SQL进阶笔记
SQL进阶笔记
CASE表达式
-
简单case表达式
case sex when '1' then '男' when '2' then '女' else '其他' end -
搜索case表达式
case when sex ='1' then '男' when sex ='2' then '女' else '其他' end编写SQL语句的时候需要注意,在发现为真的WHEN子句时,CASE表达式的真假值判断就会中止,而剩余的WHEN子句会被忽略。为了避免引起不必要的混乱,使用WHEN子句时要注意条件的排他性
-- 这样写结果不会出现“第二” case when col_1 in('a','b') then '第一' when col_1 in('a') then '第二' else '其他' end注意事项:养成写ELSE子句的习惯(不要忘了写END、统一各分支返回的数据类型)
与END不同,ELSE子句是可选的,不写也不会出错。不写ELSE子句时,CASE表达式的执行结果是NULL。但是不写可能会造成“语法没有错误,结果却不对”这种不易追查原因的麻烦,所以最好明确地写上ELSE子句(即便是在结果可以为NULL的情况下)。养成这样的习惯后,我们从代码上就可以清楚地看到这种条件下会生成NULL,而且将来代码有修改时也能减少失误
3.简单例子1:统计下表PopTbl中的内容,得出如下表“统计结果”所示的结果

-- 把县编号转换成地区编号
select case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长椅' then '九州'
else '其他' end as district,
sum(population)
from poptbl
group by
case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长椅' then '九州'
else '其他' end
-- 在PostgreSQL和MySQL中可以这样写
select case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长椅' then '九州'
else '其他' end as district,
sum(population)
from poptbl
group by district;
/*
这里的GROUP BY子句使用的正是SELECT子句里定义的列的别称——district。但是严格来说,这种写法是违反标准SQL的规则的。因为GROUP BY子句比SELECT语句先执行,所以在GROUP BY子句中引用在SELECT子句里定义的别称是不被允许的。事实上,在Oracle、DB2、SQL Server等数据库里采用这种写法时就会出错
*/
4.简单例子2:
统计表poptbl2
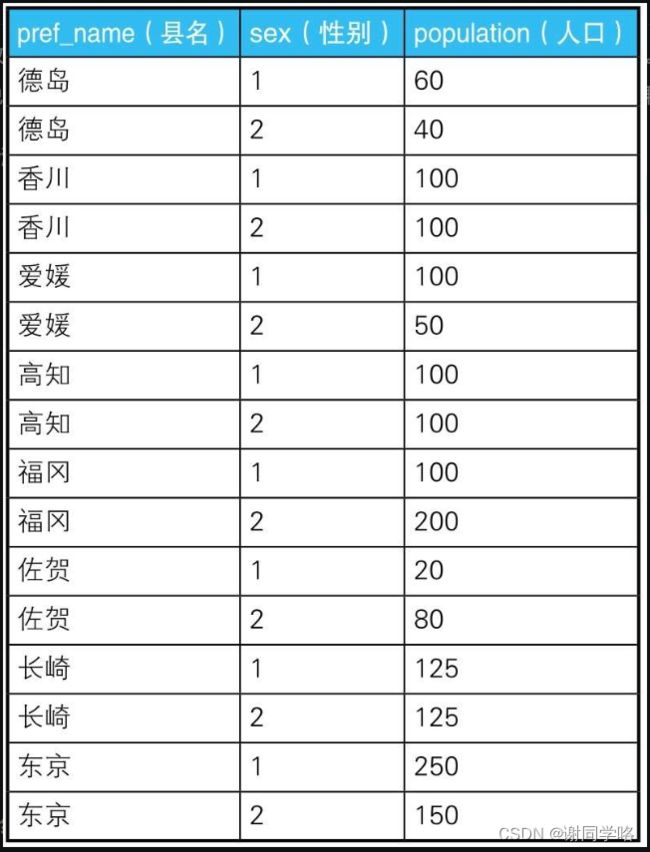
结果表
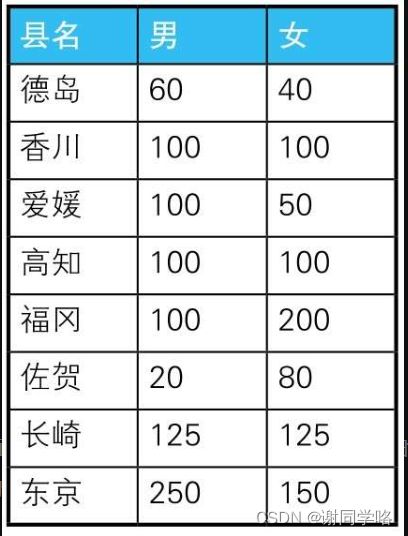
-
第一种做法,写两个查询,用union合并
select pref_name,sum(population) from poptbl2 where sex ='1' group by pref_name; union select pref_name,sum(population) from poptbl2 where sex ='2' group by pref_name; -
第二种做法,使用case表达式
