数据库表的设计——范式
目录
1. 设计数据表需要注意的点
2. 范式
2.1 范式简介
2.2 范式有哪些?
2.3 第一范式(1NF)
2.4 第二范式(2NF)
2.5 第三范式(3NF)
2.6 小结
1. 设计数据表需要注意的点
(1)首先要考虑设计这张表的用途,这张表都要存放什么数据;
(2)还要保证数据表中数据的正确性,在进行插入,删除,更新时应该做出哪些约束检查;
(3)要考虑如何降低数据表的数据冗余度,可以允许数据量变大,但要考虑数据量不会因为急速增长;
(4)在设计时还要考虑日后的数据维护问题,不能使表中的数据维护工作复杂;
2. 范式
2.1 范式简介
范式的英文名称位 Normal Form,简称NF。在关系型数据库中,关于数据表设计的基本原则,规则称之为范式。
可以简单的理解为,一张数据表的设计结构需要满足某种设计标准的级别,满足某种规则。
2.2 范式有哪些?
目前关系型数据库的范式一共有6种,按照范式的级别,从低到高分别是 第一范式(1NF),第二范式(2NF),第三范式(3NF),巴斯-科德范式(BCNF),第四范式(4NF),第五范式(5NF)。
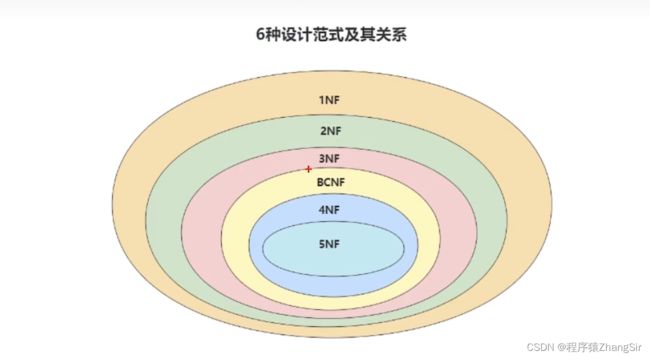
范式的阶层越高,数据的冗余度越低,但要求也会越来越严格,高范式都是在低范式的基础上推导出来的,所以高范式一定满足低范式的规范要求。
但在绝大多数企业设计数据表的时候,一般遵循到3NF,有些更为严格的表会设计到BCNF,不仅如此,有些时候,我们还会根据业务需要破坏范式要求,适当增加表的冗余度来提高查询的性能,这就是理论和实践结合的使用。
2.3 第一范式(1NF)
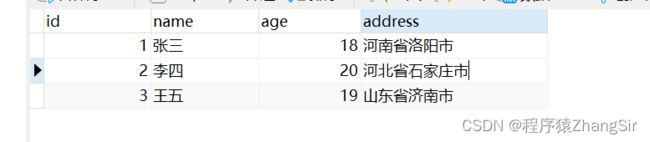
第一范式主要是确保数据表中每个字段都具有原子性,每个字段都不可再进行拆分的最小单元,像下面这种情况就违背了第一范式,address 可以拆分为省和市,除非说你的业务中只会用到查询整个地址的业务,不会用到细粒度的地址查询功能,可以这样设计,但还是建议拆分成两个,如果有需要可以在代码层再进行拼接。
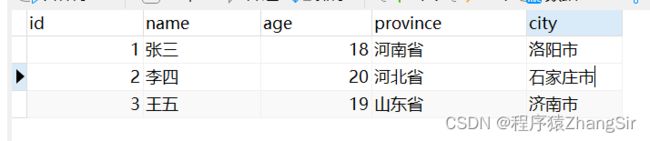
下面就是正确的表字段,将原来的 address 拆分为 province 和 city,每个字段都是最小字段,不可再拆分,满足了第一范式的要求。
2.4 第二范式(2NF)
第二范式要求,在满足第一范式的基础上,还要满足数据表中的每一条数据记录都是可唯一标识的。而且所有的非主键字段,都须完全依赖于主键,不能只依赖于主键的一部分。如果知道了主键的值,就能检索到任意一行的任意一个具体字段的值。
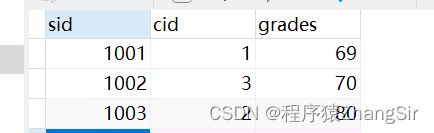
如下,sid 表示学生编号,cid 表示课程编号,grades 表示课程成绩;
在这个数据表中,想要查询到成绩,必须知道学生号和课程号才能查询的得到,一个学生会有多科成绩。
如果只知道学生号,将查询到多条数据;
如果只知道课程号,将查询到所有同学当前课程的成绩;
只有学生号和课程号都确定,才能查找到一条唯一的成绩记录;
所以 (学号,课程)——>成绩,学号和课程虽然是两个字段,但都是主键。
我们再来看一个反例
