初识C++之模板进阶与继承
一、模板进阶
非类型模板参数
在模板中,模板参数分为类型形参和非类型形参。
类型形参就是我们经常用的,出现在模板的参数列表中,跟在class或typename之后的参数类型名称。
而非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用
我们来看下面的代码:
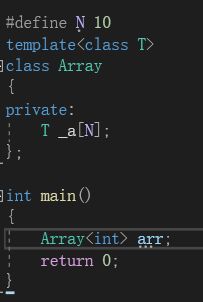
在上图中,我们写了一个Array类,里面的成员变量是一个数组。可以看到,它的数组大小是用N来控制的,是一个静态数组。当我们需要改变这个数组的大小的时候,就必须要去改变宏中定义的值。但是,如果我们现在需要两个Array类构建的数组,一个容量是10,另一个容量是100,此时宏就无法满足我们的需求。为了解决这种情况,就有了“非类型模板参数”。
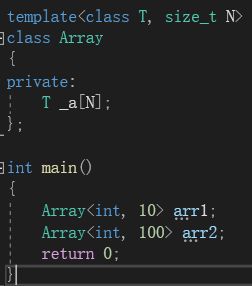
在上图中,"T"是类型形参,“N”就是非类型形参。可以看到,通过传非类型形参的方式,就可以控制开辟的数组容量。当然,我们也可以给N加上缺省值。
虽然非类型形参是用常量当参数,但还是有要求的。就是非类型形参只能传入整型。浮点型、类对象、字符串都是允许作为参数的。
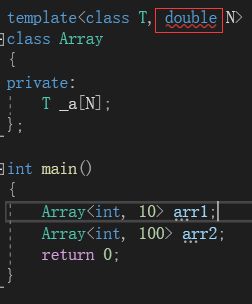
同时,非类型的模板参数必须要在编译期流能确认结果。传入的值不能是一个变量:
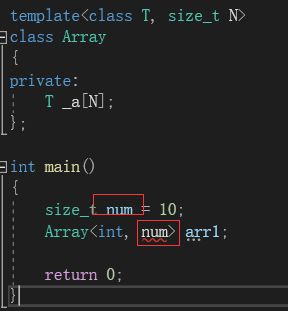
在我们的库中,也存在一个array类,就使用了非类型参数。上面我们都是在类模板中使用。如果我们在函数模板中使用,就需要将函数模板显式实例化:
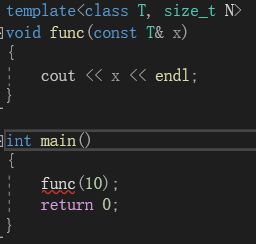
如果我们用隐式实例化,就会出现报错。所以如果在函数模板中使用了非类型参数,就必须要显式实例化:
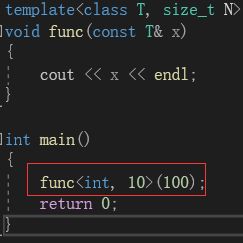
模板特化
在通常情况下,使用模板可以实现一些与类型无关的代码。但对于一些特殊类型的可能会得到一些错误的结果,需要进行特殊处理。
2.1函数模板
例如在以下的代码中:
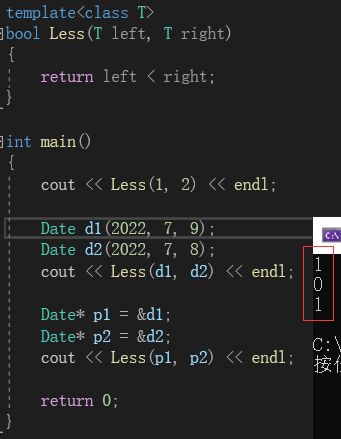
我们提前准备了一个日期类。在这个日期类中提供了“<”重载以进行比较。但是我们运行上面的程序可以看到,虽然第一个和第二个比较都是正确的,但是第三个的比较结果确实错误的。原因很简单,我们这里传入的是p1和p2,比较的是指针大小。我们可以通过解引用的方式解决。但是,如果在这里,我们不想解引用,就想传指针进行比较呢?这个时候就需要针对某些类型进行特殊处理。以上图为例,我们要特殊处理的类型就是“Date* ”。此时,就可以用“模板特化”。
2.1.1函数模板特化使用
模板特化的使用方法也很简单:1.要有一个基础的函数模板;2.关键字template后面接一对空的<>;3.函数名后跟一对<>,尖括号中为需要特化的类型;4.函数形参表必须要和模板函数的基础参数类型完全相同,否则可能出现报错
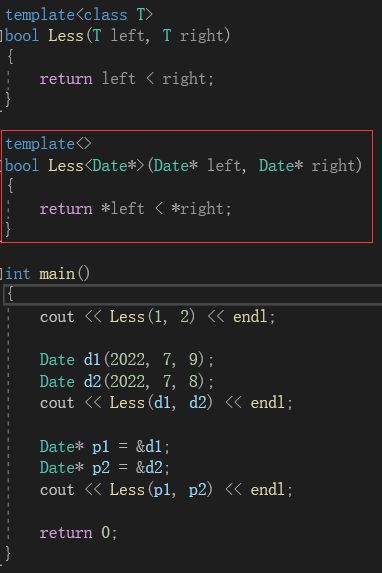
模板特化的模板中,不存在参数。当我们遇到Date*时,我们不希望用left < right比较,而是用*left < *right比较。
当我们再次运行该程序时,其他类型传入时就会去匹配Less(T left, T right)。但是当我们传入Date*时,编译器就会在匹配类模板之前,去下面看有没有针对该类型的模板特化,如果有,就去匹配模板特化:

2.2类模板
如果我们有以下代码:
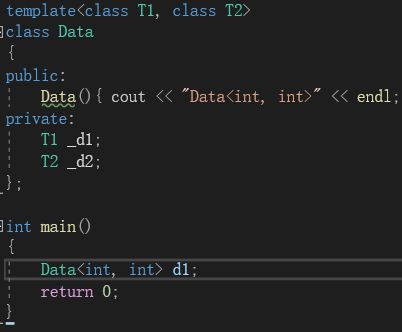
我们现在想根据传入的某些类型,如double类型,进行特殊化处理,也可以使用模板特化:

类模板的特化和函数模板差不多。都要在template后的接一个空的<>。不同的是,类模板特化的特化类型要用<>写在类名后,与原模板的参数一一对应;并且类模板特化中不需要写成员变量。
2.3特化类型
特化一共有两种类型,全特化和半特化(偏特化)。
2.3.1全特化
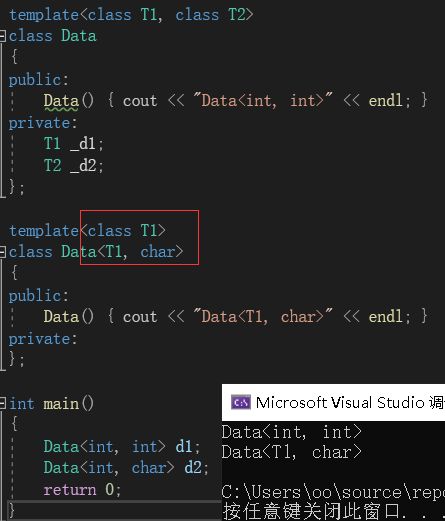
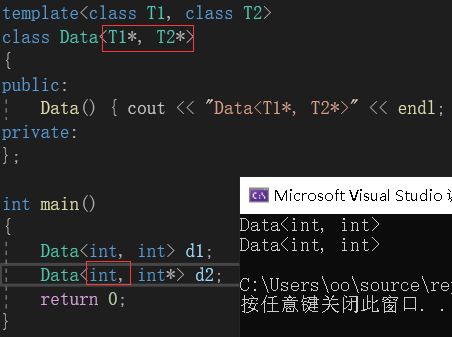
全特化,即模板参数全部都进行特化。如下图:
该图中的Data类的两个参数都进行了特化,这就是全特化。
2.3.2半特化(偏特化)
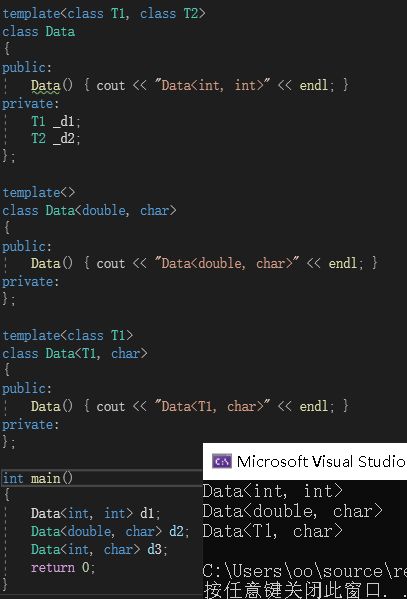
半特化,也叫做偏特化。意思是可以仅对部分参数进行特化:
上图中就是一个半特化。我们只特化了第二个参数。在这种情况下,函数进入类模板调用函数之前,会下去下面找有没有针对对应参数的模板特化,有则调用对应的模板特化。因此,这里d2调用的就是模板特化而非原模板。
半特化时,我们必须要在template后面的<>中,填入未被特化的参数。
如果全特化和半特化同时存在,它的匹配原则是:全特化 > 半特化 > 原模板。
半特化还有一种使用方式,用于参数类型的进一步限制:
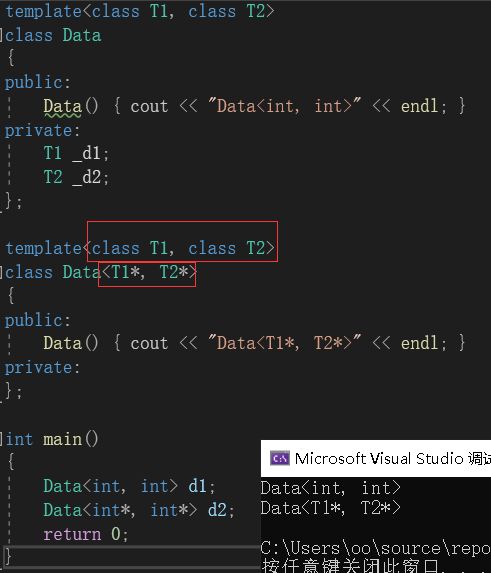
在上图中也是用了半特化。但是这种半特化是一种比较宽泛的半特化。上图中只要传入的参数是指针,就会进行半特化。当然,传入的参数必须满足半特化模板中的所有参数条件。如果传入的参数有一个不是指针,就不会走特化:
模板的优缺点
优点:
(1)模板复用了代码,节省资源,更快迭代开发,C++的标准模板库(STL)因此而产生
(2)曾庆了代码的灵活性
缺点:
(1)模板会导致代码膨胀问题,也会导致编译时间变长
(2)出现模板编译错误时,错误信息非常凌乱,不易定位错误
二、继承
继承的概念
继承是C++三大特性之一。继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能。这样产生的新的类,叫做派生类(子类)。被继承的类叫做基类(父类)。继承呈现了面向对象程序设计的层级结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,而继承则是类设计层次的复用。
我们以前写代码时,假设我们遇到需要频繁交换变量的情况,我们就会把这个交换方式提取出来,重新写一个交换函数。当遇到需要交换变量的情况,就调用该函数。这种调用函数进行复用的方式就是函数复用。
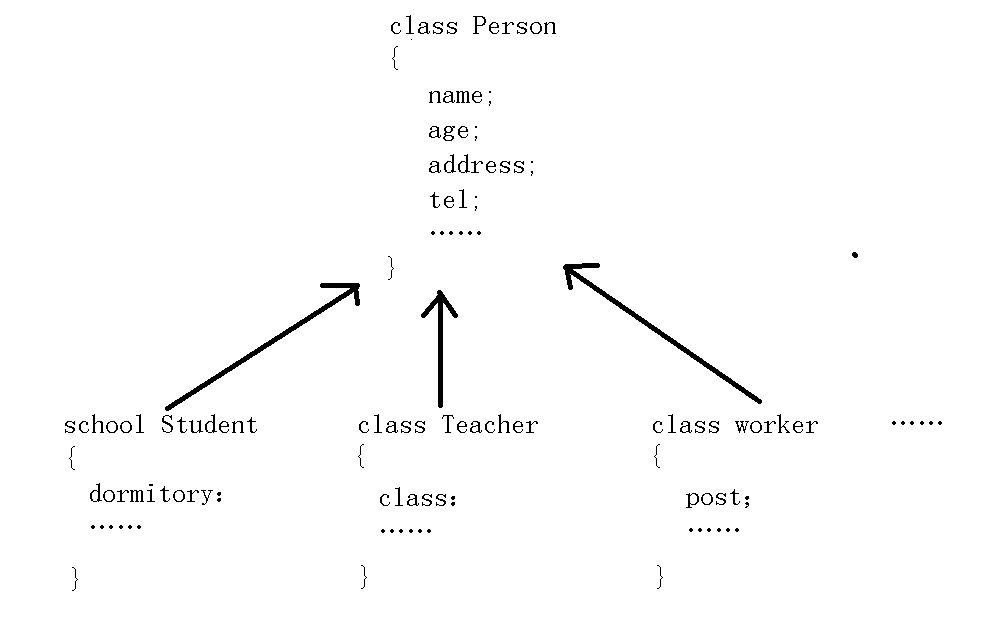
现在我们学习了类,假设我们现在要设计一个学校人员管理系统,那我们在设计时就会设计学生、教师、职工等各类角色。每个角色都需要设计一个类,但是,这些类中可能有许多重复的成员变量,如姓名、年龄、家庭住址、电话等。此时每个类里面都有这些变量,就都需要为他们单独写一份对应的修改或获取值的函数。

