学习笔记-linux系统编程
学习笔记:
终端:键盘,鼠标,显示器,shell,
echo $SHELL 查看shell 的可执行文件在哪里
一些文件夹及其主要存储的文件
bin:可执行文件
boot:开机历程
dev:设备
etc:用户配置文件
lib:库路径
opt proc: 进程相关
media mnt :挂载的设备
三方库一般放在/usr/lib中
home:用户的根目录
linux的文件类型:
普通文件 -
目录 d
字符设备 c
块设备 b
软链接 硬链接 l
管道 p
套接字 s
未知
常用命令:which查看命令
cat 和 tac 顺着打印 倒着打印
more 分屏显示
less分屏显示
head前几行
tail后几行
tree 树形目录
whoami 查看我的用户名
chown 改变所有者
find寻找命令,主要是文件名 加上-maxdepth可以限制查找层数
grep 内容查找
man查看文档
ps 后台进程
tar -zcvf 生成压缩包
vim的使用.
gcc编译的几个步骤
预处理:展开宏,头文件
编译:检查语法的规范
汇编:翻译成机器语言
链接:数据段合并(节省空间),地址回填(比如一个函数的位置在哪里,如共享库的函数地址一开始是不知道的,这个需要回填的时候给填上去)
编译阶段是最耗费时间的,报错的时候如果有行号,一般是在编译阶段出现问题,没有行号一般是链接的问题
gcc -E -S -c -g -D
静态库的制作
gcc -c -o
ar rcs lib库 add.o sub.o
动态库制作
gcc -c add.c -o add.o -fPIC -shared
编译的可执行程序的时候,指定所使用的的动态库 -l库名 -L库路径
直接将共享库放在/lib 里面
makefile文件
命名makefile Makefile
一个原理 检查依赖 找规则,生成依赖文件,查看目标是否更新,编译耗费的时间太长了,节省时间
两个函数 src = $(wildcard ./*.c) 获取符合条件的所有文件到src里面
obj = $(patsubst %.c %.o, $(src)) 将3中符合1的规则变成2赋给obj
三个自动变量
$@规则中的目标
#<第一个条件,依赖条件(模式规则中,依次更新依赖)
$^规则中所有依赖条件,组列表,唯一
模式规则:
%.o:%.c
固定模式:gcc -c $< -o $@
静态模式规则:
$(obj):%.o:%.c
gcc -c #< -o $@
系统调用:
sys_open是系统调用
open是库函数,做了一个浅封装
open 名字 flags :读写 O_TRUNC 清空,文件截断成0 创建文件还受到umask影响
一个block的单位是512byte
软连接:保存原始文件的路径,为了保证可以复制到任何位置,建议使用绝对路径
硬连接:直接创建inode指向这个文件
open函数 返回值 int fd ,pathname路径名字
Flags ,读写的方式O_RDONLY O_WRONLY 这些宏在
Mode 打开的方式,取值八进制数描述文件访问权限,权限创建还和umask相关
成功返回fd,失败返回error ,打印信息
打开就要关闭,close(fd),
src = $(wild *.c)
target = $(pathsubst %.c , %. $(src))
