KKBOX音乐——数据分析,用户研究与填坑指南
KKBOX音乐——数据分析,用户研究与填坑指南
- 导语
- 1 数据来源
- 2 数据处理
-
- 2.1 录入数据
- 2.2 数据类型
- 3 探索性分析
-
- 3.1 MySQL+Excel
-
- 3.1.1 每年3月最先注册的前100名用户的id、排名、注册时间、过期时间、城市、注册渠道,有什么发现?
- 3.1.2 找出至少连续3个月注册人数均不少于50的月份?
- 3.1.3 显示单月的注册人数与月均注册人数的正负10%(包含)相比 same/higher/lower?
- 3.1.4 每个城市每年的注册总人数,但是不包括最近的月份?
- 3.1.5 每种语言的歌曲按照歌曲时长由长到短的中位数分别是多少?
- 3.2 MySQL+Python
-
- 3.2.1 比较语言3和语言10的歌曲长短与用户喜好情况?
- 3.2.2 比较通过不同界面听歌的用户的喜爱偏好情况?
- 3.2.3 比较不同城市的用户听歌时长情况?
- 4 用户分析
-
- 4.1 “听音乐”的本质
- 4.2 发现问题
- 4.3 分析问题
- 4.4 解决问题
作者 | SAI
邮箱 | aishjun@icloud.com
微信 | aishjun
如有转载,请先联系。
如有讨论,随时骚扰。
如有纠错,热烈欢迎。
关键词 = [MySQL, Python, Excel, KKBox, 音乐, 数据分析, 用户研究]
总字数 = 24940(包括代码)
阅读时长 ≈ 30min
导语
数据能让人信服,也容易变成忽悠。说它能让人信服,因为“事实胜过雄辩”,在没法实地调研的情况下,用数据说话可以替代杂乱的逻辑推理(特别是公说公有理,婆说婆有理的情况),并提供可量化的指标。而说它是忽悠,因为数据本身以及分析手段都存在着各种各样的陷阱。而展示数据的人可能运用了片面分析,将数据结果朝着利于自己观点的方向发展而已。
打个比方,假设某公司分析了全国的泳衣线上购买情况,结果发现新疆的泳衣总购买量比海南的还大,于是得出“新疆的游泳人口比海南多”的结论。从数据看,证据确凿,但是用常识一想,这怎么可能呢?正好我从小在海南长大,到大街上一逛就明白了:海南人买泳衣犯不着网购,因为满大街到处都有卖泳衣的店。而正是因为新疆泳衣的需求量少,实体店几乎不卖,所以消费者只能求于网购。如果这家公司相信了大数据,试图采购大量泳衣在新疆卖,则后果可想而知。
因此,了解数据分析,有些时候是为了不受“大数据”的忽悠。而对于一款产品来说,确定目标受众,明确自身的优势,并极力通过提高用户的体验来实现产品更高的租值(即品牌价值),永远是最重要的。数据可以帮助产品团队发现问题,促进迭代,但在接受数据之前,以防受忽悠,不妨多问一句“为什么”。
而还有一种观点,则是说“数据本身没有好坏,是用数据的人引导受众向不同方向发展”。因此,在使用数据之前,“预判性”也很重要。假设说,某短视频APP的运营团队通过数据分析,发现平台上一个主题为“从10楼跳下来都没摔死”的视频A最火爆,于是疯狂给所有用户推荐视频A。那作为产品的经营者,我想问一句,它现在很火爆,现在能带来流量,那以后呢?会不会因为这个视频A,把你的品牌带到一个无底洞去,引发品牌危机?或者因为有了视频A,你以后如果不推荐同类型的视频,日活量就会下降10%以上?在面对用户之前,自己不妨做做“预言家”。我相信最好的产品,不仅能在当下为人们生活提供便利,而且能预判到产品上线一段时间之后,企业品牌的租值也会因为这款产品而提升。
带着这样一些思考,本次小项目被分成了4个部分:第一部分介绍数据来源。第二部分是数据清洗的记录。第三部分是在自己提出了共8个问题的基础上,运用Excel、Mysql(Navicat)和Python(Notebook),对数据集做探索性的分析。第四部分则是关于用户分析的一些方法论总结。
1 数据来源
KKBox官网简介
KKBox是2005 年创立的品牌,以独创的云端技术提供音乐串流服务,让用户透过网络即可播放储存在云端的歌曲;并以技术加密媒体文件 (Digital Rights Management, DRM),成功地为在线音乐和知识产权取得完美的平衡与保护,打开了在线音乐合法授权的版权观念,更在亚洲市场首度以此商业模式成为标竿品牌。至今,KKBOX 拥有超过 4000 万首曲目,服务地区包括台湾、香港、日本、新加坡及马来西亚。
而截至2017年初,KKBox在台湾的月活达到300万,在香港则是60万。所有用户中,年龄基本成类正态分布,其中大约40%的用户集中在25-34岁(可惜大陆用户好像下不了,反正我的电脑和手机都下失败了)。
该数据集来自Kaggle竞赛:KKBox’s Music Recommendation Challenge,记录这从04-17年在该平台的部分歌曲、用户信息。KKBOX提供了4个csv文件,分别存入了用户收听记录、歌曲信息、用户信息、以及歌曲名称的信息。
Kaggle竞赛题目:KKBox’s Music Recommendation Challenge
注:本数据集只是从KKBox的数据系统中的一部分数据而已,下文做的任何分析,仅针对数据集,与真实世界无关。
数据信息
recommendation.csv
• msno: 用户id
• song_id: 歌曲id
• source_system_tab: 触发收听事件的选项卡的名称。系统选项卡用于对KKBOX移动应用程序功能进行分类。 例如,tab我的库包含操作本地存储的功能,而tab搜索包含与搜索相关的功能
• source_screen_name: 用户见到的页面名称
• source_type: 用户首先在移动应用上播放音乐的入口点。 入口点可以是专辑,在线播放列表,歌曲等
• target: 这是目标变量。target = 1表示在用户的听完一首歌后的一个月内重复收听,否则target = 0
songs.csv
• song_id
• song_length: in ms
• genre_ids: 歌曲类型的id。 有些歌曲有多种类型,它们被 | 符号分开
• artist_name:表演者名字
• composer:作曲家
• lyricist:作词家
• language:语言的id
members.csv
• msno:用户id
• city:用户所在城市的id
• bd: 年龄(注意有异常值)
• gender:性别
• registered_via: 注册方法
• registration_init_time: 注册时间,格式为 %Y%m%d
• expiration_date: 过期时间,格式为 %Y%m%d
songs_name.csv
• song_id:歌曲id
• song_name:歌曲名称
• isrc - 国际标准录音代码,理论上可以用作歌曲的标识,但是可能有错误
展示一下4个表格的开头,其中有几个要注意的地方:
