1.1 Ceph基础及集群的搭建
1.Ceph基础
- ceph是可靠的、自动重均衡、自动恢复的分布式存储系统。
- ceph 提供块存储(RBD)、cephfs文件存储(POSIX兼容的网络文件系统)、对象存储能力(Radosgw提供RESTful接口,支持多种语言兼容S3、Swift)。
- ceph是一个对象(object)存储系统,将待管理的数据流(文件等数据)切分为固定大小(默认4M),并以其为原子单元,完成数据读写。
- 对象数据的底层存储服务是由多个存储(host)组成的存储集群,称之为RADOS存储集群
librados是RADOS集群的API,支持C/C++/JAVA/python/ruby/php/go等客户端。 - 采用CRUSH算法,摒弃存储元数据寻址方式,数据分布均衡,并行度高。通过对象名称和所在存储池,使用集群映射关系和CRUSH算法,直接通过计算得到对象所在的PG和Ceph OSD,客户端直接连接可执行读写的主OSD,获取存储的数据,在客户端和OSD之间不存在中间服务器,中间或总线。
通过跨机房、机架感知等,通过实现各类负载的副本放置规则,实现容灾域的隔离。
2.Ceph的组件和功能:
https://docs.ceph.com/en/latest/architecture/#calculating-pg-ids

2.1 monitors:监视器
- 监视ceph集群,维护ceph集群健康状态。
- 维护ceph集群映射关系:Cluster Map(OSD Map,Monitor Map,PG Map,CRUSH Map, MDS Map)。
- 管理集群中所有成员,关系和属性等信息及数据的分发。
- 如:当用户需要存储数据到ceph时,OSD需要通过Monitor获取最新的Map图,根据Map图和object id计算数据最终存储的位置。
2.2 Manager:
- 主机上运行的守护进程,负责跟踪运行时指标和ceph集群的状态,存储利用率,当前性能指标和系统负载。
- 通过Ceph Manager 守护程序托管基于python 的模块管理和公开Ceph集群信息,包括web ceph仪表板和REST API, 一般需要两个(主备)实现高可用。
2.3 Ceph OSD(对象存储守护程序,Ceph-osd)
- 提供存储数据服务,操作系统内一个磁盘对应一个osd守护进程,用来存储ceph集群数据复制、恢复、重新平衡。
- 通过检查其他OSD守护进程的心跳来向ceph 监视器和管理器提供监视信息,通常至少需要3个Ceph OSD 实现冗余和高可用。
2.4 MDS(ceph 元数据数据服务ceph-mds)
- 存储ceph文件系统元数据(不包括ceph 块存储,对象存储),提供POSIX文件系统用户基本命令行操作(ls,find…),避免给ceph 存储集群带来负担。
3.Ceph的逻辑组织架构
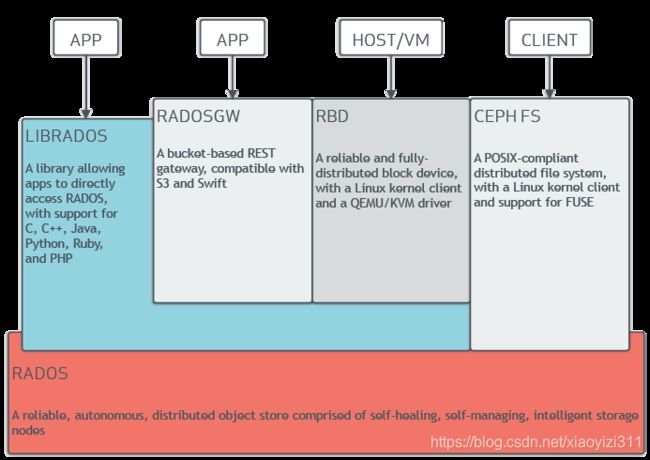
- RADOS:Ceph存储集群的基础,负责保存存储对象,确保数据始终保持一致。
- Librados:Librados库,为应用提供访问接口,同时为块存储、对象存储、文件系统提供原生接口。
- RADOSGW:网关接口,提供对象存储服务,使用librgw和librados来实现,允许应用程序与Ceph对象存储建立连接,提供与S3和Swift 兼容的RESTful API接口。
- RBD:块存储,提供自动精简配置并可调整大小,将数据分散存储在多个OSD上。
- CephFS:与POSIX兼容的文件系统,基于librados封装原生接口。
4.Ceph 数据组织架构
- Pool: 存储池分区,存储池的大小取决于底层的存储空间。
- PG(Placement Group):一个pool 内部可以有多个PG存在,是对Object的存储进行组织和位置。
- 一个PG负责组织若干个Object,但一个Object只能被映射到一个PG中。
- 一个PG会被映射到N个OSD上,每个OSD上都会承载大量的PG,一个OSD上的PG则可达到数百个,PG数量的设置与数据分布均匀性。
- OSD:OSD的数量事实上也关系到系统的数据分布均匀性,数量不应太少,生产实践中至少需要数十上百个量级才有助于Ceph系统的设计优势。

5.Ceph的元数据存储
以key-value的形式存在
5.1 RADOS 中有两种实现: xattrs 和 omap
5.1.1 xattrs(扩展属性)
将元数据保持在对应的文件扩展属性中,并保存在系统磁盘上,要求支持对象存储的本地系统(一般是XFS)支持扩展属性。
5.1.2 omap(对象映射)
是Object Map 的简称,将元数据保存在本地文件系统之外的key-value存储系统中,使用filestore时是leveldb,使用bluestore时是rocksdb,由于filestore存在功能问题(需要将磁盘格式化为XFS格式)及元数据高可用问题,因此目前ceph主要使用bluestore。
5.2 Ceph 可以选多种存储引擎,如filestore,bluestore,kvstore,memstore,Ceph使用blustore存储对象数据的元数据
- Ceph早期基于filestore使用google 的leveldb 保存对象的元数据,LevelDb 是一个持久化 存储的 KV 系统,和 Redis 这种内存型的 KV 系统不同,leveldb 不会像 Redis 一样将数据 放在内存从而占用大量的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘上的 leveldb 空间格式化为文件系统(XFS)。
- FileStore 将数据保存到与 Posix 兼容的文件系统(例如 Btrfs、XFS、Ext4)。在 Ceph 后端使 用传统的 Linux 文件系统尽管提供了一些好处,但也有代价,如性能、 对象属性与磁盘本 地文件系统属性匹配存在限制等。
5.2.1 Bluestore 和Rocksdb

BlueStore 的逻辑架构如上图所示,模块的划分都还比较清晰,我们来看下各模块的作用:
- Allocator:负责裸设备的空间管理分配。
RocksDB:rocksdb 是 facebook 基于 leveldb 开发的一款 kv 数据库,BlueStore 将元数据 全部存放至 RocksDB 中,这些元数据包括存储预写式日志、数据对象元数据、Ceph 的 omap 数据信息、以及分配器的元数据 。
RocksDB 将对象数据的元数据保存在 RocksDB,但是 RocksDB 的数据又放在哪里呢?放在内存怕丢失,放在本地磁盘但是解决 不了高可用,ceph 对象数据放在了每个 OSD 中,那么就在在当前 OSD 中划分出一部分空 间,格式化为 BlueFS 文件系统用于保存 RocksDB 中的元数据信息(称为 BlueStore),并实 现元数据的高可用,BlueStore 最大的特点是构建在裸磁盘设备之上,并且对诸如 SSD 等 新的存储设备做了很多优化工作。
- 对全 SSD 及全 NVMe SSD 闪存适配 绕过本地文件系统层,直接管理裸设备,缩短 IO 路径 严格分离元数据和数据,提高索引效率。
- 期望带来至少 2 倍的写性能提升和同等读性能 增加数据校验及数据压缩等功能。
- 解决日志“双写”问题。
- 使用 KV 索引,解决文件系统目录结构遍历效率低的问题 支持多种设备类型。
RocksDB 通过中间层 BlueRocksDB 访问文件系统的接口。这个文件系统与传统的 Linux 文件系统(例如 Ext4 和 XFS)是不同的,它不是在 VFS 下面的通用文件系统,而是一个用 户态的逻辑。BlueFS 通过函数接口(API,非 POSIX)的方式为 BlueRocksDB 提供类似文件系统的能力。
