TT U-Net: Temporal T ransformer U-Net for Motion Artifact Reduction using PAD in Cardiac CT
TT U-Net: 使用Pseudo All-phase临床数据集在心脏CT中减少运动伪影的Temporal Transformer U-Net
![]()
论文链接:https://ieeexplore.ieee.org/document/10236564
项目链接:https://github.com/ivy9092111111/TT-U-Net
Abstract
心脏不自主运动仍然是心脏计算机断层扫描(CT)成像的一个挑战。虽然心电图门控策略被广泛应用于准静止心脏期的CT扫描,但对于心率高或节律不规律的患者,运动诱发的伪影仍然不可避免。动态心脏CT,提供心脏的功能信息,遭受更严重的运动伪影。在本文中,我们开发了一个基于深度学习的框架,用于动态心脏CT的运动伪影减少。首先,我们基于全心运动模型和单相心脏CT图像构建了PAD(伪全期临床数据集)。该数据集提供了动态CT图像,具有逼真的运动伪影,有助于开发数据驱动的方法。其次,根据运动伪影的动态特性,将运动伪影减少问题表述为视频去模糊任务。为了更好地减少运动伪影,提出了一种新的temporal transformer U-Net (Temporal Transformer U-Net)算法。沿时间维度的自注意机制有效地编码运动信息,从而有助于图像恢复。实验表明,基于PAD训练的TT U-Net在临床CT扫描上表现良好,验证了该方法的有效性和良好的泛化能力。
I. INTRODUCTION
心脏CT是一种很有前途的成像技术。心脏CT具有无创成像和高空间分辨率的特点,能显示心脏的精细结构,在心脏疾病的评估中发挥重要作用。然而,目前心脏CT系统的时间分辨率仍然有限。由此产生的运动伪影不仅阻碍了解剖结构的准确重建,也阻碍了心脏功能CT的成像。
CT硬件的最新发展使心脏CT更容易执行,并提供更少的运动伪影图像。最先进的多排CT系统配备了大面积探测器,可以在一次跳动内对整个心脏进行成像。快速龙门旋转也实现了直接提高时间分辨率。不幸的是,即使更快的龙门速度也超出了今天的机械极限。双源和多源扫描仪已被提出用于更短的采集时间b[4], b[5],但成本增加相当大。心电图(ECG)门控扫描协议将数据采集与心电信号同步,因此CT成像可以在适当的心脏阶段进行,以减少运动伪影和辐射剂量[6],[7]。上述技术共同提高了心脏CT系统的时间分辨率。然而,单靠硬件来进一步提高时间分辨率变得越来越困难。
图像重建算法是现代CT系统的重要组成部分。对于心脏CT成像,运动补偿重建(MCR)方法是消除运动伪影的主要方法。利用估计的运动模型,在更宽的时间窗内收集的投影数据可以用来重建运动物体。通过基于图像的[8]、[9]算法、基于部分角度重建(PAR)的[10]、[11]算法和正向投影匹配方法[12]、[13],可以获得估计的运动模型。然而,运动模型优化困难和计算成本高是其局限性。
与传统的CT重建算法相比,基于深度学习的方法具有竞争力的性能和计算效率[14]。2019年,一项可行性研究表明,CNN在运动伪影识别和量化方面可以达到很高的精度[15]。随后,提出了两种不同的降低心脏CT运动伪影的策略。一种是用后处理的方法恢复退化的图像[16],[17],另一种是用传统的方法用深度神经网络[18],[19]来模拟心脏运动。然而,在开发基于深度学习的心脏CT成像方法方面存在两个共同的挑战:1)缺乏适当的数据集来训练和评估数据驱动模型;2)缺乏高容量网络模型来处理时空数据。
配对数据集提供匹配的参考图像和伪影扰动图像,是深度学习研究的理想数据集。不幸的是,配对的临床数据对于心脏CT成像来说非常稀缺。Gong等人最近进行了初步的尝试。他们从临床双源CT系统获取了40个心脏CT检查,并从双源数据和单源数据重建图像,以获得不同的时间分辨率。这两组图像被视为成对样本。然而,双源CT的可用性仍然有限,没有公开的数据集。心脏运动伪影的计算机模拟也很困难,因为它依赖于动态和真实的运动校正图像。众所周知的4D扩展心脏-躯干(XCAT)phantom[21]提供了心脏运动的参数化模型,但数字phantom的外观与真实CT图像有很大不同。另一方面,具有真实外观的单相临床心脏CT图像(通常处于准静止心脏期)是可用的。然后,研究人员使用合成运动场来扭曲冠状动脉,模拟运动伪影[15],[18],[19]。冠状动脉运动伪影是可控的,但它们局限于血管周围相对较小的区域,而心肌的运动被忽略了。
同时,动态心脏CT的深度学习模型目前研究不足。心脏CT可能提供心脏的功能信息(例如,动态心肌灌注CT[1]和经导管二尖瓣置换术前动态CT[22])。此外,先前的研究表明,运动伪影的出现在沿时间维度[23]的典型模式中。将运动伪影减少作为视频去模糊任务并采用时空模型是合理的。在更广泛的动态医学成像背景下,研究人员提出了几种改进的模型来处理高维时空信息。Zhi等人提出了一种基于2D+时间卷积的CycN-Net对CBCT[24]进行动态去噪。同样,Hauptmann[25]提出了用于心脏MR成像的二维+时间U-Net,该U-Net不区分空间和时间维度。相反,Lyu等人提出了一种先进的双向卷积长短期记忆神经网络(ConvLSTM NN)来独立建模时间信息[26]。一般来说,一个强大的网络模型应该与心脏运动的生理特性相适应。由于心脏运动的不均匀性,准静止阶段的图像产生的运动伪影较少,应该对整个系列的运动伪影减少做出更大的贡献。此外,心脏运动是准周期性的,两个距离较远的帧可能具有相似的空间特征。因此,局部和全局时间信息是互补的。由于CNN和RNN在建模远程依赖关系方面效率较低,我们认为它们不是心脏CT成像的最佳选择。
为了解决上述两个问题,我们提出了一个伪全阶段临床数据集(PAD),然后利用它来训练一个专门设计的temporal transformer U-Net (TT U-Net)。具体来说,PAD是通过4D心脏运动模型和各种单相临床CT图像来构建的。因此,它不仅包含了整个心脏在一个完整的心脏周期中的运动,而且具有逼真的外观。此外,PAD还为数据驱动模型的监督学习和定量评估提供配对样本。在此基础上,我们进一步设计并训练了一种新的TT U-Net,用于心脏CT的运动伪影还原。在TT U-Net中,提出了temporal transformer层(TTL)来整合具有自关注的全局和局部时间特征。通过PAD和实际临床心脏CT扫描的综合实验证明了该方法的有效性和推广能力。
II. METHOD