- msno为user id,应该是被加密过
- recommendation表格(也就是用户日志)里并没有关于时间的信息
- 图中表格已被清洗
- 但是并不知道如何清洗genre_id一列(有个别的歌曲不止一个genre_id)
members.csv
recommendation.csv
songs.csv
songs_name.csv



2 数据处理
在这一部分,主要记录从csv中录入数据、清洗数据遇到的坑。
2.1 录入数据
--在终端中进入Mysql
mysql -u root -p
--试图创建数据库
create database music;
show databases;
use music;
create table members (
msno varchar(255) not null auto_increment primary key,
city int(11),
bd int(11),
gender varchar(50),
registered_via int(11),
registration_init_time int(11),
expiration_date int(11)
);
--试图导入csv文件
load data infile '/Users/apple/Downloads/kkbox_data/members.csv' into table members;
报错:
ERROR 1290 (HY000): The MySQL server is running with the secure-file-priv option so it cannot execute this statement
--结果报错,并且无法解决(不知道是系统版本问题还是Mysql版本问题,网上各种解决方案在本机上免疫。两天无进展后,遂转战Navicat)
2.2 数据类型
(1)msno更改为string
(2)char,varchar与text类型的区别
(3)日期(Date)更改
(4)Key键设置
(5)缺失值、异常值
--更改数据类型
create database music;
use music;
alter table members modify column msno varchar(255)
;
--更改日期:用select先看语句是否生效
SELECT DATE_FORMAT(STR_TO_DATE(a.registration_init_time, '%m/%d/%Y'), '%Y-%m-%d') AS registration_init_time
FROM members a
;
--更改日期:确定语句生效后,update整个表格
UPDATE members
SET
registration_init_time = DATE_FORMAT(STR_TO_DATE(registration_init_time, '%m/%d/%Y'), '%Y-%m-%d')
;
--或者直接用date_format
UPDATE members
SET
registration_init_time = date_format(registration_init_time, '%Y-%m-%d')
;
--更改日期:再将数据类型改为date
DESCRIBE members;
ALTER TABLE members MODIFY registration_init_time date
;
--Key键设置:关键是看设置的key是否能使每一行数据“独一无二”。比如,在表格recommendation中,记录的是每次用户对歌曲的行为,单个用户可能对多个歌曲有不同行为操作,不同用户也可能对单个歌曲有操作,所以key键应该为msno、song_id两列。
--缺失值和异常值的观察,只需要count()函数来检验,比如对于表格members,用下列语句可得出19902,57.85%的gender缺失率; 得出19956,58.01%的bd(age)缺失率:
select a.null_count as null_count, concat(round(a.null_count/b.total_count*100,2),'%') as null_rate
from (
select count(msno) as null_count
from members
where gender is null
) a
join (
select count(msno) as total_count
from members
) b
;
| null_count | null_rate |
|---|---|
| 19902 | 57.85% |
由于缺失率实在太高,用填补方法的准确率也定不会高。“宁愿粗略的对,不愿精确的错”,因此暂时先不动这一块数据。
--异常值去除
--bd中小于1岁和大于100岁的去掉
select bd, count(*)
from members
group by bd
order by bd
;
update members
set bd = null
where bd < 1 or bd > 100
;
--发现有一些Null值写成了'null',遂删除
select distinct source_system_tab
from recommendation
;
update recommendation
set source_system_tab = null
where source_system_tab = 'null'
;
--同理,有缺失值被填充为'Unknown',删除
select distinct source_screen_name
from recommendation
;
update recommendation
set source_screen_name = null
where source_screen_name = 'Uknown'
;
--注意到相当多的曲目在5秒以内(可能是音效),先不删除。
select *
from songs a
join songs_name b on a.song_id = b.song_id
where song_length < 10000
order by song_length
;
相关链接
- char,varchar与text类型的区别:varchar能索引,但是占位多
- 日期更改:主要有date_format和str_to_date两种方法
3 探索性分析
3.1 MySQL+Excel
这一部分主要是为了锻炼实操技术。因此我针对数据集自己头脑风暴,提出了5个问题,然后用Mysql+Excel解答。
(注:文章截图为查询结果的部分截图)
3.1.1 每年3月最先注册的前100名用户的id、排名、注册时间、过期时间、城市、注册渠道,有什么发现?
