Apollo源码剖析学习笔记2
Apollo 源码剖析学习笔记2
Talker-ListenerNode
目录中包含了 Node 对象、Reader 对象和 Writer 对象。Node 对象主要对应 Ros 中的 Node 节点,在Node 节点中可以创建 Reader 和 Writer来订阅和发布消息,需要管理对应的通道注册:
创建Node 对象
在 CyberRT 框架下,node 是最基础的单元。在创建 writer,reader 等均需要连接到一个node上。
在 cyberRT 中创建方法如下:
std::unique_ptr<Node> apollo::cyber::CreateNode(const std::string& node_name, const std::string& name_space = "");
参数:
node_name: node 的名称,必须保证全局是唯一的,不能重名。
name_space: node 所在的命名空间。宇要用来防止node_name 发生冲突。name_space 默认为空,加入命
名空间后,node 的 name 变成 /namespace/node name:
return value: node 的独占智能指针。
在cyber:Init()还未执行前,系统还处于未初始化状态,没法创建 node,会直接返回 mullpt
Writer 对象
writer 是 CyberRT 中,用来发布消息最基本的方法。每个 writer 对应一个特定消息类型的 channel。writer可以通过 Node 类中的 CreateWriter 接口创建。具体如下:
template <typename MessageT>
auto CreateWriter(const std::string& channel_name)
-> std::shared_ptr<Writer<MessageT>>;
template <typename MessageT>
auto CreateWriter(const proto::RoleAttributes& role_attr)
-> std::shared_ptr<Writer<MessageT>>;
参数:
channel name: 字面意思,就是该 writer 对应的 channel nameMessageT: 写入的消息类型
Teturn value: std::shared_ptr
Reader 对象
reader 是接收消息最基础的方法。reader 必须绑定一个回调函数。当 channel 中的消息到达后,回调会被调用。reader 可以通过 Node 类中 CreateReader 接口创建。具体如下:
template <typename MessageT>
auto CreateReader(const std::string& channel_name,
const CallbackFunc<MessageT>& reader_func = nullptr)
-> std::shared_ptr<cyber::Reader<MessageT>>;
template <typename MessageT>
auto CreateReader(const ReaderConfig& config,
const CallbackFunc<MessageT>& reader_func = nullptr)
-> std::shared_ptr<cyber::Reader<MessageT>>;
template <typename MessageT>
auto CreateReader(const proto::RoleAttributes& role_attr,
const CallbackFunc<MessageT>& reader_func = nullptr)
-> std::shared_ptr<cyber::Reader<MessageT>>;
talker.cc
#include "cyber/examples/proto/examples.pb.h"
#include "cyber/cyber.h"
#include "cyber/time/rate.h"
#include "cyber/time/time.h"
using apollo::cyber::Rate;
using apollo::cyber::Time;
using apollo::cyber::examples::proto::Chatter;
int main(int argc, char *argv[])
{
// init cyber framework
apollo::cyber::Init(argv[0]);
// create talker node
auto talker_node = apollo::cyber::CreateNode("talker");
// create talker
auto talker = talker_node->CreateWriter<Chatter>("channel/chatter");
Rate rate(1.0);
uint64_t seq = 0;
while (apollo::cyber::OK())
{
auto msg = std::make_shared<Chatter>();
msg->set_timestamp(Time::Now().ToNanosecond());
msg->set_lidar_timestamp(Time::Now().ToNanosecond());
msg->set_seq(seq);
msg->set_content("Hello, apollo!");
talker->Write(msg);
AINFO << "talker sent a message! No. " << seq;
seq++;
rate.Sleep();
}
return 0;
}
listener.cc
#include "cyber/examples/proto/examples.pb.h"
#include "cyber/cyber.h"
void MessageCallback(
const std::shared_ptr<apollo::cyber::examples::proto::Chatter> &msg)
{
AINFO << "Received message seq-> " << msg->seq();
AINFO << "msgcontent->" << msg->content();
}
int main(int argc, char *argv[])
{
// init cyber framework
apollo::cyber::Init(argv[0]);
// create listener node
auto listener_node = apollo::cyber::CreateNode("listener");
// create listener
auto listener =
listener_node->CreateReader<apollo::cyber::examples::proto::Chatter>(
"channel/chatter", MessageCallback);
apollo::cyber::WaitForShutdown();
return 0;
}
Service-client
一个自动驾驶系统中, 很多场景不仅需要收发消息,模块之间还需要更多的通信方式。服务是节点之间的另一种通信方式。和通道不同,服务实现了双向同步通信: 一个节点通过发送一个请求得到一个响应。本节通过一个实例介绍 Cyber RT 中的服务模块。
Demo 实例
创建一个客服端-服务器模型,往返传递 Driver.proto 参数。当客户端发送一个请求,服务器解析处理这个请求并返回一个响应。这个模型的实现主要包括如下步骤:1
1、定义请求和响应消息
Cyber 中所有的消息都是基于 protobuf 格式。任何基于序列化或者反序列化接口的 protobuf 消息,都能被应用到服务请求和响应消息。下面的文件,examples.proto 是使用1服务端请求和客户端响应的例子。
//filename:examples.proto
syntax = "proto2"
package apollo.cyber.examples.proto
message Driver
{
optional string content = 1;
optional uint64 msg_id = 2;
optional uint64 timestamp = 3;
};
2.Create a service and a client
filename:cyber/examples/service.cc