在本节中,我们首先阐述了心脏CT中的运动伪影减少问题。然后,介绍了该框架的主要组成部分,包括PAD和TT U-Net模型。
A. 运动伪影减少问题公式
心脏CT图像重建被认为是一个动态逆问题,因为被成像对象(心脏)在数据采集过程中经历了一个时间演化。具体来说,心脏CT成像的数学表达式为:
p ( t ) = A ( t ) f ( t ) + e ( t ) , (1) p(t)=A(t)f(t)+e(t), \tag{1} p(t)=A(t)f(t)+e(t),(1)
式中, p ( t ) p(t) p(t)为时刻t采集的投影数据, A ( t ) A(t) A(t)为正向投影算子, f ( t ) f(t) f(t)为动态图像, e ( t ) e(t) e(t)为测量误差。基于短扫描Feldkamp-Davis-Kress (FDK)算法[27]的重构图像为:
f F D K ( t s ) = ∑ t ∈ T s A − 1 ( t ) W ( t , p ′ ( t ) ) , (2) f_{FDK}(t_s)=\sum_{t\in T_s}\mathbf{A}^{-1}(t)\boldsymbol{W}(t,\boldsymbol{p}^{'}(t)), \tag{2} fFDK(ts)=t∈Ts∑A−1(t)W(t,p′(t)),(2)
其中, t s t_s ts为所选择的重构相位, T s T_s Ts为以 t s t_s ts为中心且获得足够投影数据进行短扫描重构的时间窗, A − 1 ( t ) A^{−1}(t) A−1(t)为反向投影算子, p ′ ( t ) p′(t) p′(t)为滤波后的投影数据, W ( ⋅ ) W(·) W(⋅)为短扫描FDK重构的加权函数。由于时空模糊性,在 f F D K f_{FDK} fFDK上观察到运动伪影。
为了实现MCR方法,将动态图像 f ( t ) f(t) f(t)重新表述为目标图像 f ( t s ) f(t_s) f(ts)的时变变形。变形场 D F ( t s , t ) DF(t_s, t) DF(ts,t)描述了心脏从所选相位 t s t_s ts到任意相位t的运动:
f ( t ) = D F ( t s , t ) ∘ f ( t s ) , (3) f(t)=\boldsymbol{DF}(t_s,t)\circ\boldsymbol{f}(t_s), \tag{3} f(t)=DF(ts,t)∘f(ts),(3)
其中 ◦ ◦ ◦是图像扭曲操作。如果存在估计的运动模型 D F ~ ( t s , t ) \tilde{ DF}(t_s, t) DF~(ts,t),则通过稍微修改公式(2)来实现MCR。例如,backprojection-then-warp (BPW)方法[28]有助于减少运动伪影,如下所示:
f B P W ( t s ) = ∑ t ∈ T s D F ~ − 1 ( t s , t ) ∘ ( A − 1 ( t ) W ( t , p ′ ( t ) ) ) . ( 4 ) (4) f_{BPW}(t_{s})=\sum_{t\in T_{s}}\tilde{\boldsymbol{DF}}^{-1}(t_{s},t)\circ(\boldsymbol{A}^{-1}(t)\boldsymbol{W}(t,\boldsymbol{p}^{'}(t))).\quad(4) \tag{4} fBPW(ts)=t∈Ts∑DF~−1(ts,t)∘(A−1(t)W(t,p′(t))).(4)(4)
同时,最近基于深度学习的方法也允许在没有运动模型的情况下减少运动伪影。在这种情况下,通常将其表述为图像后处理问题。一般来说,基于学习的问题可以建模如下:
a r g min θ 1 N Ω ∑ { f ^ , f } ∈ Ω L ( G ( f ^ , θ ) , f ) , (5) arg\min_{\theta}\frac{1}{N_{\Omega}}\sum_{\{\hat{f},f\}\in\Omega}\mathcal{L}(\boldsymbol{G}(\hat{\boldsymbol{f}},\boldsymbol{\theta}),\boldsymbol{f}), \tag{5} argθminNΩ1{f^,f}∈Ω∑L(G(f^,θ),f),(5)
其中, G ( ⋅ , θ ) G(·,θ) G(⋅,θ)为具有可训练参数θ的图像去模糊模型, f f f为退化图像(例如 f F D K f_{FDK} fFDK), L ( G ( f , θ ) , f ) L(G(f, θ), f) L(G(f,θ),f)衡量恢复图像与真实图像 f f f之间的差异。通过在包含 N Ω N_Ω NΩ训练对的适当数据集 Ω Ω Ω上对公式(5)进行优化,获得学习参数 θ θ θ。
我们将展示如何建立一个数据集 Ω Ω Ω,然后在以下小节中训练一个定制的网络模型来减少运动伪影。
B. 伪全期临床数据集(PAD)
PAD提供配对的伪全期临床心脏CT图像。心脏运动伪影源于心脏和CT系统之间的相对运动。因此,少运动伪影的动态心脏CT图像成为运动伪影仿真的前提。由于此类真实数据的缺乏,我们首先从合成参考伪全期临床CT图像开始。我们期望合成图像既动态又真实。直观地说,它是通过用全相心脏运动模型动画单相临床图像来实现的(见图1中的工作流程)。然后,根据公式(1)和公式(2)通过计算机模拟CT扫描生成人工干扰的伪全相临床CT图像。在本文中,心脏运动模型提取自XCAT模型[21],真实心脏解剖来自MICCAI 2017多模态全心分割(MM-WHS)数据集[29]。通过涉及更多的单相临床CT图像,PAD可以很容易地扩展。

1) 心脏运动模型:需要人工运动场来动画单相临床CT(图1.B)。我们建立了一个4D统计形状模型(4D SSM)来产生个性化的心脏运动。4D SSM能够从一组训练形状中描述解剖学上相应的地标的时空分布。为了构建4D SSM,我们使用了21个4D XCAT模型,分别对应21名志愿者。根据经验,对于每个4D幻像,在整个心脏周期中以5% R-R间隔采样3D体积,从而得到20个体积来描述整个心脏周期。我们首先将每个3D体转换为点分布模型(PDM),并在参考坐标系中对齐它们。4D SSM是按照Perperidis的方法[30]建立的。如果一个临床四维数据集是可用的,人们可以遵循Hoogendoorn的工作[31]来建立四维SSM。