ALL:$(target)
%:%.c
Gcc $< -o $@
clean:
-rm -rf $(target)
.PHONY:celan ALL
读写文件操作
实现一个cp操作
int mian(int argc, char* argv[])
{
char buf[1024];
int n = 0;
int fd1 = open(argv[1], O+RONLY);
if(-1 == fd1)
{
perror(“open argv[1] error”);
exit(1);
}
if(-1 == fd2)
{
perror(“open argv[2] error”);
exit(1);
}
int fd2 = open(argv[2],O_RDWR|O_REATE|O_TRUNK, 0664);
while(0 != (n=read(fd1, buf, 1024)))
{
if(0 < n)
{
perror();
exit(1);
}
write(fd2, buf, n);
}
close(fd1);
close(fd2);
return 0;
}
trase命令
用法trase ./prog 可以追踪运行的系统调用
fputc 会使用4096缓冲长度,现在另一个空间凑够4096,然后再写入内核
将数据写入内核缓冲区,不调整就是4k,预读入缓输入
虽然比每次只写1个字节快,但是比不上用户空间之间的复制快
只有内核什么时候写磁盘,这个就是os做的事情,和app无关
read write都是unbuffer函数
从这里可以看出,系统调用不一定就比库快,库很成熟,还是多用,但是具体的操作具体分析,这种机制是一个双刃剑
文件描述符表 -> 指向一个struct file,OS为了隐藏这一部分,只暴露一个fd,
PCB进程控制块,结构体 成员:文件描述符表,新打开文件用文件中最小可用的fd
宏 0--STDIN_FILENO 1--STDOUT_FILENO 2--STDERR_FILENO
阻塞和非阻塞:
场景:设备.网络 常规文件没有这个说法
/dev/tty 终端文件 可能会阻塞 阻塞是文件的属性,
read一个非阻塞文件,返回-1,二人哦= EAGAINEWOULDBLOCK,说明是以非阻塞的方式读一个设备文件
这种轮询的方式都不是最优
fcntl函数可以不用重启函数而改变函数的阻塞非阻塞
位图,可以作为一个配置数组,但是相对于数组,节省内存空间
lseek函数,改变读写的位置,文件读写使用同一个位置
lseek获取文件,拓展文件大小,实质性打开还是需要IO操作
也可以使用 truncate函数拓展文件的大小
od -tcx filename 16进制查看
od -tcd filename 10进制查看
const修饰传入参数,指针传出参数
inode 文件属性管理结构,还有盘块的位置,
dentry目录项保存f.c inode
硬链接,一个dentry,inode指向同一个
没有inode指向磁盘块,但是磁盘不会擦除,会被覆盖
数据恢复就可以用这个操作进行恢复
stat函数
ftate 对于连接会穿透符号链接
因此用lstat
文件位图 ,16位
如下所示
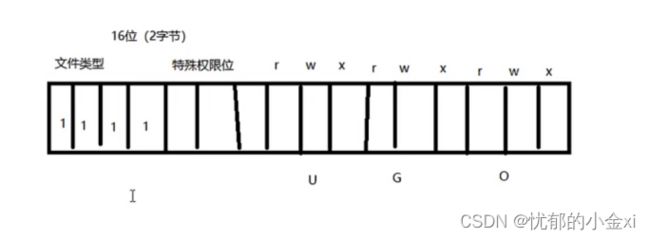
黏住位
link硬链接进行连接