-- 首先按照“YYYY-MM”显示日期
select date_format(registration_init_time, '%Y-%m')
from members
;

--其次选出所有在3月份注册的用户,并排序
select @ctr := @ctr+1, msno, city, registration_init_time, expiration_date
from members
join (select @ctr := 0) as a
where date_format(registration_init_time, '%m') = 03
order by date_format(registration_init_time, '%Y'), date_format(registration_init_time, '%d')
;

--再者以月份为小组,在小组内部按照用户的注册时间先后排名
--注意:实战中如果把@rn写成@row_number,即带有“_”的符号,就报了错
select
msno,
registration_init_time,
@rn := IF(@previous = date_format(registration_init_time, '%Y-%m'), @rn+1, 1) as ranking,
@previous := date_format(registration_init_time, '%Y-%m')
from
members
join (
select @previous := null, @rn := 0
) as a
where
date_format(registration_init_time, '%m') = 3
order by
date_format(registration_init_time, '%Y-%m')
;
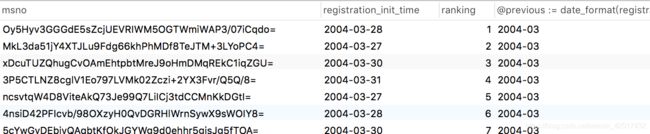
--将信息补充完整
select
ranks.msno as user_id, ranks.ranking as ranking, ranks.registration_init_time as registration_date, ranks.expiration_date as expiration_date, ranks.city as city, ranks.registered_via as registered_via
from (
select
msno, registration_init_time, expiration_date, city, registered_via,
@rn := IF(@previous = date_format(registration_init_time, '%Y-%m'), @rn+1, 1) as ranking,
@previous := date_format(registration_init_time, '%Y-%m')
from
members
join (
select @previous := null, @rn := 0
) as variables
where
date_format(registration_init_time, '%m') = 3
order by
date_format(registration_init_time, '%Y') DESC, date_format(registration_init_time, '%d'), expiration_date
) ranks
where
ranks.ranking <= 100
;

经过Excel分析,结果如下图:

3.1.2 找出至少连续3个月注册人数均不少于50的月份?
