Sql Server从入门到精通
一、SqlServer用户权限
设置权限用户的意义
操作客户端来使用数据库功能的最终是人在使用。为了保证数据库的安全性,必须对于数据库操作者有不同的权限控制。
权:能做什么事儿
限:不能做什么事儿
如何做到权限管理呢?
**通过不同的用户,不同的用户角色来分配。**这样管控,就可以通过登录数据库的用户不同,赋予相应的权利,和限制相应的操作。

SqlServer登陆方式
1、Windows身份验证方式
Windows身份验证方式,该用户具备最高权限,仅能SQLSERVER安装所在的服务器登录.
2、SqlServer身份验证方式
SQLSERVER身份验证方式(sa用户),一般会授予该用户最高权限,可以在同一网络环境下的任何电脑上登录。出于这样或那样的原因,有时需要对外开放接口,给对方一个账号,又希望限制对方访问操作权限的时候,就需要设置权限用户。

用户登录,最终目的是为了能够控制登录的用户,在数据库的很多功能中,只能操作某一部分功能;
用户+用户角色+每一个用户角色可以做哪些事儿;从而得到不同的用户可以做不同的事儿
二、SqlServer基本操作
创建数据库和表
1、工具建库建表
2、脚本建库建表
3、工具删除数据库删除表
4、脚本删除数据库删除表
数据基本CRUD
对于表中中数据的操作
1、查询
SELECT * FROM 表名称
2、新增
insert into ScoreInfo(name,course,score) values ('李四','数学',111)
3、修改
update ScoreInfo set name="andy" and score=90 where id=1
4、删除
delete from ScoreInfo where id=1
三、进阶查询
1、别名,查询结果拼接
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo]
2、条件查询
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo] where id=4
3、范围查询
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo] where id>5 and id<10
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo] where id between 5 and 10
4、查询前多少行/按比例查询
select top 3 * from ScoreInfo
select top(20)percent * from ScoreInfo
5、case when判断
#案例一
#分数有个范围:<90不及格
90--120--及格
>120 良好
>130 优秀
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
,case when score<90 then'不及格'
when score>=90 and score<120 then'及格'
when score>=120 then'良好'
when score>130 then'优秀'
else '差'
end as'等级'
FROM [Student].[dbo].[ScoreInfo] order by [score] asc
6、in查询
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo] where id in(4、5、6、7)
7、like查询
模糊匹配和通配符%一起使用才有效果 %表示可以匹配任何通配符
SELECT TOP(1000) [Id] 主键
,[name]
,[course]
,[score]
FROM [Student].[dbo].[ScoreInfo] where name like '%张'
8、with关键字查询
相当于是sql查询中的sql片段
with score as (SELECT * FROM [Student].[dbo].[ScoreInfo])
select * from score where name='andy'
9、子查询/exists关键字查询
#子查询