#include "cyber/cyber.h"
#include "cyber/examples/proto/examples.pb.h"
using apollo.cyber::examples::proto::Driver;
int main(int argc,char*argv[])
{
apollo::cyber::Init(argv[0]);
std::shared_ptr<apollo::cyber::Node> node(apollo::cyber::CreateNode("start_node"));
auto server = node->CreateService<Driver,Driver>("test_server",[](const std::shared_ptr<Driver>& request,std::shared_ptr<Driver>& response))
{
AINFO<<"server: I am driver server";
static uint64_t id = 0;
++id;
response->set_msg_id(id);
response->set_timestamp(0);
});
auto client = node->CreateClient<Driver,Driver>("test_server");
auto driver_msg = std::make_shared<Driver>();
driver_msg->set_msg_id(0);
driver_msg->set_timestamp(0);
while(apollo::cyber::OK)
{
auto res = client->SendRequest(driver_msg);
if(res!=nullptr)
{
AINFO<<"client:response: "<<res->ShortDebugString();
}
else
{
AINFO<<"client:service may not ready";
}
sleep(1);
}
apollo::cyber::WaitForShutdown();
}
注意
\1) 每当注册一个服务, 注意如果两个服务重名是允许的。
\2) 每当注册一个服务器和客户端时, 服务器端和客户端的节点名字也不能重名。
Parameter Service
节点之间通过参数服务共享数据, 提供基本的操作,set、get 和 list。 参数服务器基于 Service 实现,含有服务器和客户端。
参数对象
支持的数据类型
通过 Cyber 传递的所有参数是 apollo: :cyber::Parameter 对象, 下表列出了支持的 5 种参数类型。
| 参数类型 | C++数据类型 | protubuf数据类型 |
|---|---|---|
| apollo::cyber::proto::ParamType::INT | int64_t | int64_t |
| apollo::cyber::proto::ParamType::DOUBLE | double | double |
| apollo::cyber::proto::ParamType::BOOL | bool | bool |
| apollo::cyber::proto::ParamType::STRING | std::string | string |
| apollo::cyber::proto::ParamType::PROTOBUF | std::string | string |
| apollo::cyber::proto::ParamType::NOT_SET | - | - |
除了上面 5 种数据类型以外,Parameter 还支持以 protobuf 对象作为传入参数的接口, 执行序列化处理后的对象并将其转换为字符串类型进行传输。
创建参数对象
支持的构造函数:
Paramter(); //Name is empty,type is NOT_SET
explicit Parameter(const Parameter& parameter);
explicit Parameter(const std::string& name);
Parameter(const std::string& name,const bool bool_value);
Parameter(const std::string& name,const int int_value);
Parameter(const std::string& name,const int64_t int_value);
Parameter(const std::string& name,const float double_value);
Parameter(const std::string& name,const double double_value);
Parameter(const std::string& name,const std::string& string_value);
Parameter(const std::string& name,const char* string_value);
Parameter(const std::string& name,const std::string& msg_str,
const std::string& full_name,const std::string& proto_desc);
Parameter(const std::string& name,const google::protobuf::Message& msg);
参数对象实例
Parameter a("int",10);
Parameter b("bool",true);
Parameter c("double",0.1);
Parameter d("string","cyber");
Parameter e("string",std::string("cyber"));
//proto message Chatter
Chatter chatter;
Parameter f("chatter",chatter);
std::string msg_str(" ");
chatter.SerializeToString(&msg_str);
std:string msg_desc("");
ProtobuffFactory::GetDescriptorString(chatter,&msg_desc);
Parameter g("chatter",msg_str,Chatter::descriptor()->full_name(),msg_desc);
1、接口和数据读取
接口列表:
inline ParamType type() const;
inline std::string TypeName() const;
inline std::string Descriptor() const;
inline const std::string Name() const;
inline bool AsBool() const;
inline int64_t AsInt64() const;
inline double AsDouble() const;
inline const std::string AsString() const;
std::string DebugString() const;
template <typename Type>
typename std::enable_if<std::is_base_of<google::protobuf::Message, Type>::value, Type>::type
value() const;
template <typename Type>
typename std::enable_if<std::is_integral<Type>::value && !std::is_same<Type, bool>::value, Type>::type
value() const;
template <typename Type>
typename std::enable_if<std::is_floating_point<Type>::value, Type>::type
value() const;
template <typename Type>
typename std::enable_if<std::is_convertible<Type, std::string>::value, const std::string&>::type
value() const;
template <typename Type>