设 { s X C A T i , j ∈ R 3 M ∣ i = 1 , … , N i ; j = 1 , … , N j } \left\{s_{XCAT}^{i,j}\in\mathbb{R}^{3M}|i=1,\ldots,N_{i};j=1,\ldots,N_{j}\right\} {sXCATi,j∈R3M∣i=1,…,Ni;j=1,…,Nj}表示具有 N j N_j Nj相的 N i N_i Ni 4D XCA T影形。三维空间中的每个形状 s X C A T i , j s^{i,j}_{XCAT} sXCATi,j由 M M M个三维曲面地标组成。采用主成分分析(PCA)来描述这些样本之间的各种解剖结构和心脏运动:
s X C A T i , j ( b a n a t o m y i , b m o t i o n i , j ) = s ˉ + P a n a t o m y b a n a t o m y ı + P m o t i o n b m o t i o n i , j , (6) \begin{aligned} s_{XCAT}^{i,j}(\boldsymbol{b}_{anatomy}^{i},\boldsymbol{b}_{motion}^{i,j})& =\bar{s}+\boldsymbol{P}_{anatomy}\boldsymbol{b}_{anatomy}^{\imath} \\ &+\boldsymbol{P}_{motion}\boldsymbol{b}_{motion}^{i,j}, \end{aligned} \tag{6} sXCATi,j(banatomyi,bmotioni,j)=sˉ+Panatomybanatomy+Pmotionbmotioni,j,(6)
s ˉ \bar{s} sˉ是平均形状。 P a n a t o m y ∈ R 3 M × N a P_{anatomy}∈R^{3M×N_a} Panatomy∈R3M×Na描述了不同志愿者的心脏解剖差异。 P a n a t o m y P_{anatomy} Panatomy的列是协方差矩阵的正交特征向量:
C a n a t o m y = 1 N i ∑ i = 1 N i ( s i , ∗ − s ˉ ) ( s i , ∗ − s ˉ ) T , (7) \boldsymbol{C}_{anatomy}=\frac{1}{N_{i}}\sum_{i=1}^{N_{i}}(\boldsymbol{s}^{i,*}-\bar{\boldsymbol{s}})(\boldsymbol{s}^{i,*}-\bar{\boldsymbol{s}})^{T}, \tag{7} Canatomy=Ni1i=1∑Ni(si,∗−sˉ)(si,∗−sˉ)T,(7)
其中 s i , ∗ s^{i, *} si,∗是每种情况下参考阶段的形状。
公式(6)中的双解剖是不同解剖模式的权重,通过投影归一化形状 S i = ( s i , 1 − s ˉ , s i , 2 − s ˉ , … , s i , N j − s ˉ ˉ ) \mathbf{S}^{i}=(\mathbf{s}^{i,1}-\bar{\mathbf{s}},\mathbf{s}^{i,2}-\bar{\mathbf{s}},\ldots,\mathbf{s}^{i,N_{j}}-\bar{\mathbf{\bar{s}}}) Si=(si,1−sˉ,si,2−sˉ,…,si,Nj−sˉˉ)投影到本征模 P a n a t o m y P_{anatomy} Panatomy上而获得。公式(6)中的 P m o t i o n ∈ R 3 M × N m P_{motion}∈R^{3M×N_m} Pmotion∈R3M×Nm描述了不同心脏期之间的运动变异性。 P m o t i o n P_{motion} Pmotion的列是协方差矩阵的正交特征向量:
C m o t i o n = 1 N i N j ∑ i = 1 N i ∑ j = 1 N j ( s i , j − s i , ∗ ) ( s i , j − s i , ∗ ) T . (8) \boldsymbol{C}_{motion}=\frac{1}{N_{i}N_{j}}\sum_{i=1}^{N_{i}}\sum_{j=1}^{N_{j}}(\boldsymbol{s}^{i,j}-\boldsymbol{s}^{i,*})(\boldsymbol{s}^{i,j}-\boldsymbol{s}^{i,*})^{T}. \tag{8} Cmotion=NiNj1i=1∑Nij=1∑Nj(si,j−si,∗)(si,j−si,∗)T.(8)
为了估计公式(6)中的运动权重 b m o t i o n i , j b^{i,j}_{motion} bmotioni,j,我们将心动周期内的位移矢量 S d i s = ( s i , 1 − s i , ∗ , s i , 2 − s i , ∗ , … , s i , N j − s i , ∗ ) \mathbf{S}_{dis}=(s^{i,1}-s^{i,*},s^{i,2}-s^{i,*},\ldots,s^{i,N_{j}}-s^{i,*}) Sdis=(si,1−si,∗,si,2−si,∗,…,si,Nj−si,∗)投影到本征模 P m o t i o n P_{motion} Pmotion上。
利用公式(6)中的运动信息,使单相临床CT图像“再次跳动”的一种方法是采用训练XCAT样本之间的平均运动:
KaTeX parse error: Can't use function '$' in math mode at position 2: $̲s_{PAD}^j=s_{cl…
式中, s P A D j s^j_{PAD} sPADj为第j期的预测形状模型, s c l i n i c a l s_{clinical} sclinical为临床图像初始阶段的归一化形状模型, b m j o t i o n ‾ \overline{b^j_motion} bmjotion运动为第 j j j期的平均运动权值。另一种方法是进一步对运动权值[32]进行PCA来生成各种运动模型。到目前为止,我们已经从单相临床图像中获得了动态形状模型(图1.B)。在之前的研究中,动态形状模型随后被用于心功能的评估。在CT图像重建的研究中,我们进一步合成了伪全相位CT图像。