--- 先列出每个月的注册人数
select
date_format(registration_init_time, '%Y-%m') as register_month, count(msno)
from
members
group by
register_month
order by
register_month
;

--加上排名序列
--经验:variable所在的select语句中,不能有运算(比如count,date_format),否则导致ranking混乱。所以用了subquery
select
@ranking := @ranking+1, t1.register_month, t1.user_number
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as user_number
from
members
group by
register_month
order by
register_month
) as t1
join (
select @ranking := 0
) as variable
;
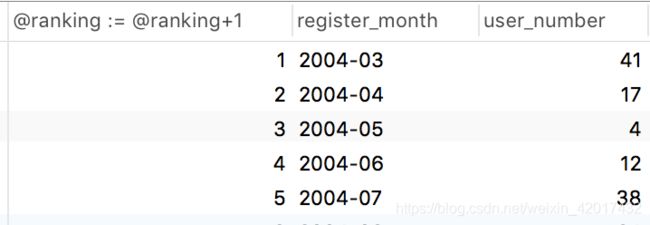
--用两种ranking方式叠加,再设置限制条件,得到符合条件的序号 9,13,17,19,23,而序号代表的就是所有符合条件的月份(一个序号代表连续3个月份及以上)
select count(ttt1.register_month) as month_count, ttt1.ranking
from (
select
tt1.ranking,
@ranking2 := if(tt1.user_number < 50, 0, 1) as ranking2,
tt1.register_month, tt1.user_number
from (
select
@ranking := case
when t1.user_number < 50 and @previous < 50 then @ranking
when t1.user_number >= 50 and @previous < 50 then @ranking + 1
when t1.user_number >= 50 and @previous >= 50 then @ranking
when t1.user_number < 50 and @previous >= 50 then @ranking + 1
end as ranking,
@previous := user_number as previous,
t1.register_month,
t1.user_number
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as user_number
from
members
group by
register_month
order by
register_month
) as t1
join (
select @ranking := 0, @previous := 0
) as variable
) as tt1
join
(select @ranking2 := 0) as variable2
) as ttt1
where
ttt1.ranking2 = 1
group by
ttt1.ranking
having
count(ttt1.register_month) >= 3
;
下图为最后的限定语句(where,groupby, having)之前的查询结果

--但是很奇怪,用where in (subquery) 或者是 inner join就没有显示,只能将前面query所得的序号记下,用在 where in语句中
select ttt1.register_month, ttt1.user_number
from (
select
tt1.ranking,
@ranking2 := if(tt1.user_number < 50, 0, 1) as ranking2,
tt1.register_month, tt1.user_number
from (
select
@ranking := case
when t1.user_number < 50 and @previous < 50 then @ranking
when t1.user_number >= 50 and @previous < 50 then @ranking + 1
when t1.user_number >= 50 and @previous >= 50 then @ranking
when t1.user_number < 50 and @previous >= 50 then @ranking + 1
end as ranking,
@previous := user_number as previous,
t1.register_month,
t1.user_number
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as user_number
from
members
group by
register_month
order by
register_month
) as t1
join (
select @ranking := 0, @previous := 0
) as variable
) as tt1
join
(select @ranking2 := 0) as variable2
) as ttt1
where ranking in (9,13,17,19,23)
;


3.1.3 显示单月的注册人数与月均注册人数的正负10%(包含)相比 same/higher/lower?
--先求出单月注册人数
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as monthly_count
from
members
group by
register_month
order by
register_month
;
--再求出月均注册人数 221.95
select avg(t1.monthly_count) as avg_count
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as monthly_count
from
members
group by
register_month
order by
register_month
) as t1
;
--用case when连接
select
a.register_month,
a.monthly_count,
case
when a.monthly_count > round(b.avg_count * 1.1, 0) then 'higher'
when a.monthly_count < round(b.avg_count * 0.9, 0) then 'lower'
else 'same' end
as comparison
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as monthly_count
from
members
group by
register_month
order by
register_month
) as a
join (
select avg(t1.monthly_count) as avg_count
from (
select
date_format(registration_init_time, '%Y-%m') as register_month,
count(msno) as monthly_count
from
members
group by
register_month
order by
register_month
) as t1
) as b
;
3.1.4 每个城市每年的注册总人数,但是不包括最近的月份?
--先查出每个城市注册总人数
select
city,
date_format(registration_init_time, "%Y-%m") as monthly_count,
count(msno) as city_count
from
members
group by
city, monthly_count
order by
city, monthly_count desc
;
--在单个城市内部按照时间排序
select
t1.city,
t1.monthly_count,
t1.city_count,
@ranking := if(@previous = city, @ranking + 1, 1) as ranking,
@previous := city
from (
select
city,
date_format(registration_init_time, "%Y-%m") as monthly_count,
count(msno) as city_count
from
members
group by
city, monthly_count
order by
city, monthly_count desc
) as t1
join
(select @ranking := 0, @previous := 0) as variable
;
--编号1代表最近的月份。去掉编号1,再用sum搞定
select
tt1.city, sum(tt1.city_count) as user_count, tt1.monthly_count as months
from (
select
t1.city,
t1.monthly_count,
t1.city_count,
@ranking := if(@previous = city, @ranking + 1, 1) as ranking,
@previous := city
from (
select
city,
date_format(registration_init_time, "%Y-%m") as monthly_count,
count(msno) as city_count
from
members
group by
city, monthly_count
order by
city, monthly_count desc
) as t1
join
(select @ranking := 0, @previous := 0) as variable
) as tt1
where
tt1.ranking > 1
group by
tt1.city, tt1.monthly_count
order by
city, months
;
3.1.5 每种语言的歌曲按照歌曲时长由长到短的中位数分别是多少?