typename std::enable_if<std::is_same<Type, bool>::value, bool>::type
value() const;
2、使用接口实例:
Parameter a("int", 10);
a.Name(); // return int
a.Type(); // return apollo::cyber::proto::ParamType::INT
a.TypeName(); // return string: INT
a.DebugString(); // return string: {name: "int", type: "INT", value: 10}
int x = a.AsInt64(); // x = 10
x = a.value<int64_t>(); // x = 10
x = a.AsString(); // Undefined behavior, error log prompt
f.TypeName(); // return string: chatter
auto chatter = f.value<Chatter>();
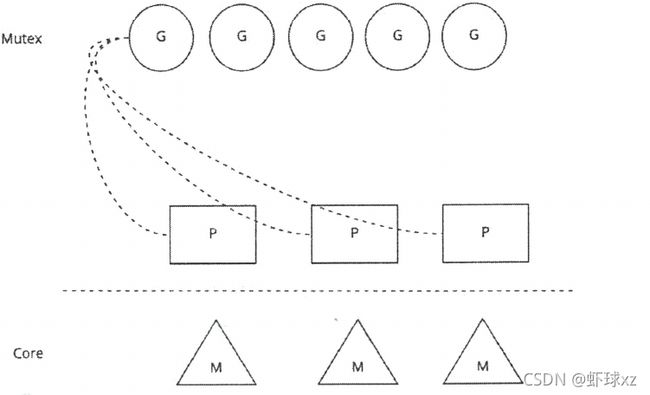
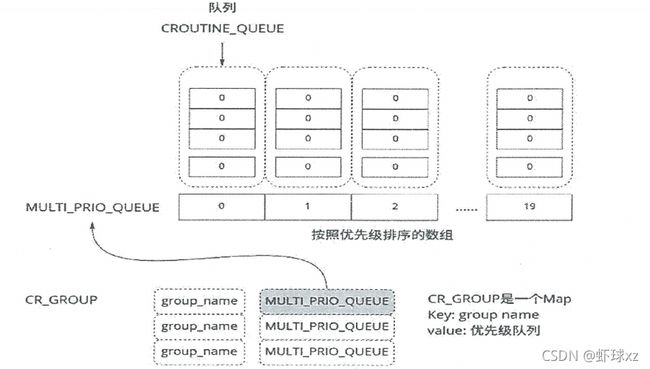
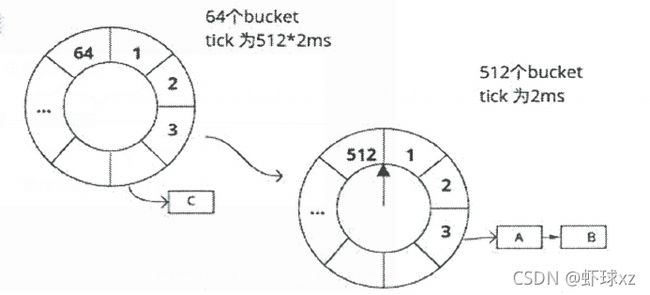
参数服务器
如果一个节点想要给其他节点提供参数服务, 你需要创建 因为所有参数都被存储再参数服务器对象中,所以能直接操作参数服务器中的参数, 不需要发数服务请求。 1、设置参数 2、获取参数 3 参数客户端 如果一个节点想要使用其他节点的参数服务,你需要创建“ParameterClient”。 你也能执行参数服务下“SetParameter,nxGetparametero 和“ListParameters"方法。 1、Demo 实例 CRoutine 协程 协程是用户态的线程, 由于进程切换需要用户态到内核态的切换, 而协程不需要切换到内核态,因此协程的切换开销比线程低。 实际上线程切换的过程如下: 1、保存当前线程的现场到堆栈,寄存器, 栈指针 2、用户态切换到内核态 3、切换到另外一个线程,跳转到栈指针, 恢复现场一个线程的几种状态: running、sleeping。 那么协程需要几种状态呢? 可以看到协程的状态有 5 种: 准备好、结束、 睡觉、等待 IO、等待数据。接着看下 CRoutine 的实现。 下面总结一下 CRoutine 的切换流程。 Scheduler 调度 所谓的调度,一定是系统资源和运行任务的矛盾,如果系统资源足够多,那么就不需要调度了,也没有调度的必要。调度的作用就是在资源有限的情况下,合理利用系统资源,使系统的效率最高。 Scheduler* Instance()在“scheduler_factory’cc”中实现了“Scheduler* Instance0”方法,该方法根据“conf”目录中的配置创建不同的调度策略。Cyber 中有 2 种调度策略“SchedulerClassic”和“SchedulerChoreosraphy”。要理解上述 2种模型,可以参考 go 语言中的 GPM 模型。1、SchedulerClassic 采用了协程池的概念,协程没有绑定到具体的 Processor,所有的协程放在全局的优先级队列中,每次从最高优先级的任务开始执行。2、SchedulerChoreography 采用了本地队列和全局队列相结合的方式,通过“ChoreographyContext”运行本地队列的线程,通过“ClassicContext ”来运行全局队列。 疑问: 这里的调度对象为原子指针“std::atomic instance”,为什么需要设置内存模型,并且加锁呢? 基本概念 1、GPM 模型 GPM 模型是 go 语言中的概念,G 代表协程,P 代表执行器,M 代表线程* P 代表协程执行的环境,一个P 绑定一个线程 M,协程 G 根据不同的上下文环境在P 中执行,上述的设计解焰了协程和线程,线程和协程都只知道P 中, 在 go 语言中还有一个调度器,把具体的协程分配到不同的P 中,这样就可以在用户态实现协程的调度,同时执行多个任务。 在 go 语言早期,只有一个全局的协程队列,每个P 都会从全局队列中取任务,然后执行。因为多个P 都会去全局队列中取任务,因此会带来并发访问,需要在全局队列中加锁。全局队列调度模型如图。 上述方法虽然实现了多个任务的调度,但是带来的问题是多个 P 都会去竞争全局锁,导致效率低下,之后 go 语言对调度模型做了改善,改善之后每个P 都会拥有一个本地队列,P 优先从本地队列中取任务执行,如果了 中没有任务了,那么 P 会从全局或者相邻的任务中偷取一半的任务执行,这样带来的好处是不需要全局锁了,每个P 都优先执行本地队列。另外调度器还会监视P 中的协程,如果协程过长时间阻塞,则会把协程移动到全局队列,以示逢罚。本地队列加全局队列如图。 理解了 GPM 模型,下面我们接着看 Cyber 中的调度器,SchedulerClassic 代表着全局队列模型,SchedulerChoreography 则代表着本地队列加全局队列模型。SchedulerChoreography 模型和 go 语言的模型稍微有点区别,全局队列和本地队列是隔离的,也就是说本地队列不会去全局队列中取任务。 2、Processor 执行器 Processor 执行器是协程的载体,对协程来说 Prozessor 就是逻辑的 CPU。Processor 中有协程执行的上下文信息,还有绑定的线程信息。先看下BindContext 的实现。 也就是说协程运行在 Processor 之上, 切换协程的时候传入对应的上下文到 Processor,然后 Processor 开始执行协程任务-:下面看 Processor 是如何执行的。 因为 Processor 每次都会从高优先级的队列开始取任务,假设 Processor 的数量不够,可能会出现低优先级的协程永远得不到调度的情况。 协程的调度没有抢占,也就是说一个协程在执行的过程中,除非主动让出,和否则会一直占用 Processor,如果 Processor 在执行低优先级的任务,来了一个高优先级的任务并不能抢古执行。调度器的抢占还是交给线程模型去实现了,cyber 中通过调节 cgroup 来调节,保证优先级高的任务优先执行。 一共有 2 种 ProcessorContext 上下文“ClassicContext”和“ChoreographyContext”上下文,分别对应不同的调度策略。后面分析 Scheduler 对象的时候,我们会接着分析。 conf 配置文件 Scheduler 调度的配置文件在“conf”目录中,配置文件中可以设置线程的 CPU 亲和性以及调度测量,也可以设置 cgroup,还可以设置协程的优先级。下面以“example_sched_classic.conf”文件来举例子。 下面我们开始看调度器,上述已经简单的介绍了 2 种调度器,SchedulerClassic 是基于全局优先队列的调度器。4和SchedulerClassic 调度器 我们知道协程实际上建立在线程之上,线程分时执行多个协程,看上去多个协程就是一起工作的。假如让你设计一个协程池, 首先需要设置协程池中协程的个数,当协程超过协程池个数的时候需要把协程放入一个阻塞队列中,如果队列满了,还有协程到来,那么丢弃到来的协程,并且报错。 (上述设计借鉴了线程池的思路) 1、创建 Processor调度器中首先会创建 Processor,并且绑定到线程。调度器根据“conf”目录中的 cgroup 配置初始化线程, SchedulerClassic 是 Scheduler 的子类,Scheduler 中实现了“CreateTask”和“NotifyTask”接口,用于创建任务和唤醒任务。对用户来说只需要关心任务,Scheduler 为我们屏蔽了 Processor 对象的操作。对应的子类中实现了“DispatchTask”,“RemoveTask”和“NotifyProcessor”的操作。 我们先看 Scheduler 如何创建任务。 总结: 这里 NotifyProcessor 实际上就是唤醒对应 Processor 的上下文执行环境。 疑问: 如果协程在等待 IO, 系统知道协程在等待 io, 但还是触发对应的协程组去工作。 并没有让协程继续阻塞?再看如何从“ClassicContext”获取 Processor 执行的协程。下图是全局协程队列的数据结构, 为一个 2 级数组,第一级数组为优先级数组,第二级数组为一个队列。 我们知道线程阻塞的条件有 4 种: 关于 SchedulerClassic 我们就先介绍到这里,下面我们开始介绍另外一种调度器 SchedulerChoreography SchedulerChoreography 调度器 在看 SchedulerChoreography 如何分发任务。 