2) 从单相临床图像合成伪全期心脏CT:我们使用基于深度学习的ShapeMorph模型来填补动态形状模型与伪全期CT图像之间的空白。将动态形状模型以分割图的形式转换为图像体,并输入到ShapeMorph模型中(图1.C)。ShapeMorph是改进的VoxelMorph模型[33]。它不是将一对三维图像作为输入,而是从一对分割图中预测密集的变形场。ShapeMorph模型以类似于VoxelMorph的自监督方式在XCAT数据集上进行训练。通过将每个分割图与参考相位的分割图配准,得到一系列变形场 D F P A D ( t c l i n i c a l , t ) DFP_{AD}(t_{clinical}, t) DFPAD(tclinical,t)(图1.D)。为了获得更高的时间分辨率,对4D变形场进行插值,然后对原始的单相临床CT图像 f c l i n i c a l f_{clinical} fclinical进行变形,生成伪全相CT图像(图1. E):
KaTeX parse error: Can't use function '$' in math mode at position 2: $̲f_{PAD}^{t}=\bo…
3) 心脏运动伪影仿真:心脏运动伪影仿真:PAD的示例图像如图2所示。伪全相变形场(图2(a1)(a5))描述了参考伪全相图像(图2(b1)-(b5))的心脏运动。与参考伪全相位图像,我们然后获得伪影干扰图像使用计算机模拟的CT扫描。具体来说,锥束投影数据使用公式(1)与真实的CT扫描几何模拟。由于龙门旋转的时间不可忽略,所以投影数据是从不同阶段的参考图像中收集的。使用公式(2)进行短扫描FDK重建。由于图像重建需要在一个时间窗口Ts(大多数情况下,Ts不短于半个龙门架旋转周期)内收集投影数据,因此重建图像将包含混合的时空信息,呈现模糊的外观。根据CT扫描的几何形状,伪影干扰图像将进一步包括不规则的冠状动脉运动伪影,如新月形(图2(c2)-(c3))、尾巴(图2(c5))和角状(图2(c4))伪影[23]。该方法获得了具有逼真的全心运动伪影和相应的ground truth的图像。

在图3中,我们给出了模拟PAD图像与临床多期心脏CT图像之间的视觉比较。可以看出,PAD提供了高质量的图像,合成图像与临床图像在视觉上难以区分。PAD图像显示出逼真的运动伪影,甚至冠状动脉伪影的演变模式也非常相似。

C. TT U-Net
心脏CT的动态特性使其区别于其他CT成像问题。在PAD的帮助下,可以以数据驱动的方式建模和利用心脏CT图像的时空相关性。因此,我们提出了一种新的TT U-Net用于动态数据。首先,我们将公式(5)扩展到视频去模糊问题:
a r g min θ 1 N Ω ∑ { F ^ , F } ∈ Ω L ( G ( F ^ , θ ) , F ) , (11) arg\min_{\boldsymbol{\theta}}\frac1{N_{\Omega}}\sum_{\{\hat{\boldsymbol{F}},\boldsymbol{F}\}\in\Omega}\mathcal{L}(\boldsymbol{G}(\hat{\boldsymbol{F}},\boldsymbol{\theta}),\boldsymbol{F}), \tag{11} argθminNΩ1{F^,F}∈Ω∑L(G(F^,θ),F),(11)
其中, F ^ = { f ^ ( t 1 ) , f ^ ( t 2 ) , … , f ^ ( t N c ) } \hat{\boldsymbol{F}}=\left\{\hat{\boldsymbol{f}}(t_{1}),\hat{\boldsymbol{f}}(t_{2}),\ldots,\hat{\boldsymbol{f}}(t_{N_{c}})\right\} F^={f^(t1),f^(t2),…,f^(tNc)}表示降级的心脏CT视频片段, F = { f ( t 1 ) , f ( t 2 ) , … , f ( t N c ) } \boldsymbol{F}=\{\boldsymbol{f}(t_{1}),\boldsymbol{f}(t_{2}),\ldots,\boldsymbol{f}(t_{N_{c}})\} F={f(t1),f(t2),…,f(tNc)}表示ground truth视频clip。 N c N_c Nc是每个视频clip的长度。本文将 N c N_c Nc设为48。
1) 总体架构:TT U-Net架构如图4所示。U-Net[34]已被证明是一种有效且轻量级的图像去模糊模型,因此它是所提出模型的支柱。层次结构对空间信息建模具有一定的灵活性,并能提供多分辨率的特征图。为了捕捉动态CT图像之间的时间关系,我们用所提出的Temporal Transformer层(TTL)取代了跳过连接模块,该层为时间建模引入了自注意机制。由于TTL主要在时间维度上工作,因此该模型具有较好的性能和较高的效率。请注意,我们在实验中省略了最高分辨率层中的TTL,以实现更快的训练和推理(有关更多信息,请参阅第IV -C节)。对于U型神经网络的解码器部分,使用三维卷积来整合来自每个分辨率的时空特征。

2) Temporal Transformer层(TTL):所提出的TTL包含一个patch和位置嵌入层、一个标准transformer编码器块和一个patch非嵌入层,如图4(b)所示。与著名的ViT[35]和Swin Transformer[36]不同,本文提出的TTL侧重于时间建模。为此,TTL不是在整个图像或空间窗口内计算自注意,而是在时间窗口内进行自注意。TTL的输入是一个时空特征图 X ∈ R B × N c × C × H × W X∈R^{B×N_c×C×H×W} X∈RB×Nc×C×H×W,其中B、Nc、C、H、W分别表示特征图的批大小、相位数、通道数、高度和宽度。使用patch和位置嵌入层将高维特征映射转换为一系列patch嵌入。具体而言,我们首先在空间维度上将特征映射分割为不重叠的 B H W P 2 × N c × C × P × P \frac{BHW}{P^{2}}\times N_{c}\times C\times P\times P P2BHW×Nc×C×P×P块。之后,除时间维外,每个高维斑块被平化,并转换为 N C × C P P N_C × CPP NC×CPP嵌入。每个标记用可训练的投影层进一步投影到 N C × D N_C × D NC×D空间。贴片嵌入层以较低的计算复杂度扩大了空间感受场。为了保留位置信息,我们还在patch嵌入中添加了位置嵌入。然后,两个级联的Transformer块对时空信息进行整合和处理。在Transformer块内,标准多头自注意在NC大小的时间窗口中进行,以探索不同心相之间的整体相互作用。patch解嵌层执行重塑操作。它从处理过的patch嵌入中恢复特征映射,并为U-Net的解码器部分提供输入。
