pandas操作excel-基础部分
B站链接【Python自动化办公--Pandas玩转Excel(全30集)-哔哩哔哩】 https://b23.tv/Xk1r46d
1 创建文件

DataFrame:数据帧,相当于excel的sheet
to_excel:写入表格
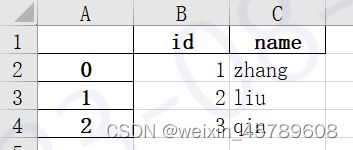
2 读取文件
print(df)输出df
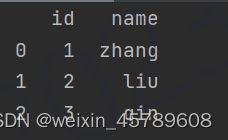
设置行索引为id,避免自动生成索引
import pandas as pd
df = pd.DataFrame({'id':[1,2,3], 'name':['zhang', 'liu', 'qin']})
# df.to_excel('D:\output.xlsx')
df.set_index('id')
print(df)
print('Down!')
import pandas as pd
df = pd.DataFrame(pd.read_excel('D:\数据解析需求\需求.xlsx'))
print(df.shape)
print(df.columns)
print(df.head(2))
print(df.tail())shape:文件大小
columns:列title
head:打印前5行数据,可自定义
tail:打印后五行数据
3 行、列、单元格

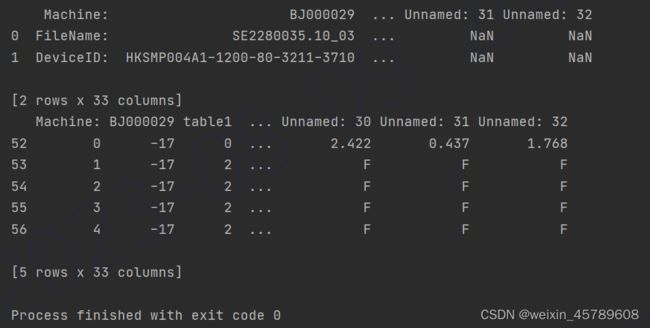 如果第一行为无效数据,可指定数据第一行的位置
如果第一行为无效数据,可指定数据第一行的位置
如果第一行为空,可以不用指定
df = pd.DataFrame(pd.read_excel('D:\数据解析需求\需求.xlsx', header=1))df = pd.DataFrame(pd.read_excel('D:\output.xlsx', header=None))
df.columns = ['sum', 'id', 'time']
print(df.columns)
df.to_excel('D:\output.xlsx')如果没有header,可以调用columns创建,但保存的时候会自动生成索引
df.set_index('id', inplace=True)在原来的dataframe上改,不生成索引
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', index_col='id'))设置id为索引,不会再自动生成
import pandas as pd
d = {'x':2, 'y':34, 'z':99}
s1 = pd.Series(d)
print(s1.index)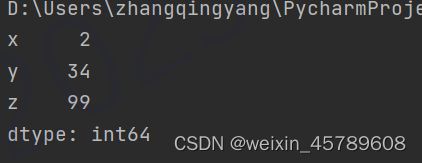
生成序列对象,属性有index
import pandas as pd
s1 = pd.Series([1,2,3], index=[1,2,3], name='A')
s2 = pd.Series([10,20,30], index=[1,2,3], name='B')
s3 = pd.Series([100,200,300], index=[1,2,3], name='C')
df = pd.DataFrame([s1, s2, s3])
print(df) 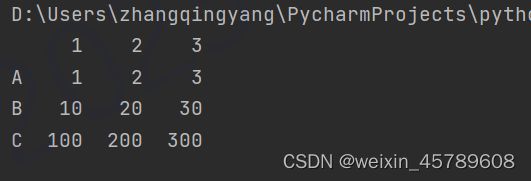
可以分别把值和索引告诉它
import pandas as pd