ChoreographyContext 中“Wait”和“Notify ”方法与 ClassicContext 类似,这里就不展开了。总结1、SchedulerClassic 采用了协程池的概念,协程没有绑定到具体的 Processor,所有的协程放在全局的优先级队列中,每次从最高优先级的任务开始执行。2、SchedulerChoreography 采用了本地队列和全局队列相结合的方式,通过“ChoreographyContext”运行本地队列的线程,通过“ClassicContext”来运行全局队列。3 、Processor 对协程来说是一个逻辑上的 cpu,ProcessorContext 实现 Processor 的运行上下文,通过ProcessorContext 来获取协程,休眼或者唤醒,Scheduler 调度器实现了协程调度算法。下面介绍下 cyber 的异步调用接口"cyber:Async",启动异步执行任务。 异步调用 在“taskh”中定义了异步调用的方法包括“Async”,“Yield”, “SleepFor”,“USleep” 方法。下面我们逐个看下上述方法的实现。 Async 方法 如果为真实模式,则采用“TaskManager”的方法生成协程任务,如果是仿真模式则创建线程。 TaskManager 实际上实现了一个任务池,最大执行的任务数为scheduler 模块中设置的 TaskPoolSize 大小。超出的任务会放在大小为 1000 的有界队列中,如果超出 1000,任务会被丢弃。下面我们看 TaskManager 的具体实现。 1、协程承载运行具体的任务,也就是说如果任务队列中有任务,则调用协程去执行,如果队列中没有任务,则让出协程,: 并且设置协程为等待数据的状态,那么让出协程之后唤醒是谁去触发的呢? 每次在任务队列中添加任务的时候,会唤醒协程执行任务。 接着看下 Enqueue 的实现,加入任务到任务队列。 每次在任务队列中添加任务的时候,唤醒任务协程中所有的协程。 Yield 和 Sleep 方法 Yield 方法和 Async 类似,如果为协程则让出当前协程,如果为线程则让出线程。SleepFor 和 USleep 方法类似,这里就不展开了。 SysMo 系统监控 SysMo 模块的用途主要是监控系统协程的运行状况。 Start Checker 每隔 100ms 调用1次 Checker,获取调度信息。 打印的是协程的调度快照。 Timer 定时器 定时器提供在指定的时间触发执行的功能。定时器的应用非常普遍,比如定时触发秒杀活动、定时清理日志、定时发送心跳信息等。实现定时器的方法多种多样,古代有采用水漏或者沙漏的方式,近代有采用机械的方式(各种各样的时钟) ,数字脉冲,元素衰减等方式。 在计算机领域有.2 种形式,一种是硬件定时器,一种是软件定时器。 硬件定时器的原理是计算时钟脉冲,:当规定的时钟脉冲之后由硬件触发中断程序执行,硬件定时器一般是芯片自带的,硬件定时器时间比较精准但是数量有限,因此人们又发明了软件定时器。软件定时器由软件统计计算机时钟个数,然后触发对应的在务执行;由于是纯软件实现,理论上可以创建很多个,下面我们主要看下软件定时器的实现。 定时器实现 1、双向链表 首先我们想到的是把定时任务放入一个队列中,每隔固定的时间〈一个 tick) 去检查队列中是否有超时的任务,如果有,则触发执行该任务。这样做的好处是实现简单,但是每次都需要轮询整个队列来找到谁需要被和触发,当队列的长度很大时,每个固定时间都需要去轮询一次队列,时间开销比较大。当我们需要删除一个任务的时候,也需要轮询一遍队列找到需要删除的任务,实际上我们可以优化一下用双向链表去实现队列,这样删除的任务的时间复杂度就是 O(0)了。总结一下就是采用双向链表实现队列,插入的时间复杂度是 00D,副除的时间复杂度也是 O(D),但是查询的时间复杂度是 Oo)。 2、最小堆 最小堆的实现方式是为了解决上述查找的时候需要遍历整个链表的问题, 我们知道最小堆中堆项的元素就是最小的元素,每次我们只需要检查堆项的元素是否超时,超时则弹出执行,然后再检查新的堆顶元素是否超时,这样查找可执行任务的时间复杂度约等于 0(D),最小堆虽然提高了查找的时间,但是插入和删除任务的时间复杂度为 O(og2n)。下面我们看一个例子。 堆中节点的值存放的是任务到期的时间,每隔 1 分钟判断下 是否有任务需要执行,比如任务 A 是 19:01 分触发,周期为 5 分钟,任务 B 是 19:02 分触发,周期为 10 分钟,那么第一次最小扒弹出 19:01,执行之后,在堆中重新插入 19:06 分的任务 A,这时候任务 B 到了堆项,!1 分钟之后检测需要执行任务 B,执行完成后,在堆中重新插入 19:12 分的任务 B。然后循环执行上述过程。每执行一次任务都需要重新插入任务到堆中,当任务频繁执行的时候,插入任务的开销也不容忽略。 3、时间轮 最后, 我们介绍一种插入、删除和触发执行都是 0G)的方法,由计算机科学家“George Varghese”等提出,在 NetBSD(一种操作系统)上实现并蔡代了早期内核中的 callout定时器实现。最原始的时间轮如下图。 一共有 8 个 backet,每个 bucket 代表 tick 的时间,类似于时钟,每个 1 秒钟走一格,我们可以定义 tick的时间为 1 秒钟, 那么 bicket[1]就代表第 1 秒, 而 bucket[8]就代表第 8 秒, 然后循环进行上述步骤。 一个 bucket中可能有多个任务, 每个任务采用链表的方式连接起来.下面通过一个例子来说明如何添加、 删除和查找任务。假设时间轮中有 8 个 bucket,每个 bucket 占用一个 tick 时间,每个 tick 为 1 秒。当前有 2 个定时任务 A、B,分别需要 3 秒、11 秒执行一次。目前指针指在 0 的位置,3 秒钟之后指针将指向 bucket[3]的位置,因此我们把任务 A 放入 bucket[3]中,接下来我们再看如何放置任务 B,任务B 是 11 秒之后执行,也就是说时间轮转 1圈之后,再过 3 秒种,任务 B 才执行,那么如何标记任务的圈数呢? 这里引入了 round 的概念,round 为 1 就表示需要 1 圈,如果 round 为 2 则需要 2 圈,同理推广到其它围数。我们把 B 任务也放入 bucket[3],但是设置它的 round 为 1。 我们先看下任务 A 和任务 B 的执行过程,3 秒钟之后时间轮转到 bucket[3],这时候检查bucket[3]中的任务,只执行 round 为 0 的任务,这里执行任务 A,然后把 bucket[3]中所有任务的round减 1,这时候任务 B 的 round 数为0 了,等到时间轮转一圈之后,就会执行任务 B 了。 这里还有一个疑问就是任务 和执行完成之后,下一次人触发如何执行,其实在 bucket[3]执行完成之后,会把任务 A 从 bucket[3]中删除,然后从新计算 3+3,放入 bucket[6]中,等到 bucket[6]执行完成之后,然后再放入(6+3 ) 对 8 取余,放入 bucket[]]中。也就是说每次任务执行完成之后需要重新计算任务在哪个 bucket,然后放入对应的 bucket 中。 可以看到时间轮算法的插入复杂度是 0(1),删除的复杂度也是 O(1),查找执行的复杂度也是 O(1),因此 Cyber 定时器实现 用户接口 Timer 对象是开放给用户的接口,主要实现了定时器的配置“TimerOption”,启动定时器和关闭定时器 3个接口。我们首先看下定时器的配置 。 包括: 定时器周期、回调函数、一次触发还是周期触发〈默认为周期触发) 。 Timer 对象主要的实现都在“Start()”中。 Start 中的步骤很简单: 下面对 Timer 中初始化任务的过程做一些解释。 在 Timer 对象中创建 Task 任务并注册回调“task_->callback”,任务回调中首先会调用用户传入的”callback) ”函数,然后把新的任务放入下一个时间轮 bucket 中,对应到代码就是“TimingWheel::Instance()->AddTask(task)”。 task->next_fire_duration_ms 是任务下一次执行的间隔, 这个间隔是以 task 执行完成之后为起始时间的,因为每次插入新任务到时间轮都是在用户"callback"函数执行之后进行的,因此这里的时间起点也是以这个时间为准。 task->accumulated error_ ns 是累计时间误差,注意这个误差是累计的,而且每次插入任务的时候都会修复这个误差, 因此这个误差不会一直增大,也就是说假设你第一次执行的比较早,那么累计误差为负值,下次执行的时间间隔就会变长,如果第一次执行的时间比较晚,那么累计误差为正值,下次执行的时间间隔就会缩短。