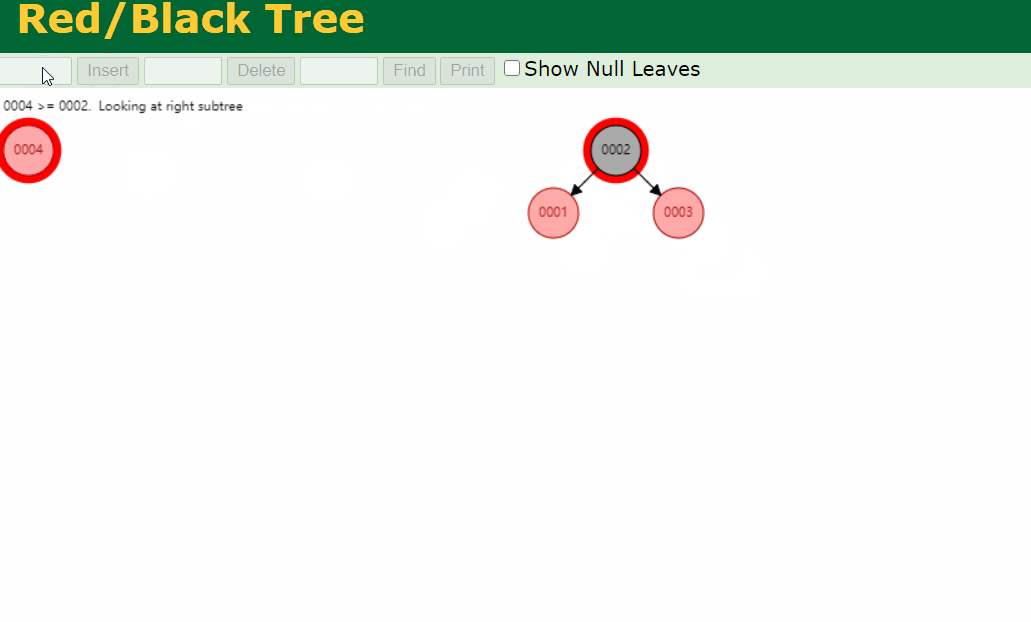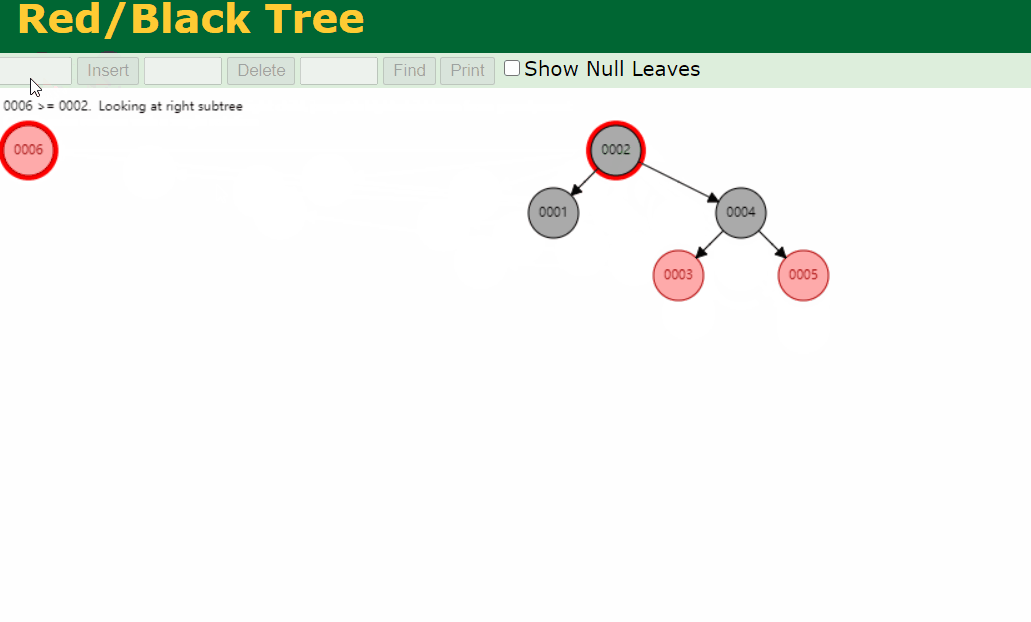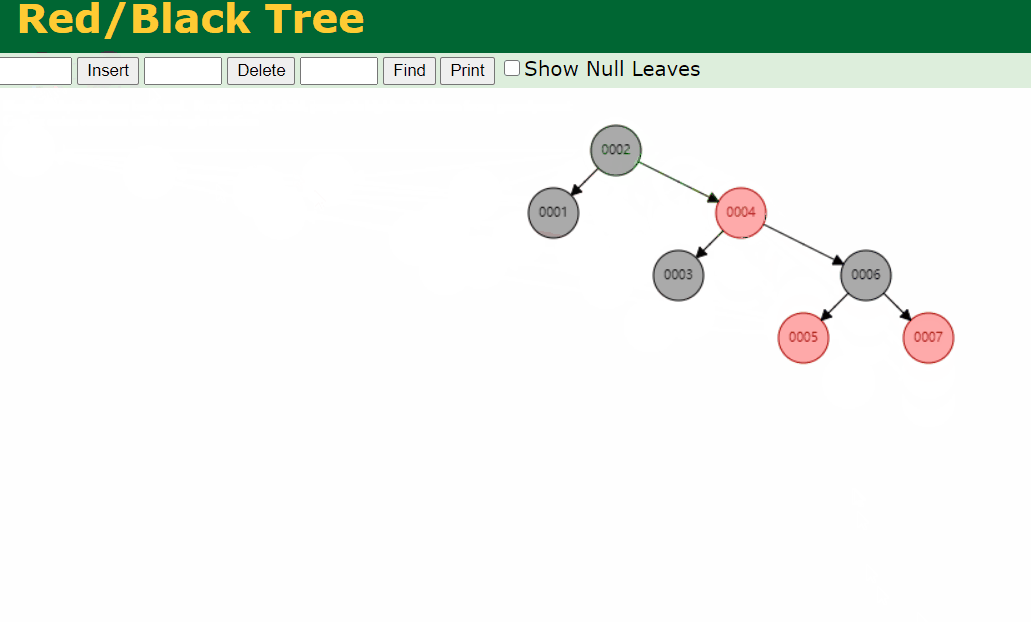
由于平衡机制,使得树的高度降低,查找效率提高

