线性函数拟合R语言示例
线性函数拟合(y=a+bx)
1. R运行实例
R语言运行代码如下:绿色为要提供的数据,黄色标识信息为需要保存的。
x<-c(0.10,0.11, 0.12, 0.13, 0.14, 0.15,0.16, 0.17, 0.18, 0.20, 0.21, 0.23)
y<-c(42.0,43.5, 45.0, 45.5, 45.0, 47.5,49.0, 53.0, 50.0, 55.0, 55.0, 60.0)
data1=data.frame(x=x,y=y) #数据存入数据框
#拟合线性函数
lm.data1<-lm(y~ x,data=data1)
summary(lm.data1) #输出拟合后信息
Call:
lm(formula = data1$y ~ data1$x)
Residuals: #残差分位数(当残差个数较少时,此处显示所有残差值)
Min 1Q Median 3Q Max
-2.0431 -0.7056 0.1694 0.6633 2.2653
Coefficients:
#系数估计值 #系数标准误差 #t检验值 #对应t值概率的2倍
Estimate Std. Error t value Pr(>|t|)
(Intercept) 28.493 1.580 18.04 5.88e-09 ***
data1$x 130.835 9.683 13.51 9.50e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’1
Residual standard error: 1.319 on 10degrees of freedom
#拟合优度判定系数 #修正的拟合优度判定系数
Multiple R-squared: 0.9481, AdjustedR-squared: 0.9429
#F检验值 #F检验值对应的概率
F-statistic: 182.6 on 1 and 10 DF, p-value:9.505e-08
t检验值对应的Pr(>|t|):该数值由于是t检验量对应的概率的2倍,所以其数值小于0.1时,就说明对应的自变量对于因变量来说是有显著性的,当然数值越小,显著性越高。
F检验值对应的p-value:F检验值对应的概率。当其数值小于0.05时,说明回归方程是显著的。
Adjusted R-squared修正拟合优度:数值越接近1,模型拟合的越好。
/***********************数值输出********************************/
coefficient<-lm.data1$coefficients #回归所有系数列举
coefficient[1] #系数a:截距
coefficient [2] #系数b
tvalue<-summary(lm.data1)$coefficients[1:2,3] #t检验值
tvalue[1] #系数a对应的t检验值
tvalue[2] #系数b对应的t检验值
Pr<-summary(lm.data1)$coefficients[1:2,4] #t检验值对应的概率的2倍
Pr[1] #系数a对应t检验值对应的概率2倍
Pr[2] #系数b对应t检验值对应的概率2倍
ARsquared<-summary(lm.data1)$adj.r.squared #修正的拟合优度判定系数
F_info<-summary(lm.data1)$fstatistic #F检验的F值、自由度DF和概率
F_info[1] #F检验值
F_info[2] #F检验量的自由度
F_info[3] #F检验值对应的概率
/****************************************************************/
#残差正态性检验
ks.test(lm.data1$residuals,"pnorm",0)
One-sampleKolmogorov-Smirnov test
data: lm.data1$residuals
#D检验值 #对应的概率值
D = 0.1332, p-value = 0.9648
alternative hypothesis: two-sided
D检验值对应的概率值p-value:该数值大于0.05,说明残差服从均值为0的正态分布。
/***********************数值输出********************************/
ks_test<-ks.test(lm.data1$residuals,"pnorm",0) #获取正态性检验信息
ks_test[1] #KS检验值
ks_test[2] #KS检验值对应的概率
/****************************************************************/
#残差独立性检验:DW法检验残差序列的自相关性
dwtest(lm.data1)
Durbin-Watsontest
data: lm.data1
#d.w检验值#对应的概率值
DW = 2.5465, p-value = 0.7422
alternative hypothesis: trueautocorrelation is greater than 0
DW检验值对应的概率值p-value:该数值大于0.05时,说明残差序列独立。
/***********************数值输出********************************/
dw_test<-dwtest(lm.data1) #获取独立性检验信息
dw_test[1] #DW检验值
dw_test[4] #DW检验值对应的概率
/****************************************************************/
#残差同方差检验
bptest(lm.data1)
studentizedBreusch-Pagan test
data: lm.data1
#BP检验值 #自由度 #对应概率值
BP = 0.9831, df = 1, p-value = 0.3214
BP检验值对应的概率值p-value:该数值大于0.05,说明残差是同方差的。
/***********************数值输出********************************/
bp_test<- bptest(lm.data1) #获取独立性检验信息
bp_test[1] #BP检验值
bp_test[2] #BP检验量的自由度
bp_test[4] #BP检验值对应的概率
/****************************************************************/
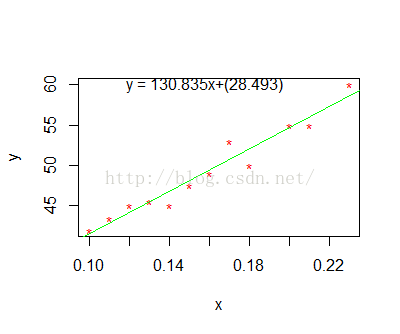
2. 拟合曲线图
ab<-round(lm.data1$coefficients[1],3) #回归方程系数a,保留3位小数
bb<-round(lm.data1$coefficients[2],3) #回归方程系数b,保留3位小数
plot(data1$x,data1$y,xlab="x",ylab = "y",col="red",pch="*") #训练数据点
abline(lm.data1,col="blue") #拟合曲线
text(mean(data1$x),max(data1$y),paste("y = ",bb,"x+(",ab,")",sep = ""))#方程式