通过动态的调节,保持绝对的时间执行间隔一致。 2、TimingWheel 时间轮 接下来看时间轮 Timing Wheel 的实现,TimingWheel 时间轮的配置如下: TimingWheel 是通过ddTask 调用执行的,下面是具体过程。 从上述过程可以看出 Cyber 的时间轮单独采用一个线程调度执行“std::thread(this { this->TickFunc0; )”,定时任务则放入协程池中去执行。也就是说主线程单独执行时间计数,而具体的定时任务开多个协程去执行,可以并发执行多个定时任务:定时任务中最好不要引入阻塞的操作,或者执行时间过长。Cyber 定时器中引入了 2 级时间轮的方法〈消息队列 kafka 中也是类似实现) ,类似时钟的小时指针和分钟指针,当一级时间轮触发完成之后,再移动到二级时间轮中执行。第二级时间轮不能超过一图,因此定时器的最大定时时间为 645122ms,: 最大不超过约 65s。 3、Tick 这里需要注意假设二级时间轮中有一个任务的时间周期就为 312,那么在当前 bucket 回调中又会在当前bucket 中增加一个任务,那么这个任务会执行 2 次,如何解决这个问题呢? Cyber 中采用把这个任务放入上一级时间轮中,然后在触发一个周期之后二放到平一级的时间轮中触发。 一是定时器是否为单线程,任务都是在单线程中的多个协程中执行? 答: 定时器的计数单独在一个线程中执行,具体的定时任务在协程池中执行汪 也就是说多个定时任务可以并发执行。 当“TimingWheel::AddTask”中“work_wheel_index >= WORK_ WHEELSIZE”并且“assistant_ticks 一1”时,假设原始的 current_ work_wheel index_mutex_= 200,消息触发周期为 600 个 tick,那么按照上述计算方法得到的 workswheel_index = 800,real_work wheel index = 288,assistant ticks = 1,那么“work_wheel[real_work_wheel_index].AddTask人(tasb)”会往 288 增加任务,实际上这个任务在 88 个 tick 之后就触发了? 其他模块函数 data_fusion_ data_fusion 总是以第一个消息为基准,查找融合最新的消息。 Transport Transport 把消息通过 DataDispatcher, 把消息放进 buffer 并且触发 DataNotifier:Notify 。notify 之后会触发协程执行,而协程会调用 DataVisitor:TryFetch 去取数据,取到数据之后,调用 process函数执行。 ListenerHandler 和 RtpsDispatcher 是否为通知 signal 接收发送消息,对应一张线性表?RtpsDispatcher 用来分发消息,同时触发 ListenerHandler? Croutine 调度 什么时候采用协程,用协程做了哪些工作?1、scheduler, task 和 croutine如果有一个新的任务需要处理,则调度器会创建一个任务,而任务又由协程去处理。 创建任务的时候DataVisitorBase 在调度器中注册回调,这个回调触发调度器根据任务 id 进行 NotifyProcessor一个任务就是一个协程,协程负责调用 reader enqueue 读取消息,平时处于 yeild 状态,等到 DataVisitor触发回调之后开始工作。 地图模块 地图模块是定位、感知、规划模块的基础,在自动驾驶领域具有特别重要的意义,它是百度等自动驾驶大厂主要的技术壁又,目前高精地图制作相关工具没有公开。 其实我们只需要知道 map 模块的主要功能是“加载 opendriver 格式的地图,并且提供一系列的 API 给其他模块使用”。然后再根据具体的场景来了解地图各个部分的作用,就算是对 map 模块比较了解了。 高精地图制作流程 制作一张高精度地图可以大概分为 4 个过程: 地图采集、点云地图制作、地图标注、地图保存。 采集 如何采集地图? 我们需要一些传感器来获取数据,下面是需要的传感器列表: 点云地图制作 如何加工上述地图? 首先需要生成一张原始的地图, 这里我们采用点云生成原始的地图, 因为点云的距离位置信息比较准确,因为点云数据是 0.1s 采集一帧,下面我们可以做一个计算。如果车速是 100km/h,对应27.8mAs。即 0.1s 车行驶的距离是 2.78m,而激光雷达的扫描距离大概是 150m,所以前后 2 帧大部分地方是重合的。因为数据是一帧一帧的,我们需要把上面说的每一帧进行合并,生成一张完整的地图,有点类似全景昭片拼接,这样我们就可以得到一张原始的采集路段的地图。这里用到了点云的配准技术,有 2 种算法: ICP 和NDT。基于上面的算法,可以把点云的姿态进行变换并且拼接。Autoware NDT mapping 采用开源社区 Autoware 提供的 NDT mapping,可以实现点云的拼接,从而得到整个街道的三维模型。各种离线 SLAM 建图方法,目前可以参考的基于激光雷达的 SLAM 建图方法如下:LOAM (A-LOAM、LeGO-LOAM) 、Cartographer、hdl_graph_slam、blam、LIO-mapping interactive_slam。 地图标注 点云拼接好之后,我们就需要在道路上标出路沿,车道线,红绿灯,路口,一些交通标识等。大部分的工作都可以用深度学习结合图像的方法去解决, 查找出上面的一些信息并且标识出来, 目前有些场景还是需要人工标识出来,比如路口停止线和红绿灯的关系,一些特殊场景的车道线等,需要人工去做一些校正。当前地图标注主要面临以下 2 个挑战。六 传感器融合:由于激光雷达采集的点云数据比较稀玻,并且没有颜色信息, 因此需要把摄像头的信息和激光雷达做融合,之后可以获取更加清晰的信息来识别车道线信息、交通标志信息等。> 自动化标注:采用人工标注的方式无法解决大规模高精度地图制作工作量巨大的问题,如何实现自动化标注是目前地图标注的主要问题。 地图保存 地图保存主要是把上述标注好的信息保存为固定的格式,:目前百度 Apollo 社区采用的高精度地图格式是Opendrive 格式,并且做了一些改进,高精度地图最好采用统一的格式标准。地图服务商对高精度地图做了一部分扩展,把高精度地图分为 3 个图层:1、车道级路网图层,主要用于感知和导航规划主要是对路网精确的三维表征〈厘米级精度) 进行描述,并存储为结构化数据,主要可分为两大类:> ”道路数据;比如路面的几何结构: 车道线类型 (实线/虚线、单线/双线) 、车道线颜色〔和白色、黄色)以及每个车道的〈坡度、曲率、航向高程等) 数据属性等;> 车道周边的固定对象信息: 比如交通标志、交通信号灯等信息、车道限高、下水道口、障碍物以及其他道路细节,还包括高架物体、防护栏数目、道路边缘类型、路边地标等基础设施信息,2、定位图层,主要用于车辆定位该层所包含的元素,取决于自动驾驶汽车打算采用何种传感器来匹配定位图层进行定位, 但目前自动驾驶汽车在定位方面的解决方案差异性较大,比如有基于视觉特征匹配定位方案, 也有基于激光雷达点云特征匹配定位解决方案, 还有基于视觉特征和激光雷达点云特征数据融合的定位方案; 同时定位图层所包含元素还与自动驾驶车辆的应用场景相关; 未来图商有可能会根据不同的场景、不同的传感器生成不同的高精地图的定位图层。3、动态图层,主要是一些实时路况,修路或者封路等需要实时推送或者更新的数据。现阶段对于高精度地图动态图层需要哪些信息要素也还没有定论, 仍处于探讨研究的阶段。 但动态图层包含的内容大致可分为两个方面:实时路况和交通事件例如: 道路拥堵情况、施工情况、是否有交通事故、交通管制情况、天气情况等动态交通信息。由于路网每天都有变化,如整修、道路标识线磨损及重漆、交通标示改变等。这些变化需要及时反映在高精地图上以确保自动驾驶车辆的行驶安全。 hdmap 其实我们只需要知道 map 模块的主要功能是“加载 openstreet 格式的地图, 并且提供一系列的 API 给其他模块使用”。然后再根据具体的场景来了解地图各个部分的作用,就算是对 map 模块比较了解了。 Map 目录结构 本章主要介绍下 apollo 代码的 map 模块,map 的代码目录结构如下: apollo 的高精度地图采用了 opendrive 格式,opendrive 是一个统一的地图标准, 这样保证了地图的通用性。其中 map 模块主要提供的功能是读取高精度地图,并且转换成 apollo 程序中的 Map 对象。直白一点就是说把xml 格式的 opendrive 高精度地图,读到为程序能够识别的格式。 