Linux操作系统硬件性能调优测试
Linux操作系统硬件性能调优测试
- 1. CPU性能测试
- 2. 内存性能测试
- 3. 磁盘性能测试
-
- 3.1. dd工具
- 3.2. fio工具
- 3.3. iostat工具
- 4. 存储性能测试
- 5. 网卡性能测试
-
- 5.1. sar工具
- 5.2. 脚本工具
- 5.3. iftop工具
1. CPU性能测试
模拟对CPU加压
接下来使用dd命令不停的消耗CPU资源(可以类比一个车不断的空踩油门)
连续执行两次:
dd if=/dev/zero of=/dev/null &
dd if=/dev/zero of=/dev/null &
执行top命令,再按c按键可以查看具体的命令:

jobs
[1]- 运行中 dd if=/dev/zero of=/dev/null &
[2]+ 运行中 dd if=/dev/zero of=/dev/null &
kill %1
[1]- 已终止 dd if=/dev/zero of=/dev/null
kill %2
[2]+ 已终止 dd if=/dev/zero of=/dev/null
通过上述实验可以看到两颗CPU跑满,但是总的CPU还剩下95.0(id值),是因为该服务器是40核CPU,2个CPU资源被占满,剩余38个空闲CPU资源,(38/40=0.95)
如果把CPU的任务执行设置成先进先出,那么执行dd就会死机了,就好比一个厕所只有一个坑,只有等先进去的人完事第二个人才可以进去
假如系统是2核的CPU,一个dd一直执行,系统其他程序还要占据一部分CPU,所以如果设置成先进先出,第二个dd执行就直接死机了
如果不设置先进先出,每个任务共享CPU资源,每个任务的执行都分配一部分CPU
写一个脚本将dd执行80次,因为是40核的CPU,这样每个任务都会分一部分CPU资源,所以每个dd命令占据的CPU资源基本上是50%左右,而剩余CPU资源将会是0
#!/bin/bash
for ((i=1; i<=80; i++))
do
dd if=/dev/zero of=/dev/null &
done
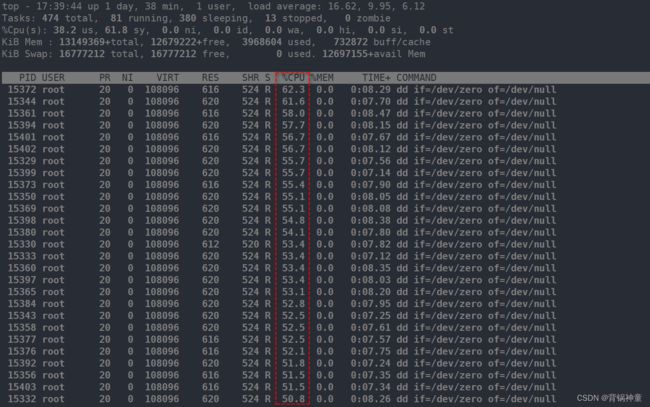
如果设置成先进先出:
# chrt -f 10 dd if=/dev/zero of=/dev/null &
我的服务器是40核的,这条命令执行39下,第40个就直接把服务器卡死,因为系统程序都会挤到一个CPU去运行,第一个dd不运行完,第二个就不允许进来,所以每个dd都占着一个CPU运行。39个dd任务全占着CPU资源,系统运行还需要一些CPU资源,所以再次执行第40个dd,会直接将系统干崩溃。
使用iostat工具查看CPU使用情况:
yum install -y sysstat-10.1.5-19.el7.x86_64
iostat
Linux 3.10.0-1160.el7.x86_64 (worker1) 05/28/2022 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.20 0.00 0.79 0.01 0.00 98.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.68 0.03 8.92 219540 61027516
%user:用户级CPU使用率,也就是上层应用程序的CPU使用率
%nice:nice命令是调优先级的, nice -15 command 调优先级,调用了nice cpu就需要重新计算
%system:系统内核CPU资源消耗
%iowait:磁盘消耗,IO的等待时间
%steal:这个数值和虚拟化有关,如果在虚拟机中使用dd命令(后面有操作)则这个值就会增大,但是vmware的虚拟机是看不到的,需要使用KVM的虚拟机,我使用金山云、腾讯云主机测试也没效果
%idle:CPU空闲率
tps:每秒钟处理的请求数(每秒处理的IO数目),可以把kB_read+ kB_wrtn加一起除以tps值,就可以算出block的大小
2. 内存性能测试
free -m
total used free shared buff/cache available
Mem: 128411 3869 123826 9 715 124001
Swap: 16383 0 16383
shared:共享内存(shared)是19M,也就是多个程序占用的共享内存16M
buff/cache:缓存,buff是inode,cache是block,缓存作用:当读取一个数据时,系统会从硬盘中将数据读到内存中,读完后并不会立即释放该内存,如果内存不紧张,一直不释放,除非内存紧张。这部分内存可以被当作缓存来使用,加速缓存来操作
sysctl -w vm.drop_caches=3