s1 = pd.Series([1,2,3], index=[1, 2, 3], name='A')
s2 = pd.Series([10,20,30], index=[1, 2, 3], name='B')
s3 = pd.Series([100,200,300], index=[1, 2, 3], name='C')
df = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})
print(df)
如果要以列的方式加进去,要用dict的方式
df = pd.DataFrame(pd.read_excel('D:\output.xlsx'))
print(df) 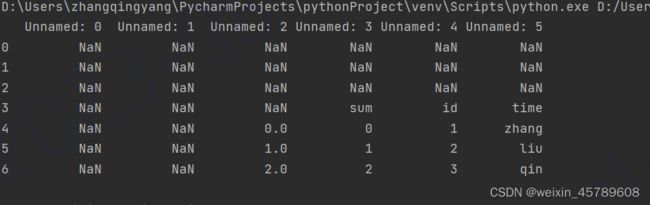
数据不靠边的输出形式
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', skiprows=4, usecols='D: F'))
print(df)
print(type(df['sum']))
skiprows跳过行数
usrcols使用的列
4 数据区域读取填充数字
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', skiprows=4, usecols='C: F'))
for i in df.index:
df['id'].at[i] = i+1
print(df) 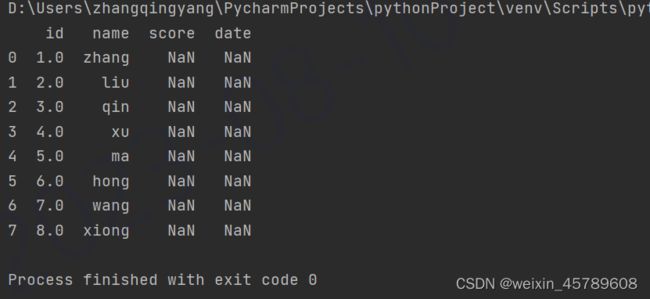
使用at[]方法自动填充
print(df['id']) 
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', skiprows=4, usecols='C: F', index_col=None, dtype={'id': str})) 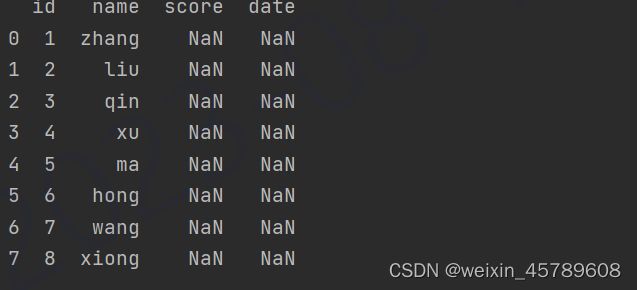
把id类型设置成str
5 填充日期序列
import pandas as pd
from datetime import date, timedelta
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', skiprows=4, usecols='C: F', index_col=None, dtype={'id': str}))
start = date(2018, 1, 1)
for i in df.index:
df['id'].at[i] = i+1
df['score'].at[i] = 'Yes' if i%2==0 else 'No'
df['date'].at[i] = start + timedelta(days=i)
print(df) 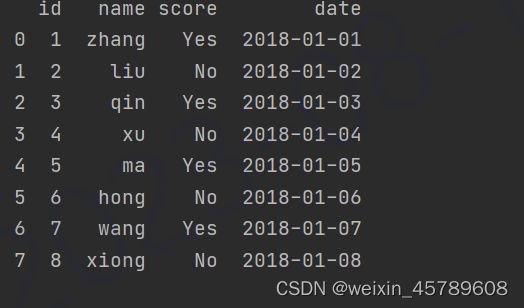
自动填充score和日期
def add_month(d,md):
yd = md // 12
m = d.month + md % 12
if m != 12:
yd += m//12
m = m%12
return date(d.year + yd, m, d.day)
df = pd.DataFrame(pd.read_excel('D:\output.xlsx', skiprows=4, usecols='C: F', index_col=None,
dtype={'id': str}))