linux删除文件的机制,不断将nlink -1,为0,OS择机进行释放,删除文件,只是让文件具备了被释放的条件, 没有dentry对应,但是该文件不会马上被释放掉,要等到所有打开这个文件的进程都关闭文件的时候 ,unlink 删除文件
隐式回收系统资源,操作系统会在程序运行结束的时候回收资源
readlink命令读符号链接真正存的东西,其实就是存储路径名,因为就是快捷方式
函数:getcwd,当前工作目录, get current working directory
chdir 改变当前工作目录
目录也是一个”文件”,可以用
函数opendir closedir , readdir,没有写目录,直接操作目录就可以了
dirent 返回结构体主要解析文件的名字
递归获取文件目录:
1 获取到目录名
空则是当前目录
2 如果是一个文件名,直接输出 S_ISDIR
3 遇到目录,递归调用,注意还要加上绝对路径,sprintf相对strcat好用
dup
dup2 重定向一个fd到一另个fd里面,对新fd的操作就是对旧的fd的操作,就是指针那回事
fctl函数也是可以实现dup的功能,重定向文件
进程:
程序和进程,程序是二进制文件,放在磁盘,不占用内存,加载的时候,产生进程,
存储介质大小:网络>硬盘>内存>cache>寄存器
寄存器4k,位于cpu, 基于经济考虑
二进制进入CPU.预读器,入译码器,开始算数逻辑单元,然后再回写数据到寄存器堆,寄存器堆然后写入CACHE,内存,一级级下来
MMU:虚拟内存映射单元
0-4G,32位系统,
4-3G,是内核区,有一个PCB,进程控制块,可用范围为4G,常量区,代码段,数据段,等在下面,MMA作用,将虚拟地址和实际地址的一个映射,一个页就是4K,寄存器也是4K,MMU也是4K,两个进程通过MMU映射,即便映射的值一样,也是分开的,无关
以一个数组为例子,假如数组很长,但是内存条没有一段连续的地址,MMU就会分开映射,
但是内核区域通过MMU映射的东西还是一样的,不会分块,因为一个计算机只有一个操作系统
用户级是3级,而内核是0级,完成这个层级切换比较慢,
PCB:
进程ID,进程状态,进程切换需要保存和恢复的一些CPU寄存器,描述虚拟地址空间信息,描述控制终端的信息,当前工作目录,umask掩码,文件描述符表,包含很多指向file结构体的指针,和信号相关的信息,用户ID和组ID,回话和进程组,进程可以使用的资源上限,
ps aux 可以查看各个进程的信息
echo $PATH命令 打印路径信息
一些环境变量:PATH SHELL TERM LANG HOME
进程fork之后,子会复制父,但是fork之前执行的东西就不会复制了 ,之后的就会复制,顺序执行一次,函数,getpid getppid
父子进程的关系:
相同: 全局变量,data,text,栈,堆,环境变量,用户ID,宿主目录,进程工作目录,信号处理方式
不同:进程ID fork返回 父进程ID 进程运行时间 闹钟 未决信号值,
看似子进程复制了父进程0 -3 G的内容,实际上,为了节省物理内存空间,按照”读时共享,写时复制”的原则,因此,对于全局变量,全局变量就不会共享了,写的时候就复制一次 ,
重点:进程间共享1.文件描述符号,2.mmp建立的映射区
execlp执行失败才返回
可以这样写:
execlp(“ls”, “ls”,””“-l”,”-d”,”NULL”);
perror(“execlp error”);