III. EXPERIMENTS
A. 比较方法
比较了五种著名的算法。1)Parker加权短扫描FDK法[27]。2) PAR方法[10],是一种高效、高性能的MCR方法。3) 2D+time U-Net[25],为动态成像设计的全卷积神经网络。4) ConvLSTM NN[26],是一种基于LSTM的动态成像神经网络。5) VRT[37],这是一种基于Transformer的神经网络,专为自然视频还原而设计。VRT采用TMSA (temporal mutual self-attention)模块对时空信息进行同步编码。由于每个TMSA模块的时间窗口大小有限,VRT采用移位窗口策略逐步扩大时间感受野。通过比较,TT U-Net可以有效地对每个TTL内的远程依赖关系进行建模。后三种数据驱动的方法在应用前需要一个训练过程。
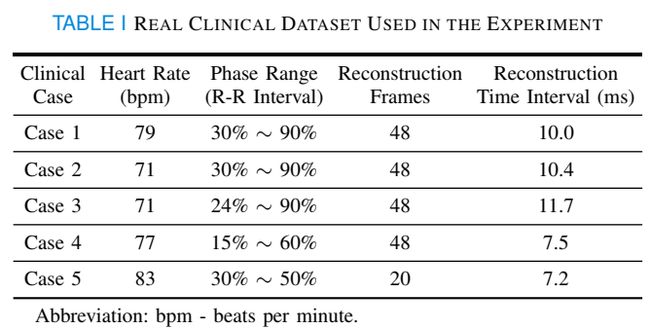
B. 数据集
1) PAD:为了建立PAD,我们从MM-WHS数据集[29]中选取43例临床一期心脏CT图像。由于其中一些图像缺乏分割标注,我们首先对这些图像进行手动分割。然后,我们使用4D SSM将单相图像转换为伪全期临床图像,如第II-B节所述。对于每个单相CT图像,我们生成了三组不同心率的参考伪全相位图像。然后,我们模拟轴向锥束CT扫描,获得伪影干扰的CT图像。几何构型如下:光源和探测器到旋转中心的距离均为1000 mm。探测器的物理尺寸为600 mm×150 mm,通道为800×200。视图采样率为每回合1000个投影视图。gantry旋转速度为每转250毫秒,如果采用短扫描重建,则时间分辨率约为135毫秒。对于每个病例,模拟扫描从随机的心脏阶段和随机的gantry角度开始,以模拟无心电图扫描协议,并提供各种运动伪影。重建图像的大小为512×512×120体素。我们裁剪并调整感兴趣区域(ROI)的大小为256×256×90体素。重建时间间隔12.5 ms的48帧图像进行动态CT成像。这些图像被逐片重组,形成视频片段,每个视频片段有48帧256×256像素图像。PAD在患者水平上随机分为3组:训练组37例,验证组3例,测试组3例。使用训练集和验证集对上述神经网络进行训练。测试集用于定量评价所有方法的性能。
2) 真实临床数据集:回顾性收集5例临床心脏CT扫描。在心电图门控轴向扫描后,使用320排CT扫描仪(uCT 960+, United Imaging Healthcare)获取投影数据。gantry 旋转速度为每转250毫秒。扫描通常在心脏收缩中期开始,在心脏舒张末期结束,但因情况而异。为了实现该方法与其他基于深度学习的比较方法,我们首先使用Parker加权短扫描FDK方法重建图像。设置适当的重构间隔,以获得除情形5外的48帧的均匀间隔图像序列。然后,我们裁剪心脏ROI,并以逐片的方式重新格式化未校正的图像,作为网络模型的输入。更详细的信息列于表1中。我们使用真实的临床数据集来评估所有方法的性能。此外,还利用该方法评价了在PAD上训练的TT U-Net的泛化能力。
C. 实现细节
为了公平的比较,我们使用相同的数据集和损失函数来训练所有的神经网络。像素L1损失和WGAN-GP对抗损失都被使用。L1损耗对低频信号的恢复效果很好,而对抗性损耗则有助于更好地重建高频细节。我们在WGAN训练过程中使用了一个具有可训练参数 θ D θ_D θD的马尔可夫判别器[39] D ( ⋅ , θ D ) D(·,θ_D) D(⋅,θD)。去模糊模型 G ( ⋅ , θ ) G(·,θ) G(⋅,θ)的总体目标函数为L1损失和对抗损失的组合:
a r g min θ 1 N Ω ∑ { F ^ , F } ∈ Ω [ L 1 ( G ( F ^ , θ ) , F ) − λ 1 E ( D ( G ( F ^ , θ ) , θ D ) ] , (12) arg\min_{\boldsymbol{\theta}}\frac{1}{N_{\Omega}}\sum_{\{\hat{\boldsymbol{F}},\boldsymbol{F}\}\in\Omega}[\mathcal{L}1(\boldsymbol{G}(\hat{\boldsymbol{F}},\boldsymbol{\theta}),\boldsymbol{F})-\lambda_{1}\mathbb{E}(\boldsymbol{D}(\boldsymbol{G}(\hat{\boldsymbol{F}},\boldsymbol{\theta}),\boldsymbol{\theta}_{\boldsymbol{D}})], \tag{12} argθminNΩ1{F^,F}∈Ω∑[L1(G(F^,θ),F)−λ1E(D(G(F^,θ),θD)],(12)
其中 λ 1 λ_1 λ1经验设置为0.001。判别器的目标函数是Wasserstein距离(前两项)和梯度惩罚(第三项)[26]的组合:
a r g min θ p 1 N Ω ∑ { F ^ , F } ∈ Ω [ E ( D ( G ( F ^ , θ ) , θ D ) ) − E ( D ( F , θ D ) ) + λ 2 E F ⃗ ∣ ∣ ∇ F ⃗ D ( F ~ , θ D ) − 1 ∣ ∣ 2 2 ] , (13) \begin{aligned}arg\min_{\boldsymbol{\theta}\boldsymbol{p}}\frac{1}{N_{\Omega}}\sum_{\{\hat{\boldsymbol{F}},\boldsymbol{F}\}\in\Omega}[\mathbb{E}(\boldsymbol{D}(\boldsymbol{G}(\hat{\boldsymbol{F}},\boldsymbol{\theta}),\boldsymbol{\theta}_{\boldsymbol{D}}))-\mathbb{E}(\boldsymbol{D}(\boldsymbol{F},\boldsymbol{\theta}_{\boldsymbol{D}}))\\\\+\lambda_{2}\mathbb{E}_{\vec{\boldsymbol{F}}}||\nabla_{\vec{\boldsymbol{F}}}\boldsymbol{D}(\widetilde{\boldsymbol{F}},\boldsymbol{\theta}_{\boldsymbol{D}})-1||_{2}^{2}],\end{aligned} \tag{13} argθpminNΩ1{F^,F}∈Ω∑[E(D(G(F^,θ),θD))−E(D(F,θD))+λ2EF∣∣∇FD(F ,θD)−1∣∣22],(13)