红黑树并不适合作数据库索引,假如有 100w 条数据,加入待查找的关键字存放在叶子节点中,假如这时待查找的元素在红黑树的最深层,这就意味着需要进行多次 I/O 操作
4、B+ 树
B 树:改变节点的度,让每个节点能承载更多信息,以降低树的高度
B 树的特点
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
- 可以将 15、56、77 理解为索引字段的值,将 data 理解为索引所在行的磁盘地址
- 空白框框即为多叉树的指针域,存储的是下一个节点在磁盘中的地址

B 树的创建
B 树的搜索

B+ 树(B 树变种):非叶子节点可以存放更多索引,叶子节点间通过指针链接
B+ 树特点(又名多叉平衡树)
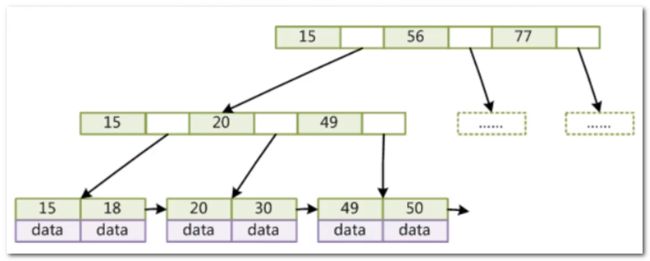
- B+ 树将 data 信息挪到了叶子节点,非叶子节点不存放 data 信息,只存储索引(冗余),这就意味着非叶子节点可以存放更多的索引
- 叶子节点包含所有索引字段,叶子节点没有子节点,不用存储下一个字节的磁盘地址,所以没有那个白色的框框,但是叶子节点包含索引的 data 域
- 叶子节点用指针连接,提高区间访问的性能,这也恰好是 B 树索引和 Hash 索引劣势所在,比如执行如下 SQL :
select* from t where col1 > 6,对于 B 树索引和 Hash 索引,他们根本不知道大于 6 的数据有哪些 - 假设索引为主键索引,我们使用 BigInt 类型,占用 8 个字节(对应着色并且带着数字的框框),MySQL 中的磁盘地址指针为 6 个字节(对应空白框框),那么我们存储一个索引则需要 14 个字节,那么一个 MySQL 磁盘页可以存储
16KB/14B = 1170个索引字段 - 不同数据库对 data 域的实现方式不同,有些数据库 data 域存放的是索引行所在的磁盘地址指针,有些数据库 data 域存储的是索引行所有其他字段的信息,我们保守估计,假设每个 data 域占用 1KB,那么一个 MySQL 磁盘页可以存储个
16KB/1KB = 16个索引字段和 data 域 - 假设三层 B+ 树被撑满了,能存放的数据量为 1170 * 1170 * 16 = 21902400 条,能存放两千多万条数据呀
B+ 树的创建

B+ 树的搜索

查看 MySQL 磁盘页的大小,默认 16KB
SHOW GLOBAL STATUS like 'Innodb_page_size';
B+ 相较于 B 树的优点
参考资料:https://zhuanlan.zhihu.com/p/27700617
- B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
- B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
- B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高;
- B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描;
- B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
5、MyISAM
MyISAM 引擎简介
-
存储引擎是基于表的
-
MyISAM 索引文件和数据文件是分离的(非聚集索引)
-
MyISAM 使用 B+ 树作为索引,图中的 data 域存储的是下一个磁盘的地址
举例说明 select * from t where col1='49' 查找的过程:
- 加载第一层(根节点)的磁盘文件至内存,发现 15<49<56,拿到到第二层的磁盘地址
- 根据第一步拿到的磁盘地址,到第二层加载磁盘文件至内存,发现 49>=49 ,拿到到第三层的磁盘地址
- 根据第二步拿到的磁盘地址,到根节点找到
col1=49的索引列,拿到索引所在行在磁盘中的地址 - 根据第三步拿到的磁盘地址,区磁盘中加载索引所在行的数据,返回给客户端
总共发生了 4 次 I/O

