CoRL 2023 获奖论文公布,manipulation、强化学习等主题成热门
今年大模型及具身智能领域有了非常多的突破性进展,作为机器人学与机器学习交叉领域的全球顶级学术会议之一,CoRL也得到了更多的关注。
CoRL 是面向机器人学习的顶会,涵盖机器人学、机器学习和控制等多个主题,包括理论与应用。今年的CoRL 2023共有199 篇论文入选,热门主题包括控制、强化学习等。大会已经于上周11 月 6 日- 9 日在美国亚特兰大举行,在本次大会上,公布了最佳论文奖、最佳学生论文奖、最佳系统论文奖等奖项。
下面我们一起起来看看CoRL 2023的获奖论文详情:
PS:除了今年的获奖论文,我也整理了去年CoRL 2022的获奖论文,有想法发顶会的同学建议都看看哦。
需要的全部论文及源码同学看文末
CoRL 2023
最佳论文奖
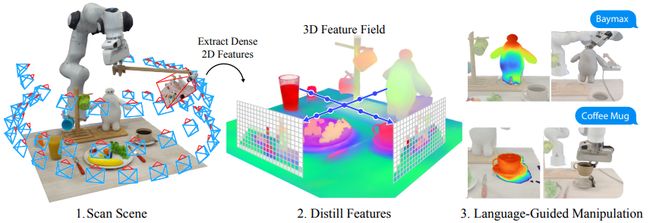
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
标题:蒸馏特征场实现少样本语言引导操作
作者:William Shen, Ge Yang, Alan Yu, Jensen Wong, Leslie Pack Kaelbling, Phillip Isola
内容:本研究通过利用蒸馏特征场,将准确的3D几何与2D基础模型中的丰富语义相结合,填补了机器人操作中2D到3D的空白。作者提出了一种用于6自由度抓取和放置的少样本学习方法,利用这些强大的空间和语义先验知识实现对未见过物体的野外泛化。通过从视觉语言模型CLIP中提取的特征,作者展示了一种通过自由文本自然语言指定新对象进行操作的方法,并证明了其能够泛化到未见过的表达和新类别的物体上。
最佳学生论文奖
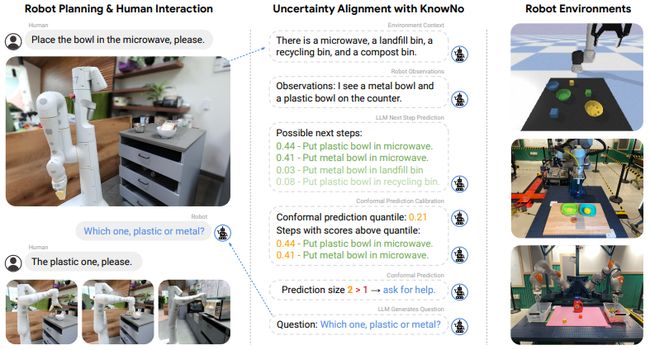
Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
标题:大型语言模型规划器的不确定性对齐
作者:Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, Anirudha Majumdar
内容:本研究提出了一种名为KNOWNO的框架,用于测量和对齐基于大型语言模型(LLM)的规划器的不确定性。该框架可以帮助规划器在不知道时知道并请求帮助。KNOWNO建立在共形预测理论的基础上,提供任务完成的统计保证,同时最小化复杂多步规划设置中需要人类帮助的情况。实验结果表明,在涉及不同模态的模糊性的任务中,KNOWNO在提高效率和自主性方面优于现代基线方法(可能涉及集成或广泛的提示调整),并提供正式保证。
Predicting Object Interactions with Behavior Primitives: An Application in Stowing Tasks
标题:使用行为原语预测物体交互
作者:Haonan Chen, Yilong Niu, Kaiwen Hong, Shuijing Liu, Yixuan Wang, Yunzhu Li, Katherine Rose Driggs-Campbell