丢弃缓存,当然buff/cache这个数值不能为清为0,因为有些正在被读取的数据可能正在使用,1是清理buff,2 是清理cache,3是buff和cache都清理。
swap:虚拟内存,如果没有swap分区,那么可能发生内存溢出,swap是虚拟内存,实际上是从硬盘出分出一块分区(内存置换就是使用这块分区)
time cp -r /var/ /tmp
real 0m1.464s
user 0m0.030s
sys 0m0.650s
cp的时候就把数据缓存到内存中了,再执行就更快了,因为不再从硬盘读了,直接从缓存读了
time cp -r /var/ /data
real 0m1.284s
user 0m0.022s
sys 0m0.616s
所以当内存资源不紧张时,可以一直留着缓存,增加读性能。
但是为了测试其他数据的准确性,最好执行sysctl -w vm.drop_caches=3,这样更能体现测试的准确性,不让数据直接从缓存读取。
问:如果内存不足,有新的程序又要申请内存,缓存会自动释放了吗?
答:会自动释放了,到时候是让新的程序使用swap分区还是让缓存释放来给新的程序使用,是有参数控制的,见后的讲解
问:如何查看一个进程使用多少内存?
ps aux | grep vsftp
root 3059 0.0 0.0 53292 696 ? Ss 2月01 0:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf
696也就是ps aux中RSS列的值
服务器可使用的最大内存频率:
背景:由于某线上存储运行平台的服务器内存为2400MHz,现计划扩容该存储集群,但得到厂商的反馈是扩容的服务器必须要和原服务器的内存频率保持一致,但是手里头有一些利旧服务器,不想再去迎合厂商的需求采购新的服务器,又不想去单独采购2400MHz的内存条插到服务器上,接下来开始调试之旅吧~~~
内存的频率显示是和CPU型号紧密相关的
-
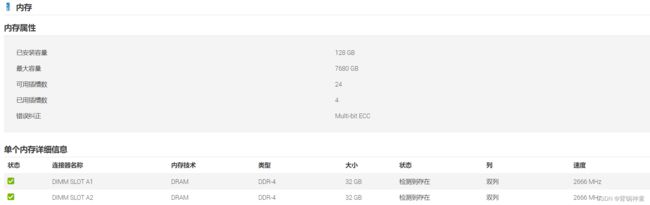
服务器1的CPU型号是:Intel® Xeon® Gold 5218 CPU @ 2.30GHz
- 如果插入如下3200频率的内存,那么在服务器的的管理界面查看到的内存频率将为2666MHz

- 如果插入如下3200频率的内存,那么在服务器的的管理界面查看到的内存频率将为2666MHz
服务器管理界面显示如下:
该CPU型号并不能完全的使用到3200MHz,即该CPU最大识别到2666MHz
-
如果插入如下2933MHz的内存,那么在服务器的的管理界面查看到的内存频率同样为2666MHz

-
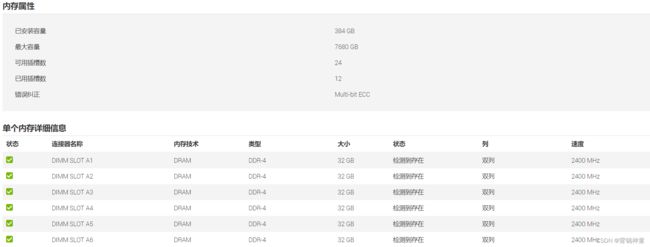
服务器2的CPU型号是:Intel® Xeon® Silver 4214 CPU @ 2.20GHz
- 如果插入如下2933MHz的内存,那么在服务器的的管理界面查看到的内存频率为2400MHz

- 如果插入如下2933MHz的内存,那么在服务器的的管理界面查看到的内存频率为2400MHz
其实到此需求已经有解决办法了,那就是把服务器2的内存都插上2933MHz的内存条就行了,但是服务器2的台数不够,扩容需求中至少需要4台,而我只有3台,但是服务器1总共有4台,哎~~
只能跟领导申请买内存条,用最少的钱解决问题,服务器1总计有4台,而每台服务器有两颗CPU,所以每台服务器至少需要2条2400MHz的内存(即每个CPU控制的内存都插1条,A1插一条2400MHz的,B1插一条2400MHz的内存条)
CPU控制的内存频率中,如果有一条频率较低,其他内存条的频率会降频和最低的频率保持对其,所以每个CPU处只需要插一条2400MHz的内存,其他的内存条频率无论怎么高,也得跟这个2400MHz的保持对其
综上的分析也就是我只需要买8条2400MHz的内存条即可解决问题(其余无论该服务器插多少根内存条,那么所有内存的频率在服务器管理界面都将显示2400MHz)
可能遇到的问题:
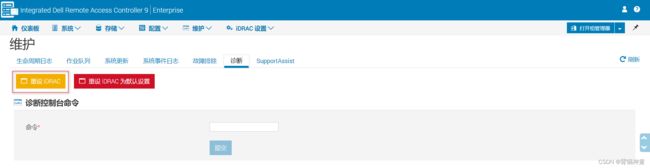
总计4台服务器中的3台这么操作之后都是显示2400MHz,其中1台还是显示2666MHz,联系戴尔售后反馈需要更新iDRAC固件版本( 3.36.36.36),需要戴尔售后工程师操作。
更换完内存条在之后,需要重设iDRAC,重设之后将强制退出管理界面,需要过几分钟再登录。
总结:内存频率和CPU型号息息相关,但是也不是按照内存的最大频率(内存条标注的频率)使用,具体按照哪个内存频率使用,需要具体看CPU的型号。低频内存条需要两颗CPU处至少各插一条(A1、B1)才能降频。
当然也可以去网络查找相关CPU支持的内存频率:
Intel® Xeon® Gold 5218 Processor 22M Cache, 2.30 GHz:

Intel® Xeon® Silver 4214 Processor16.5M Cache, 2.20 GHz详细参数:

3. 磁盘性能测试
3.1. dd工具
dd if=/dev/zero of=test1 bs=8k count=102400 oflag=direct &
不写oflag=direct会把数据直接写到内存,所以加这个参数后数据直接写到硬盘,更能测试出硬盘的性能(省去了内存和硬盘数据资源整合的过程)
block块大小设置为8k:
# dd if=/dev/zero of=test1 bs=8k count=102400 oflag=direct
102400+0 records in
102400+0 records out
838860800 bytes (839 MB) copied, 12.1258 s, 69.2 MB/s
block块大小设置为4K:
# dd if=/dev/zero of=test1 bs=4k count=102400 oflag=direct
102400+0 records in
102400+0 records out
419430400 bytes (419 MB) copied, 12.3598 s, 33.9 MB/s
同样是800M大小数据,块大小设置的不一样,写的速率也不一样
3.2. fio工具
yum install -y fio
测试案例:
协商测试条件 :64KB 随机100% 读70%写30% IO深度16 :
实际会生成一个这个文件/wangzy_demo73.file
# fio -filename=/data/wangzy_demo73.file -direct=1 -iodepth 16 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=64k -size=10G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
输出:
fio-3.7
Starting 50 threads
randrw_70read_4k: Laying out IO file (1 file / 10240MiB)
Jobs: 50 (f=50): [m(50)][100.0%][r=241MiB/s,w=102MiB/s][r=3856,w=1628 IOPS][eta 00m:00s]
randrw_70read_4k: (groupid=0, jobs=50): err= 0: pid=17888: Mon Nov 8 05:35:12 2021
read: IOPS=3990, BW=249MiB/s (262MB/s)(43.9GiB/180062msec)
clat (usec): min=246, max=176467, avg=7023.24, stdev=8212.76
lat (usec): min=246, max=176468, avg=7023.62, stdev=8212.77
clat percentiles (usec):
| 1.00th=[ 1500], 5.00th=[ 1909], 10.00th=[ 2212], 20.00th=[ 2704],
| 30.00th=[ 3130], 40.00th=[ 3589], 50.00th=[ 4113], 60.00th=[ 4817],
| 70.00th=[ 6259], 80.00th=[ 10814], 90.00th=[ 14615], 95.00th=[ 19006],
| 99.00th=[ 46924], 99.50th=[ 58983], 99.90th=[ 81265], 99.95th=[ 88605],
| 99.99th=[115868]
bw ( KiB/s): min= 896, max=18688, per=2.00%, avg=5109.15, stdev=1532.54, samples=17989
iops : min= 14, max= 292, avg=79.79, stdev=23.95, samples=17989
write: IOPS=1712, BW=107MiB/s (112MB/s)(18.8GiB/180062msec)
clat (usec): min=343, max=116561, avg=12794.22, stdev=4158.95
lat (usec): min=344, max=116566, avg=12798.81, stdev=4158.98
clat percentiles (usec):
| 1.00th=[ 5997], 5.00th=[ 7701], 10.00th=[ 8717], 20.00th=[ 9765],
| 30.00th=[10552], 40.00th=[11207], 50.00th=[11994], 60.00th=[12780],