---训练三种ranking方式:12345,12234,12245
--基本排列,1 2 3 4 5
select
song_id, song_length, songs.`language`,
@rn := IF(@previous = songs.`language`, @rn+1, 1) as ranking,
@previous := songs.`language`
from
songs
join (
select @previous := null, @rn := null
) as variables
order by
songs.`language`, song_length DESC
;
--排列, 1 2 2 3 4 5 5
elect
song_id, song_length, songs.`language`,
@rn := case
when @lang = songs.`language` and @leng = songs.song_length then @rn
when @lang = songs.`language` and @leng := songs.song_length then @rn := @rn+1
when @leng := songs.song_length and @lang := songs.`language` then 1
end as ranking,
@lang := songs.`language`,
@leng := songs.song_length
from
songs
join (
select @lang := null, @rn := null, @leng := null
) as variables
order by
songs.`language`, song_length DESC
;
--ranking1 - 1 2 3 4 5
--ranking2 - 1 2 2 4 5
--如果把上面的ranking也加进来(1 2 2 3 4),ranking一列就没有显示了;
--如果再JOIN别的表(比如songs-name),ranking排序也会出错
select
song_id, song_length, songs.`language`,
@rn := if(
@lang = songs.`language`, @rn+1, 1
) as ranking1,
@rk := case
when @lang = songs.`language` and @leng = songs.song_length then @rk
when @lang = songs.`language` and @leng := songs.song_length then @rk := @rn
when @leng := songs.song_length and @lang := songs.`language` then 1
end as ranking2,
@lang := songs.`language`,
@leng := songs.song_length
from
songs
join (
select @lang := null, @leng := null, @rn := 1, @rk := 1
) as variables
order by
songs.`language`, song_length DESC
;
--找中位数
--注意最后两步关于奇数偶数的中位数的逻辑
select
t1.song_id, round(t1.song_length / 60000, 2) as song_min, t1.`language`, t1.genre_ids, t1.ranking
from (
select
songs.song_id, songs.song_length, songs.`language`,songs.genre_ids,
@rn := if(
@lang = songs.`language`, @rn+1, 1
) as ranking,
@lang := songs.`language`
from
songs
join (
select @lang := null, @rn := 1
) as variables
order by
songs.`language`, songs.song_length DESC
) as t1
join (
select
count(song_id) as total_rank, `language`
from
songs
group by
`language`
) as t2
on
t1. `language` = t2.`language`
where
t1.ranking = floor((total_rank+1)/2) or
t1.ranking = floor((total_rank+2)/2)
;

3.2 MySQL+Python
这一部分则提出了3个问题,然后用Mysql+Python解答。
---基本查询
---由于导出时间问题,我只选择了1-10分钟的歌曲
select
r.msno, r.song_id, sn.song_name, r.source_system_tab, r.source_screen_name, r.source_type, s.`language`, s.genre_ids, m.city, round(s.song_length/60000, 2) as song_length_min, r.target
from
recommendation r
join
songs s on r.song_id = s.song_id
join
members m on m.msno = r.msno
join
songs_name sn on s.song_id = sn.song_id
where
s.song_length between 60000 and 600000
order by
s.`language`, song_length_min
;
#导出文件csv文件有1.2GB,Excel带不动了
#环境 Anaconda Jupyter Notebook 5.5.0
#python调包
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入数据为dataframe
kkbox_file_path = '/Users/apple/Downloads/kkbox_data/4.csv'
kkbox_data = pd.read_csv(kkbox_file_path)
#首先看看数据完不完整
#由于本篇文章并不涉及机器学习算法,因此目前来看缺失值的影响不大,因此不动
null_values_col = kkbox_data.isnull().sum()
null_values_col = null_values_col[null_values_col != 0].sort_values(ascending = False).reset_index()
null_values_col.columns = ["feature", "number of missing"]
# 因为city、language、target三列的数据为ID代号,并不是int类型,因此更改三列的数据类型(from int to str)
kkbox_data['language'] = kkbox_data['language'].apply(str)
kkbox_data['city'] = kkbox_data['city'].apply(str)
kkbox_data['target'] = kkbox_data['target'].apply(str)
# 增加新列,以歌曲时长为[1.0,2.5), [2.5,4.0),[4.0,5.5),[5.5,7.0),[7.0,8.5),[8.5,10.0]为分组
condition = [
(kkbox_data['song_length_min'] < 2.5),
