Transformer模型
目录
1. 概述
2. Model Architecture
2.1 自回归
2.2 编码器与解码器
2.3 Attention
2.4 Attention—mask
2.5 Multi-Head Attention
2.6 自注意力使用
2.7 point-wise feed forward network
2.8 embeddings
2.9 positional Encoding
1. 概述
之前的模型,如RNN等,需要按时序做运算,对与并行设备能够减少运算时间这一方法并不能运用得很好,比如ht需要由之前ht-1的隐藏状态(包含历史信息)来完善,但如果序列很长的话,以往的历史信息很容易被丢失。
而Transformer模型中的attention可以进行并行运算。Multi-Head-Attention多头注意力机制可以模拟卷积神经网络多输出通道的一个效果。
文章选图来自:Attention Is All You Need
地址:https://arxiv.org/abs/1706.03762
2. Model Architecture
2.1 自回归
编码器将句子中词的表示(x1,...,xn)变为对应的词向量z=(z1,...,zn),解码器拿到编码器的输出z,生成一个长为m的序列(n与m可以是不一样长的,比如中英翻译时句子可能是不一样长的)。auto-regressive:编码器可以看到完整的句子,但是在解码时只能一个一个的生成。z生成(y1,...,ym),在生成yt时,可以将y1到yt-1全都拿到,即在过去时候的输出可以作为当前时刻的输入。
2.2 编码器与解码器
编码器:
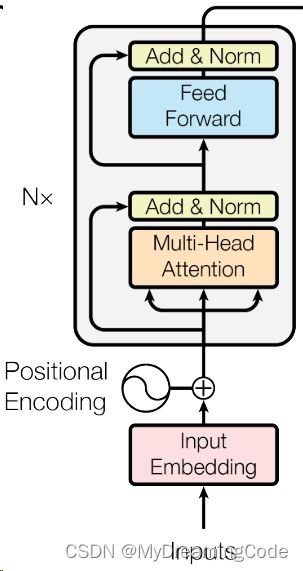
解码器:
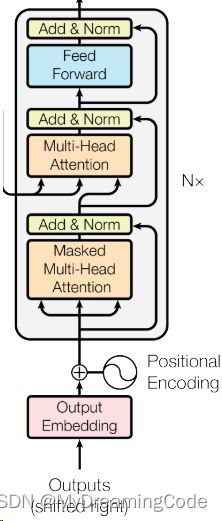
在解码器做预测时,不应该看到之后的那些时刻的输出。而在注意力机制中,每一次都能看到完整的输入,所以需要避免这个情况的发生。即在解码器训练的时候,在预测第t个时刻的输出时,不应该看到t时刻以后的那些输入。可以用一个带掩码(masked)的注意力机制,保证训练和预测时候的行为是一致的。
2.3 Attention
value、key与query
output是value的加权和。对于每一个value的权重,是这个value对应的key与查询query的相似度算来的。(权重等价于query和你对应的key的那个相似度,相似度越大权重越大)
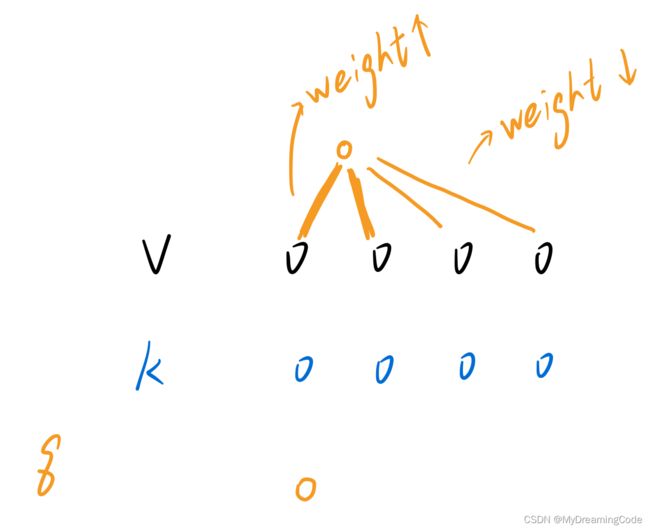
注意:不同相似函数会导致不一样的注意力版本。
Transformer中的注意力机制:
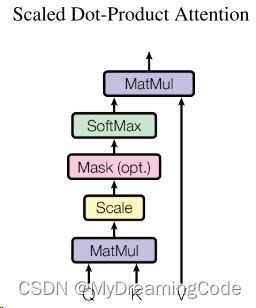
将query与每个key做内积作为相似度,内积值越大,表示相似度越高。(假设:给一个query,再给n个key value pair,则query会和每个key做内积,算出n个值,再放入softmax得到n个非负且加起来为1的一个权重,将权重作用在value上得到输出)