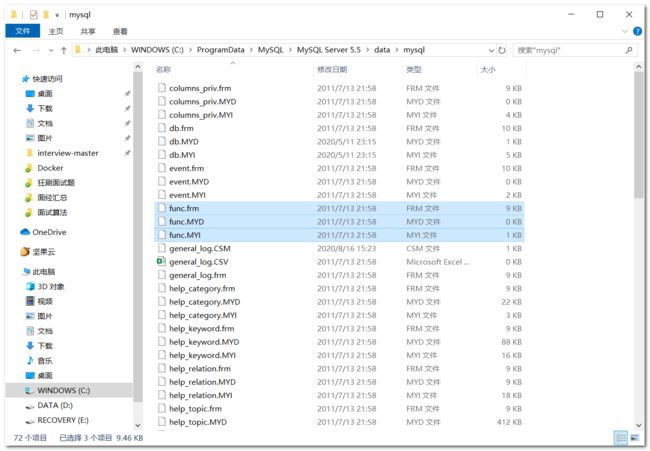
数据库表存储在哪儿?

数据表各种文件的含义
- .frm:表结构的定义
- .MYD:数据文件
- .MYI:索引文件
6、InnoDB
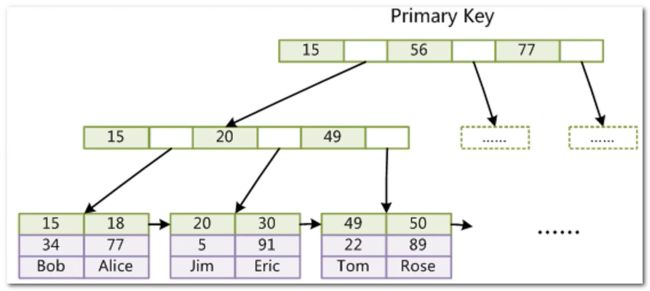
InnoDB 索引实现(聚集)
- 表数据文件(.ibd 文件)本身就是按B+Tree组织的一个索引结构文件
- InnoDB 中叶节点包含了完整的数据记录( data 与存放了索引所在行其他所有字段的信息)
- 聚集(簇)索引:索引文件和数据文件是存储在一个文件里面,InnoDB 的主键索引就是聚集索引
- 聚集索引的优势:比非聚集索引的查找效率高,因为非聚集索引需要在 .MYD 文件和 .MYI 文件中查找,而聚集索引只需要在一个 .ibd 文件中查找
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- InnoDB 本身在组织数据文件时,就是按照 B+ 树去组织的,如果没有主键,InnoDB 没办法组织这个数据文件
- 为什么推荐主键为整形?自增主键数据类型为整形,比较效率高,不要用 UUID 作为主键,字符串之间的比较效率低,并且整形数据占用的空间也比 UUID 小很多
- 为什么推荐主键自增?原因见下
- 在 MySQL 如果我们没有建立主键,那么MySQL 会自动选择一个具有唯一索引的列作为主键,如果找不到,就帮我们悄悄地新建一列
- 对于范围查找,叶子节点之间的指针起大作用啊,兄弟!比如
select* from t where col1 > 20这条 SQL 语句,我们先定位至索引列为 20 叶子节点,我们再根据叶子节点之间的指针,挨个向后遍历查找即可(叶子节点中的数据从左到右依次递增) - 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
数据表各种文件的含义
- .frm:表结构的定义
- .ibd:索引和数据文件

为什么推荐 InnoDB 主键自增?
参考资料:https://blog.csdn.net/Alen_xiaoxin/article/details/104753135
InnoDB 使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
自增的情况
- 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
- 这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
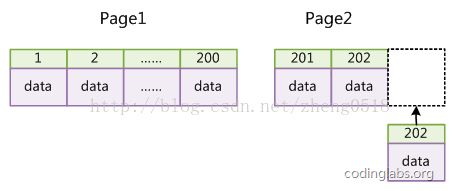
非自增的情况
- 如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
- 此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。

因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
联合索引长啥样?
- 我们在三个列上建立了一个联合索引:整形 id 、字符串 name、日期 birthDate
- 排序规则:建立索引时,哪个列写在前面,就先按照他排序
- 大致查找流程:先按照 id 查找,如果 id 能比出大小,就按照 id 字段排序,如果 id 字段都相同,就按照第二个 name 字段进行比较,以此类推 …
- 那现在就能解释最左前缀原则啦~~~,比如
select* from employee where name='Staff'就不会走索引,因为 name 是依靠着 id 进行排序的