内容:本研究提出了一种使用行为原语从预测物体交互的预测模型和单个演示中学习泛化机器人装载策略的方法。作者提出了一种新的框架,利用图神经网络在行为原语参数空间内预测物体交互。进一步地,作者使用增强的原语轨迹优化来搜索预定义的异构行为原语库的参数以实例化控制动作。该框架使机器人能够通过几个关键帧(3-4)从单个演示中熟练地执行长期装载任务。
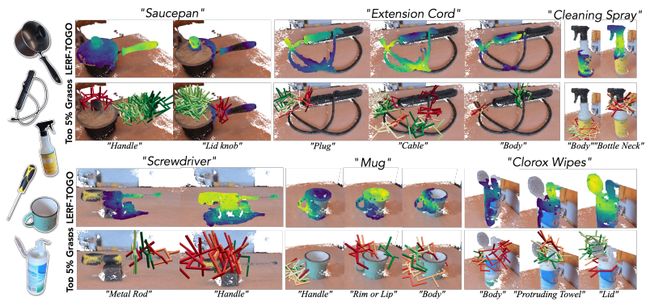
Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
标题:用于零样本面向任务抓取的语言嵌入辐射场
作者:Satvik Sharma, Adam Rashid, Chung Min Kim, Justin Kerr, Lawrence Yunliang Chen, Angjoo Kanazawa, Ken Goldberg
内容:本研究提出了一种新的语言嵌入辐射场用于面向任务的物体抓取的方法LERF-TOGO。该方法使用视觉语言模型,在给定自然语言查询的情况下,零样本输出一个物体的抓取分布。为了实现这一点,作者首先构建了一个场景的LERF,将CLIP嵌入到多尺度3D语言字段中,可使用文本进行查询。然而,LERF没有物体边界的感觉,因此其相关性输出通常返回对象上的不完整激活,这对于抓取是不够的。LERF-TOGO通过提取DINO特征的3D物体掩码来弥补这种缺乏空间分组的问题,然后在此掩码上条件性地查询LERF以获得物体上的一个语义分布,从而从现成的抓取规划器中对抓取进行排序。
最佳系统论文奖
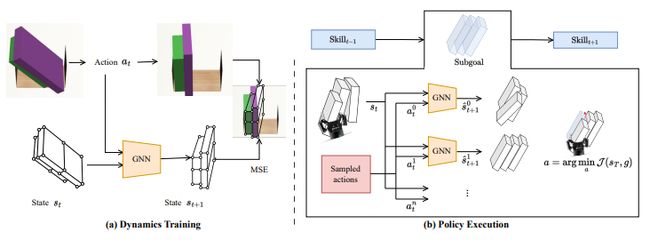
RoboCook: Long-Horizon Elasto-Plastic Object Manipulation with Diverse Tools
标题:使用多种工具进行长期弹性-塑性物体操纵
作者:Haochen Shi, Huazhe Xu, Samuel Clarke, Yunzhu Li, Jiajun Wu
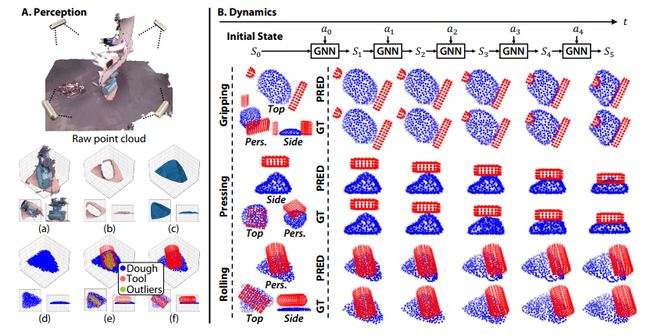
内容:本研究开发了一种名为RoboCook的智能机器人系统,能够感知、建模和操纵各种工具的弹塑性物体。RoboCook使用点云场景表示法,利用图神经网络(GNN)对工具-物体交互进行建模,并将工具分类与自监督策略学习相结合,制定操纵计划。作者展示了一个通用的机器人手臂可以从每个工具仅需20分钟的实际交互数据中学习复杂的长期软体物体操纵任务,如制作饺子和字母饼干。
MimicPlay: Long-Horizon Imitation Learning by Watching Human Play
标题:通过观察人类玩耍进行长期模仿学习
作者:Chen Wang, Linxi Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, Anima Anandkumar
内容:本研究提出了一种分层学习框架MimicPlay,通过观察人类玩耍的视频序列来学习机器人的长期模仿技能。作者认为,即使形态不同,人类玩耍数据仍然包含丰富的物理交互信息,可以促进机器人策略学习。受此启发,MimicPlay从人类玩耍数据中学习潜在计划,以指导在少量远程操作演示上训练的低层次视觉运动控制。通过对14个现实世界中的长期操纵任务进行系统评估,作者发现MimicPlay在任务成功率、泛化能力和对干扰的鲁棒性方面优于最先进的模仿学习方法。