其中∇为梯度算子。 F ~ \widetilde{F} F 沿生成样本 G ( F ^ , θ ) G(\hat{F},θ) G(F^,θ)与实际样本F对的直线均匀采样, λ 2 λ_2 λ2经验设为10。
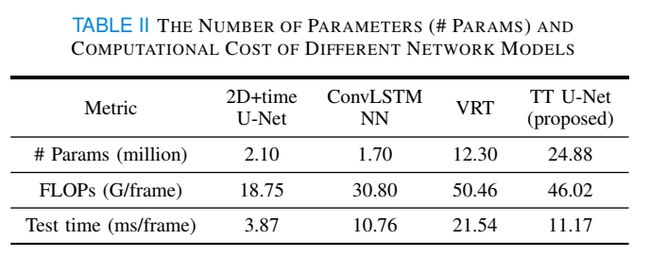
我们使用PyTorch工具箱实现了所有基于深度学习的模型,并在内存为40GB的NVIDIA Tesla A100 GPU上进行了训练。采用Adam算法对模型进行优化。学习率从10−4缓慢下降到10−5。由于内存有限,将批大小设置为1。注意,由于内存有限,我们简化了ConvLSTM神经网络和VRT的结构(该模型在原始论文中设计为7帧100×100图像或24帧64×64图像,而这里使用48帧256×256图像作为输入)。神经网络模型的参数个数和计算成本列于表2。测试时间是在内存为11 GB的NVIDIA RTX 2080 Ti GPU上测量的。采用MA TLAB R2021a进行CT重建。
D. 评估指标
模拟PAD是一个配对数据集,因此可以进行定量评估。采用结构相似性指数(SSIM)和均方根误差(RMSE)对各种方法进行评价。由于心脏运动伪影主要出现在结构边界区域(例如图2中黄色框所示的伪影),我们计算了这些局部斑块内的SSIM和RMSE。此外,我们对每个病例的右冠状动脉(RCA)进行分割,并根据ground truth图像计算Dice评分,以评估冠状动脉运动伪影还原的性能。
虽然真实的临床数据集不存在真实图像,但已经提出了几个运动伪影度量来量化重建冠状动脉的视觉质量。我们采用折叠重叠比(FOR)、低强度区域评分(LIRS)和运动伪影评分(MAS)指标在真实临床数据集上对所提出的方法进行评估。与专家读者[23]相比,这些指标在运动伪影排序方面显示出很高的一致性。在这个实验中,我们关注的是RCA。
FOR测量冠状动脉的形状。给定分割血管的二值图像,通过评估血管像素[16]的主成分特征向量确定通过分割血管质心的两个正交轴v1和v2。每根轴将血管分成两个区域 R 1 v i R^{vi}_1 R1vi和 R 2 v i R^{vi}_2 R2vi。通过 R 1 v i R^{vi}_1 R1vi按照轴向 v i v_i vi镜像,重叠比 L F O R v i L^{v_i}_{FOR} LFORvi衡量了血管的对称程度:
L F O R v i = ∣ ∣ R 1 v i ^ ∩ R 2 v i ∣ ∣ 0 / ∣ ∣ R 1 v i ^ ∪ R 2 v i ∣ ∣ 0 , (14) L_{FOR}^{v_{i}}=||\hat{R_{1}^{v_{i}}}\cap R_{2}^{v_{i}}||_{0}/||\hat{R_{1}^{v_{i}}}\cup R_{2}^{v_{i}}||_{0}, \tag{14} LFORvi=∣∣R1vi^∩R2vi∣∣0/∣∣R1vi^∪R2vi∣∣0,(14)
其中, R 1 v i ^ \hat{R^{v_i}_1} R1vi^为镜像区域。最终FOR定义为两个轴的重叠比较小:
L F O R = m i n ( L F O R v 1 , L F O R v 2 ) . (15) L_{FOR}=min(L_{FOR}^{v_{1}},L_{FOR}^{v_{2}}). \tag{15} LFOR=min(LFORv1,LFORv2).(15)
LIRS测量运动引起的阴影区域的面积和强度。在我们的实现中,我们分段低强度区,阈值为-200 HU。LIRS指标表示为:
L L I R S = 0.5 × ( 1 − A L I R A v e s ) + 0.5 × I L I R ‾ + 1024 I B G ‾ + 1024 , (16) L_{LIRS}=0.5\times(1-\frac{A_{LIR}}{A_{ves}})+0.5\times\frac{\overline{I_{LIR}}+1024}{\overline{I_{BG}}+1024}, \tag{16} LLIRS=0.5×(1−AvesALIR)+0.5×IBG+1024ILIR+1024,(16)
其中 A L I R A_{LIR} ALIR为低强度区面积, A v e s A_{ves} Aves为血管区面积, I L I R ‾ \overline{I_{LIR}} ILIR为低强度区CT均值, I I B G ‾ \overline{I_{IBG}} IIBG为背景心肌区CT均值。最后,MAS被定义为FOR和LIRS指标的乘积,以考虑血管形状和运动诱导的低强度区域。
IV. RESULTS
A. 真实临床数据集实验
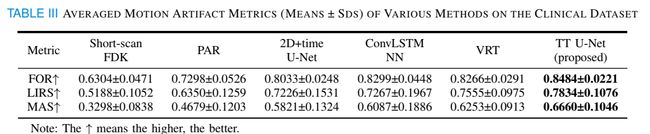
在没有微调的情况下,通过5次真实的临床扫描来评估TT U-Net在PAD上训练的有效性。在本文中,我们的目标是解决具有挑战性的问题,全相位运动伪影减少。在这里,我们介绍了不同心脏阶段的重建(病例1和病例2在舒张期,病例3和病例4在收缩期),尽管其中一些目前通常被排除在临床应用之外。图5给出了轴向视图和矢状视图中各种方法的运动伪影减小结果。在短扫描FDK图像中,在快速阶段观察到严重的运动伪影(图5(a1)-(a8))。该方法使用一对共轭PAR图像来估计心脏运动,以补偿心脏运动。心肌形状部分恢复,但由于快速运动,尾状和新月形冠状运动伪影仍然存在(图5(b1), (b3), (b7))。与传统重建方法相比,深度学习方法具有更好的视觉效果。注意,所有的神经网络都是在PAD上训练的,这证明了所提出数据集的有效性。2D+time U-Net、ConvLSTM NN和VRT都能提供更高质量的图像。然而,一些结构细节略有破坏。如图5(c3)、(c7)所示,rca是扭曲的。在图5(d3)、(d7)、(e3)中也观察到模糊的RCA。我们的TT U-Net在心肌恢复和RCA重建方面都表现出优异的性能(图5(f1)-(f8))。

为了定量地评估重建图像的视觉质量,我们在表III中给出了运动伪影度量。结果表明,基于PAD训练的神经网络能够有效提高临床真实心脏CT图像的视觉质量。此外,TT UNet实现了最高的FOR、LIRS和MAS指标。综上所述,在PAD上训练的TT U-Net可以在真实临床数据集上产生令人满意的结果。