select pref_name, -- 男性人口 sum(case when sex ='1' then population else 0 end) as cnt_m, -- 女性人口 sum(case when sex ='2' then polulation else 0 end) as cnt_f from poptbl2 group by pref_name; /* 上面这段代码所做的是,分别统计每个县的“男性”(即’1')人数和“女性”(即’2')人数。也就是说,这里是将“行结构”的数据转换成了“列结构”的数据。除了SUM, COUNT、AVG等聚合函数也都可以用于将行结构的数据转换成列结构的数据 */5.用CHECK约束定义多个列的条件关系
-- 假设某公司规定“女性员工的工资必须在20万日元以下”,而在这个公司的人事表中,这条无理的规定是使用CHECK约束来描述的,代码如下所示 constraint check_salary check (case when sex = '2' then case when salary <=200000 then 1 else 0 end else 1 end =1) -- 逻辑与也是一个逻辑表达式,意思是“P且Q”,记作P∧Q。用逻辑与改写的CHECK约束如下 constraint check_salary check (sex = '2' and salary <=200000) /* 说明: 如果在CHECK约束里使用逻辑与,该公司将不能雇佣男性员工。而如果使用蕴含式,男性也可以在这里工作。 解释: 要想让逻辑与P∧Q为真,需要命题P和命题Q均为真,或者一个为真且另一个无法判定真假。也就是说,能在这家公司工作的是“性别为女且工资在20万日元以下”的员工,以及性别或者工资无法确定的员工(如果一个条件为假,那么即使另一个条件无法确定真假,也不能在这里工作)。而要想让蕴含式P→Q为真,需要命题P和命题Q均为真,或者P为假,或者P无法判定真假。也就是说如果不满足“是女性”这个前提条件,则无需考虑工资约束。*/6.逻辑与和蕴含式
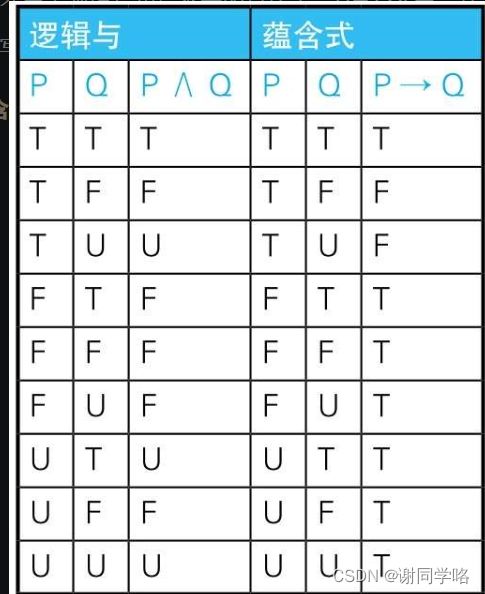
蕴含式在员工性别不是女性(或者无法确定性别)的时候为真,可以说相比逻辑与约束更加宽松
简单应用:
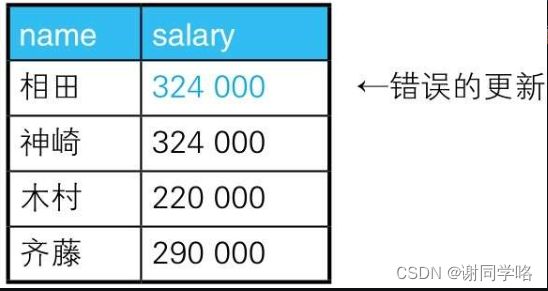
假设现在需要根据以下条件对该表的数据进行更新。
1.对当前工资为30万日元以上的员工,降薪10%。
2.对当前工资为25万日元以上且不满28万日元的员工,加薪20%。按照这些要求更新完的数据应该如下表所示
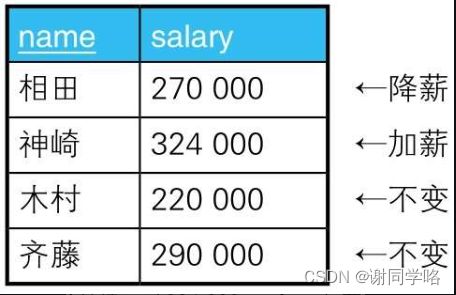
执行下面两个UPDATE操作好像就可以做到,但这样的结果却是不正确的。
-- 对当前工资为30万日元以上的员工,降薪10%
update salarise set salary=salary*0.9 where salary >=300000;
-- 对当前工资为25万日元以上且不满28万日元的员工,加薪20%
update salarise set salary=salary*1.2 where salary >=250000 and salary <=280000;
分析一下不正确的原因:
例如这里有一个员工,当前工资是30万日元,按“条件1”执行UPDATE操作后,工资会被更新为27万日元,但继续按“条件2”执行UPDATE操作后,工资又会被更新为32.4万日元。这样,本来应该被降薪的员工却被加薪了2.4万日元
用case来写
update salarise set salary = case when salary >= 300000
then salary*0.9
then salary >= 250000 and
salary <280000
then salary*1.2
else salary end;
/*
说明:
需要注意的是,SQL语句最后一行的ELSE salary非常重要,必须写上。因为如果没有它,条件1和条件2都不满足的员工的工资就会被更新成NULL。这一点与CASE表达式的设计有关,在刚开始介绍CASE表达式的时候我们就已经了解到,如果CASE表达式里没有明确指定ELSE子句,执行结果会被默认地处理成ELSE NULL
*/
7.表之间的数据匹配
in和exisin和区别:
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理
练习1:
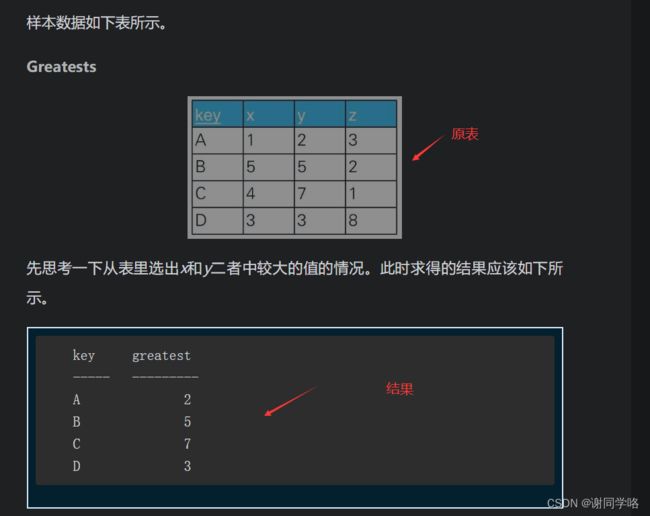
select key,case when x<y then y else x end as greatest from greatests;
练习2:
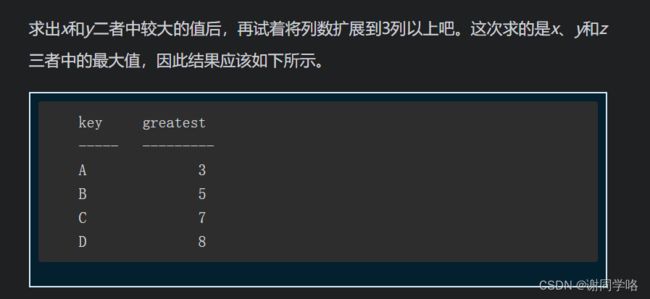
-- 用case表达式
select key,case when
case when x<y then y else x end <z
then z
else case when x<y then y else x end end as greatest
from greatests;
-- 用max函数
select key,max(num) as greatest form(
select key,x as num from greatsets
union all
select key,y as num from greatests
union all
select key,z as num from greatests
) as a
group by key;
-- Oracle或者MySQL数据库
select key,greatest(greatest(x,,y),z) as greatest from greatests;
练习3:
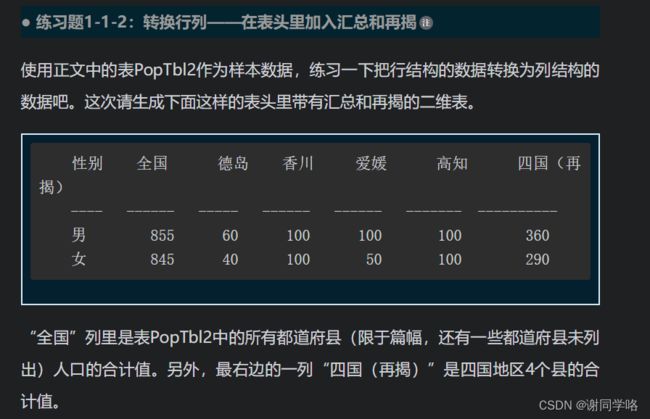
select sex,
-- 全国
sum(population) as numbers,
-- 德岛、香川、爱媛、高知
sum(case when pref_name ='德岛' then population eles 0 end as col_1 ),
sum(case when pref_name ='香川' then population else 0 end as col_2 ),
sum(case when pref_name ='爱媛' then population eles 0 end as col_3 ),
sum(case when pref_name ='高知' then population eles 0 end as col_4 ),
-- 四国
sum(case when pref_name in('德岛','香川','爱媛','高知') then population else 0 end as zaijie)
from poptbl2
group by sex;
练习4:

select key from greatests
order by
case when b then 1
when a then 2
when d then 3
when d then 4
else null end;
自连接
- 删除重复行

-
查找局部不一致的列
- 表Addresses
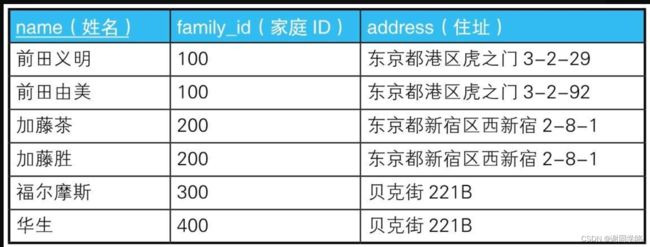
select distinct p1.name,p1.address from addresses p1,addresses p2 where p1.family_id=p2.family_id and p1.address<> p2.address;
