并发包工具之 批量处理任务 CompletionService(异步)、CompletableFuture(回调)
文章目录
-
-
- 一、处理异步任务并获取返回值——CompletionService
- 二、线程池
- 三、Callable 与 Future
- 四、通过回调方式处理可组合编排任务——CompletableFuture
-
一、处理异步任务并获取返回值——CompletionService
特点描述:
对于比较复杂的计算,把任务进行提交,并发执行,哪个任务先执行完,get()方法就会获取到相应的任务结果。
范式:
1、
假设有一组针对某个问题的任务solvers(需要实现Callable接口,任务的具体逻辑就在其call方法里),每个任务都返回一个类型为Result的值,并且想要并发地运行它们,处理每个返回一个非空值的结果,在某些方法使用:
void solve(Executor e,
Collection<Callable<Result>> solvers)
throws InterruptedException, ExecutionException {
CompletionService<Result> ecs
= new ExecutorCompletionService<Result>(e);
for (Callable<Result> s : solvers)
ecs.submit(s);
int n = solvers.size();
for (int i = 0; i < n; ++i) {
Result r = ecs.take().get();
if (r != null)
use(r);
}
}
2、
假设想使用任务集的第一个非空结果,忽略任何遇到异常的任务,并在第一个任务准备好时取消所有其他任务(比如:多仓库文件/镜像下载,从最近的服务中心下载后,终止其他下载过程)
void solve(Executor e,
Collection<Callable<Result>> solvers)
throws InterruptedException {
CompletionService<Result> ecs
= new ExecutorCompletionService<Result>(e);
int n = solvers.size();
List<Future<Result>> futures
= new ArrayList<Future<Result>>(n);
Result result = null;
try {
for (Callable<Result> s : solvers)
futures.add(ecs.submit(s));
for (int i = 0; i < n; ++i) {
try {
Result r = ecs.take().get();
if (r != null) {
result = r;
break;
}
} catch (ExecutionException ignore) {}
}
}
finally {
for (Future<Result> f : futures)
// 注意这里的参数给的是 true,详解同样在前序 Future 源码分析文章中
f.cancel(true);
}
if (result != null)
use(result);
}
总得来说分两步:
1、提交异步任务 submit方法(submit最终会委托给内部的 executor 去执行任务)
2、从队列中拿取并移除元素 take(如果队列为空,那么调用 take() 方法的线程会被阻塞)/poll(…不会被阻塞,返回null)/poll带超时参数(获取并移除阻塞队列中的第一个元素,如果超时时间到而队列还是空,该方法返回null) 方法
实现原理:
将异步任务的生产、任务完成结果的消费进行解耦,类似mq,哪个任务先执行完,就把结果放到队列中。
唯一实现类:
ExecutorCompletionService;阻塞队列默认是 LinkedBlockingQueue
二、线程池
为什么要用线程池
∵ 手动创建线程的缺点:
1、不受控,系统资源有限,每个人如果都创建的话,标准不一样,线程疯狂抢占资源.,混乱…
2、开销大,创建一个线程需要调用操作系统内核API,然后操作系统要为线程分配一系列资源,创建个线程啥也不干大概需要1M左右大小。
线程池可以统一管理、控制最大并发数并实现拒绝策略、隔离线程环境;当执行大量异步任务时,线程池里的线程能复用,不用频繁创建和销毁,能够提供好的性能。
Java并发包里的线程池——ThreadPoolExecutor; (接口是ExecutorService)
Spring对线程池的封装——ThreadPoolTaskExecutor
关于线程池核心线程数的设置:
CPU是时间片轮转机制来让线程占用的,也就是说程序表面上是同时进行的,实际上是切换执行的,CPU每个时刻只能由一个线程占用,比如 4核CPU,只能同时跑4个线程。
对于CPU密集型程序(如运算、逻辑判断等,I/O操作可以在短时间完成,但CPU运算比较多)
——最佳线程数量=CPU核数+1,这个1可以理解为替补,如果某个线程因为发生错误或其他原因暂停了,这个线程可以继续工作。
对于I/O密集型(如涉及网络、磁盘、内存等)
——最佳线程数=CPU核心数 * (1/CPU利用率)=CPU核心数 * (1 + (I/O耗时/CPU耗时)),如果几乎都是I/O耗时,可取2N+1(1为替补)
(p.s.线程数不是越多越好,线程上下文切换开销不小)
三、Callable 与 Future
Runnable接口的方法没有返回值;Callable 是泛型接口,可以返回指定类型的结果。
当提交一个Callable 任务后,会同时获得一个Future对象,然后,在主线程某个时刻调用Future对象的get() 方法,就可以获得异步执行的结果。在调用get()时,如果异步任务已经完成,就直接获得结果。如果异步任务还没有完成,那么get()会阻塞,直到任务完成后才返回结果。
四、通过回调方式处理可组合编排任务——CompletableFuture
特点描述:
CompletableFuture是由 Java 8 引入的,在 Java 8之 前一般通过 Future 实现异步,CompletableFuture 对 Future 进行了扩展,可以通过设置回调的方式处理计算结果,同时也支持组合操作,比如步骤1、2、3存在依赖关系,支持对步骤进一步的编排,降低依赖之间的阻塞。