准确的冠状动脉重建具有重要的临床价值。我们在图6中给出了临床病例1-4的矫直曲面改造(CPR)结果。在未校正图像的CPR上可以看到阴影、模糊和重影现象,而校正后的图像则更明亮、更清晰。虽然TT U-Net以逐片方式处理图像,但运动伪影减少结果在各截面上相对一致。

除了真实的心脏运动外,我们认为训练后的TT U-Net的有效性和良好的泛化能力也归功于PAD的真实外观。为了进行比较,我们构建了一个动态的XCAT数据集。利用XCAT软件,我们生成了各种4D心脏CT phantom。然后,使用与PAD相同的策略模拟具有和不具有运动伪影的配对XCAT图像(在第II-B.3节中描述)。当我们使用从XCATphantom中提取的运动模型构建PAD时,PAD和XCAT数据集共享相似的运动模式。然而,PAD中的图像来源于临床CT图像,因此具有逼真的外观,而XCA T图像是理想的数字phantom,纹理较少。我们使用FR起始距离(FID)度量来量化两个模拟数据集与真实临床数据集之间的相似性,该度量被证明与人类对视觉质量的判断有很好的相关性。FID是通过计算两个高斯函数之间的FR切距离来计算的,这些高斯函数拟合到Inception网络的特征表示中,如下所示:
F I D ( x , r ) = ∣ ∣ μ x − μ r ∣ ∣ 2 2 + T r ( C x + C r − 2 ( C x C r ) 1 / 2 ) (17) FID(\boldsymbol{x},\boldsymbol{r})=||\mu_x-\mu_r||_2^2+Tr(\boldsymbol{C}_x+\boldsymbol{C}_r-2(\boldsymbol{C}_x\boldsymbol{C}_r)^{1/2}) \tag{17} FID(x,r)=∣∣μx−μr∣∣22+Tr(Cx+Cr−2(CxCr)1/2)(17)
式中,x、r分别为模拟数据集和真实临床数据集样本的特征表示。 μ x \mu_x μx, μ r \mu_r μr是表示的平均数。 T r ( ⋅ ) Tr(·) Tr(⋅)计算矩阵的轨迹。 C x , C r C_x, C_r Cx,Cr是表示的协方差矩阵。FID越低,表明模拟数据集与真实临床数据集之间的相似性越高。如表4所示,与XCAT数据集相比,PAD实现了更低的FID。

我们在动态XCAT数据集上进一步训练了一个TT U-Net。在XCAT数据集中包含相同数量的训练样本来训练模型。如图7所示,在XCAT数据集上训练的TT U-Net的运动伪影减少结果是过度平滑的。红色箭头所示的骨区变形,部分复杂结构模糊。虽然XCATphantom提供了动态图像,但XCATphantom与临床图像之间巨大的分布差距可能导致域移位问题。相比之下,具有逼真外观的PAD将更适合深度学习研究。

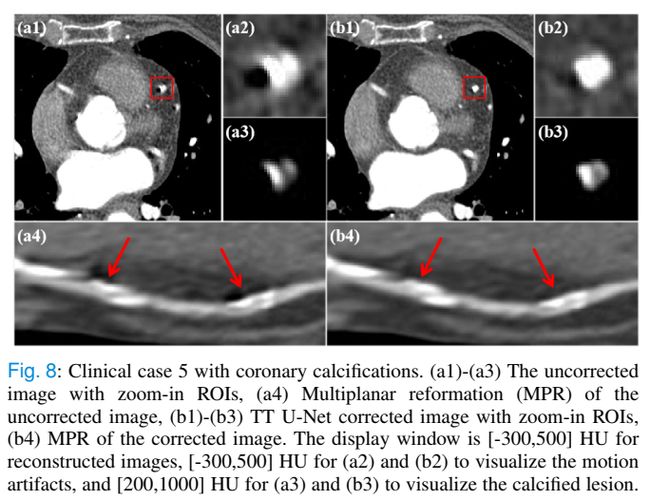
另一个临床病例如图8所示,左侧前降支可见多发钙化病灶。在ROI图像中可见典型的新月形运动伪影,致密钙化病灶的CT值较高。我们的TT U-Net可以去除运动伪影,同时以后处理的方式保持病变的形状和CT值,尽管冠状动脉钙化目前尚未包括在PAD中。它显示了我们的模型处理此类未知情况的潜力。
B. PAD的定量评价
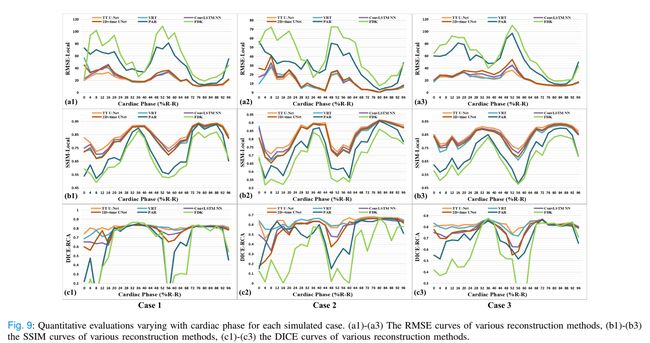
还对PAD的三个模拟病例进行了定量评估。我们使用RMSE和SSIM指标来评估心肌运动伪影还原的性能,并使用Dice评分来评估RCA重建的性能。表V显示了平均定量度量。由于心脏运动的强度随阶段而变化,

为了更好地可视化,我们在图9中绘制了度量曲线。一般来说,在心脏快速期可以看到更显著的改善。PAR方法能够在准静息期(大约心脏周期的40%和75%)改善图像质量。然而,它几乎不能补偿快速阶段的心脏运动。另一方面,所有的深度学习方法都取得了有竞争力的结果。结果表明,在PAD上训练的深度神经网络在执行去模糊任务方面具有很强的能力。然而,详细结构的恢复需要额外的时间信息,特别是对于快速移动的rca。在图9(c1)、(c3)中,2D+time U-Net和ConvLSTM NN的Dice分数在快速阶段急剧下降。相比之下,我们的TT U-Net的Dice评分的标准差明显较低,并且在病例1和病例3的整个心脏周期中,Dice评分几乎是一致的。这证明了所提出的网络模型的优越性能。
C. 消融研究
为了评估所提出的TTL模块的有效性,我们进行了三次消融研究,并比较了不同网络结构模型的性能。首先,我们在图10中给出时间剖面结果,直观地显示TTL的影响。时间剖面有助于在二维图像中呈现心脏运动。由于心脏快速运动,未校正图像的时间轮廓是模糊的。对于没有TTL的模型,也观察到严重的时间不一致。相比之下,提议的TT U-Net提供了更清晰的结果。

在第二个实验中,我们重点研究了时间窗口大小(TWS)的影响。TT U-Net计算TWS内的自注意力。因此,通过调整TWS,我们调节模型的时间建模能力。数量指标见表六。请注意,我们保留了原始TT U-Net中使用的所有变体的3D解码器,以整合时间特征。与“w/o TTL”组相比,有TTL的模型的性能都有较大的提高。这表明时间信息对于减少运动伪影是很重要的。这也表明,当辐射剂量成为主要问题时,TT U-Net可以适应较短的采集时间。另一方面,我们发现较长的序列产生更好的性能,这表明在远距离帧之间直接交互的好处。由于计算资源有限,我们将最大TWS设置为48。我们相信,如果有必要,TT U-Net可以适应更长的序列。

在第三个实验中,我们研究了TTL模块与U-Net架构的集成策略。一般来说,TT U-Net的编码器部分从原始U-Net中继承,以提取不同空间分辨率的空间特征。TTL模块随后根据分层特征映射对时序特征进行编码。表7中的定量指标评估了每个TTL的有效性。TTL1、TTL2、TTL3、TTL4分别对应不同阶段的ttl,其中1表示最低空间分辨率,4表示最高空间分辨率。TTL1实现了显著的性能提升,而在TTL4的存在下,性能趋于饱和。由于TTL1的输入来自编码器路径的更深层,它包含更高层次的空间特征,并且具有更大的接受场,可以更好地检测条纹运动伪影。此外,高维特征映射具有较小的空间尺寸,这使我们能够将我们的TT U-Net扩展到更大的模型。因此,TTL1极大地提高了模型的性能。相比之下,TTL4具有相对较小的空间接受野,并且包含较少的可训练参数。为了更好地满足临床对快速推理的需求,我们在TT U-Net中省略了TTL4。然而,TTL仍然可以扩展到更高的分辨率,并在其他任务中有效。