exit(1);
注意在这里需要一个NULL变量作为哨兵,最后如果返回说明错误,执行一下dbg输出,并且结束
execl(“/bin/ls”,”ls”, “-l”);这样使用
execvp 将参数封装成数组
exec族的函数都是库, execve是系统调用
孤儿进程:父先死 ,子被init收养 ,收养的作用是为了回收子进程回收之后的资源
僵尸进程:死亡时候没有进行回收的那一段过程,强行回收,将父亲杀死,让init收养即可
wait(&status)函数,也可以传一个空值,不关心,
如果wait(NULL) 只能回收一个子进程,那个返回就回收那个,无差别回收
进程结束之后PCB保存信息,死亡原因,正常则清除,不正常保留死亡信号,然后由父进程回收
父进程调用有三个功能:1.阻塞等待子进程返回,2.回收子进程残留资源.3.获取子进程结束状态
返回一个参数,将其作为一个参数调用库里面的诸多宏,获取其退出值,死亡信息等
一些比较常用的宏函数:WIFEXITED WEXITSTATUS WIFSIGNELED WTERMSIG
(不常用)WIFSTOPPED WSTOPSIG WIFCONTINUED
waitpid(pid_t pid, int status, int option) 也是回收的函数,
如果pid是0,则是顺便一个子进程
如果是0,就是组内的同组子进程
<-1 组内任意一组,
-1 回收某个组内任意子进程
可以设置堵塞状态 option WNOHAND 不挂起
返回值>0 成功回收的子进程ID
0:函数调用制定 WNOHANG ,并且没有子进程结束
-1 失败 error
如果想要回收所有的,只能通过循环进行回收,
while(wpid = waitpid(-1,NULL,0))
{
}
进程间通信:
- 内核缓冲区,一般是4096k,管道,最简单的方式
- 信号,开销最小
- 共享映射区,没有血缘关系
- 本地套接字,最稳定,但是实现的复杂性最高
管道:作用于有血缘关系的进程之间
- 本质是一个伪文件
- 两个文件描述符引用,一个读端,一个写端
- 规定从写进去,读端出来
缺陷:
- 数据不能自己写,自己读
- 管道中数据不能反复读取
- 采用半双工的方式
4.只能在有共同祖先的进程间使用管道
文件有一些叫做伪文件,不占用实际的磁盘空间,使用内存空间
管道的使用:
pipe函数:创建并且打开管道
int pipe(int fd[2]) f[0]读端 f[1]写端
失败-1 ,成功0
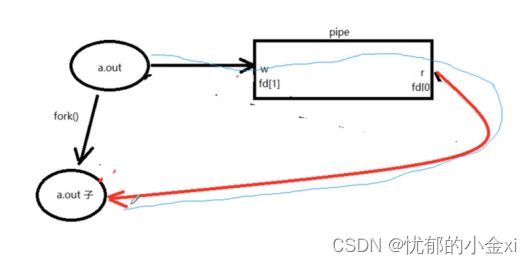
读端关闭写端,写端关闭读端
管道的读写行为,注意4个情况
- 所有写都关闭,read空管道会返回0
- 有写,但是pipe空,read阻塞
- 读都关闭,write会受到信号SIGPIPE,
- 读还有,pipe满,write会堵塞
兄弟进程间通信:
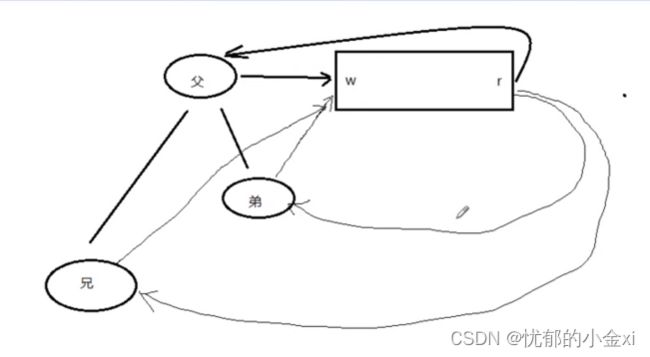
对于兄弟之间的管道通信,要将父进程的读端写端进行关闭才能关闭
实际上允许一个pipe有一个写端,多个读端,或者多个写端,一个读端,但是这样的场景尽量避免
可以使用ulimit -a命令查看当前系统中所创建管道的内核缓冲区大小
可以使用函数fpathconf查看各种参数,比如文件名字最大值,输入的最大值,这些都是和缓存相关,因此有一些限制.