比赛表 player_game 中,包含球员id,比赛id,球员姓名,球员年龄,比赛时间,比赛地点,比赛分数,
但是细细分析会发现,name,age跟球员具有强关联;time,address跟比赛具有强关联;score 跟球员id和比赛id都有关联,但是现在放在了一张表中,是不合理的,所以这种表的设计都是垃圾表。

正确的做法是将上面的一张表拆分为3张表,分别是球员信息表,比赛信息表,球员得分表。
球员信息表,球员id为主键,通过球员id可以查询到详细的球员信息
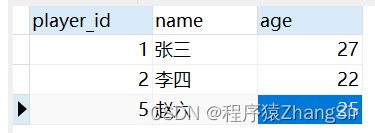
比赛信息表,比赛id为主键,通过比赛id可以查询到比赛的具体信息
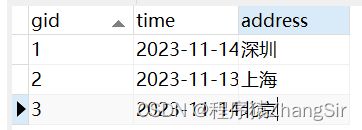
球员得分表,球员id和比赛id为联合主键,通过球员id和比赛id可以查询到某位球员在某场比赛的得分
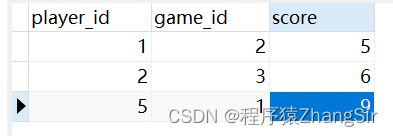
2.5 第三范式(3NF)
第三范式是在第二范式的基础上,确保数据表中每一个非主键字段都和主键字段注解相关,所有的非主键字段不能依赖与其他的非主键,不能存在依赖传递。
比如说一张表现有三个字段 A,B,C,且A是主键,我要查询C,应当通过主键A直接就可以查询到C。不能先通过A查询B,再经过B才能查出C,如果是这样就出现了依赖传递,不符合第三范式的要求。
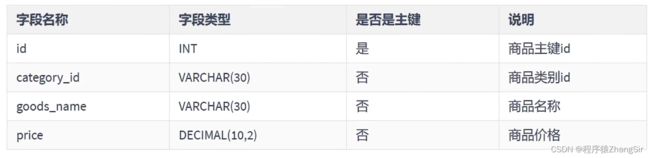
如下设计一张关于商品的数据库表,可以看到,通过非主键字段商品类别id category_id 可以确定商品类别名称,通过商品主键id 也可以确定商品类别名称,中间具有传递性,不满足第三范式的要求也,商品类别名称这个字段在这张表中属于冗余字段。
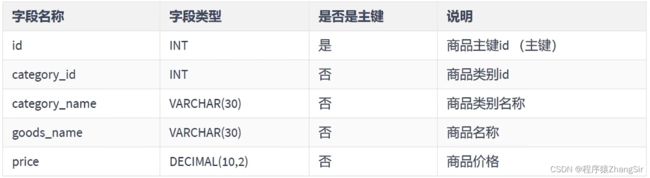
正确做法应该把商品类别id 和商品部类别名称单独放在另外一张表中

然后把商品类别id 作为商品表的一个外键,如果想要查询商品的分类名称,再通过外键去另一张表中查询即可。
2.6 小结
从上面对一二三范式的简单可以得出,第一范式确保每列的原子性,第二范式确保每列和主键完全依赖,第三范式确保每列和主键直接关联而非间接关联。
范式的优点:有助于消除数据库的数据冗余,第三范式通常认为在性能,扩展性,数据完整性方面达到了最好的平衡。
范式的缺点:降低了查询效率,其实同学们可以看出,范式的等级越高,拆分出来的表越多,而多表查询在数据库层面是一个比较耗时的操作,直接影响到了我们的业务吞吐能力,因此在实际设计数据表的时候,我们有时候会为了达到一种平衡违反第三范式来追求业务的性能,但第一范式和第二范式都是几乎会遵守的。
有些时候,我们会违反第三范式的要求,将一部分数据放在一张表中,虽然会有一定的冗余,但是能减少多表查询次数,提高了数据的查询效率,增大了业务吞吐能力,这就是我们常说的牺牲空间换时间。对于用户而言,最不喜欢的就是等待,只要能最快速度的响应用户请求,就是一个好的业务功能设计。
因此,在实际设计数据表的时候,我们需要根据业务需求而定,如果是一个查询比较频繁的业务,可以适当违反范式要求,如果是一个增删改比较频繁的业务,可以适当增大范式规范,,降低数据的冗余度,提高修改数据的效率。