(kkbox_data['song_length_min'] < 4.0),
(kkbox_data['song_length_min'] < 5.5),
(kkbox_data['song_length_min'] < 7.0),
(kkbox_data['song_length_min'] < 8.5),
(kkbox_data['song_length_min'] >= 8.5)
]
choice = ['2.5below', '4.0below', '5.5below', '7.0below', '8.5below', '10.0below']
kkbox_data['song_len_class'] = np.select(condition, choice, default=3)
#看看每个group的听歌次数
print(kkbox_data.song_len_class.value_counts())
print(kkbox_data.language.value_counts())
"""
结果
5.5below 3061822
4.0below 3016256
7.0below 170282
2.5below 144555
8.5below 25958
10.0below 11358
Name: song_len_class, dtype: int64
3 3493438
52 1656983
31 581559
-1 262473
17 213373
10 151374
24 65014
59 3736
45 2095
38 186
Name: language, dtype: int64
"""
#为了解决下面三个问题,决定建一个class
class Users(object):
def __init__(self, feature, data):
"""
feature是指想要比较的feature,比如歌曲时长的差异,那song_len_min一列就是feature
data在这里是指kkbox_data
"""
self.feature = feature
self.data = data
def choice(self):
"""
看这一列有多少唯一值
并删除nan值
"""
choice = self.data[self.feature].unique().tolist()
choice = [x for x in choice if str(x) != 'nan']
return choice
def preference(self, df):
"""
df是指需要比较的features&target所在的列
choice里的都是这一列的唯一值
当target一列为1,则表示30天内用户反复听过,表明喜欢,反之为不喜欢
"""
pre_dic = {}
choice = self.choice()
for i in choice:
class_data = df[df[self.feature] == i]
pre_class_data = class_data[class_data['target'] == '1']
pre_data = pre_class_data[['target']]
total_data = class_data[['target']]
pre_count = len(pre_data)
total_count = len(total_data)
pre_rate = pre_count / total_count
pre_dic[i] = pre_rate
return pre_dic
def listen_len(self, df):
"""
与self.preference()类似,不过这里算的是听歌总时长
"""
len_dic = {}
choice = self.choice()
for i in choice:
class_data = df[df[self.feature] == i]
len_data = class_data[['song_length_min']]
sum_data = float(len_data.sum())
len_dic[i] = sum_data
return len_dic
def single_plot(self, dic, ylabel, rot=0):
"""
rot=0要写到最后,比如def example(a, b, c=None, r="w" , d=[], *ae, **ab)
"""
plt.bar(range(len(dic)), list(dic.values()), align='center')
plt.xticks(range(len(dic)), list(dic.keys()), rotation=rot)
plt.xlabel(str(self.feature))
plt.ylabel(ylabel)
return plt.show()
def double_plot(self, dic1, dic2, label1, label2, ylabel):
"""
为了比较两组数据而创立,比如3.2.1问语言3和语言10两组数据在听歌时长的比较
推荐网站 https://htmlcolorcodes.com,里面记录各种颜色的RGB、HEX值
"""
barWidth = 0.3
bar1 = list(dic1.values())
bar2 = list(dic2.values())
pos1 = np.arange(len(bar2))
pos2 = [x + barWidth for x in pos1]
keys = list(dic1.keys())
plt.bar(pos1, bar1, width = barWidth, color = '#12A4EF', edgecolor = 'black', capsize=7, label=label1)
plt.bar(pos2, bar2, width = barWidth, color = '#F75E2A', edgecolor = 'black', capsize=7, label=label2)
plt.xticks([r + barWidth for r in range(len(bar1))], keys)
plt.ylabel(ylabel)
plt.xlabel(str(self.feature))
plt.legend()
return plt.show()
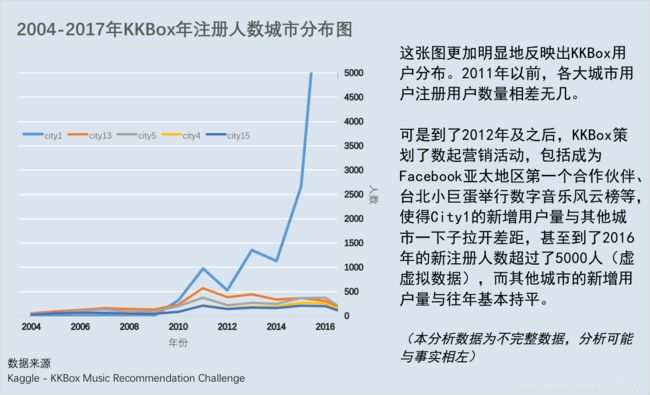
3.2.1 比较语言3和语言10的歌曲长短与用户喜好情况?
#先定义df
len_data = kkbox_data[['language', 'song_len_class', 'target']]
language3_data = len_data[len_data['language'] == '3']
language10_data = len_data[len_data['language'] == '10']
#安装User类
user1 = Users('song_len_class', kkbox_data)
lan3_pre_dic = user1.preference(language3_data)
lan10_pre_dic = user1.preference(language10_data)
#调用类
user1.double_plot(lan3_pre_dic, lan10_pre_dic, 'language3', 'language10', 'preference_rate')
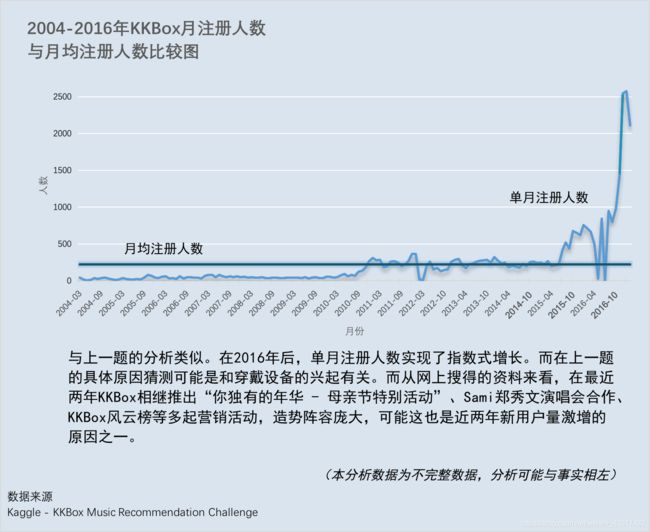
单从此图,似乎可以得出“语言3在短时间歌曲(8.5min一下)上比语言10更加受用户青睐。然而在得出这个结论后,不妨问自己一些问题:
(1)如果这个结论是符合事实的,那为什么会这样呢?和语言本身有关系吗?比如说语言3是台湾少数民族语言,而语言10是英语。听少数民族歌曲的人大多数是属于或者认同这个民族的,喜好度当然高,反之听英文歌的人偏大众化?