这样就可能导致我们写出了许多相同的代码。但是我们又不能不写,因为这些类里面又有许多不同的成员变量,如学生有宿舍、老师有教的班级、职工有自己的工作岗位等等内容。
既然我们这些类里面都有许多相同的成员变量,并且实现方法也是一样的。那我们能不能像函数那样,将这些相同的变量和需要的函数都提取出来放到一个类里面,然后将这些类中独有的变量放在自己的类里面呢?此时,我们就可以用“继承”来达到这一目的:
在使用继承时,我们需要在子类的类名后面带上继承的基类名字和继承方式:
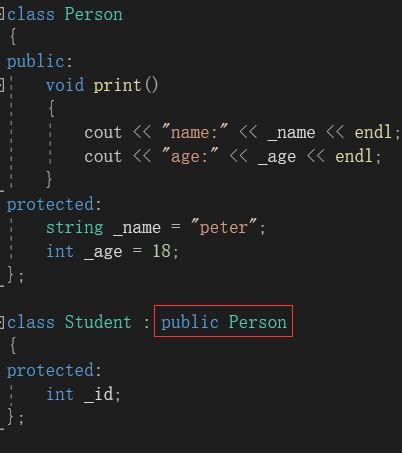
在上图中,Stuent类以公有方式继承了基类Person。然后我们写出以下代码:
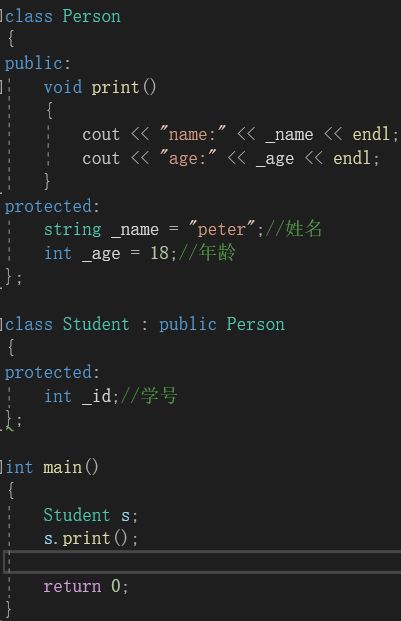
在上图中,我们写了Student类,继承了Person类。我们运行该程序:

在上面的程序中,我们并没有写_name和_age成员变量,也没有写print()函数。但是却可以调用他们。这就是继承在发挥作用,使派生类Student可以使用基类Person里面的成员变量和函数。
继承定义
2.1定义格式

上图中就是继承的书写格式。Person基类,指被继承的类;public是继承方式;Student是派生类,指需要继承的类。派生类和基类,我们也叫做子类和父类。
2.2继承关系和访问限定符
继承关系和访问限定符都有三种。分别是public、protected、private。

我们之前说过,protected和private在类外访问时并没有区别。它们的区别主要就是体现在继承上。
2.3继承基类成员的访问方式
上面说过,继承关系和访问限定符各有三种。因此继承关系和访问限定符组合起来就有9种访问方式。