SELECT * FROM [Student].[dbo].[ScoreInfo] where id in (SELECT * FROM [Student].[dbo].[ScoreInfo] where name='andy')
#exists关键字
SELECT * FROM [Student].[dbo].[ScoreInfo] t1 where
exists(SELECT * FROM [Student].[dbo].[ScoreInfo] t2 where t1.id=t2.id and t2.name='andy')
10、复制新表/表数据复制
#复制新表
select * into ScoreInfo2 from ScoreInfo
#把另外一个结构相同的表数据复制到指定表中
insert student.ScoreInfo2 select name,course,score from student.ScoreInfo
11、distinc同一列去掉重复
select distinc(score) from student.ScoreInfo order by score desc
12、左连接
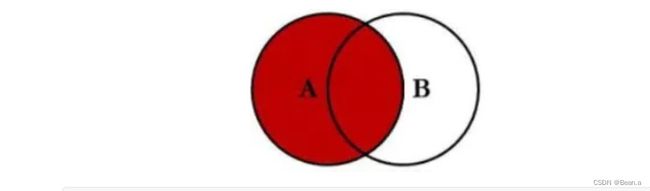
select * from company c left join User u on c.id=u.cid
13、内连接查询

select * from company c inner join User u on c.id=u.cid
14、右连接查询
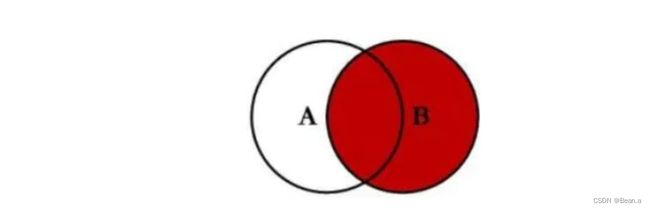
select * from company c right join User u on c.id=u.cid
15、全连接
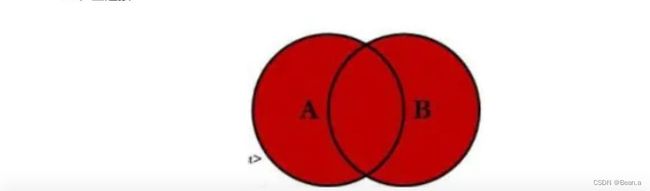
select * from company c full join User u on c.id=u.cid
四、视图
视图价值
在数据查询中,可以看到数据表设计过程中,考虑到数据的冗余度低、数据一致性等问题,通常对数据表的设计要满足范式的要求,因此也会造成一个实体的所有信息保存在多个表中。当检索数据时,往往在一个表中不能够得到想要的所有信息。为了解决这种矛盾,在SQL Server中提供了视图。
视图概念
视图是一种数据库对象,是从一个或者多个数据表或视图中导出的虚表,视图的结构和数据是对数据表进行查询的结果;只存放视图的定义,不存放视图对应的数据;基表中的数据发生变化,从视图中查询出的数据也随之改变。
创建视图
数据库管理工具创建
Sql脚本创建
视图查询、修改、删除、增加
推荐大家在使用视图的时候,仅用作查询。不推荐大家基于视图来做增删改
五、存储过程
存储过程的概念
存储过程(procedure)是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程优点
1、可以针对于某一项业务逻辑处理:通过把处理封装在简单易用的单元中,简化复杂的操作存储过程创建后****可以在程序中被多次调用执行,而不必重新编写该存储过程的SQL语句。可以针对于某一项业务逻辑处理,把处理过程就定义好。需要处理业务,就直接调用存储过程。
2、提高性能:使用存储过程比使用单独的SQL语句要快如果某一操作包含大量的SQL语句代码,分别被多次执行,那么存储过程要比批处理的执行速度快得多。
3、安全:调用者只需要知道如何调用指定的存储过程即可,而不用关心存储过程的内容,防止SQL注入。存储过程减轻网络流量对于同一个针对数据库对象的操作,这一操作所涉及到的T-SQL语句被组织成一存储过程,那么当在客户机上调用该存储过程时,网络中传递的只是该调用语句,否则将会是多条SQL语句。从而减轻了网络流量,降低了网络负载。
存储过程缺点
1、编写复杂
2、如果没有相应的权限,你将无法创建存储过程
3、当服务器调用过多存储过程,用户访问量大了,那么压力就丢给数据库来解决,数据库压力会过大
4、过多的存储过程,优化过于麻烦
自定义存储过程创建语法
create proc | prodedure 存储名(
[{@参数 数据类型} [=默认值] [out|output],
{@参数 数据类型} [=默认值] [out|output],
...]