- BlueRocksEnv:这是 RocksDB 与 BlueFS 交互的接口;RocksDB 提供了文件操作的接口 EnvWrapper(Env 封装器),可以通过继承实现该接口来自定义底层的读写操作, BlueRocksEnv 就是继承自 EnvWrapper 实现对 BlueFS 的读写。
- BlueFS:BlueFS 是 BlueStore 针对 RocksDB 开发的轻量级文件系统,用于存放 RocksDB 产生的.sst 和.log 等文件。
- BlockDecive:BlueStore 抛弃了传统的 ext4、xfs 文件系统,使用直接管理裸盘的方式; BlueStore 支持同时使用多种不同类型的设备,在逻辑上 BlueStore 将存储空间划分为三层: 慢速(Slow)空间、高速(DB)空间、超高速(WAL)空间,不同的空间可以指定使用不 同的设备类型,当然也可使用同一块设备。
BlueStore 的设计考虑了 FileStore 中存在的一些硬伤,抛弃了传统的文件系统直接管理裸 设备,缩短了 IO 路径,同时采用 ROW 的方式,避免了日志双写的问题,在写入性能上有 了极大的提高。

6.Ceph CRUSH算法
-
Controllers replication under scalable hashing : 可控的、可复制的、可伸缩的一致性 hash 算法。
-
CRUSH 是一种分布式算法,类似于一致性 hash 算法,用于为 RADOS 存储集群控制数据的分配。
Ceph 使用 CURSH 算法来存放和管理数据,它是 Ceph 的智能数据分发机制。Ceph 使用 CRUSH 算法来准确计算数据应该被保存到哪里,以及应该从哪里读取,和保存元数据不同的 是,CRUSH 按需计算出元数据,因此它就消除了对中心式的服务器/网关的需求,它使得 Ceph 客户端能够计算出元数据,该过程也称为 CRUSH 查找,然后和 OSD 直接通信。 如果是把对象直接映射到 OSD 之上会导致对象与 OSD 的对应关系过于紧密和耦合,当 OSD 由于故障发生变更时将会对整个 ceph 集群产生影响。于是 ceph 将一个对象映射到 RADOS 集群的时候分为两步走:
-
首先使用一致性 hash 算法将对象名称映射到 PG。
-
然后将 PG ID 基于 CRUSH 算法映射到 OSD 即可查到对象。
以上两个过程都是以”实时计算”的方式完成,而没有使用传统的查询数据与块设备的对应 表的方式,这样有效避免了组件的”中心化”问题,也解决了查询性能和冗余问题。使得 Ceph 集群扩展不再受查询的性能限制。
这个实时计算操作使用的就是 CRUSH 算法。
-
6.1 映射过程
-
Ceph Pool的属性:Object的副本数,PG数量,使用的CRUSH Ruleset。
-
(Pool,PG)→ OSD 的映射由4个因素决定:
-
CRUSH算法
-
OSD Map:包含pool的状态和OSD的状态。OSD Map 管理Ceph中的所有OSD,OSD Map规定来CRUSH算法的范围。OSD Map是一个树形结构,如下图, 中间虚拟的Bucket 节点是数据中心抽象,机房抽象,机架抽象、主机抽象。
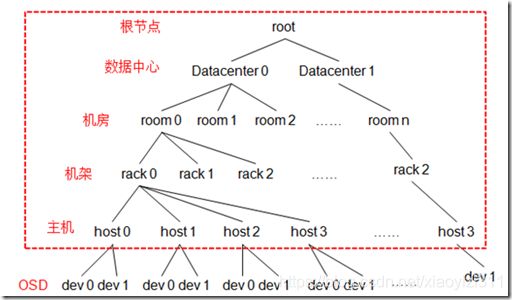
-
-
CRUSH Map : 包含当前磁盘、服务器、机架的层次结构。
-
CRUSH Rules:数据映射的策略,可以灵活设置object存放的区域。如:pool1中的所有objects放在机架1上,objects 第一副本放在机架1的A服务器上,第二副本放在机架1上的服务器B上。
7. Ceph的数据读写流程
- Ceph 需要走完 (Pool, Object) → (Pool, PG) → OSD set → OSD/Disk 完整的链路,才能让 ceph client 知道目标数据 object的具体位置在哪里。
- 数据写入时,文件被切分成object,object先映射到PG,再由PG映射到OSD set。每个pool有多个PG,每个object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD个数由pool的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
- 第一步: 计算文件到对象的映射。
- 第二步:通过 hash 算法计算出文件对应的 pool 中的 PG:通过一致性 HASH 计算 Object 到 PG, Object -> PG 映射 hash(oid) & mask-> pgid。
- 第三步: 通过 CRUSH 把对象映射到 PG 中的 OSD 通过CRUSH算法计算PG到OSD,PG->OSD 映射:[CRUSH(pgid)->(osd1,osd2,osd3)]。
- 第四步:PG 中的主 OSD 将对象写入到硬盘。
- 第五步: 主 OSD 将数据同步给备份 OSD,并等待备份 OSD 返回确认。
- 第六步: 主 OSD 将写入完成返回给客户端。
8. Ceph PG数量的确定
- PG数量的设置牵扯到数据分布的均匀性问题。
- 预设Ceph集群中的PG数至关重要,公式如下: (结果必须舍入到最接近2的N次幂的值)
- PG 总数 = (OSD 数 * 100) / 最大副本数。
- 集群中单个池的PG数计算公式如下:(结果必须舍入到最接近2的N次幂的值)
- PG 总数 = (OSD 数 * 100) / 最大副本数 / 池数。
- PGP是为了实现定位而设计的PG,PGP的值应该和PG数量保持一致;pgp_num 数值才是 CRUSH 算法采用的真实值。
- 虽然 pg_num 的增加引起了PG的分割,但是只有当 pgp_num增加以后,数据才会被迁移到新PG中,这样才会重新开始平衡。
9. Ceph 的Cluster Map
- OSD Map:它保存一些常用的信息,包括集群ID,OSD map 自创建以来最新版本号自己最后修改时间,以及存储池相关的信息,包括存储名称,ID,状态,副本级别和PG。它还保存着OSD信息,比如数量,状态,权重,最后清理间隔以及OSD节点信息。它保存信息包括PG版本,时间戳,OSD。
- Monitor Map:它包含监视节点端到端的信息,包括ceph集群ID,monitor 节点名称,IP地址和端口等。
- PG Map:map的最新版本号,容量已满百分比,容量将满百分比,它还记录了每个PG的ID,对象数量,状态,状态时间戳。
- CRUSH Map:它保存的信息包括集群设备列表,bucket列表,故障域分层结构,为故障域定义的规则等。
- MDS Map:它保存的信息包括MDS map 当前版本号,MDS map 的创建和修改时间,数据和元数据存储池ID,集群MDS数量以及MDS状态。
10. Ceph集群部署:
10.1 基础环境
- 网络规划:两张网卡,存储内网(集群内通信)、存储外网(提供存储服务)。
- 3个mon节点,多node节点,2个mgr节点, node 上的osd盘别太小,20G后面就加不进去,建议100G。
- 操作系统:ubuntu 64 18.04.5 4.15.0-130-generic #134-Ubuntu。
10.2 Deploy节点安装ansible
~# apt install ansible
~# mkdir ansible
~# cd ansible
~# apt install sshpass
~# vim ansible.cfg
[defaults]
host_key_checking = False
~# vim hosts
[mons]
192.168.6.64 hostname=ceph_mon1.cluster.exp