| 70.00th=[13829], 80.00th=[15533], 90.00th=[18220], 95.00th=[20579],
| 99.00th=[25822], 99.50th=[28443], 99.90th=[35390], 99.95th=[38011],
| 99.99th=[48497]
bw ( KiB/s): min= 256, max= 8448, per=2.00%, avg=2192.45, stdev=690.87, samples=17989
iops : min= 4, max= 132, avg=34.21, stdev=10.79, samples=17989
lat (usec) : 250=0.01%, 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=4.42%, 4=29.22%, 10=27.73%, 20=33.82%, 50=4.17%
lat (msec) : 100=0.58%, 250=0.02%
cpu : usr=0.10%, sys=0.30%, ctx=1029009, majf=0, minf=2354
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=718594,308385,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=16
Run status group 0 (all jobs):
READ: bw=249MiB/s (262MB/s), 249MiB/s-249MiB/s (262MB/s-262MB/s), io=43.9GiB (47.1GB), run=180062-180062msec
WRITE: bw=107MiB/s (112MB/s), 107MiB/s-107MiB/s (112MB/s-112MB/s), io=18.8GiB (20.2GB), run=180062-180062msec
测试场景:
- 100%随机,100%读, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
- 100%随机,100%写, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
- 100%顺序,100%读 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
- 100%顺序,100%写 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
- 100%随机,70%读,30%写 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
参数说明:
- 输入参数:
filename=/dev/emcpowerb 支持文件系统或者裸设备,-filename=/dev/sda2或-filename=/dev/sdb
direct=1 测试过程绕过机器自带的buffer,使测试结果更真实
rw=randwread 测试随机读的I/O rw=randwrite 测试随机写的I/O
rw=randrw 测试随机混合写和读的I/O
rw=read 测试顺序读的I/O
rw=write 测试顺序写的I/O
rw=rw 测试顺序混合写和读的I/O
bs=4k 单次io的块文件大小为4k
bsrange=512-2048 同上,提定数据块的大小范围
size=5g 本次的测试文件大小为5g,以每次4k的io进行测试
numjobs=30 本次的测试线程为30
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止
ioengine=psync io引擎使用pync方式,如果要使用libaio引擎,需要yum install libaio-devel包
rwmixwrite=30 在混合读写的模式下,写占30%
group_reporting 关于显示结果的,汇总每个进程的信息
此外
lockmem=1g 只使用1g内存进行测试
zero_buffers 用0初始化系统buffer
nrfiles=8 每个进程生成文件的数量
- 输出参数:
io=执行了多少M的IO
bw=平均IO带宽
iops=IOPS
runt=线程运行时间
slat=提交延迟
clat=完成延迟
lat=响应时间
bw=带宽
cpu=利用率
IO depths=io队列
IO submit=单个IO提交要提交的IO数
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO完延迟的分布
io=总共执行了多少size的IO
aggrb=group总带宽
minb=最小.平均带宽.