使用:

如上图所示,这里描绘的是一个业务接口的流程,其中包括 CF1\CF2\CF3\CF4\CF5 共5个步骤,并描绘了这些步骤之间的依赖关系,每个步骤可以是一次 RPC 调用、一次数据库操作或者是一次本地方法调用等,在使用 CompletableFuture 进行异步化编程时,图中的每个步骤都会产生一个 CompletableFuture 对象,最终结果也会用一个 CompletableFuture 来进行表示。(只看第一层的话 好像跟 CompletionService 效果差不多… 都可以异步执行批量任务并拿到结果…)
1、零依赖,CompletableFuture 的创建
比如图中所示的 CF1、CF2,可以有以下方式:
// 1、使用 runAsync 或 supplyAsync 发起异步调用
// 线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
CompletableFuture<String> CF1 = CompletableFuture.supplyAsync(() -> {
return "CF1 result";
}, executorService);
// 2、CompletableFuture.completedFuture() 直接创建一个已完成状态的 CompletableFuture<
CompletableFuture<String> CF2 = CompletableFuture.completedFuture("CF2 result");
// 3、先初始化一个未完成的 CompletableFuture
CompletableFuture<String> CF3 = new CompletableFuture<>();
// 然后通过complete()、completeExceptionally(),完成该CompletableFuture
CF3.complete("CF3result");
2、一元依赖,依赖一个 CompletableFuture
比如图中所示的 CF3、CF5,可以用 thenApply、thenAccept、thenCompose 等方法来实现:
// result为CF1的结果
CompletableFuture<String> CF3=CF1.thenApply(result->{
return "CF3result";
});
3、二元依赖:依赖两个 CompletableFuture
比如图中所示的 CF4,这种二元依赖可以通过 thenCombine 等回调来实现:
// result1、result2分别为CF1、CF2的结果
CompletableFuture<String> CF4 = CF1.thenCombine(CF2, (result1, result2) -> {
return "CF4result";
});
4、多元依赖,依赖多个 CompletableFuture
比如图中所示的 CF6,依赖于三个步骤CF3、CF4、CF5,这种多元依赖可以通过 allOf 或 anyOf 方法来实现,区别是当需要多个依赖全部完成时使用allOf,当多个依赖中的任意一个完成即可时使用anyOf:
CompletableFuture<Void> CF6 = CompletableFuture.allOf(CF3, CF4, CF5);
CompletableFuture<String> result = CF6.thenApply(v ->
{
// 这里的 join是完成任务后用来获取结果的,并不会阻塞
// 因为传给 thenApply 的函数都是在 CF3、CF4、CF5 全都完成时才会执行
String result3 = CF3.join();
String result4 = CF4.join();
String result5 = CF5.join();
// 根据 result3、result4、result5组装最终 result
return result3 + result4 + result5;
});
如果只用一层的话,异步执行批量任务并拿到总的结果,参考api里 allOf:
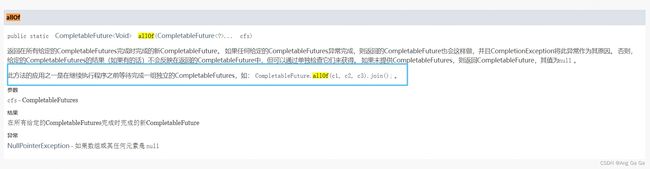
代码示例:
// 任务入参集合
ArrayList<String> paramList = new ArrayList<>();
// 用于汇总所有结果
ArrayList<String> resultList = new ArrayList<>();
CompletableFuture.allOf(
paramList.stream().map(string ->
CompletableFuture.supplyAsync(() ->
// 这里返回了本身,实际上也可以是具体的方法
string,
asyncServiceExecutor)
// thenApply是对结果做简单映射,类似于Stream.map,list->list就是原样往下传递,这里不使用thenApply也行
.thenApply(list -> list)
.whenComplete((result, e) -> {
// 对异常结果的处理
if (e != null) System.out.println("exception");
// 汇总结果
resultList.add(result);
})
).toArray(CompletableFuture[]::new)
// 完成后返回结果值,如果异常完成则抛出(未经检查)异常,相当于一个等待任务完成的动作
).join();
参考文档:
https://dayarch.top/p/how-many-threads-should-be-created.html
https://segmentfault.com/a/1190000023129592?utm_source=sf-similar-article
https://segmentfault.com/a/1190000023587881
https://tech.meituan.com/2022/05/12/principles-and-practices-of-completablefuture.html