192.168.6.65 hostname=ceph_mon2.cluster.exp
192.168.6.66 hostname=ceph_mon3.cluster.exp
[nodes]
192.168.6.67 hostname=ceph_node1.cluster.exp
192.168.6.68 hostname=ceph_node2.cluster.exp
192.168.6.72 hostname=ceph_node3.cluster.exp
192.168.6.71 hostname=ceph_node4.cluster.exp
[mgrs]
192.168.6.69 hostname=ceph_mgr1.cluster.exp
192.168.6.70 hostname=ceph_mgr2.cluster.exp
[deploy]
192.168.6.73 hostname=ceph_deploy.cluster.exp
[all:vars]
ansible_ssh_user=root
ansible_ssh_pass=123456
ansible_python_interpreter=/usr/bin/python3
10.3 设置hostname
~# cat hostname.yaml
---
- hosts: all
remote_user: root
gather_facts: false
tasks:
- name: change hostname
shell: "hostnamectl set-hostname {{hostname|quote}}"
- name: verify hostname
shell: "hostname"
register: hostname_result
- debug:
var: hostname_result.stdout_lines
~# ansible-playbook -i hosts hostname.yaml
10.4 设置时间同步
~# ansible -i hosts all -m shell -a "apt install -y chrony"
~# vim chrony.conf
server ntp.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp1.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp2.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp3.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp4.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp5.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp6.aliyun.com minpoll 4 maxpoll 10 iburst
server ntp7.aliyun.com minpoll 4 maxpoll 10 iburst
~# vim chrony.yaml
---
- hosts: all
remote_user: root
gather_facts: false
tasks:
- name: apt install chrony
shell: "apt install chrony"
- name: copy chrony.conf
copy: "src=./chrony.conf dest=/etc/chrony/chrony.conf"
- name: restart chrony
shell: "systemctl restart chrony"
- name: check chrony status
shell: "systemctl status chrony"
register: chrony_result
- debug:
var: chrony_result.stdout_lines
- name: enable chrony
shell: "systemctl enable chrony"
- name: check chrony active
shell: "chronyc activity"
- name: set timezone
shell: "timedatectl set-timezone Asia/Shanghai"
- name: force to synchronize time
shell: "chronyc -a makestep"
- name: check timedate status
shell: "timedatectl status"
register: timedatectl_result
- debug:
var: timedatectl_result.stdout_lines
- name: write sys clock
shell: "hwclock -w"
~# ansible-playbook -i hosts chrony.yaml
10.5 设置域名解析
~# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu.example.local ubuntu
192.168.6.64 ceph_mon1.cluster.exp ceph_mon1
192.168.6.65 ceph_mon2.cluster.exp ceph_mon2
192.168.6.66 ceph_mon3.cluster.exp ceph_mon3
192.168.6.67 ceph_node1.cluster.exp ceph_node1
192.168.6.68 ceph_node2.cluster.exp ceph_node2
192.168.6.72 ceph_node3.cluster.exp ceph_node3
192.168.6.71 ceph_node4.cluster.exp ceph_node4
192.168.6.69 ceph_mgr1.cluster.exp ceph_mgr1
192.168.6.70 ceph_mgr2.cluster.exp ceph_mgr2
192.168.6.73 ceph_deploy.cluster.exp ceph_deploy
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
~# ansible -i hosts all -m copy -a "src=/etc/hosts dest=/etc/hosts"
10.6 创建ceph用户
~# ansible -i hosts all -m shell -a 'groupadd -r -g 2022 ceph && useradd -r -m -s /bin/bash -u 2022 -g 2022 ceph && echo ceph:123456 | chpasswd'
~# ansible -i hosts all -m shell -a 'echo "ceph ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers'
10.7 配置deploy 与各节点的互信
10.7.1 deploy 主机上
~# su - ceph
~# ssh-keygen
~# for i in ceph_{mon1,mon2,mon3,node1,node2,node3,node4,mgr1,mgr2}; do ssh-copy-id ceph@$i; done