)
as
begin
SQL_statements
end
go
存储过程修改语法
alter proc | procedure 存储过程名
as
begin
sql语句;
end
存储过程删除语法
drop proc | procedure 存储过程名
调用语法
exec 存储过程名; ----不带参数调用
exec 存储过程名 参数1 out|output,参数2 out|output; ----带参数调用
六、索引
索引基本概念
在数据库中建立索引是为了加快数据的查询速度。
书籍的索引表是一个词语列表,其中注明了包含各个词的页码。
**而数据库中的索引是一个表中所包含的列值的列表,其中注明了表中包
含各个值的行数据所在的存储位置。**可以为表中的单个列建立索引,也可以为一组列建立索引。索引一般采用B树结构。
索引由索引项组成,索引项由来自表中每一行的一个或多个列(称为搜索关键字或索引关键字)组成。B树按搜索关键字排序,可以对组成搜索关键字的任何子词条集合上进行高效搜索。
例如,对于一个由A、B、C三个列组成的索引,可以在A以及A、B和A、B、C上对其进行高效搜索。例如,假设在Student表的Sno列上建立了一个索引(Sno为索引项或索引关键字),则在索引部分就有指向每个学号所对应的学生的存储位置的信息,如下图

利用索引提高查询效率是以占用空间和增加数据更改的时间为代价的。
在设计和创建索引时,应确保对性能的提高程度大于在存储空间和处理资源方面的代价。
数据页
在数据库管理系统中,数据一般是按数据页存储的,数据页是一块固定大小的连续存储空间。不同的数据库管理系统数据页的大小不同,有的数据库管理系统数据页的大小是固定的
比如SQL Server的数据页就固定为8KB;有些数据库管理系统的数据页大小可由用户设定,比如DB2。
在数据库管理系统中,索引项也按数据页存储,而且其数据页的大小与存放数据的数据页的大小相同。
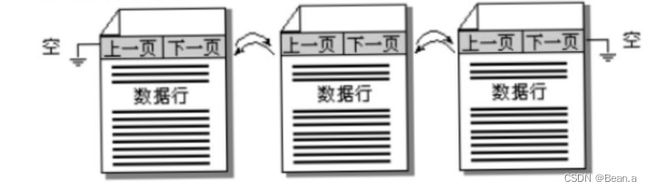
索引的存储结构及分类
索引分为两大类,一类是聚集索引(Clustered Index,也称为聚簇索引),另一类是非聚集索引(Non-Clustered Index,也称为非聚簇索引)。聚集索引对数据按索引关键字值进行物理排序,非聚集索引不对数据按索引关键字值进行物理排序,而只将索引关键字按值进行排序。
在SQL Server中聚集索引和非聚集索引都采用B树结构来存储索引项,而且都包含数据页和索引页,其中索引页用来存放索引项和指向下一层的指针,数据页用来存放数据。不同的数据库管理系统中索引的存储结构不尽相同,本章我们主要介绍SQL Server。对索引采用的存储结构。