map 模块没有实现的功能是高精度地图的制作。map 模块生成的地图主要有如下几种;pnc_map: 负责解析 routing response,并生产候选 reference lines,其过程是: 首先根据 lane 是否为左/右转lane《〈是: 变道+直行) ,产生若干条候选 road segments,最后再转化为 reference lines,并根据 hdmap 设置覆盖区域。relative_map: 用于没有高精地图, 但是有离线平滑好的 reference line 的场景,并且可通过摄像头检测到未来一部分道路元素信息。将其构造成伪高精地图,供后续决策规划模块使用,常用的如道路边界信息,用于traffic rule 决策使用的覆盖区域信息,如,stop,yield 指示牌,路口等。 地图数据结构 由于 openstreet 格式是一个标准,可以它的参考官方网站。下面主要介绍下 apollo 是如何读取 xml 地图,并且使用的。地图的读取在 adapter 中,其中 xml_parser 目录提供解析 xml 的能力。而"opendrive_adaptercc"则实现了地图的加载,转换为程序中的 Map 对象。然后地图在"hdmap_implcc"中提供一系列 api 接口给其他模块使用。下面先介绍下地图消息格式,主要在 proto 目录。 “map.proto”分为地图头部信息和结构体。头部信息主要介绍了地图的基本信息“版本,时间,投影方法,地图大小,厂家等”。结构体主要是道路的不同组成部分, 包括“人行横道,路口区域,车道,停车观察,信号灯,让路标志,重登区域,禁止停车,减速带,道路,停车区域,路边的小路,或者行人走的路”。 2、地图的道路信息 下面是地图的道路信息,其中有 2 个标志(StopSign,YieldSig器是美国才有的,对应到国内是(停,让),具体的含义都一样: “停车”的意思是到路口先停止,看下有没有车,然后再开始启动,“让车”就是先让行,比如交汇路口,理应让直行的车辆先通过;然后再汇入道路下面再介绍下 overlap。overlap 在注释里的解释是“任何一对在地图上重合的东西,包括〈车道,路口,人行横道) ”,比如路口的人行横道和道路是重合的,还有一些交通标志和道路也是重登的,这是创造的一个逻辑概念。 \1) 人行横道 人行横道消息结构在 map_crosswalk.proto 中描述。 \2) 路口 路口是道路汇聚点,消息结构在文件 map_junction.proto 中描述。 \3) 车道线 车道线,消息结构比较复杂,在 map_lane.proto 中描述。 停止信号消息结构在 map_stop_sign.proto 中描述。 \5) 交通信号标志 交通信号标志消息结构在 map_signal.proto 中描述。 \6) 让行标志 让行标志消息结构在 map_yield_sign.proto 中描述。 \7) 重伏区域 重倒区域消息结构在 map_overlap.proto 中描述。 \8) 禁止停车标志 禁止停车标志消息结构在 map_clear area.proto 中描述。 \9) 减速带标志 减速带标志消息结构在 map_speed_bump.proto 中描述。 \10) 道路信息 道路信息是由一些 RoadSection 组成,消息结构在 map road.proto 中描述。 \11) 停车区域 停车区域消息结构在 map_parking_space.proto 中描述。 \12) 限速标志 限速标志消息结构在 map_speed_control.proto 中描述。 \13) 几何形状 \14) PNC 路口 RSU opendriver 地图解析 由于 opendriver 格式是一个标准,可以参考它的官方网站。下面主要介绍下 apollo 是如何读取 xml 地图,并且使用的。地图的读取在 adapter 中, 其中 xml_parser 目录提供解析 xml 的能力, 比如 junctions_xml_parser.cc中的函数。 然后地图在“hdmap_implcc”中提供一系列 api 接口给其他模块使用。 pnc_mappnc map 全称是 Planning and Control Map,其实和 hd map 没有关系,后者是专门为规划与控制模块设计的库函数。在 hd map 层次之上,负责一些地图相关信息的处理。例如查询车辆可能的形式路由段(isb,然后对每个路由段合成一个路径 Path,这是 pnc map 最重要的功能。pnc map 在参考线提供器 ReferenceLineProvider 中调用,规划控制地图 pnc map 主要的功能有三个:1) 更新路由信息。这部分接受 Routing 模块的路径查询响应,将其响应信息处理存储到地图类中。2) 短期路径段查询。根据 Routing 规划路径以及当前车辆的位置,计算当前车辆可行驶的车道区域。3) 路径段生成最终路径。针对 2) 中每个可行驶的车道路由段,生成一条路径 Path,可以后续生成参考线 Reference Line。 更新路由信息 〈PncMap: :UpdateRoutingResponse)更新路由信息的函数原型为;bool PncMap: :UpdateRoutingResponse(const routing: :RoutingResponse &routing)从参数可以看到宇更新阶段其实是将路径查询的响应结果进行初步的剥离,剥离出查询点(routing.routing_request().waypoint()) 以及对应的查询结果 routing.road()) 。下面我们从代码入手,对更新路由信息阶段进行分析。从代码的功能性上分析, 我们将这个阶段的内容分为两个流程: 响应结果的剥离与查询点处理。 1、响应结果和剥离 从上述代码可以看出,响应结果和剥离工作比较简单,就是对这条完整路径进行 RoadSegment,Passage,LaneSegment 的存储,如下图所示: 查询点处理 从上述图中可以看到,该次查询的查询点 waypoint 二共两个,起点(红色星星)和终点(蓝色星星)。这一步需要对这两个 waypoint 进行处理,计算这两个waypoint分别在上述的那些 LaneSegment 中,准确的说是上述all lane ids 中每个 LaneSegment 包含有哪些 waypoint 判断是否在对应的 LaneSegment 中的代码为: 从代码中可以看到,waypoint 在 lane_segment 中需要满足条件: ”waypoint 和 lane_segment 的所在的车道 lane 的id 必须一致 ”waypoint 的累计距离 s 必须在 lane_segment 的 start_ s 和 end_s之间。 短期路径段查询 (PncMap: :GetRouteSegments) 查询路径的目的其实与 Prediction 模块的 Obstacle 的 LaneGraph 的 LaneSequence 生成是一样的。Planning模块的短期路径查询是根据当前主车的位置,去查询无人驾驶汽车可以行使的车道段Passage &义LaneSegment)。而后者是为预测障碍物的运动轨迹(LaneSequence)。在这个查询阶段,必须要保证已经存在RoutingeResponse,所以在 PncMap::GetRouteSegments 函数运行时,必须保证在之前已经更新过路由信息了PncMap::UpdateRoutingResponse。短期路径查询的函数原型为: 这是 pnc map 最重要的功能,从函数参数分析,我们可以看到 GetRouteSegments 接受的参数最主要的是车辆的状态(包含车辆的位置,偏航角,速度,加速度等信息),backward_length 和 forward_length 是短期路径生成过程中前向与后向修正距离,目前暂时不用考虑。而返回的是短期内(注意是短期内,长期调度不确定因素太多,无法实现)车辆的运动轨迹 route_segments,这是 std::list 类型的,与 LaneGraph::LineSequence 类似,每个元素都是代表当前车辆的一种运动方案。那么存在如下问题: 1、更新 pnc map 中无人车状态 这部分由 UpdateVehicleState 函数完成,这个函数完成的工作就是计算上图中的红色部分: 包括 由于代码量比较多,而且代码难度不高,所以 GetNearestPointFromRouting 函数就不贴代码,这里描述一下函数计算的流程: 举例1 假设有以下这个情况: 车辆行驶到了 LaneSegment k,并且经过了 wp0。 |–wp0--------------------vp---------|--------wp1-------wp2------------wp3-------|--------------------------------wp4------| \ LaneSegment k /\ LaneSegment k+1 /\ LaneSegment k+2 /\ 其中 wp 为当前车辆在 LaneSegment 中的投影,wp0, wpl, wp2, wp3 分别是路径查询的 4 个 waypoint(必须经过的点。现在我们要查询车辆下一个最近的必经点 waypoint,那么结果应该是 wpl! 假设车辆当前是前进状态,cur_index 值为k,那么; 可以判断,函数执行前,next_routing_waypoint_index_值为 0查询 wp0 时得到)。第1 步,查找最近包含有 waypoint 的 LaneSegment,最终得到的结果 next_routing_waypoint_index_仍然为0,因为 routing_waypoint_index_[next_routing_waypoint_index_].,index 就是 wp0.index,值为k,与 cur_index 相等。第 2 步,查找下一个最近的 waypoint 对应的索引 ,next_routing_ waypoint index_变为 1,因为adc_waypoint .s >= wp0.s。举例2假设有以下这个情况: 车辆行驶到了 LaneSegment k+t2,并且经过了 wp1,wp2 和 wp3。 |–wp0-----------------------------|--------wp1-------wp2------------wp3-------|----------vp----------------------wp4------| \ LaneSegment k /\ LaneSegment k+1 /\ LaneSegment k+2 /\ 其中 wp 为当前车辆在 LaneSegment 中的投影,wp0, wpl, wp2, wp3 分别是路径查询的 4 个 waypoint(必须经过的点),其中 wp0,wp1,wp2 和 wp3 已经经过了,wp4 待车辆经过。现在我们要查询车辆下一个最近的必有经点 waypoint,那么结果应该是 wp4! 假设车辆当前是前进状态,cur_index 值为 kt2,那么: 可以判断,函数执行前,next_routing_waypoint_index 值为 3(查询 wp3 时得到) 第 1 步, 查找最近包含有 waypoint 的 LaneSegment,最终得到的结果 next_routing_waypoint_index_变为 4,因为 routing_waypoint_index_[next_routing_waypoint_index_].index 就是 wp3.index,值为 kr1,, wp3.index < cur_ index。 第 2 步,查找下一个最近的 waypoint 对应的索引,next_routing_waypoint_ index_仍然为4,因为adc_waypoint .sS< wp4.s2. 计算临近通道在上一步更新车辆状态中,根据路由查询响应以及车辆状态可以得到当前车辆在规划路径中的位置adc_waypoint ,以及下一个必经查询点的索引 next_routing_waypoint_index_。接下来这一步就是查询当前位置下,附近的通道。这部分功能由函数 GetNeighborPassages 实现。 代码实现比较容易看章,这里我们简单地总结一下获取邻接可驶入通道的原则: \3) 如果下一个路径查询点(routing_waypoint_index_[next_routing_waypoint_index_].waypoinb)在当前通道中,不需要变道,直接返回车辆所在的车道。 // 查询当前 Roadsegment 中所有 Passage: :LaneSegment 的所属车道,有交集就添加到结果中 3、创建车辆当前可行驶区域 在上一步中, 我们找到了当前车辆在规划轨迹中的邻接车道。这一步就对每个邻接车道做一个是否可驶入的检查,并做道路段截取。也就是制定出无人车在当前情况下可能行驶的区域,每个可行驶通道将划分出一个道路区间,上面已经提到过,道路区间的长度由前向查询距离 forward_length 和后向查询距离 backward_length决定,短期内规划的可行驶道路段长度为 forward length+backward_ lcigth。最终的路由段 RouteSegments 生成只需要对每个邻接可驶入的通道进行 Segments 生成即可。Passage 生成对应的 RouteSegments 分为 4 个步骤,分别为;Step1: 将当前车辆的坐标投影到 Passage这部分是比较常见的,也是辫前模块反反复复计算的,直接贴源码: Step2:检查 Passage 是否可驶入explicit ParameterService(const std::shared_ptr<Node>& node);
void SetParameter(const Parameter& parameter);
bool GetParameter(const std::string& param_name,Parameter* parameter);
ParameterClient(const std::shared_ptr<Node>& node,const std::string& service_node_name);
#include "Cyber/cyber.h"
#include "cyber/parameter/parameter_client.h"
#include "cyber/parameter/parameter_service.h"
using apollo::cyber::Parameter;
using apollo::cyber::ParameterServer;
using apollo::cyber::ParameterClient;
int main(int argc,char **argv)
{
apollo::cyber::Init(*argv);
std::shared_ptr<apollo::cyber::Node> node = apollo::cyber::CreateNode("parameter");
auto param_server = std::make_shared<ParameterServer>(node);
auto param_client = std::make_shared<ParameterClient>(node,"parameter");
param_server->setParameter(Parameter("int",1));
Parameter parameter;
param_server->GetParameter("int",¶meter);
AINFO<<"int:"<<parameter.AsInt64();
param_client->SetParameter(Parameter("string","test"));
param_client->GetParameter("string",¶meter);
AINFO<<"string:"<<parameter.AsString();
param_client->GetParameter("int",¶meter);
AINFO<<"int: "<<parameter.AsInt64();
return 0;
}
enum class RoutineState{READY,FINISHED,SLEEP,IO_WAIT,DATA_WAIT}
class CRoutine
{
public:
explicit CRoutine(const RoutineFunc &func);
virtual ~CRoutine();
// static interfaces
static void Yield();
static void Yield(const RoutineState &state);
static void SetMainContext(const std::shared_ptr<RoutineContext> &context);
static CRoutine *GetCurrentRoutine();
static char **GetMainStack();
// public interfaces
bool Acquire();
void Release();
// It is caller's responsibility to check if state_ is valid before calling
// SetUpdateFlag().