maxb=最大平均带宽.
mint=group中线程的最短运行时间.
maxt=group中线程的最长运行时间.
ios=所有group总共执行的IO数.
merge=总共发生的IO合并数.
ticks=Number of ticks we kept the disk busy.
io_queue=花费在队列上的总共时间.
util=磁盘利用率
以64KB为一个单位 ,3990就是1秒进行3990次64KB的写入,3390x64/1000
1MB = 1000KB
1MiB = 1024KiB
3.3. iostat工具
iostat -d 1 5 -d(disk)仅查看磁盘,1秒显示一次,总计显示5次
Linux 3.10.0-1160.el7.x86_64 (worker1) 05/28/2022 _x86_64_ (4 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.68 0.03 8.92 219540 61028412
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 1.00 0.00 12.00 0 12
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
iostat –x 显示更加详细的信息
iostat -c 1 5 -c是仅查看CPU,1秒显示一次,总计显示5次
iostat只能显示开机到现在的数据,要么就显示当下的数据状态, iostat不能查看昨天的历史数据,但是sar可以
使用sar工具查看磁盘IO情况:
sar -d 1 10 -d表示硬盘
sar -p -d 1 10 -p 可以显示设备本身
4. 存储性能测试
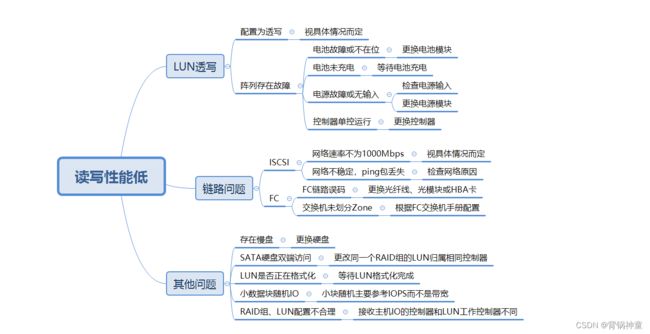
案例说明:
描述问题:某IPTV局点客户反馈,偶尔出现黑屏情况。
分析原因:系统状态正常,LUN运行策略为回写镜像,链路正常、无误码、无闪断。使用iostat -x 1观察,发现在业务量大时,有一个盘的服务时间(svctm)明显比其他盘高很多,超过50ms,判定该盘为慢盘。
解决步骤:将该硬盘离线,并更换该硬盘
验证恢复:更换硬盘后,没有再出现黑屏现象
5. 网卡性能测试
主要测试网卡承载的流量以及网卡的实时流量
5.1. sar工具
yum install -y sysstat
sar -n DEV 5 1 # 每5秒钟取1次值,取1次
DEV显示网络接口信息,-n参数后面还可以接6个不同的开关:DEV | EDEV | NFS | NFSD | SOCK | ALL ,其代表的含义如下:
● DEV显示网络接口信息。
● EDEV显示关于网络错误的统计数据。
● NFS统计活动的NFS客户端的信息。
● NFSD统计NFS服务器的信息
● SOCK显示套接字信息
● ALL显示所有5个开关
参数说明:
● IFACE:LAN接口
● rxpck/s:每秒钟接收的数据包
● txpck/s:每秒钟发送的数据包
● rxbyt/s:每秒钟接收的字节数
● txbyt/s:每秒钟发送的字节数
● rxcmp/s:每秒钟接收的压缩数据包
● txcmp/s:每秒钟发送的压缩数据包
● rxmcst/s:每秒钟接收的多播数据包
● rxerr/s:每秒钟接收的坏数据包
● txerr/s:每秒钟发送的坏数据包
● coll/s:每秒冲突数
● rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
● txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
● txcarr/s:发送数据包时,每秒载波错误数