10.7.2 ubuntu 单独安装python2.7
~# ansible -i hosts all -m shell -a "apt install python -y "
10.8 Ceph集群建立
10.8.1 设置源码镜像地址
查看清华源官方添加文档https://mirrors.tuna.tsinghua.edu.cn/help/ceph/
~# ansible -i hosts all -m shell -a "wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -"
~# ansible -i hosts all -m shell -a "apt-add-repository 'deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific/ buster main'"
~# ansible -i hosts all -m shell -a "apt update"
清华源失效,使用阿里的
wget -q -O- 'https://mirrors.aliyun.com/ceph/keys/release.asc' | sudo apt-key add -
ceph_stable_release=pacific
echo deb https://mirrors.aliyun.com/ceph/debian-$ceph_stable_release/ $(lsb_release -sc)\
main | sudo tee /etc/apt/sources.list.d/ceph.list
10.8.2 安装部署工具
~# ceph@ceph_deploy:~/ceph_deploy$ apt-cache madison ceph-deploy
~# ceph@ceph_deploy:~/ceph_deploy$ sudo apt install ceph-deploy
10.8.3 初始化集群mon节点
10.8.3.1 初始化(在deploy上)
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy new --cluster-network 192.168.6.0/24 --public-network 192.168.204.0/24 ceph_mon1.cluster.exp
10.8.3.2 验证
ceph@ceph_deploy:~/ceph_deploy$ ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
ceph@ceph_deploy:~/ceph_deploy$ cat ceph.conf
[global]
fsid = 8fa8e277-a409-42ef-96b3-9b5047d86303
public_network = 192.168.204.0/24
cluster_network = 192.168.6.0/24
mon_initial_members = ceph_mon1
mon_host = 192.168.204.14
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
10.8.4 初始化node节点
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph_node1 ceph_node2 ceph_node3
- 如果部署中出现如下错误:
![]()
- 在出现错误的节点上 采用如下脚本修复:
#!/bin/bash
mv /var/lib/dpkg/info/ /var/lib/dpkg/info_old/
mkdir /var/lib/dpkg/info/
apt-get update
apt-get -f install
mv /var/lib/dpkg/info/* /var/lib/dpkg/info_old/
rm -rf /var/lib/dpkg/info
mv /var/lib/dpkg/info_old/ /var/lib/dpkg/info
10.8.5 部署mon节点
10.8.5.1 部署
- 注意:ubuntu安装ceph-mon 时需要交互配置postfix,无法使用ansible
root@ceph_mon1:~# apt install -y ceph-mon
root@ceph_mon2:~# apt install -y ceph-mon
root@ceph_mon3:~# apt install -y ceph-mon
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mon create-initial
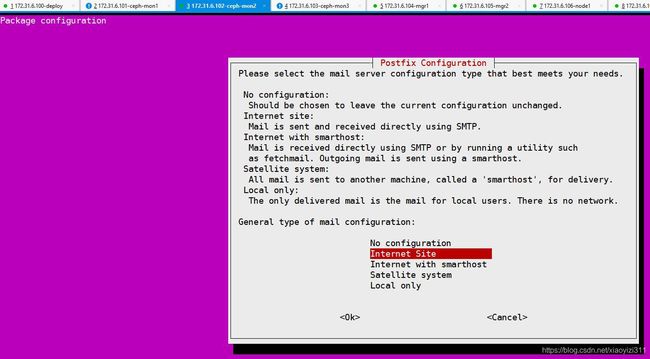

10.8.5.2 验证
root@ceph_mon1:~# ps -ef | grep ceph-mon
ceph 31410 1 0 18:37 ? 00:00:00 /usr/bin/ceph-mon -f --cluster ceph --id ceph_mon1 --setuser ceph --setgroup ceph
10.8.6 分发ceph密钥
10.8.6.1 部署
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy admin ceph_node1 ceph_node2 ceph_node3
![]()
10.8.6.2 修改ceph.client.admin.keyring的权限,对ceph用户进行授权
ansible -i hosts 192.168.6.67,192.168.6.68,192.168.6.72 -m shell -a "setfacl -m u:ceph:rw /etc/ceph/ceph.client.admin.keyring"
10.8.7 部署mgr节点
10.8.7.1 部署
root@ceph_deploy:~/ceph/ansible# ansible -i hosts mgrs -m shell -a "apt install -y ceph-mgr"
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy mgr create ceph_mgr1
10.8.7.2 验证

10.8.8 配置deploy节点管理ceph集群
root@ceph_deploy:~/ceph/ansible# apt install -y ceph-common
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy admin ceph_deploy
root@ceph_deploy:~/ceph/ansible# setfacl -m u:ceph:rw /etc/ceph/ceph.client.admin.keyring
10.8.9 检查ceph集群状态
ceph@ceph_deploy:~$ ceph -s
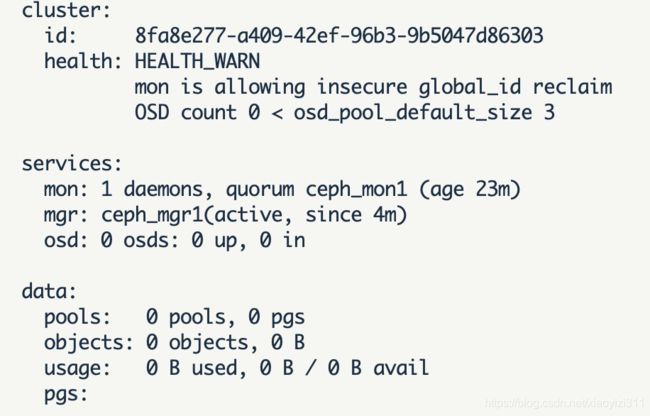
10.8.10 禁用不安全模式

ceph@ceph_deploy:~$ ceph config set mon auth_allow_insecure_global_id_reclaim false

10.8.11 部署node 节点 osd
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy install --release pacific ceph_node1