我们说了,继承会使派生类继承基类的成员变量和成员函数。但是这些继承其实也是有条件限制的。如上图。
在这里,protected和private修饰的基类成员就有了区别。基类的protected成员可以被派生类直接访问和使用,不能被从类外直接访问使用。但是基类的privateed成员哪怕是派生类也无法直接访问和使用。
举个例子。把基类看成父亲,把派生类看成儿子。整个类看做你父亲买的一套房。派生类继承基类就好比你已经成年了在外面自己买了套房,但是你逢年过节还是会回父亲家玩。在这父亲的房里,public成员就是客厅中摆的各种水果零食,你和其他客人都可以随意使用。protected成员就是你父亲的卧室里面放的各类用品。你作为家庭成员,可以随意使用查看。但是外来的客人不是你们的家庭成员,没有权限查看卧室里面的物品;而private就是你父亲用自己的私房钱买的私人物品,哪怕你是他的儿子,他都不会允许你直接使用和查看这些东西,只能通过基类提供的函数间接访问。
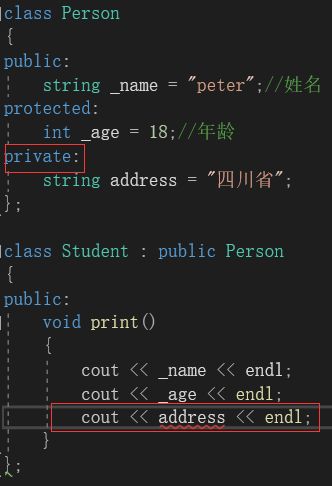
因此,基类的private成员虽然也在派生类中,但是在派生类中是不能被访问的。如果基类成员不想在类外直接被访问,但需要在派生类中能被直接访问,就定义为protected。
了解了访问限定符后,我们就再来看看继承方式。这三种继承方式也很好理解。继承的权限只能缩小,不能放大。如我们用public继承,全部成员就按照基类的访问限定符方式继承,private成员也会被继承,但是我们在派生类里面是看不见的,无法直接访问;protected继承就是将基类的public和protected成员都视为protected成员;private继承就是也是将其都视为private成员。
虽然这里有9种访问方式,但是我们使用最多的都是public继承。protected和private继承很少使用。同时在实际中,我们也不提倡使用protected/private继承,这两种继承方式继承的类成员都只能在派生类中使用,可扩展维护性不强。基类中的成员也一般是设置为public和protected,很少设置为private。
还有一点要注意,那就是其实在派生类中,我们是可以不写继承方式。如果我们不写,class默认private继承,struct默认public继承。
基类和派生类的赋值转换
派生类对象可以赋值给基类的对象/指针和引用。这个过程一般被叫做切片或切割。寓意为把派生类中基类的那部分切割出来赋值给基类。但是基类对象不能给派生类对象赋值。
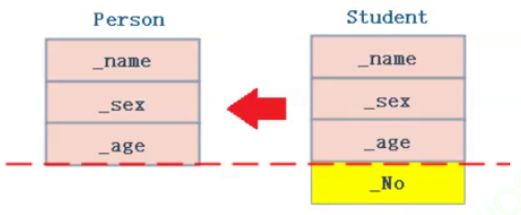
注意,切割的过程中,是没有类型转换(意味着切割转换中不会产生临时拷贝)的。这就意味着,我们可以直接使用用基类来引用派生类对象:
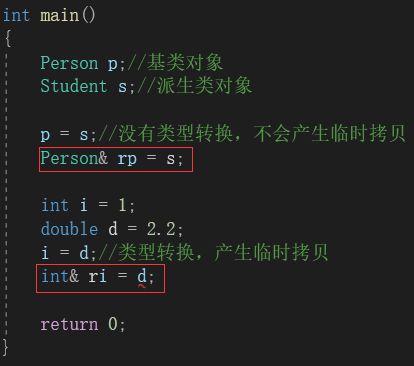
在上图中,我们可以使用Person& rp = s;来使rp成为s的别名。但是却不能让int类型的ri成为d引用。原因就在于ri和d的类型不同,会类型转换产生临时拷贝,这里的引用实际上成为了临时拷贝的引用,导致报错。
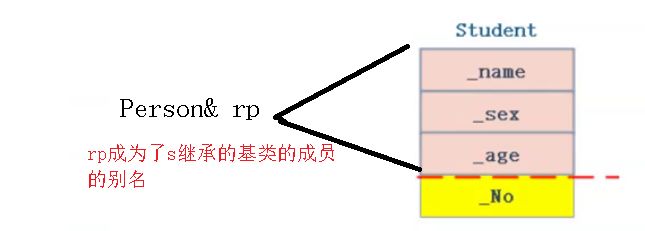
当然,不仅可以用引用,也可以让父类对象指针指向派生类:
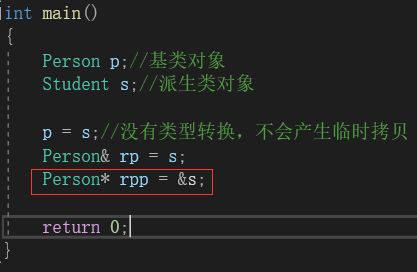
但是我们要注意,在当前,只允许向上转换,不允许向下转换。即只允许派生类给基类传值,不允许基类给派生类传值。
继承中的作用域
在继承体系中,基类和派生类都有其独立的作用域。因为在同一个作用域中,不能出现同名变量。但是在不同的作用域中就可以出现同名变量。
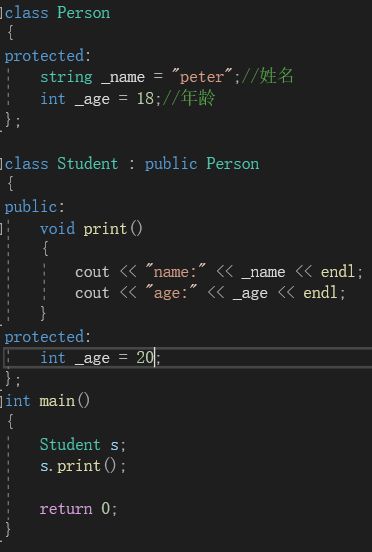
在上图中,基类Person和派生类Student都存在一个_age变量。此时,Student类中有一个print()函数。如果我们调用该函数,那么它优先会打印Student中的_age,因为编译器采用的是“就进原则”,print()调用时它会先去自己的作用域找_age,找不到才会到基类的作用域去找:
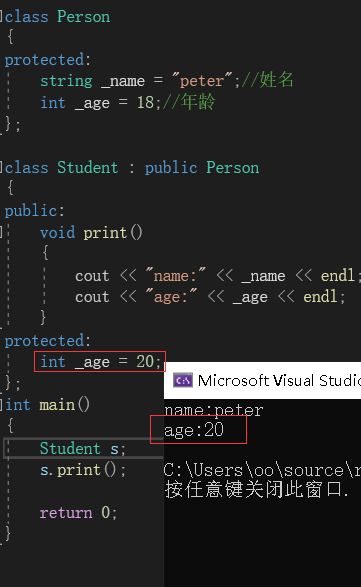
因此,如果我们将print()函数放在基类中,它就会优先选择基类中的_age。这里就不再演示。此时该print()函数在派生类中,如果我们就想让它打印基类中的_age,在_age前加上作用域限定即可:

上述子类和父类有同名成员,子类成员屏蔽父类对同名成员的直接访问,这种情况就叫做“隐藏”,也叫做“重定义”。
在上述的代码中,仅仅只是同名成员变量导致的隐藏。而同名成员函数也会导致隐藏。

在上图中,A类和B类中都有一个同名函数func()。此时就构成了隐藏。但是我们要注意,成员函数的隐藏,只需要函数名相同就构成隐藏:

在上图中,我们在基类和派生类中写了一个同名不同参的函数func()。但是当我们调用时,却出现了报错。原因就是此时基类和派生类的func()同名,导致基类A中的func()被派生类B隐藏,无法通过B进行访问。
因此,对于基类和派生类中的成员函数,只要函数名相同,哪怕你的返回值和参数都不同,也一样会构成隐藏。如果在基类的函数被隐藏的情况下要访问它的函数成员,只需要在访问时加上作用域限定即可。
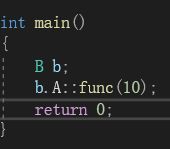
由于基类和派生类的同名成员后构成隐藏,可能导致我们在某些情况下访问到错误的成员。因此,在实际的继承体系中,最好不要定义同名的成员。
继承中的默认成员函数
从实际上看,基类的默认成员函数我们该怎么写还是得怎么写,和我们以前写一个普通的类没有任何区别。但是派生类的默认成员函数却有所不同了。

上图中有一个基类Person,里面提前写好了Person类的构造函数、拷贝构造、运算符=重载和析构函数。
5.1构造函数
依赖上面的Person类,我们写出如下程序:
这里写了一个派生类Student,里面什么都没有写。
运行该程序,我们可以看到如下结果:
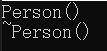
很明显,这里调用了Person类的构造函数。这就很奇怪了,明明在Student类中我们什么都没有写,那为什么这里会调用Person类的构造函数呢?原因派生类中的构造函数构造方式有关。在派生类中,基类成员调用基类的构造函数完成初始化,派生类自己的原生成员调用自己的构造函数。
因此,虽然我们没有在Student类里面写构造函数,但是它作为Person的派生类,内部已经有了基类的成员,此时就需要调用基类的构造函数进行构造。如果父类没有默认构造函数,就会报错。
如果我们在派生类里面自己写构造函数,我们不能自己去初始化父类成员,必须调用父类的构造函数:
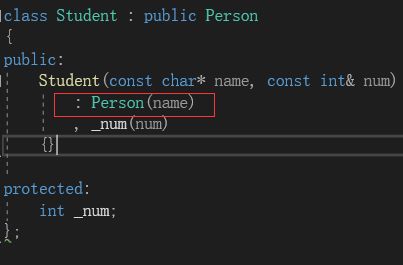
注意在,在继承中,一个子类如果存在多个父类时,它的构造函数需要调用它的多个父类的构造函数进行初始化,而初始化的顺序是按照子类的继承声明中的顺序来初始化的,谁先声明就先初始化谁,与初始化列表无关
5.2拷贝构造函数
拷贝构造函数和拷贝构造函数一样,如果一个派生类对象需要拷贝构造,它内部基类的成员调基类的拷贝构造,自己的成员调自己拷贝构造函数:
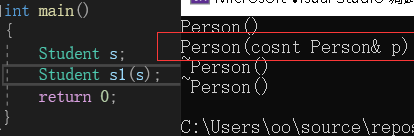
派生类的拷贝构造自己写时,也需要显示调基类的拷贝构造:
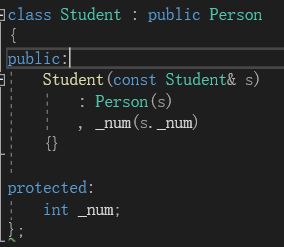
传入基类的类对象直接传其s本身就可以了,因为虽然s是Student类的整体对象,但是传过去给基类中的成员赋值时会发生切割。
注意,如果在基类和派生类中都写了运算符重载,在需要调用基类的运算符重载时,需要加上作用域限定。因为运算符重载的函数名就是运算符本身,基类和派生类中都有相同的运算符重载会导致基类的运算符重载被隐藏。
例如,我们在派生类中写一个运算符“=”重载:
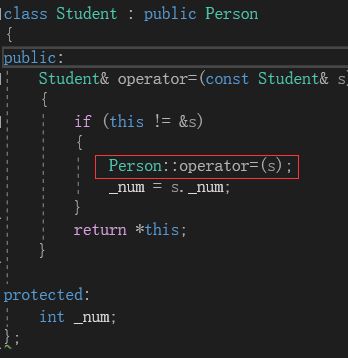
在这个运算符重载中,需要调用基类的运算符重载来完成对基类成员的赋值。这里如果不加作用域限定,就会一直调自己,导致栈溢出。
5.3析构函数
析构函数与构造和拷贝构造函数就有所不同。
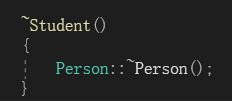
第一点不同:子类析构函数和父类析构函数构成隐藏关系。我们写以下代码:

此时该程序报错,原因就是子类和父类的析构构成隐藏,因此无法调用父类的析构(这是由于多态的需需求,所有的析构函数都会被视为destructor())。要解决很简单,加上作用域限定即可:
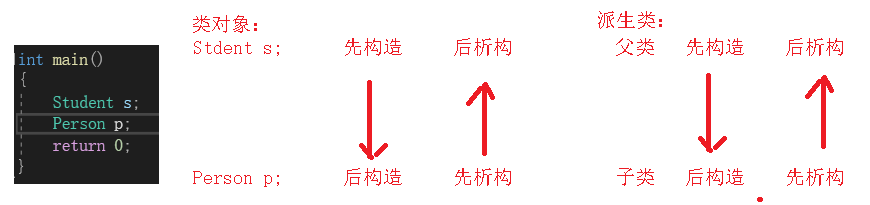
第二点不同:子类先析构,父类再析构。因此子类的析构函数中不再需要显式调用父类的析构。我们运行程序:

可以看到,打印的结果显示,~Student()在中间,这就表示析构时先调用了子类的析构。在~student()下面还打印了一个~Person(),这就表示在子类析构完成后,又调用了父类的析构。此时就导致了父类进行了两次析构。如果析构函数会释放空间,就会出现报错。因此,在子类的析构函数中,我们不需要显式调用父类的析构函数。
在构造类对象时,一般都是先构造的对线后析构,后构造的对象先析构。而要创建一个派生类对象,在其构造时会先调用父类的进行构造,然后再构造自己的。继承中为了和类对象的构造析构顺序保持一致,便采用了先构造的父类后析构,后构造的子类的先析构的析构顺序。
了解知识
6.1继承与友元
在继承中,友元关系不能继承,也就是说基类友元不能访问子类私有保护成员。
6.2继承与静态成员
如果一个基类定义了static静态成员,则整个继承体系中都只有一个该静态成员。无论派生出多少个子类,都只有一个该成员。简单来讲就是,基类的static静态成员所有派生类共用。
一个子类继承父类,在实例化时,是该子类的实例化的空间中存有一份单独的父类实例化。如果这个父类中有static静态成员,该静态成员不属于某个对象,而是属于整个类和所有派生类
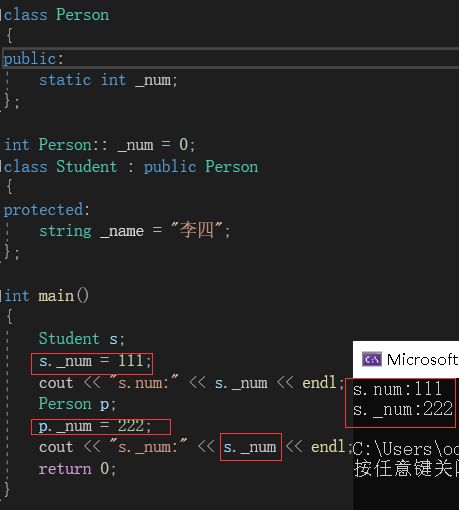
从上面的程序中可以看到,我们修改p._num时,导致s._num的值也被修改。
对象访问方式不同:
假设现在有以下程序:
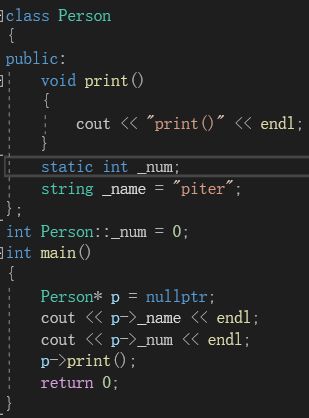
在该程序中,有一个Person指针p,指向nullptr。然后我们用这个指针去访问对象里面里的成员和函数。在这里,大家可能三个访问都会报错。但是只有访问_name时会报错:

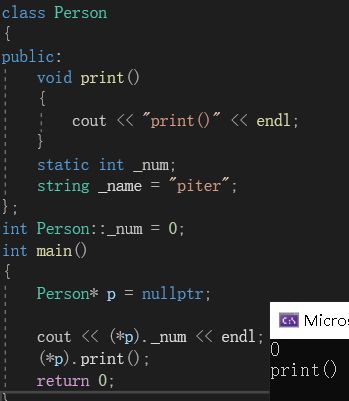
可以看到,空指针p访问_num和print()函数都可以正常运行。原因就是,_num是static静态成员,print()是函数,它们都不存储在对象中。因此用p访问时,p不会进行解引用,而是直接去代码区和常量区寻找,因此不会报错。而_name存储在对象中,因此会发生解引用导致报错。当然,如果print()函数访问了_name,也会报错。
同样的,如果我们把“p->”换成(*p).也不会报错。道理一样的,此处不会解引用。
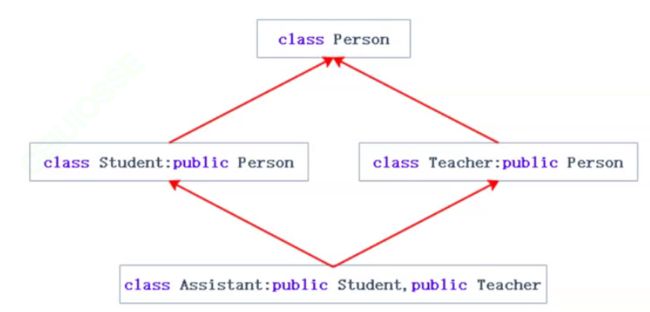
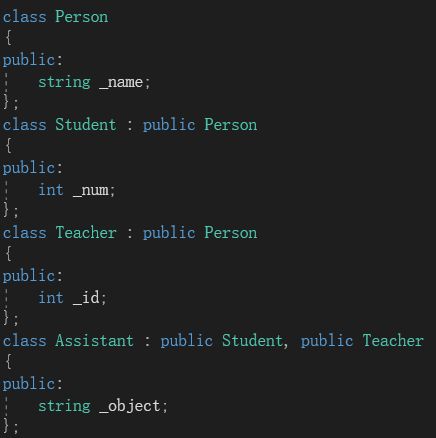
多继承
在上面,讲的全部都是单继承的情况。C++其实还允许多继承。单继承,顾名思义就是一个子类只有一个直接父类,这种继承就称为单继承。

在上图中,虽然有两个继承关系,但是每个子类都只有一个直接父类,因此属于单继承。
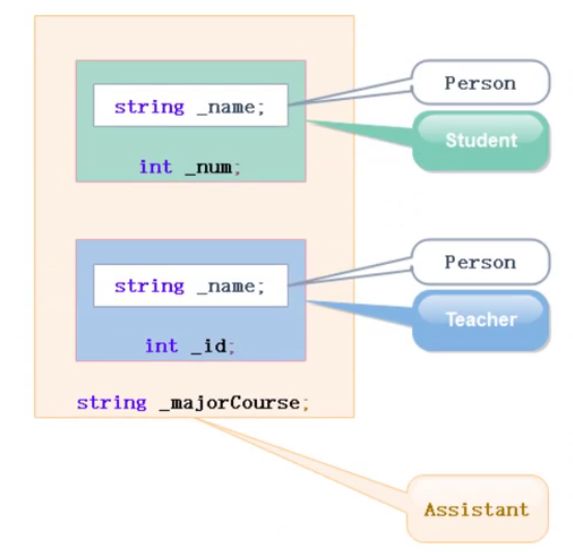
多继承则指的是一个子类有两个火两个以上的直接父类:

如上图,类Assistant有Student和Teacher两个直接父类,此时就称这种继承关系为多继承。
7.1菱形继承
多继承很好理解,此处我们主要讲的是多继承中的一种特殊情况,菱形继承:
在使用多继承时,我们一般很不推荐出现菱形继承,因为菱形继承可能会导致数据冗余和二义性的问题。
数据冗余很好理解,如上图,Assistant中有两份Person,此时就会出现数据重复,导致数据冗余。二义性也很好理解,既然你的Assistant子类中有了两份Person,当需要去访问该子类中的继承下来的Person的数据时,就会导致编译器不知道访问哪份数据,出现报错。
假设现在有以上菱形继承。写一个程序运行:

此时就出现了报错,报错中提示有两个基类Person,编译器找不到该访问哪一个。此时就是二义性问题。要解决二义性很简单,可以指定要访问的作用域。要访问Teacher类中的Person时就加上“Teacher::”,Student类也是如此。但是这样也仅仅只是解决了二义性问题,但并没有彻底解决问题。
7.2虚继承
为了彻底解决二义性和数据冗余,就可以在菱形继承中使用虚继承。
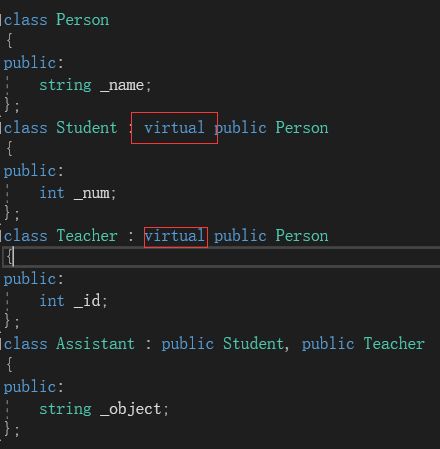
要使用虚继承,就需要使用“virtual”关键字。注意,在菱形继承中使用虚继承时,是在菱形继承的腰部使用,如下图:

使用方法也很简单,就是给腰部的子类中的继承方式前面加上virtual关键字:
使用了虚继承后,就只会生成一份父类的数据。即最高等级下的直接子类和间接子类都使用一份数据:
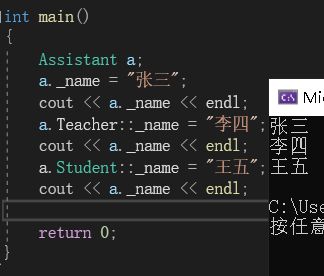
如图,在上图中,只创建了一个Assistant类,然后分别修改三个作用域中的_name,然后打印同一个a_name。此时每次修改都会导致a_name被修改。
7.3虚继承对菱形继承的改变
现在写出如下代码:

上图中是没有使用虚拟继承的普通菱形继承。然后再写下如下测试用例:

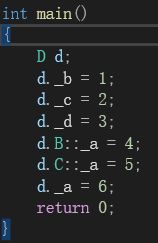
我们调出内存窗口,然后进行调试:当我们调试完后,就可以得到如下结果:
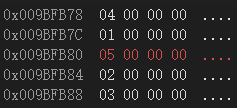
这样看可能不太容易看懂,将这里的结果和代码拿出来比对:
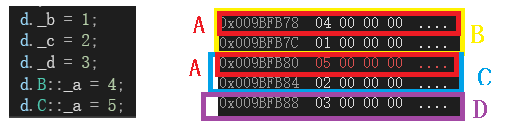
提取出来后进行比对,就可以发现,在内存中,最上面的两个数据是类B的数据,中间的两个数据是类C的数据,最后一个数据是类D的数据。而B和C继承的A的数据都在它们中。这就是一个简单的普通菱形继承的内存上的模型。
看了普通的菱形继承模型后,给B和C加上virtual修饰形成虚继承:
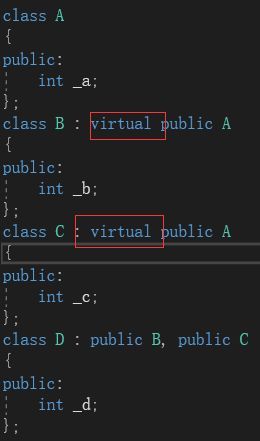
再次运行以下测试代码并查看它的内存窗口:
可以看到,当使用了虚继承后,内存窗口上就出现了明显的变化。

同样将内存窗口与测试代码相比对:

在使用了虚继承后,父类A的数据不再放到B和C中,而是放到了这几个类的数据的最下面,即B和C外。然后可以看到,之前放A类数据的位置如今存放的却是两个不同的地址。那这两个地址里面存放的究竟是什么呢?再打开一个内存窗口,查看这两个地址存放的内容并进行比对:
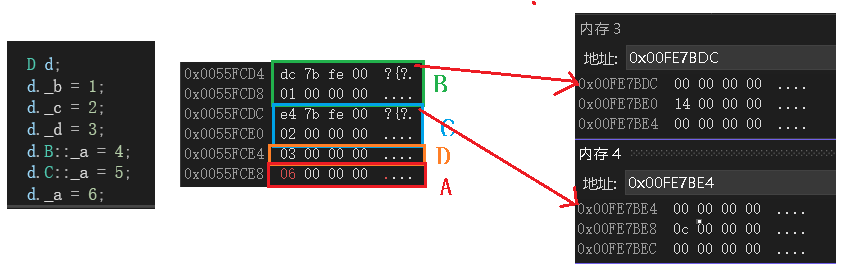
这里就很奇怪了,这两个地址中指向的位置保存的数据是0。但是在它们的下面又保存了一份数据,上面分别是14和0c。这两个数据有什么意义呢?再看这个之前,我们看看内存窗口1中保存的数据的地址与A类的地址的距离。此处只用看最后两位,第一个数据的地址是d4,第二个数据的地址是e4,A类的地址是dc。此时e8 - d4 = 14;e8 - dc = 0e。现在就很明确了,在这两个地址存的数据下一个地址中所存的数据,刚好是该子类到A类的地址的差值。因此,这里所存的数据就是子类距离虚基类的偏移量。因此子类中存的这两个数据的目的也很明确了,就是用于让子类找到虚基类。
有人可能觉得子类为什么需要去找虚基类呢?虚基类就在子类的下方啊。虽然我们调出内存窗口,用肉眼就可以看到虚基类的位置,但是编译器并不能看到虚基类的位置。需要存储一个偏移量来找到虚基类。
比如写如下指针:

此时它们的指针类型不同,但是指向同一个位置,存在切片查找。而这两个指针到达A类的距离都不同,因此需要使用偏移量来提供寻址。
也因为虚继承不是直接用指针找,而是用指针找到一块空间,拿到该空间内的偏移量,然后再用偏移量加上地址找到虚基类的位置,就导致使用虚基类会产生效率损失。
总的来说,多继承可以看成是C++的设计缺陷之一,因此很多后来的语言,如java都不再允许多继承。就是因为多继承可能导致菱形继承,进而出现各种问题。因此,在实际中,非常不推荐写代码时出现菱形继承。
并且测试代码中修改了三次_a,分别为4,5,6。但是打开内存窗口后却只能看到最后一次修改的6。这也就证明了使用了虚继承后,只有一份A类数据。
继承与组合
public继承是一种“is-a”的关系,即每个派生类都可以看成一个基类对象。而组合是一种“has-a”的关系。假设B组合了A,那么每个B对象中都有一个A对象。
组合,简单来讲,就是让A类成为B类的一个成员。

在上图中,X和Y就是继承关系,X是Y的父类。而A和B则是组合,B中包含了一个A对象。
在本质上,继承和组合都是在复用。但是它们之间还是存在一定的不同的。
首先,在继承中,子类可以直接使用父类的保护成员;在组合中,B对象是无法直接使用A对象的保护成员的。简单来讲,就是继承的访问权限比组合的大。
在一般情况下,为了区分继承和组合,将继承称为白盒复用,组合称为黑盒复用。白和黑的区别就在于能否看见里面的内容。继承会将父类的所有成员都放入到子类中,private成员也会放入,只是在子类中不可见而已。而组合仅仅是在B类中创建一个A类对象。
在实际使用中,如果碰到既可以使用继承,也可以使用组合的情况,最好使用组合。因为组合的耦合度低,而继承的耦合度高。因为继承中的子类可以直接访问父类的保护和公有成员,而组合中仅仅只能直接访问公有成员。如果此时有80个保护成员,20个公有成员。使用继承,父类的任何一个成员改变都可能影响到子类。而组合则仅仅在A类修改20个公有成员时才可能影响B类。