Robot Parkour Learning
标题:机器人跑酷学习
作者:Ziwen Zhuang, Zipeng Fu, Jianren Wang, Christopher G Atkeson, Sören Schwertfeger, Chelsea Finn, Hang Zhao
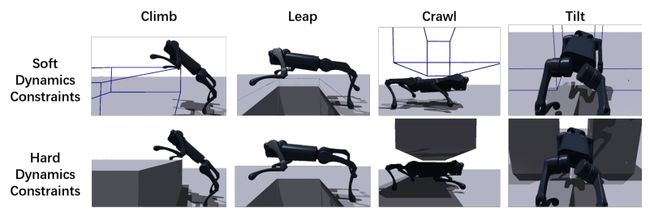
内容:本研究提出了一种用于学习多样化跑酷技能的端到端视觉跑酷策略的系统,该系统使用简单的奖励,而无需任何参考运动数据。作者开发了一种受直接定位启发的强化学习方法来生成跑酷技能,包括攀爬高障碍物、跃过大间隙、爬行低障碍物、挤过窄缝和奔跑等。作者将这些技能提炼为单一的视觉跑酷策略,并使用其自我中心的深度相机将其转移到四足机器人上。
CoRL 2022
最佳论文奖
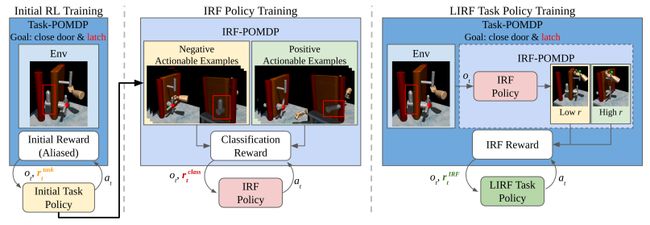
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
用于策略学习的基于示例的交互式奖励函数
简述:本研究提出了一种名为“交互式奖励函数”(IRFs)的方法,用于训练机器人自动获取物理互动行为,以评估尝试执行的机器人技能的结果,从而提高任务执行的性能。
最佳论文入围名单
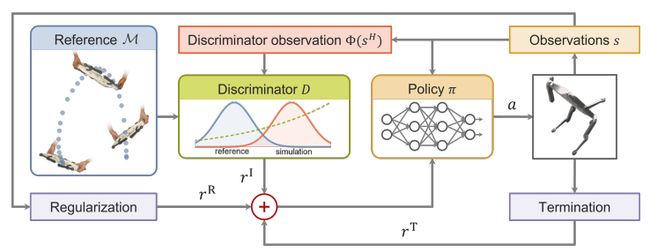
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
通过对手的粗略部分演示进行对抗性模仿来学习敏捷技能
简述:本研究提出了一种生成对抗网络方法,用于从部分和可能物理不兼容的演示中推断奖励函数,以成功获取技能。
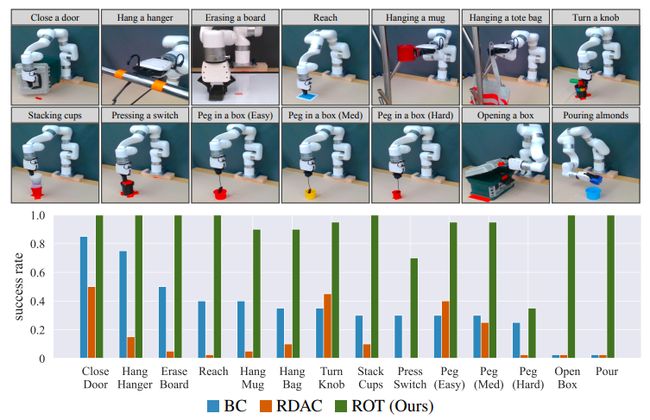
Supercharging Imitation with Regularized Optimal Transport
用正则化最优传输加强模仿
简述:本研究提出了一种新的模仿学习算法——正则化最优传输(ROT),该算法结合了轨迹匹配奖励和行为克隆,可以显著加速模仿学习,并在多个视觉控制任务上表现出色。
最佳系统论文奖
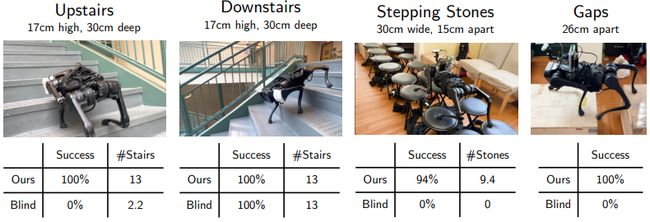
Legged Locomotion in Challenging Terrains using Egocentric Vision
基于自我中心视觉的挑战性地形中的腿部运动
简述:本研究提出了一种全新的端到端移动系统,能够跨越多种地形,并在小型四足机器人上实现实时运行。该系统使用单个前置深度相机进行自我中心视觉,并通过强化学习和有监督学习训练了策略。
特别创新奖
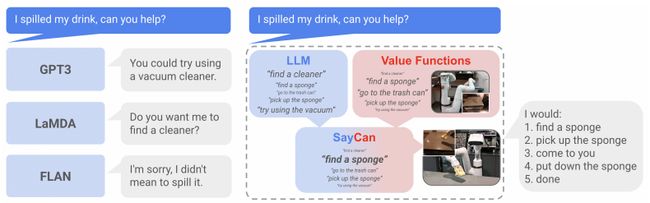
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
基于机器人可供性的语言
简述:本研究提出了一种通过预训练技能提供真实世界基础的方法,以约束语言模型提出既可行又适合上下文的自然语言行动。
关注下方《学姐带你玩AI》
回复“CoRL”领取获奖论文+代码合集
码字不易,欢迎大家点赞评论收藏!