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy install --release pacific ceph_node2
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy install --release pacific ceph_node3
10.8.12 移除无用的包
root@ceph_deploy:~/ceph/ansible# ansible -i hosts nodes -m shell -a "apt -y autoremove"
10.8.13 添加OSD
10.8.13.1 列出node1 上的所有磁盘
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy disk list ceph_node1
10.8.13.2 擦除各个node上的所有数据盘
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy disk zap ceph_node1 /dev/sdb
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy disk zap ceph_node1 /dev/sdc
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy disk zap ceph_node1 /dev/sdd
ceph@ceph_deploy:/home/ceph/ceph_deploy$ ceph-deploy disk zap ceph_node1 /dev/sde
……
10.8.13.3 添加数据osd
ceph-deploy osd create ceph_node1 --data /dev/sdb
ceph-deploy osd create ceph_node1 --data /dev/sdc
ceph-deploy osd create ceph_node1 --data /dev/sdd
ceph-deploy osd create ceph_node1 --data /dev/sde
ceph-deploy osd create ceph_node2 --data /dev/sdb
ceph-deploy osd create ceph_node2 --data /dev/sdc
ceph-deploy osd create ceph_node2 --data /dev/sdd
ceph-deploy osd create ceph_node2 --data /dev/sde
ceph-deploy osd create ceph_node3 --data /dev/sdb
ceph-deploy osd create ceph_node3 --data /dev/sdc
ceph-deploy osd create ceph_node3 --data /dev/sdd
ceph-deploy osd create ceph_node3 --data /dev/sde
- 输出
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/ceph/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create ceph_node4 --data /dev/sde
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f54ce9c2960>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] journal : None
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] host : ceph_node4
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x7f54cec223d0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.cli][INFO ] data : /dev/sde
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sde
[ceph_node4][DEBUG ] connection detected need for sudo
[ceph_node4][DEBUG ] connected to host: ceph_node4
[ceph_node4][DEBUG ] detect platform information from remote host
[ceph_node4][DEBUG ] detect machine type
[ceph_node4][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: Ubuntu 18.04 bionic
[ceph_deploy.osd][DEBUG ] Deploying osd to ceph_node4
[ceph_node4][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_node4][DEBUG ] find the location of an executable
[ceph_node4][INFO ] Running command: sudo /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sde
[ceph_node4][WARNIN] Running command: /usr/bin/ceph-authtool --gen-print-key
[ceph_node4][WARNIN] Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new 4c981fcb-1054-43c1-88d0-986c2ae5d3d3
[ceph_node4][WARNIN] Running command: /sbin/vgcreate --force --yes ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e /dev/sde
[ceph_node4][WARNIN] stdout: Physical volume "/dev/sde" successfully created.
[ceph_node4][WARNIN] stdout: Volume group "ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e" successfully created
[ceph_node4][WARNIN] Running command: /sbin/lvcreate --yes -l 25599 -n osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3 ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e
[ceph_node4][WARNIN] stdout: Logical volume "osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3" created.
