机器学习:集成学习之 Bagging、Boosting和AdaBoost
Bagging、Boosting和AdaBoost(Adaptive Boosting)都是Ensemble learning的方法。集成学习其实就是有很多个分类器,概念就是三个臭皮匠,顶过诸葛亮。
ensemble learning的基本条件是每个分类器之间要有差异,并且每个分类器的准确率需要大于0.5.如果分类器没有差异,那么用多个分类器和用一个分类器没有什么差别,如果单个分类器的准确率小于0.5那么随着集成规模的增加,准确率却在不断下降。如果单个分类器的准确率大于0.5,随着集成规模的增加,理论上准确率可以接近于1.
既然集成学习顾名思义就是要产生很多个分类器,所以大家把研究的目标放在怎么产生多个分类器。bagging、Boosting和Adaboost都是产生多个分类器的手法。
Bagging
Bagging概念比较简单,从训练器中随机抽取样本(取出后放回)训练多个分类器(分类器的个数由自己设定),每个分类器的权重一致,最后用投票的方式(Majority vote)得到最终结果,而这种抽样的方法在统计上称为bootstrap。
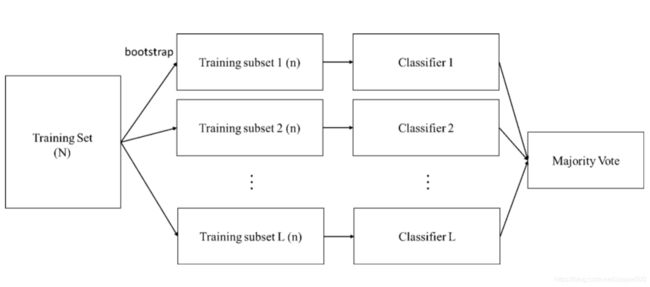
Bagging的精髓在于从样本中抽样,如果模型不是分类问题而是预测问题,分类器部分可以改成regression,最后投票方式改成算平均数即可。用Bagging会希望单一分类器能够是一个比较好的分类器。Bagging的优点在于如果原始训练样本中有噪声资料,透过Bagging抽样就有机会不让噪声资料被训练到,可以降低模型的不稳定性。
Boosting
Boosting算法是将很多个弱分类器进行合成变成一个强分类器,和Bagging不同的是分类器之间是有关联性的,是通过将旧分类器的错误数据权重提高,然后再训练新的分类器,这样新分类器就会学习到分类错误样本的特征,进而提升分类结果。
Boosting的概念很玄,我自己的理解是旧的分类器训练有些数据落在confusion area,如果在用全部的data去训练,错的数据永远都会判断错误。因此需要针对错误的数据去学习,也就是将错误数据的权重加大,这样新训练出来的分类器才能针对这些错误数据得到好的结果。
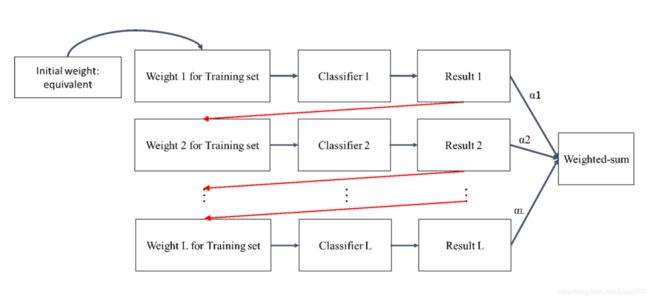
由于Boosting将注意力集中在分类错误的数据上,因此Boosting对训练数据的噪声非常敏感,如果一份训练数据噪声非常多,将导致后面的分类器都会集中在进行噪声数据上分类,反而会影响最终的分类性能。
对于Boosting来说,有两个关键,一是如何改变训练数据的权重,二是如何将多个若分类器组合成一个强分类器。
AdaBoost
AdaBoost是一种改进的Boosting分类算法。方式是提高被前几个分类器线性组合的分类错误样本的权重,这样可以让每次训练新的分类器的时候都聚焦在容易分类错误的训练样本上。每个弱分类器使用加权投票机制取代平均投票机制,准确率较大的弱分类器有较大的权重,准确率较低的弱分类器投票时权重较低。
Adaboost让判断错误的train data提高权重,产生新的权重的train set让旧的分类器fail掉,但在新的分类器上去加强学习这些新的training set。
Bagging与Boosting的区别之处:
训练样本:
Bagging :每一次的训练集是随机抽取(每个样本权重一致),抽出可放回,以独立同分布选取的训练样本子集训练弱分类器。
Boosting :每一次的训练集不变,训练集之间的选择不是独立的,每一是选择的训练集都是依赖上一次学习得结果,根据错误率(给予训练样本不同的权重)取样。
分类器:
Bagging :每个分类器的权重相等。
Boosting :每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
每个分类器的生成:
Bagging :每个分类器可以并行生成。
Boosting :每个弱分类器只能依赖上一次的分类器顺序生成。
Bagging和Boosting这两种方法是比较常见的ensemble learning的方法,当然ensemble learning还有很多不同的方法,比如
1. 将不同的分类器进行合成提高单一分类器的效果例如SVM+k-NN+MLP+QDA+BNC等。
2.很多个SVM合成,方式为每个SVM给不同的kernel function或是kernel参数。
3. Random subspace: 这个概念跟bagging很像,不同的是bagging是从训练样本去抽样产生不同的训练集来训练分类器,但Random subspace是feature bagging,从特征中去抽样,然后训练多个分类器做合成,通常用在非常高维度的资料中。当然也有衍生出来的feature Adaboosting。
但不论用哪种方式都是把多个分类器整合出一个结果,只是整合的方式不一样,最终得到不一样的效果。
ensemble learning 关于 Decision tree
1. Random Forest : Bagging + Decision tree
2. Boosting Tree : AdaBoost + Decision tree
3. GBDT : Gradient Boost + Decision tree