(2)如果这个结论不符合事实,那图中的结果又是怎么回事呢?是样本量太小或是图中的差异性不显著吗?
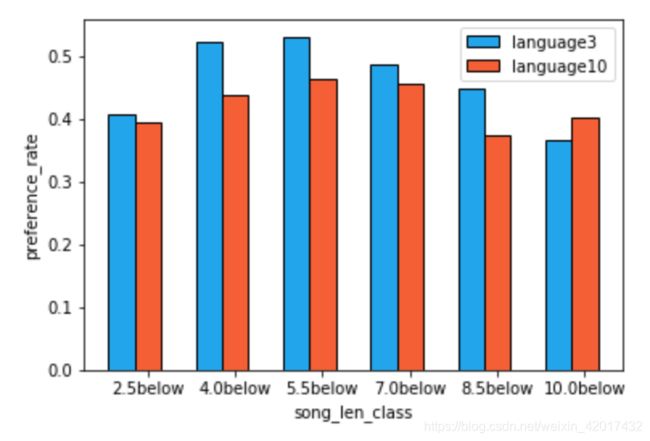
3.2.2 比较通过不同界面听歌的用户的喜爱偏好情况?
#定义df
source_data = kkbox_data[['source_type', 'target']]
#安装类
user2 = Users('source_type', kkbox_data)
source_pre_dic = user2.preference(source_data)
#调用画图
user2.single_plot(source_pre_dic, 'preference_rate', rot=90)
而我们如果单从此图得出了“如果用户从local-library和local-playlist听歌,对歌曲的喜好度更高”的结论,仔细一想,这不等于没说吗?都在本地播放了,那当然是喜欢这首歌的呀。这就属于因果关系搞反了,用户是因为喜欢歌,才在local-playlist播放的。
那我们可以得出什么有意义的结论呢?就我个人而言,我比较关注“artist”和“my-daily-playlist”两个界面。从图上可以得出,从“artist”界面听到的歌,用户的喜好率更高,这说明用户更倾向于听自己喜欢的歌手的其他歌(与追星现象吻合)。因此,我们的推荐系统“my-daily-playlist”是否应该考虑将“artist”的权重增加呢?亦或者说,虽然我们在推荐系统里增加了很多用户喜好歌手的其他歌曲,但是这真的是用户在推荐系统中想听到的吗?“猜我喜欢什么歌”真的是推荐系统的价值所在吗?
3.2.3 比较不同城市的用户听歌时长情况?
#定义df
city_data = kkbox_data[['city', 'song_length_min']]
#安装类
user3 = Users('city', kkbox_data)
city_listen_dic = user3.listen_len(city_data)
#调用画图
user3.single_plot(city_listen_dic, 'listen_length')

与之前的分析相一致,城市1果然是KKBox的“大头”用户聚集地。然而看到了听歌总时长的差异后,我们也要想一想,会不会是因为城市1的用户多,而其实单个用户的听歌时间并不长呢?为什么其他城市的用户使用黏性上不来呢?是我们的marketing本地化策略不够好吗?还是我们的产品本身在当地的竞争性不够强?