[ceph_node4][WARNIN] Running command: /usr/bin/ceph-authtool --gen-print-key
[ceph_node4][WARNIN] Running command: /bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-15
[ceph_node4][WARNIN] --> Executable selinuxenabled not in PATH: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin
[ceph_node4][WARNIN] Running command: /bin/chown -h ceph:ceph /dev/ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e/osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-3
[ceph_node4][WARNIN] Running command: /bin/ln -s /dev/ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e/osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3 /var/lib/ceph/osd/ceph-15/block
[ceph_node4][WARNIN] Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap
-o /var/lib/ceph/osd/ceph-15/activate.monmap
[ceph_node4][WARNIN] stderr: 2021-08-18T16:27:40.305+0800 7fe61c3cc700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
[ceph_node4][WARNIN] 2021-08-18T16:27:40.305+0800 7fe61c3cc700 -1 AuthRegistry(0x7fe61405b408) no keyring found at /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
[ceph_node4][WARNIN] stderr: got monmap epoch 3
[ceph_node4][WARNIN] Running command: /usr/bin/ceph-authtool /var/lib/ceph/osd/ceph-15/keyring --create-keyring --name osd.15 --add-key AQB7xBxht8wOIxAAqE7Q37odhf3vutdpFgYQGg==
[ceph_node4][WARNIN] stdout: creating /var/lib/ceph/osd/ceph-15/keyring
[ceph_node4][WARNIN] stdout: added entity osd.15 auth(key=AQB7xBxht8wOIxAAqE7Q37odhf3vutdpFgYQGg==)
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-15/keyring
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-15/
[ceph_node4][WARNIN] Running command: /usr/bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 15 --monmap /var/lib/ceph/osd/ceph-15/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-15/ --osd-uuid 4c981fcb-1054-43c1-88d0-986c2ae5d3d3 --setuser ceph --setgroup ceph
[ceph_node4][WARNIN] stderr: 2021-08-18T16:27:40.613+0800 7fcc28df3f00 -1 bluestore(/var/lib/ceph/osd/ceph-15/) _read_fsid unparsable uuid
[ceph_node4][WARNIN] --> ceph-volume lvm prepare successful for: /dev/sde
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-15
[ceph_node4][WARNIN] Running command: /usr/bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e/osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3 --path /var/lib/ceph/osd/ceph-15 --no-mon-config
[ceph_node4][WARNIN] Running command: /bin/ln -snf /dev/ceph-944db8e6-4bbb-49b3-9584-659a7c53c56e/osd-block-4c981fcb-1054-43c1-88d0-986c2ae5d3d3 /var/lib/ceph/osd/ceph-15/block
[ceph_node4][WARNIN] Running command: /bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-15/block
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-3
[ceph_node4][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-15
[ceph_node4][WARNIN] Running command: /bin/systemctl enable ceph-volume@lvm-15-4c981fcb-1054-43c1-88d0-986c2ae5d3d3
[ceph_node4][WARNIN] stderr: Created symlink /etc/systemd/system/multi-user.target.wants/[email protected] → /lib/systemd/system/[email protected].
[ceph_node4][WARNIN] Running command: /bin/systemctl enable --runtime ceph-osd@15
[ceph_node4][WARNIN] stderr: Created symlink /run/systemd/system/ceph-osd.target.wants/[email protected] → /lib/systemd/system/[email protected].
[ceph_node4][WARNIN] Running command: /bin/systemctl start ceph-osd@15
[ceph_node4][WARNIN] --> ceph-volume lvm activate successful for osd ID: 15
[ceph_node4][WARNIN] --> ceph-volume lvm create successful for: /dev/sde
[ceph_node4][INFO ] checking OSD status...
[ceph_node4][DEBUG ] find the location of an executable
[ceph_node4][INFO ] Running command: sudo /usr/bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host ceph_node4 is now ready for osd use.
10.8.14 验证node节点自启动
root@ceph_node1:~# ps -ef | grep osd
ceph 3471 1 0 07:46 ? 00:03:27 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
ceph 5276 1 0 07:46 ? 00:03:26 /usr/bin/ceph-osd -f --cluster ceph --id 1 --setuser ceph --setgroup ceph
ceph 7047 1 0 07:46 ? 00:03:28 /usr/bin/ceph-osd -f --cluster ceph --id 2 --setuser ceph --setgroup ceph
ceph 8834 1 0 07:46 ? 00:03:26 /usr/bin/ceph-osd -f --cluster ceph --id 3 --setuser ceph --setgroup ceph
root 10825 10761 0 13:54 pts/0 00:00:00 grep --color=auto osd
root@ceph_node1:~# systemctl is-enabled ceph-osd@1
enabled
root@ceph_node1:~# systemctl is-enabled ceph-osd@0
enabled