start = date(2018, 1, 31)
for i in df.index:
df['id'].at[i] = i+1
df['score'].at[i] = 'Yes' if i%2==0 else 'No'
df['date'].at[i] = add_month(start, i)
print(df)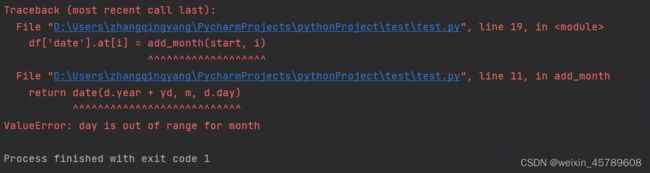
填充月份的时候注意超出界限会报错
6 函数填充,计算列
import pandas as pd
books = pd.read_excel('d:/test.xlsx', index_col='id')
# 操作列
books['price'] = books['score'] * books['discount']
books['price'] = books['score'] * 0.8
books['price'] = 0.8 * books['score']
# 操作单元格
# for i in books.index:
# books['price'].at[i] = books['score'].at[i] * books['discount'].at[i]
print(books)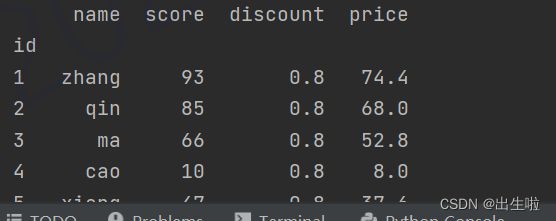
books['score'] += 50
def add_2(x):
return x+2
# books['score'] = books['score'].apply(add_2)
books['score'] = books['score'].apply(lambda x: x+2)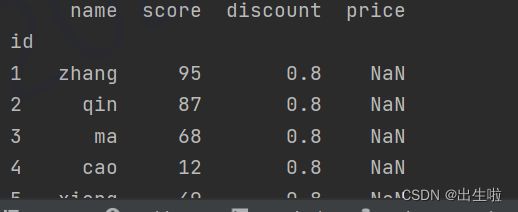
7 排序,多重排序
# products.sort_values(by='score', inplace=True)
# 降序排序:
products.sort_values(by='score', inplace=True, ascending=False)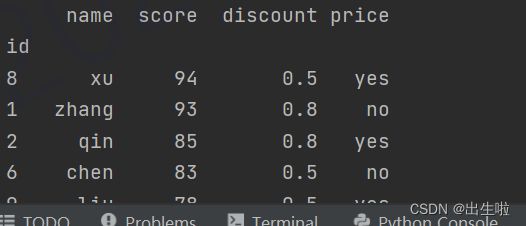
products.sort_values(by=['price', 'score'], inplace=True, ascending=False)
# 两列按不同方法排序
products.sort_values(by=['price', 'score'], inplace=True, ascending=[True, False]) 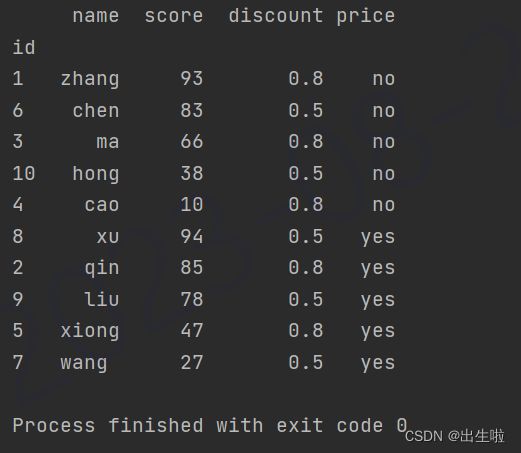
8 数据筛选、过滤
import pandas as pd
def score_a(s):
return 60<=s<=100
def price_y(p):
return p=='yes'
df = pd.read_excel('d:/test.xlsx', index_col='id')
# df = df.loc[df['score'].apply(score_a)].loc[df['price'].apply(price_y)]
# df = df.loc[df.score.apply(score_a)].loc[df.price.apply(price_y)]
df = df.loc[df.score.apply(lambda s:60<=s<=100)].loc[df.price.apply(lambda p:p=='yes')]
print(df)