V. DISCUSSIONS
A. TT U-Net能“读取”动态CT图像吗?
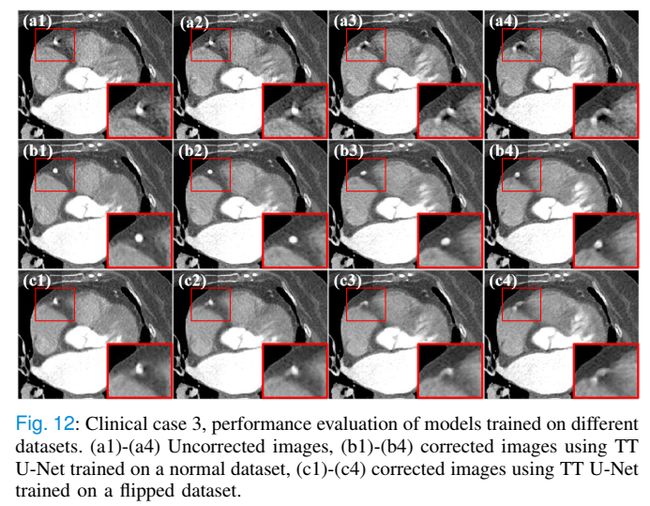
先前的研究已经证明了运动伪影的形状与CT扫描几何形状之间的关系。一个有趣的发现是,逆向旋转的CT系统在空间或时间上呈现翻转运动伪影(见图11)。这让我们想起了视觉手性的研究。在动态CT成像的背景下,运动伪影也是手性的。由于手性出现在动态CT图像上,我们称之为“运动手性”。基于这一观察,我们进行了一个实验来证明我们的TT U-Net能够感知运动。

两个TT U-Net分别在一个正常PAD和一个翻转PAD上进行了训练。除CT旋转方向外,其他设置保持不变。然后,我们在临床数据集上评估了两个训练模型的性能。如图12(b1)-(b4)所示,TT U-Net减少了大部分伪影。然而,在翻转数据集上训练的模型观察到严重的性能下降(见图12(c1)-(c4))。事实上,尽管每个单相图像上的运动伪影在视觉上相似,但运动手性导致动态图像的时空特征完全不同。因此,在翻转数据集上训练的模型不能很好地泛化反向旋转的临床图像。这一现象表明,TT U-Net不仅根据人工形状估计心脏运动,而且还根据其随时间的演变方式来估计心脏运动。也就是说,训练后的模型可以考虑到时空信息,这有助于减少歧义。这样,该模型可以根据不同的运动模式更好地区分组织的病理改变(如图8中的冠状动脉钙化)和由运动伪影引起的极端CT值。
B. 未来工作
在本文中,我们提出了一种二维+时间TT U-Net来减少运动伪影。实际上,心脏运动是4D (3D+时间)的,4D模型有望表现出更高的性能。在我们未来的工作中,我们的目标是进一步研究直接在四维空间的心脏CT成像问题。训练4D网络模型需要更大的数据集。由于所提出的PAD易于扩展,我们相信它可以满足大型数据集的需求。由于维数的限制,将一个低维的网络模型提升到四维也不是很简单。提出的TT U-Net是一个可能的选择,因为它将时间和空间特征分开处理以实现高效编码。然而,4D心脏CT图像的高冗余要求对数据表示和模型优化进行精心设计。我们计划设计一个能够更有效和高效地处理4D心脏CT图像的模型。
此外,虽然我们已经证明我们的方法在真实的CT扫描上效果很好,但心脏CT成像在临床实践中面临各种困难。患者的高心率和不规则心律可能会引起复杂的运动伪影。在心脏CT图像上也可以看到意想不到的图像退化(例如,calcium blooming和由移动的起搏器引起的混合伪影)。一般来说,临床心脏CT图像呈长尾分布,我们的方法需要进一步适应各种情况。作为基于深度学习的心脏CT运动伪影减少的初步研究,我们构建了PAD来实现监督学习框架。我们计划进一步提高PAD的多样性,以训练一个更健壮的模型。
受最近稳定深层层析重建[42]研究的启发,缓解上述两个问题的另一种方法是将我们的TT U-Net与传统的MCR方法相结合。例如,训练后的网络模型可以作为去模糊模块,实现更好的运动估计。从去模糊图像中估计出的变形场将更加精确,从而有利于MCR步骤。从另一个角度来看,MCR方法为数据驱动模型引入了一个校正循环,增强了可解释性。通过迭代地执行这两个步骤,我们在初步实验中看到了令人鼓舞的结果。
VI. CONCLUSION
本文提出了一种基于深度学习的动态心脏CT运动伪影还原框架。为了训练用于减少运动伪影的深度神经网络模型,我们建立了一个由成对参考图像和伪影干扰的心脏CT图像组成的PAD。临床CT扫描实验证实了PAD的有效性。对于模型架构,我们设计了TTL模块来提取动态CT图像中的局部和全局时间特征。利用时间自注意机制,提出的TT U-Net能够通过后处理的方式减少整个心脏周期的运动伪影。我们的框架是有效的和可扩展的,我们相信它可以有利于动态医学成像的更广泛的研究。