B树结构
B树(Balanced Tree,平衡树)的最上层节点称为根节点(Root Node
),最下层节点称为叶节点(Left Node)。在根节点所在层和叶节点所在层之间的层上的节点称为中间节点(Intermediate Node)。B树结构从根节点开始,以左右平衡的方式存放数据,中间可根据需要分成许多层。

聚集索引
聚集索引的B树是自下而上建立的,最下层的叶级节点存放的是数据,因此它即是索引页,同时也是数据页。
多个数据页生成一个中间层节点的索引页,然后再由数个中间层节点的索引页合成更上层的索引页,如此上推,直到生成顶层的根节点的索引页,如下图
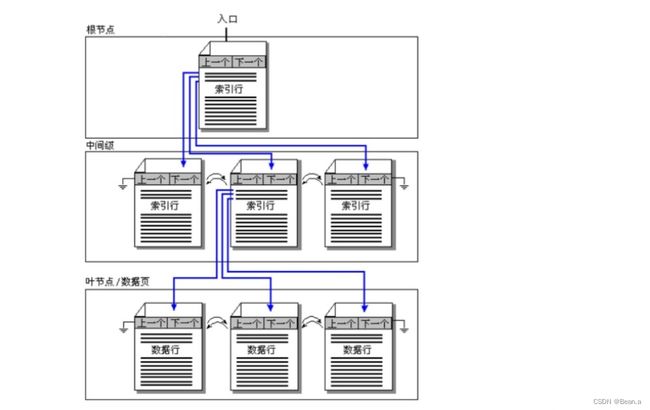
生成高一层节点的方法是:从叶级节点开始,高一层节点中每一行由索引关键字值和该值所在的数据页编号组成,其索引关键字值选取的是其下层节点中的最大或最小索引关键字的值。
除叶级节点之外的其他层节点,每一个索引行由索引项的值以及这个索引项在下层节点的数据页编号组成。
聚集索引使用建议:
1.包含大量非重复值的列
2.使用下列运算符返回一个范围值的查询:BETWEEN AND、>、>=、<和<=
3.经常被用作连接的列,一般来说,这些列是外键列
4.对ORDER BY或GROUP BY子句中指定的列建立索引,可以使数据库管理系统在查询时不必对数据再进行排序,从而可以提高查询性能。对于频繁进行更改操作的列则不适合建立聚集索引
非聚集索引
非聚集索引与图书后边的术语表类似。书的内容(数据)存储在一个地方,术语表(索引)存储在另一个地方。而且书的内容(数据)并不按术语表(索引)的顺序存放,但术语表中的每个词在书中都有确切的位置。
非聚集索引就类似于术语表,而数据就类似于一本书的内容。非聚集索引的存储示意图如下图
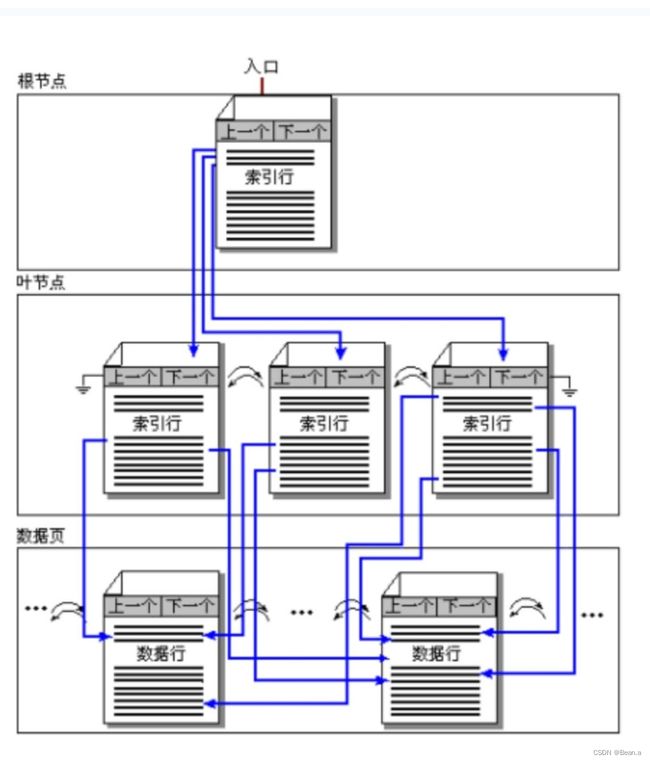
非聚集索引与聚集索引一样用B树结构,但有两个重要差别:
1.数据不按非聚集索引关键字值的顺序排序和存储。
2.非聚集索引的叶级节点不是存放数据的数据页。非聚集索引B树的叶级节点是索引行。每个索引行包含非聚集索引关键字值以及一个或多个行定位器,这些行定位器指向该关键字值对应的数据行(如果索引不唯一,
则可能是多行)
对于下述情况可考虑创建非聚集索引:
1.包含大量非重复值的列。如果某列只有很少的非重复值,比如只有1和
0,则不对这些列建立非聚集索引
2.经常作为查询条件使用的列
3.经常作为连接和分组条件的列