root@ceph_node1:~# systemctl is-enabled ceph-osd@2
enabled
10.8.15 验证ceph集群
10.8.15.1 验证集群健康状态
ceph@ceph_deploy:~$ ceph -s
cluster:
id: 8fa8e277-a409-42ef-96b3-9b5047d86303
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph_mon1 (age 7h)
mgr: ceph_mgr1(active, since 18h)
osd: 12 osds: 12 up (since 26s), 12 in (since 17h)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 83 MiB used, 1.2 TiB / 1.2 TiB avail
pgs: 1 active+clean
10.8.15.2 验证数据上传下载
10.8.15.2.1 创建testpool
ceph osd pool create testpool 32 32 #32PG 和 32PGP
ceph pg ls-by-pool testpool | awk '{print $1,$2,$15}’ #验证 PG 与 PGP 组合
ceph osd pool ls
10.8.15.2.2 使用rados 访问ceph的对象存储进行测试
- 上传文件
sudo rados put msg1 /var/log/syslog --pool=testpool #把 messages 文件上传到 mypool 并指定对象 id 为 msg1
- 列出文件
rados ls --pool=testpool
- 文件在池中存储的具体位置信息
ceph osd map testpool msg1
- 下载文件
sudo rados get msg1 --pool=testpool /opt/my.txt
- 修改文件
sudo rados put msg1 /etc/passwd --pool=testpool
- 删除文件
sudo rados rm msg1 --pool=testpool
rados ls --pool=testpool
11 ceph 集群运维
11.1 添加mon节点
root@ceph_mon2:~# apt install -y ceph-mon
root@ceph_mon3:~# apt install -y ceph-mon
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mon add ceph_mon2
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mon add ceph_mon3
11.2 添加node节点
11.2.1 节点初始化
ceph-deploy install --no-adjust-repos --nogpgcheck ceph_node4
11.2.2 添加node节点
ceph-deploy install --release pacific ceph_node4
11.2.3 分发ceph密钥
ceph-deploy admin ceph_node4
11.2.4 添加node 节点 osd
11.2.4.1 列出node4 上的所有磁盘
ceph-deploy disk list ceph_node4
11.2.4.2 擦除node4上的所有数据盘
ceph-deploy disk zap ceph_node4 /dev/sdb
ceph-deploy disk zap ceph_node4 /dev/sdc
ceph-deploy disk zap ceph_node4 /dev/sdd
ceph-deploy disk zap ceph_node4 /dev/sde
11.2.4.3 添加数据osd
ceph-deploy osd create ceph_node4 --data /dev/sdb
ceph-deploy osd create ceph_node4 --data /dev/sdc
ceph-deploy osd create ceph_node4 --data /dev/sdd
ceph-deploy osd create ceph_node4 --data /dev/sde
11.2.4.4 验证集群状态
ceph@ceph_deploy:~/ceph_deploy$ ceph -s
cluster:
id: 8fa8e277-a409-42ef-96b3-9b5047d86303
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_mon1,ceph_mon2,ceph_mon3 (age 13m)
mgr: ceph_mgr1(active, since 19h)
osd: 16 osds: 16 up (since 3m), 16 in (since 3m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 122 MiB used, 1.6 TiB / 1.6 TiB avail
pgs: 1 active+clean
11.3 添加mgr节点
11.3.1 安装ceph-mgr
root@ceph_mgr2:~# apt install ceph-mgr
11.3.2 添加mgr2到集群
ceph-deploy mgr create ceph_mgr2
11.3.3 分发admin 密钥
ceph-deploy admin ceph_mgr2
11.3.4 修改ceph.client.admin.keyring的权限,对ceph用户进行授权
setfacl -m u:ceph:rw /etc/ceph/ceph.client.admin.keyring
11.3.5 检查集群状态
ceph@ceph_deploy:~/ceph_deploy$ ceph -s
cluster:
id: 8fa8e277-a409-42ef-96b3-9b5047d86303
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph_mon1,ceph_mon2,ceph_mon3 (age 15m)
mgr: ceph_mgr1(active, since 19h), standbys: ceph_mgr2
osd: 16 osds: 16 up (since 5m), 16 in (since 5m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 122 MiB used, 1.6 TiB / 1.6 TiB avail
pgs: 1 active+clean
11.4 下线osd
11.4.1 列出所有osd
ceph@ceph_deploy:~/ceph_deploy$ ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.09769 1.00000 100 GiB 7.0 MiB 1.4 MiB 0 B 5.6 MiB 100 GiB 0.01 0.92 0 up
1 hdd 0.09769 1.00000 100 GiB 7.0 MiB 1.4 MiB 0 B 5.6 MiB 100 GiB 0.01 0.92 0 up
2 hdd 0.09769 1.00000 100 GiB 7.0 MiB 1.4 MiB 0 B 5.6 MiB 100 GiB 0.01 0.92 0 up
3 hdd 0.09769 1.00000 100 GiB 7.0 MiB 1.4 MiB 0 B 5.6 MiB 100 GiB 0.01 0.92 0 up
4 hdd 0.09769 1.00000 100 GiB 8.0 MiB 1.4 MiB 0 B 6.6 MiB 100 GiB 0.01 1.06 0 up
5 hdd 0.09769 1.00000 100 GiB 8.0 MiB 1.4 MiB 0 B 6.6 MiB 100 GiB 0.01 1.06 0 up
6 hdd 0.09769 1.00000 100 GiB 8.0 MiB 1.4 MiB 0 B 6.6 MiB 100 GiB 0.01 1.05 1 up
7 hdd 0.09769 1.00000 100 GiB 8.0 MiB 1.4 MiB 0 B 6.6 MiB 100 GiB 0.01 1.05 0 up
8 hdd 0.09769 1.00000 100 GiB 7.9 MiB 1.4 MiB 0 B 6.5 MiB 100 GiB 0.01 1.04 0 up
9 hdd 0.09769 1.00000 100 GiB 7.9 MiB 1.4 MiB 0 B 6.4 MiB 100 GiB 0.01 1.03 0 up
10 hdd 0.09769 1.00000 100 GiB 7.9 MiB 1.4 MiB 0 B 6.4 MiB 100 GiB 0.01 1.03 0 up
11 hdd 0.09769 1.00000 100 GiB 7.8 MiB 1.4 MiB 0 B 6.4 MiB 100 GiB 0.01 1.03 1 up
12 hdd 0.09769 1.00000 100 GiB 7.6 MiB 1.4 MiB 0 B 6.2 MiB 100 GiB 0.01 1.00 0 up
13 hdd 0.09769 1.00000 100 GiB 7.6 MiB 1.4 MiB 0 B 6.2 MiB 100 GiB 0.01 1.00 1 up
14 hdd 0.09769 1.00000 100 GiB 7.5 MiB 1.4 MiB 0 B 6.1 MiB 100 GiB 0.01 0.99 0 up