● rxfram/s:每秒接收数据包的帧对齐错误数
● rxfifo/s:接收的数据包每秒FIFO过速的错误数
● txfifo/s:发送的数据包每秒FIFO过速的错误数
5.2. 脚本工具
此脚本不需要额外再安装软件,并且可自定义查看的接口,精确到小数,可根据流量大小灵活显示单位,默认采集间隔为1秒
cat net.sh
#!/bin/bash
ethn=$1
while true
do
RX_pre=$(cat /proc/net/dev | grep $ethn | sed 's/:/ /g' | awk '{print $2}')
TX_pre=$(cat /proc/net/dev | grep $ethn | sed 's/:/ /g' | awk '{print $10}')
sleep 1
RX_next=$(cat /proc/net/dev | grep $ethn | sed 's/:/ /g' | awk '{print $2}')
TX_next=$(cat /proc/net/dev | grep $ethn | sed 's/:/ /g' | awk '{print $10}')
clear
echo -e "\t RX `date +%k:%M:%S` TX"
RX=$((${RX_next}-${RX_pre}))
TX=$((${TX_next}-${TX_pre}))
if [[ $RX -lt 1024 ]];then
RX="${RX}B/s"
elif [[ $RX -gt 1048576 ]];then
RX=$(echo $RX | awk '{print $1/1048576 "MB/s"}')
else
RX=$(echo $RX | awk '{print $1/1024 "KB/s"}')
fi
if [[ $TX -lt 1024 ]];then
TX="${TX}B/s"
elif [[ $TX -gt 1048576 ]];then
TX=$(echo $TX | awk '{print $1/1048576 "MB/s"}')
else
TX=$(echo $TX | awk '{print $1/1024 "KB/s"}')
fi
echo -e "$ethn \t $RX $TX "
done
chmod +x net.sh
sh net.sh bond1
![]()
5.3. iftop工具
iftop 可以监控指定网卡的实时流量、端口连接信息、反向解析 IP 等,还可以精确显示本机网络流量及网络内各主机和本机相互通信的流量集合
通过源代码编译安装:
yum install -y libpcap libpcap-devel ncurses ncurses-devel flex byacc
wget "http://www.ex-parrot.com/~pdw/iftop/download/iftop-0.17.tar.gz"
tar zxvf iftop-0.17.tar.gz
cd iftop-0.17
./configure
make && make install
安装完iftop工具后,直接输入iftop命令即可显示网卡实时流量信息。在默认情况下,iftop显示系统第一块网卡的流量信息,如果要显示指定网卡信息,可通过“-i”参数实现
iftop -P -i bond1
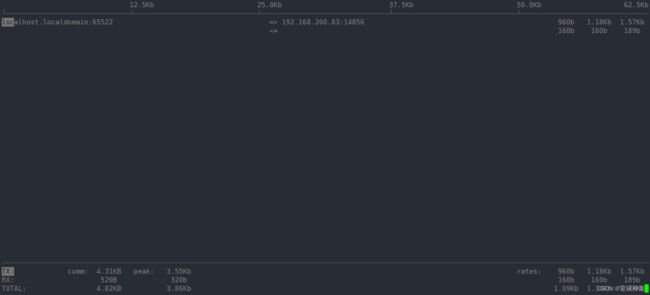
- 第一部分
- iftop 输出中最上面的一行,此行信息是流量刻度,用于显示网卡带宽流量。
- 第二部分