- 表Products
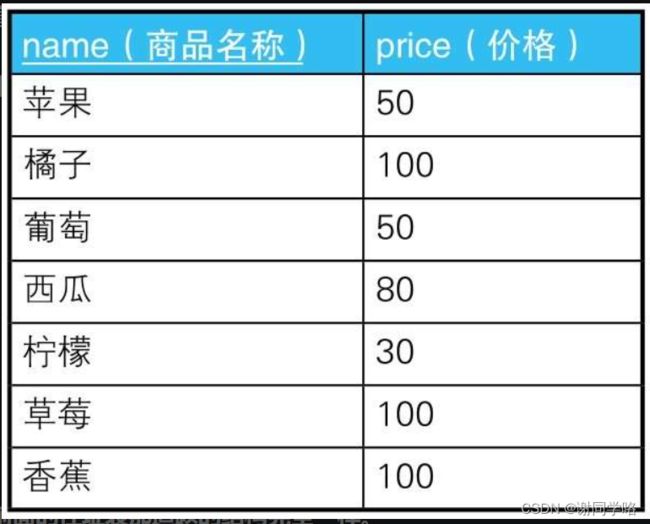
select distinct p1.name,p1.price from products p1,products p2 where p1.name <> p2.name and p1.price = p2.price
三值逻辑和NULL
概念
普通语言里的布尔型只有true和false两个值,这种逻辑体系被称为二值逻辑。而SQL语言里,除此之外还有第三个值unknown,因此这种逻辑体系被称为三值逻辑(three-valued logic)
两种NULL、三值逻辑还是四值逻辑
“两种NULL”这种说法大家可能会觉得很奇怪,因为SQL里只存在一种NULL。然而在讨论NULL时,我们一般都会将它分成两种类型来思考。因此这里先来介绍一些基础知识,即两种NULL之间的区别。
-
null的区别
两种NULL分别指的是“未知”(unknown)和“不适用”(not applicable,inapplicable)。以“不知道戴墨镜的人眼睛是什么颜色”这种情况为例,这个人的眼睛肯定是有颜色的,但是如果他不摘掉眼镜,别人就不知道他的眼睛是什么颜色。这就叫作未知。而“不知道冰箱的眼睛是什么颜色”则属于“不适用”。因为冰箱根本就没有眼睛,所以“眼睛的颜色”这一属性并不适用于冰箱。
总结:
未知”指的是“虽然现在不知道,但加上某些条件后就可以知道”;而“不适用”指的是“无论怎么努力都无法知道”
-
为什么必须写成“IS NULL”,而不是“=NULL”
先看这个例子吧
select * from table where name =null /* 说明: 对NULL使用比较谓词后得到的结果总是unknown。而查询结果只会包含WHERE子句里的判断结果为true的行,不会包含判断结果为false和unknown的行。不只是等号,对NULL使用其他比较谓词,结果也都是一样的。所以无论name是不是NULL,比较结果都是unknown */ --类似还有 1 = null 2 > null 3 < null 4 <> null null = nullnull的理解:
列的值为NULL”“NULL值”这样的说法本身就是错误的。因为NULL不是值,所以不在定义域(domain)中。相反,如果有人认为NULL是值,那么请问:它是什么类型的值?关系数据库中存在的值必然属于某种类型,比如字符型或数值型等。所以,假如NULL是值,那么它就必须属于某种类型
-
比较谓词和NULL(1):排中律不成立
我们假设约翰是一个人。那么,下面的语句(以下称为“命题”)是真是假?
约翰是20岁,或者不是20岁,二者必居其一
说明:是的这是正确的,但是现实世界中正确的事情在SQL里却不正确的情况时有发生。实际上约翰这个人是有年龄的,只是我们无法从这张表中知道而已。换句话说,关系模型并不是用于描述现实世界的模型,而是用于描述人类认知状态的核心(知识)的模型。因此,我们有限且不完备的知识也会直接反映在表里。
表students
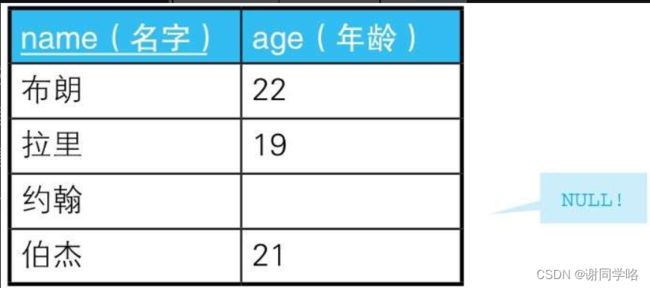
SQL查询语句
-- 查询约翰
select * from students where age = 20 or age <> =20
-- 必须加了这个第三真值才会出现约翰
or age is null
比较谓词和NULL(2):CASE表达式和NULL
-- 错误写法
case col_1 when 1 then 'X'
when null then 'O' end
-- 说明:第二个句子相当于 col_1=null,所以结果显而易见
-- 正确写法
case when col_1 =1 then 'X'
when col_1 is null then 'O' end