15 hdd 0.09769 1.00000 100 GiB 7.5 MiB 1.4 MiB 0 B 6.1 MiB 100 GiB 0.01 0.98 0 up
TOTAL 1.6 TiB 122 MiB 22 MiB 3.8 KiB 99 MiB 1.6 TiB 0.01
MIN/MAX VAR: 0.92/1.06 STDDEV: 0
11.4.2 显示osd与node的对应关系,确认需要下线的node有哪些osd
ceph@ceph_deploy:~/ceph_deploy$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.56299 root default
-3 0.39075 host ceph_node1
0 hdd 0.09769 osd.0 up 1.00000 1.00000
1 hdd 0.09769 osd.1 up 1.00000 1.00000
2 hdd 0.09769 osd.2 up 1.00000 1.00000
3 hdd 0.09769 osd.3 up 1.00000 1.00000
-5 0.39075 host ceph_node2
4 hdd 0.09769 osd.4 up 1.00000 1.00000
5 hdd 0.09769 osd.5 up 1.00000 1.00000
6 hdd 0.09769 osd.6 up 1.00000 1.00000
7 hdd 0.09769 osd.7 up 1.00000 1.00000
-7 0.39075 host ceph_node3
8 hdd 0.09769 osd.8 up 1.00000 1.00000
9 hdd 0.09769 osd.9 up 1.00000 1.00000
10 hdd 0.09769 osd.10 up 1.00000 1.00000
11 hdd 0.09769 osd.11 up 1.00000 1.00000
-9 0.39075 host ceph_node4
12 hdd 0.09769 osd.12 up 1.00000 1.00000
13 hdd 0.09769 osd.13 up 1.00000 1.00000
14 hdd 0.09769 osd.14 up 1.00000 1.00000
15 hdd 0.09769 osd.15 up 1.00000 1.00000
11.4.3 停用osd
ceph@ceph_deploy:~/ceph_deploy$ ceph osd out 15
11.4.4 停止node上的osd进程
root@ceph_node4:~# systemctl status ceph-osd@15
11.4.5 移除osd
ceph@ceph_deploy:~/ceph_deploy$ ceph osd purge 15
purged osd.15
11.4.6 验证是否成功
ceph@ceph_deploy:~/ceph_deploy$ ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.09769 1.00000 100 GiB 7.3 MiB 1.5 MiB 0 B 5.7 MiB 100 GiB 0.01 0.95 0 up
1 hdd 0.09769 1.00000 100 GiB 7.3 MiB 1.5 MiB 0 B 5.7 MiB 100 GiB 0.01 0.95 0 up
2 hdd 0.09769 1.00000 100 GiB 7.3 MiB 1.5 MiB 0 B 5.7 MiB 100 GiB 0.01 0.95 0 up
3 hdd 0.09769 1.00000 100 GiB 7.3 MiB 1.5 MiB 0 B 5.7 MiB 100 GiB 0.01 0.95 0 up
4 hdd 0.09769 1.00000 100 GiB 8.3 MiB 1.5 MiB 0 B 6.8 MiB 100 GiB 0.01 1.08 0 up
5 hdd 0.09769 1.00000 100 GiB 8.4 MiB 1.5 MiB 0 B 6.9 MiB 100 GiB 0.01 1.09 0 up
6 hdd 0.09769 1.00000 100 GiB 8.4 MiB 1.5 MiB 0 B 6.8 MiB 100 GiB 0.01 1.08 1 up
7 hdd 0.09769 1.00000 100 GiB 8.3 MiB 1.5 MiB 0 B 6.8 MiB 100 GiB 0.01 1.08 0 up
8 hdd 0.09769 1.00000 100 GiB 8.2 MiB 1.5 MiB 0 B 6.7 MiB 100 GiB 0.01 1.07 0 up
9 hdd 0.09769 1.00000 100 GiB 8.1 MiB 1.5 MiB 0 B 6.6 MiB 100 GiB 0.01 1.06 0 up
10 hdd 0.09769 1.00000 100 GiB 8.2 MiB 1.5 MiB 0 B 6.6 MiB 100 GiB 0.01 1.06 0 up
11 hdd 0.09769 1.00000 100 GiB 8.2 MiB 1.5 MiB 0 B 6.6 MiB 100 GiB 0.01 1.06 1 up
12 hdd 0.09769 1.00000 100 GiB 6.8 MiB 1.5 MiB 0 B 5.2 MiB 100 GiB 0.01 0.88 0 up
13 hdd 0.09769 1.00000 100 GiB 6.8 MiB 1.5 MiB 0 B 5.2 MiB 100 GiB 0.01 0.88 1 up
14 hdd 0.09769 1.00000 100 GiB 6.7 MiB 1.5 MiB 0 B 5.2 MiB 100 GiB 0.01 0.87 0 up
TOTAL 1.5 TiB 116 MiB 23 MiB 6.6 KiB 92 MiB 1.5 TiB 0.01
MIN/MAX VAR: 0.87/1.09 STDDEV: 0
11.5 解决too many PGs per osd

11.5.1 查询目前mon_max_pg_per_osd的值
ceph config show-with-defaults osd.0 | grep mon_max_pg_per_osd
mon_max_pg_per_osd 250 default
11.5.2 修改
- 修改配置文件,需要重启ceph服务
ceph@ceph_deploy:~$ cat ceph_deploy/ceph.conf
[global]
fsid = 8fa8e277-a409-42ef-96b3-9b5047d86303
public_network = 192.168.204.0/24
cluster_network = 192.168.6.0/24
mon_initial_members = ceph_mon1
mon_host = 192.168.204.14
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon_max_pg_per_osd = 300
ceph-deploy --overwrite-conf config push ceph_mon1 ceph_mon2 ceph_mon3 ceph_node1 ceph_node2 ceph_node3 ceph_node4 ceph_mgr1 ceph_mgr2
ansible -i hosts all -m shell -a "systemctl restart ceph.target"
- 直接修改,不用重启服务
ceph config set osd mon_max_pg_per_osd 300
11.6 安装dashboard
ceph@ceph_deploy:~$ ceph mgr module enable dashboard —force
ceph@ceph_deploy:~$ ceph dashboard create-self-signed-cert
ceph@ceph_deploy:~$ mkdir mgr-dashboard && cd mgr-dashboard
ceph@ceph_deploy:~$ openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
ceph@ceph_deploy:~$ ceph mgr module disable dashboard
ceph@ceph_deploy:~$ ceph mgr module enable dashboard
ceph@ceph_deploy:~$ ceph config set mgr mgr/dashboard/server_addr 192.168.204.19
ceph@ceph_deploy:~$ ceph config set mgr mgr/dashboard/server_port 8443
ceph@ceph_deploy:~$ ceph mgr services
{
"dashboard": "https://192.168.204.19:8443/"
}
ceph@ceph_deploy:~$ vim dashboard.pass
123456
ceph dashboard set-login-credentials admin -i dashboard.pass
12 额外知识点
12.1 热添加磁盘后,让ubuntu系统识别
# ll /sys/class/scsi_host/host
host0/ host1/ host2/
# echo "- - -" > /sys/class/scsi_host/host0/scan #重新扫描总线上的磁盘
# echo "- - -" > /sys/class/scsi_host/host1/scan
# echo "- - -" > /sys/class/scsi_host/host2/scan