- 此部分为分割线中间的部分,其中又分别分为左、中、右三列。左列和中列,记录了哪些IP或主机正在和本机的网络进行连接。其中,中列的“=>”代表发送数据,“<=”代表接收数据,通过这个指示箭头可以很清晰地知道两个IP之间的通信情况。最右列又分为三小列,这些实时参数分别表示外部 IP连接到本机 2 秒内、10 秒内和 40 秒内的平均流量值。
- 另外,这个部分还有一个流量图形条,流量图形条是对流量大小的动态展示,以第一部分中的流量刻度为基准。通过这个流量图形条可以很方便地看出哪个IP的流量最大,进而迅速定位网络中可能出现的流量问题。
- 第三部分
- 位于iftop输出的最下面,可以分为三行,其中,“TX”表示发送数据,“RX”表示接收数据,“TOTAL”表示发送和接收全部流量。与这三行对应的有三列,其中“cumm”列表示从运行 iftop 到目前的发送、接收和总数据流量。“peak”列表示发送、接收以及总的流量峰值。“rates”列表示过去 2s、10s、40s 的平均流量值。
交互操作:
在iftop的实时监控界面中,还可以对输出结果进行交互式操作,用于对输出信息进行整理和过滤,在上图所示界面中,按键 “h” 即可进入交互选项界面,iftop 的交互功能和 Linux 下的top命令非常类似,交互参数主要分为4个部分,分别是一般参数、主机显示参数、端口显示参数和输出排序参数。相关参数的含义如下表所示:
参数 含义
P 通过此键可切换暂停/继续显示
h 通过此键可在交互参数界面/状态输出界面之间来回切换
b 通过此键可切换是否显示平均流量图形条
B 通过此键可切换显示2秒、10秒、40秒内的平均流量
T 通过此键可切换是否显示每个连接的总流量
j/k 按j键或k键可以向上或向下滚动屏幕显示当前的连接信息
l 通过此键可打开iftop输出过滤功能,比如输入要显示的IP,按回车后,屏幕就只显示与这个IP相关的流量信息
L 通过此键可切换显示流量刻度范围,刻度不同,流量图形条会跟着变化
q 通过此键可退出iftop流量监控界面
n 通过此键可使iftop输出结果以IP或主机名的方式显示
s 通过此键可切换是否显示源主机信息
d 通过此键可切换是否显示远端目标主机信息
t 通过此键可切换iftop显示格式,连续按此键可依次显示:以两行显示发送接收流量、以一行显示发送接收流量、只显示发送流量/接收流量
N 通过此键可切换显示端口号/端口号对应服务名称
S 通过此键可切换是否显示本地源主机的端口信息
D 通过此键可切换是否显示远端目标主机的端口信息
p 通过此键可切换是否显示端口信息
1/2/3 根据最近 2 秒、10 秒、40 秒的平均网络流量排序
< 通过此键可根据左边的本地主机名或IP地址进行排序
> 通过此键可根据远端目标主机的主机名或IP地址进行排序
o 通过此键可切换是否固定显示当前的连接
使用示例:
- 显示网卡 eth0 的信息,主机通过 ip 显示
iftop -i bond1 -n
- 显示端口号(添加 -P 参数,进入界面可通过 p 参数关闭)
iftop -i bond1 -n -P
- 显示将输出以 byte 为单位显示网卡流量,默认是 bit
iftop -i bond1 -n -B
- 显示流量进度条
iftop -i bond1 -n
# 进入界面后按下shift+l
- 显示每个连接的总流量
iftop -i bond1 -n
# 进入界面后按下shift+t
- 显示指定 ip 172.17.1.158 的流量
iftop -i bond1 -n
# 进入界面后按下 l 后,再输入172.17.1.158并回车
实战:
下面将通过找出最费流量的IP和端口号实例来综合讲解iftop
进入界面:
iftop -i bond1 -nNB -m 10M
-i 指定网卡,
-n 代表主机通过ip显示不走DNS
-N 只显示连接端口号,不显示端口对应的服务名称(不加会显示如ssh这样的服务名称,不便于排查)
-B 指定显示单位为Kb,默认是bit,太小!