- NOT IN和NOT EXISTS不是等价的
EXISTS只会返回true或者false。因此就有了IN和EXISTS可以互相替换使用,而NOT IN和NOT EXISTS却不可以互相替换的混乱现象
总结:
1.NULL不是值。
2.因为NULL不是值,所以不能对其使用谓词。
3.对NULL使用谓词后的结果是unknown。
4.unknown参与到逻辑运算时,SQL的运行会和预想的不一样。
5.按步骤追踪SQL的执行过程能有效应对4中的情况。
要想解决NULL带来的各种问题,最佳方法应该是往表里添加NOT NULL约束来尽力排除NULL。这样就可以回到美妙的二值逻辑世界(虽然并不能完全回到)
HAVING子句的力量
简单例子:查找一个连续编号的表里是否存在缺失数据
表test_01
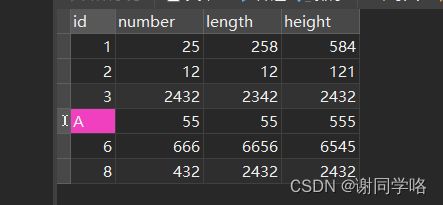
-- 不存在就没有缺失数据,反之存在
select '存在缺失数据' as gpa from test_01 having count(*) <> max(id)
-- 查找缺失数据的最小值
select min(id+1) as id from test_01 where id+1 not in(select id from test_01)
-
COUNT(*)和COUNT(列名)的区别
第一个是性能上的区别;第二个是COUNT(*)可以用于NULL,而COUNT(列名)与其他聚合函数一样,要先排除掉NULL的行再进行统计
第二个区别也可以这么理解:COUNT(*)查询的是所有行的数目,而COUNT(列名)查询的则不一定是。
表
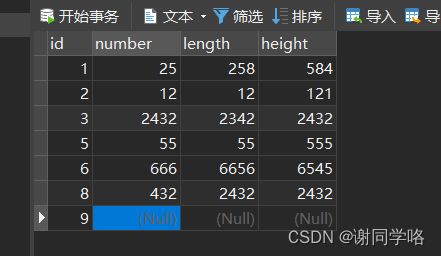
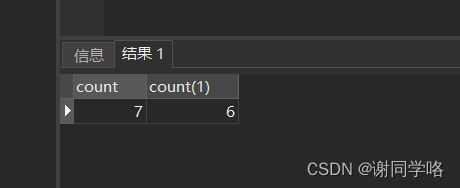
-- 查询结果还是不一样
select count(*),count(number) from test_01
结果:
-
例子

-- 可能会这样写 select distinct shop from shopltems where item in(select item from items) -- 结果 -- shop -- 仙台 -- 东京 -- 大版 -- 正确的写法 select t1.shop from shopltems t1,items t2 where t1.item=t2.item group byt1.item -- 分组里数量一致 having count(t1.item)=(select count(item) from items)
外连接(outer jion/left join)
简单例子:将下原表简化成结果表
原表:
DROP TABLE IF EXISTS `courses`;
CREATE TABLE `courses` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`course` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
------------------------------------------------------------------------------------------------------
INSERT INTO `courses` VALUES (1, '赤井', 'SQL入门');
INSERT INTO `courses` VALUES (2, '赤井', 'UNIX基础');
INSERT INTO `courses` VALUES (3, '铃木', 'SQL入门');
INSERT INTO `courses` VALUES (4, '吉田', 'UNIX基础');