有名管道FIFO
其实也是在内核里面的一个通道,主要是为了解决无血缘进程之间的通信,
为什么管道需要有血缘呢,因为父进程在fork子进程的时候将数据都copy了一份给子进程,子进程自然而然地获取到了管道的读端和写端,但是这个没有血缘的进程无法拥有这个管道的读写fd
函数mkfifo ,当做一个文件就可以了 ,常见的close read等文件操作都可以适用于他
共享存储映射
使用文件通信:
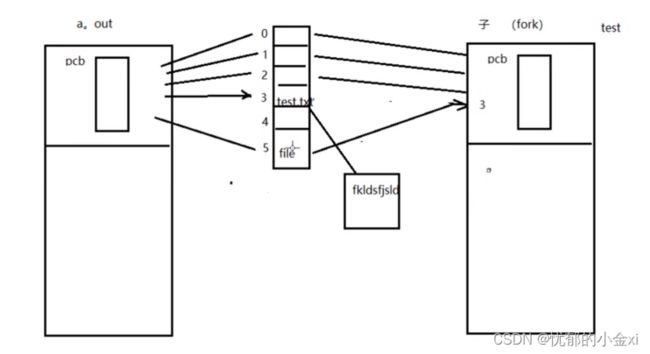
因此,没有亲缘关系的进程也可以进行通信,因为就是同一个文件
存储映射I/O
使一个磁盘文件与存储空间中的一个缓冲区相映射,于是当缓冲区中取数据,就相当于读文件中的相应字节,于此类似,写数据到缓冲区,就是将字节自动写入文件,
使用mmap函数作这个事情
mmap(void &addr, size_t length, int prot, int flags, int fd, off_t offset);
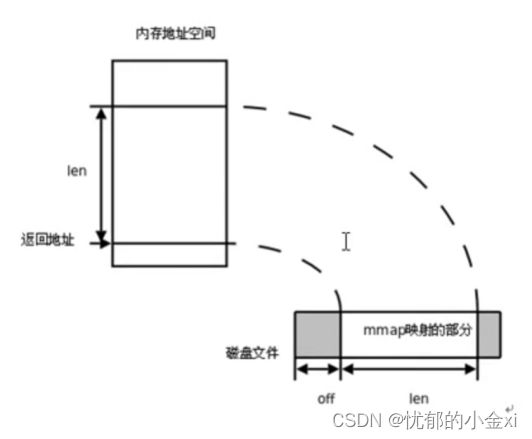
参数
addr:制定映射区的首地址,通常是NULL,系统自动分配即可
length: 共享内存区域的大小 (<=文件的实际大小)
prot: 共享内存映射区的读写属性,PROT_READ PROT_WRITE,表示读写用|,
flags:标注共享内存的共享属性,MAP_SHARED/MAP_PRIVATE(私有的,不会修改磁盘上的文件)
fd: 用于创建内存映射区的那个文件的文件描述符
offset:偏移位置的取值,需是4k整数倍,默认0,表示映射文件全部
返回
成功:映射区的首地址,
失败:MAP_FILED,设置全局error,
创建空文件,使用open,然后使用lseek扩展一下长度,但是这样不能实际扩展,需要使用write操作进行实际上的扩展大小,”\0”,
当然也可以使用truncate,
使用mmap之后就是对返回的内存映射做的字符串操作了,注意要赋予写权限
munmap(void *addr, size_t length)则是释放这个区域,老规矩,-1则是返回
mmap使用的注意事项:
- 创一个空文件,但是mmap创建一个比其大的,就会出现总线错误
- 如果空文件,长度为0传参,也会出错
- 如果文件只读,mmap属性为读写,也会出错
- 创建映射区,mmap权限<=文件权限,文件创建只写不允许
- 文件描述符fd,mmap创建完就可以关闭,后续使用地址访问
- offset必须是4096的整数倍,MMU映射的最小单位就是4k
- 不要对返回指针进行越界操作
- 不要对指针自增
- 要对mmap调用的返回值都要进行检查
- 映射区访问权限为私有的,对内存的修改,只在内存生效,不会反应到物理磁盘
- 映射区访问权限为私有,只需要open文件,有读权限,用于创建映射区也可以
使用mmap的保险方式
1.fd = open(“文件名”,O_RDWR)
- mmap(NULL, 有效文件大小, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0)
mmap父子进程通信
先创建共享,再进行fork,对于private,父子进程不共享,shared才共享
mmap非血缘关系通信,只要open的时候的名字相同就可以了
跟管道不同是,管道读走了就没了,这个还是存在的,就像文件一样不会清除除非关闭
匿名映射:(只能用于有血缘关系的进程里面)
由于映射区的使用比较麻烦,这个简单
信号:
简单.不能携带大量的信息.满足条件才发送,
机制:和硬件的中断有点相似,异步模式 ,软件层面的”中断”,所有的信号的产生和处理都是交给内核完成