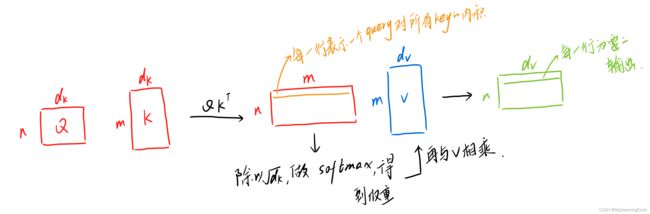
2.4 Attention—mask
对于第t时间的qt即query,在做计算时应只看k1,...,kt-1,不看kt及之后的。但是计算也可以算,我们加入mask,即对于qt和kt和之后计算的值换成一个非常大的负数,在softmax出来后对应的那些权重都会变成0。实现只用到v1,...,vt-1对应权重的效果。
2.5 Multi-Head Attention
将query、key、value投影到一个低维,再做h次的注意力函数,将每一个函数的输出并在一起,再投影回来,可以得到最终的输出。
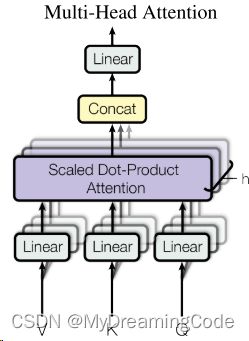
V、K、Q进入线性层(投影到比较低的维度),放入Scaled Dot-Product Attention中做h次(多头)运算并得到h个输出,将这些向量合并在一起,最后做一次线性投影。
使用多头注意力机制的作用:投影的参数可以学习,去匹配不同模式需要的相似函数。类似卷积神经网络的多输出通道。

将不同头的输出结果concat起来,投影到![]() 中。对每一个头,把q、k、v通过一个不同的可以学习的
中。对每一个头,把q、k、v通过一个不同的可以学习的![]() 、
、![]() 、
、![]() 投影到低维上面,再做注意力函数。
投影到低维上面,再做注意力函数。
2.6 自注意力使用
attention是如何在编码器和解码器之间传递信息时起到作用?
回答:去有效的把编码器的输出根据我们想要的东西给拎出来。即在解码器时输入的不一样,会根据当前的向量去在编码器的输出里面挑选我们感兴趣的东西。

2.7 point-wise feed forward network
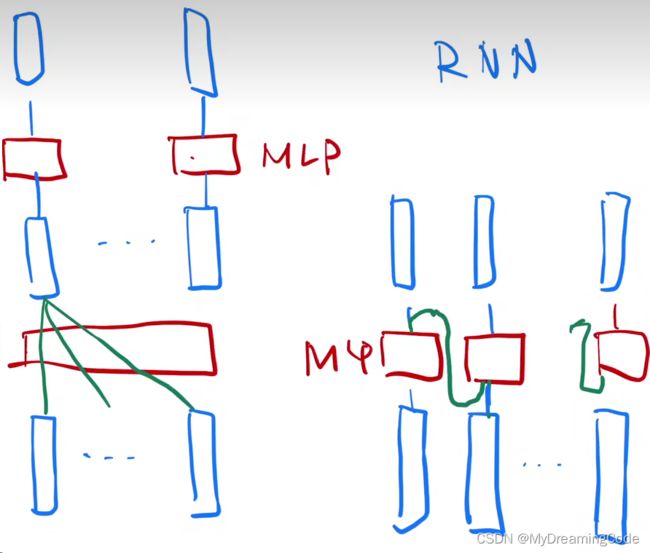
在我们输入的序列里,每一个词对应一个点。把一个MLP(多层感知器)对每一个词作用一次,做一个语义空间的转换。
下图是b站up主:跟李沐学AI
Transformer与RNN对于序列信息的使用(左Transformer 右RNN):
2.8 embeddings
由于输入是一个个词,需要将其映射为一个向量。embedding可以给任何一个词,学习一个长为d的向量来表示。编码器需要embedding,解码器的输入也需要embedding,在softmax前面的线性也需要embedding,且这三个embedding是一样的权重。
2.9 positional Encoding
由于attention不会有时序信息,则在处理时序数据时需要把时序信息加进来。例如:RNN是将上一个时刻的输出作为下一个时刻的输入来传递历史信息。attention的做法是在输入里面加入时序信息,比如一个词在位置i,将i这个位置的数字加到输入里面(即将词在句子中的位置也放入输入里)。