-m 设置输出界面中最上面的流量刻度最大值,流量刻度分5个大段显示
进入后界面如下:

按下shift+l显示流量刻度(L 参数直接显示进度条,方便阅读):

按下shift+t显示总量,总数统计:

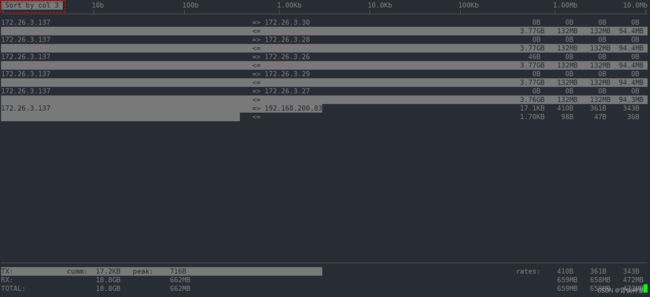
按下 3,根据最近 40s 统计排序,用平均值来统计最权威:
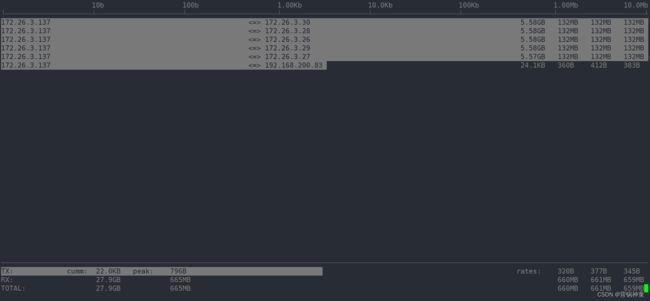
按下 t,流量发送和流量接收合成一行:
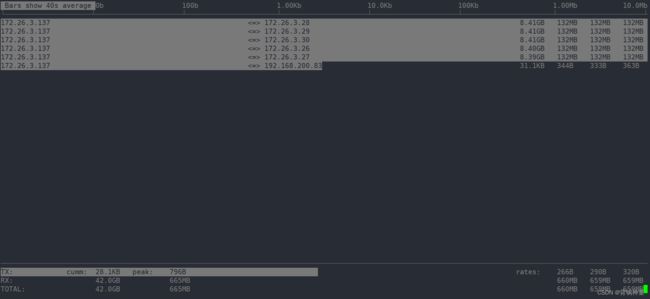
多按几次 shift+b,查看最近 2s、10s、40s的统计:
根据流量进度条找出图中流量用得最多的 IP(当然我这个是压测仪打的流量,所以每个IP都很高),假定172.26.3.30是流量最高的,筛选指定 IP:172.26.3.30
按下 shift+l, 输入172.26.3.30,出现如下:
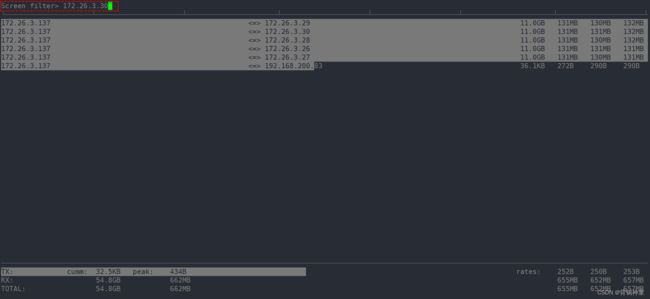
按回车:
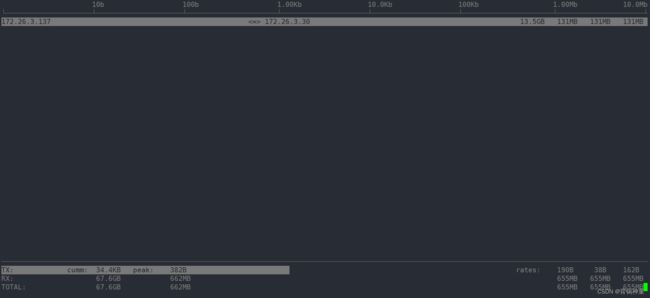
这样就只看到这个 IP 的流量监控了。找到这个IP哪个端口流量用得最多
按下 p根据端口号显示(我这个服务器没有任何端口流量,使用压测仪往网卡打的流量)