INSERT INTO `courses` VALUES (5, '工藤', 'SQL入门');
INSERT INTO `courses` VALUES (6, '渡边', 'SQL入门');
INSERT INTO `courses` VALUES (7, '工藤', 'Java中级');
INSERT INTO `courses` VALUES (8, '赤井', 'SQL入门');
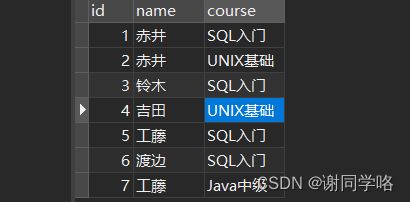
结果表:
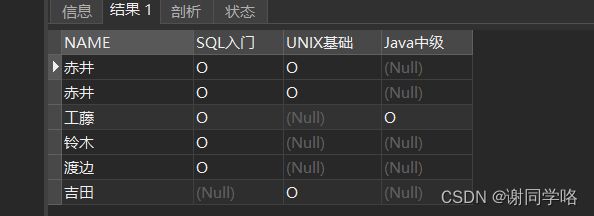
代码:
-- 第一种写法outer jion
SELECT
t0.NAME,
CASE
WHEN t1.NAME IS NOT NULL THEN
'O' ELSE NULL
END AS 'SQL入门',
CASE
WHEN t2.NAME IS NOT NULL THEN
'O' ELSE NULL
END AS 'UNIX基础',
CASE
WHEN t3.NAME IS NOT NULL THEN
'O' ELSE NULL
END AS 'Java中级'
from (select distinct `name` from courses) as t0
left outer join
(select `name` from courses where course ='SQL入门') t1
on t1.`name`=t0.`name`
left outer join
(select `name` from courses where course ='UNIX基础') t2
on t2.`name`=t0.`name`
left outer join
(select `name` from courses where course ='Java中级') t3
on t3.`name`=t0.`name`
-- 第二种嵌套case表达式
SELECT
`name`,
case when sum(case when course = 'SQL入门' then 1 ELSE null end)=1 then 'O' else null end as 'SQL入门',
case when sum(case when course = 'UNIX基础' then 1 ELSE null end)=1 then 'O' else null end as 'UNIX基础',
case when sum(case when course = 'Java中级' then 1 ELSE null end)=1 then 'O' else null end as 'Java中级'
from
courses
GROUP BY
name;
-- 特别注意,错误的写法
SELECT
t0.`name`,
-- 这里会报 作为一个表达式使用的子查询返回了多列
-- ( SELECT 'O' FROM courses t1 WHERE course = 'SQL入门' AND t0.`name` = t1.`name` ) AS 'SQL入门',
( SELECT 'O' FROM courses t2 WHERE course = 'UNIX基础' AND t0.`name` = t2.`name` ) AS 'UNIX基础',
( SELECT 'O' FROM courses t3 WHERE course = 'Java中级' AND t0.`name` = t3.`name`) AS 'Java中级'
FROM
( SELECT DISTINCT `name` FROM courses ) as t0;

用关联子查询比较行与行