4 用户分析
分析完了以上数据集,在这一部分中稍微聊一聊自己对与用户相关的体会。下文中如有观点浅薄部分,欢迎指正。
听音乐和吃穿住行一样,也是一种消费方式。支付出去的是时间、精力,或是购买音乐的使用权,得到的大多数是精神享受。而我个人认为,听音乐与看电影、打游戏有不同的地方,就是消费大部分音乐的时候并不会消耗你的注意力。比如说,你可以边听歌边打球,边听歌边写作业,边听歌边上班。但是如果是看电影、打游戏的话,如果不投入精力,你很难从中获得乐趣。而这也是我喜欢音乐的一个重要原因。
4.1 “听音乐”的本质
要做用户分析,要意识到听音乐是用户在特定局限条件下的特定行为。这句话有3层意思:
- 喜好的歌曲是不固定的,也许今天喜欢这首歌,明天就有可能拉入黑名单。
- 喜好的种类也是不固定的,也许今天在上班没精神,就听了一下午的摇滚,但是明天在家里宅着,就放了一整天的贝多芬交响曲。
- 喜好的APP也是不固定的,假如某个用户特别喜欢歌曲A,而在你的曲库里也有。但是在别的APP里它是免费下载的,而你需要会员,用户就有可能就在短时间内和你说分手了。但是如果下一次,你有了别的APP没有的歌,正好用户又喜欢,他可能又回来了。所以一般用户的手机里都有多个音乐类APP。
4.2 发现问题
意识到了这3点之后,为了了解用户,就要学会准确抓住用户所处局限条件。而在分析的过程中,可以对用户的行为做“三部曲”,即发现与定义问题,使用逻辑推理,并进行逻辑与事实验证。而对于音乐平台来说,问题有:
为什么用户选择了我们这个APP而不是别的APP呢?为什么用户昨天还听歌,今天就不听了呢?为什么上个月他开通了会员,这个月就取消了呢?为什么昨天的日活量还正常,今天就下降了20%呢?
在这里,我引用并修改了包包的一篇文章提出的问题《产品经理,如何真正的实现数据驱动》。今天做报表,发现了日活量下降之后,就要进一步定义问题:到底是谁的日活量下降了?是新/老,还是城市A/城市B用户?这些都是可以通过数据可视化帮助团队准确察觉到的现象。
4.3 分析问题
通过数据准确感知到了问题之后,就要针对问题做分析了。为什么新用户的日活量会下降?因为用户体验下降。而为什么体验下降?开始想象一些潜在的局限条件,并进一步抓住关键的局限条件(即原因)。
- 是新版界面对用户不友好?- 那为什么老用户没有下降?
- 对于新用户的推送太过频繁?- 那为什么昨天没有下降,只有今天下降了?
- 还是想要的歌找不到? - 看起来好像有点道理,因为我们今天正好失去了Eason的版权
在采取措施之前,先要做验证。是不是真的因为Eason版权而使得日活下降?事实验证可以包括亲身体验、用户访谈、控制变量等方法,证明是不是真的因为只是版权问题(假设现在是3条/天)而导致了20%的日活下降。而逻辑验证包括反证法等方法(假如明天的日活开始回升,而Eason的版权依然没有得到,说明至少不完全是因为版权问题导致日活下降)。在这里,我认为其实是没有100%把握确定真的只是因为“Eason版权”这一唯一因素而导致日活下降的,可是在力所能及排查到的因素中,它的可能性最大(无论是数据表现、用户访谈、以及历史经验来看)。
4.4 解决问题
一旦有了把握是因为版权问题而导致的日活下降,那么在预期事态继续扩大(可能明天日活下降更多,如果被媒体放大,再严重一点就变成了危机公关事件)之前,要想办法怎么解决。之前网易云音乐因为周杰伦版权事件而导致用户口碑遭遇滑铁卢。因此在对待版权、音乐人权益的问题上,千万不能掉以轻心。
如何解决这个问题呢?这个问题就像是去医院看病,结果你需要的药,医院正好没有,作为医院方该怎么办呢?首先,最能满足消费者的方案一定是尽可能想办法(从别的分院或者其他合法途径)以平常价弄到这个药。那如果不行呢?退而求其之,如果有一种途径,能高价弄到这个药,这也不失为一种给消费者的选择。然而还有另一种选择,就是在消费者能接受的同等价位上,选择其他有相同效果的药。但是正好这两天医院病人暴增,这类药短缺了呢?那只能在挂号门口贴上招牌“如得XX病,请前往XX医院就诊。联系电话是:138XXXXXXXX”。作为类比,在音乐版权时间上,平台方的做法可以是:
- 想办法按照原来的成本,弄到Eason的版权。
- 如果相同的成本弄不来,估算一下需求量与增加的边际成本,如果能接受,可以高价回收版权,并想办法在价格上做文章。
- 如果不划算,那看看有没有替代品。对于喜欢Eason的用户,是否可以通过推荐系统推荐与Eason类似的歌手,以及好听的歌,以分散用户对Eason的注意力。
- 而当没有Eason版权之时,千万不能犯“想要满足用户需求而侵犯版权”的错误。
- 如果上述活动效果均不佳,只能像医院一样了,向用户阐明失去版权的原因,并真诚地向用户提供选择:选择留下,我们一定早日争取版权;选择离开,我们知道在目前哪些APP上有Eason版权,但是不久之后我们也会争取。
总的来说,用户都是“利己”的,也是随时流动的。在哪个APP有什么版权方面,用户与市场的嗅觉都特别灵敏。虽然在最后一招之后,很可能暂时挽回不了用户,但是也不至于造成品牌危机。而对于品牌来说,暂时的用户日活、收听量、付费率,是不如你的“品牌”租值来得重要的。
这也应了句老话,留得青山在,不怕没柴烧。而怕的就是有柴的时候,没地方烧了。
完结。