增长、减少、维持现状
例子:使用SQL输出与上一年相比营业额是增加了还是减少了
表:Sales

SQL:
-- 第一种写法,子查询
select t1.year,t1.sale,case
-- 比较上一年的结果——>持平
when sale =(select sale from sales t2 where t2.year=t1.year-1 ) then '持平'
-- 上升
when sale >(select sale from sales t3 where t3.year=t1.year-1 ) then '上升'
-- 下降
when sale <(select sale from sales t3 where t3.year=t1.year-1 ) then '下降'
else '起点对比数据' end as sale_state
from sales t1
order by t1.year;
-- 第二种写法,自连接,会少一行1990
select t1.year,t1.sale,case
when t1.sale = t2.sale then '持平'
when t1.sale > t2.sale then '上升'
when t1.sale < t2.sale then '下降'
else '起点对比数据' end as sale_state
-- t2是上一年数据
from sales t1,sales t2
where t2.year=t1.year-1
order by t1.year
假如上表数据缺失就不能用year-1这个条件了
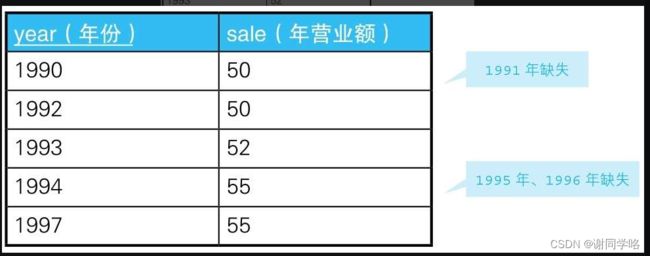
-- 查询每一年与过去最临近的年份之间的营业额之差
SELECT
S2.YEAR AS pre_year,
S1.YEAR AS now_year,
S2.sale AS pre_sale,
S1.sale AS now_sale,
S1.sale - S2.sale AS diff
FROM Sales2 S1,Sales2 S2
WHERE
S2.YEAR = ( SELECT MAX( YEAR ) FROM Sales2 S3 WHERE S1.YEAR > S3.YEAR )
ORDER BY
now_year;
查询重复的情况
酒店预约的简单例子:表——Reservations
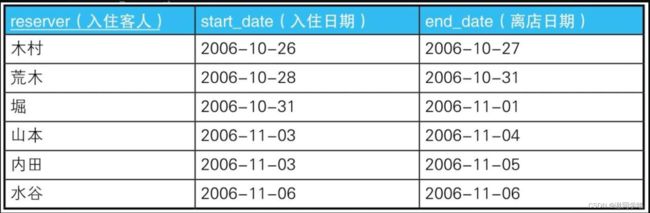
SQL:
-- 查询日期冲突的客人
SELECT
reserver,
start_date,
end_date
FROM
reservations t1
WHERE
EXISTS (
SELECT
*
FROM
reservations t2
WHERE
-- 和自己比较
t1.reserver <> t2.reserver
-- 入住日期和离开日期 在别人住的时间
AND ( t1.start_date BETWEEN t2.satrt_date AND t2.end_date OR t1.start_date BETWEEN t2.start_date AND t2.end_date )
)
in和exists的区别
- 如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in
- EXISTS不仅可以将多行数据作为整体来表达高级的条件,而且使用关联子查询时性能仍然非常好
集合运算
UNION:交集
- 查询重复的数据
-- 公式 S UNION S = S
-- 查询A B表的数据
select count(*) as row_num from (select * from tableA union select * from tableB ) Tme