void SetUpdateFlag();
// acquire && release should be called before Resume
// when work-steal like mechanism used
RoutineState Resume();
RoutineState UpdateState();
RoutineContext *GetContext();
char **GetStack();
void Run();
void Stop();
void Wake();
void HangUp();
void Sleep(const Duration &sleep_duration);
// getter and setter
RoutineState state() const;
void set_state(const RoutineState &state);
uint64_t id() const;
void set_id(uint64_t id);
const std::string &name() const;
void set_name(const std::string &name);
int processor_id() const;
void set_processor_id(int processor_id);
uint32_t priority() const;
void set_priority(uint32_t priority);
std::chrono::steady_clock::time_point wake_time() const;
void set_group_name(const std::string &group_name)
{
group_name_ = group_name;
}
const std::string &group_name() { return group_name_; }
private:
CRoutine(CRoutine &) = delete;
CRoutine &operator=(CRoutine &) = delete;
std::string name_;
std::chrono::steady_clock::time_point wake_time_ =
std::chrono::steady_clock::now();
RoutineFunc func_;
RoutineState state_;
std::shared_ptr<RoutineContext> context_;
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
std::atomic_flag updated_ = ATOMIC_FLAG_INIT;
bool force_stop_ = false;
int processor_id_ = -1;
uint32_t priority_ = 0;
uint64_t id_ = 0;
std::string group_name_;
static thread_local CRoutine *current_routine_;
static thread_local char *main_stack_;
};
void Processor::BindContext(const std::shared_ptr<ProcessorContext> &context)
{
context_ = context;
std::call_once(thread_flag_,
[this]() { thread_ = std::thread(&Processor::Run, this); });
}
void Processor::Run()
{
tid_.store(static_cast<int>(syscall(SYS_gettid)));
AINFO << "processor_tid: " << tid_;
snap_shot_->processor_id.store(tid_);
while (cyber_likely(running_.load()))
{
if (cyber_likely(context_ != nullptr))
{
auto croutine = context_->NextRoutine();
if (croutine)
{
snap_shot_->execute_start_time.store(cyber::Time::Now().ToNanosecond());
snap_shot_->routine_name = croutine->name();
croutine->Resume();
croutine->Release();
}
else
{
snap_shot_->execute_start_time.store(0);
context_->Wait();
}
}
else
{
std::unique_lock<std::mutex> lk(mtx_ctx_);
cv_ctx_.wait_for(lk, std::chrono::milliseconds(10));
}
}
}
scheduler_conf {
policy: "classic"
process_level_cpuset: "0-7,16-23" # all threads in the process are on the cpuset
threads: [
{
name: "async_log"
cpuset: "1"
policy: "SCHED_OTHER" # policy: SCHED_OTHER,SCHED_RR,SCHED_FIFO
prio: 0
}, {
name: "shm"
cpuset: "2"
policy: "SCHED_FIFO"
prio: 10
}
]
classic_conf {
groups: [
{
name: "group1"
processor_num: 16
affinity: "range"
cpuset: "0-7,16-23"
processor_policy: "SCHED_OTHER" # policy: SCHED_OTHER,SCHED_RR,SCHED_FIFO
processor_prio: 0
tasks: [
{
name: "E"
prio: 0
}
]
},{
name: "group2"
processor_num: 16
affinity: "1to1"
cpuset: "8-15,24-31"
processor_policy: "SCHED_OTHER"
processor_prio: 0
tasks: [
{
name: "A"
prio: 0
},{
name: "B"
prio: 1
},{
name: "C"
prio: 2
},{
name: "D"
prio: 3
}
]
}
]
}
}
void SchedulerClassic::CreateProcessor()
{
// 读取调度配置文件,参照 conf 目录
for (auto &group : classic_conf_.groups())
{
// 1. 分组名称
auto &group_name = group.name();
// 2. 分组执行器(线程)数量 等于协程池大小
auto proc_num = group.processor_num();
if (task_pool_size_ == 0)
{
task_pool_size_ = proc_num;
}
//3. 分组CPU 亲和xin
auto &affinity = group.affinity();
//4. 分组线程调度策略
auto &processor_policy = group.processor_policy();
//5. 分组优先级
auto processor_prio = group.processor_prio();
//6. 分组 cpu set
std::vector<int> cpuset;
ParseCpuset(group.cpuset(), &cpuset);
for (uint32_t i = 0; i < proc_num; i++)
{
auto ctx = std::make_shared<ClassicContext>(group_name);
pctxs_.emplace_back(ctx);
auto proc = std::make_shared<Processor>();
//绑定上下文
proc->BindContext(ctx);
//设置线程的cpuset 和 cpu 亲和人性
SetSchedAffinity(proc->Thread(), cpuset, affinity, i);
// 设置线程调度策略和优先级 (proc->Tid( )为线程 pid)
SetSchedPolicy(proc->Thread(), processor_policy, processor_prio,
proc->Tid());
processors_.emplace_back(proc);
}
}
}
bool Scheduler::CreateTask(std::function<void()> &&func,
const std::string &name,
std::shared_ptr<DataVisitorBase> visitor)
{
if (cyber_unlikely(stop_.load()))
{
ADEBUG << "scheduler is stoped, cannot create task!";
return false;
}
auto task_id = GlobalData::RegisterTaskName(name);
//创建协程,绑定 fanc 函数
auto cr = std::make_shared<CRoutine>(func);
cr->set_id(task_id);
cr->set_name(name);
AINFO << "create croutine: " << name;
//分发任务
if (!DispatchTask(cr))
{
return false;
}
if (visitor != nullptr)
{
visitor->RegisterNotifyCallback([this, task_id]()
{
if (cyber_unlikely(stop_.load()))
{
return;
}
this->NotifyProcessor(task_id);
});
}
return true;
}
1、创建任务的时候只有对应数据访问的 DataVisitorBase 注册了回调,其它的任务要自己触发回调。
2、DispatchTask 中调用子类中的不同策略进行任务分发。
接着我们看 SchedulerClassic 的 DispatchTask 调度策略。bool SchedulerClassic::DispatchTask(const std::shared_ptr<CRoutine> &cr)
{
// we use multi-key mutex to prevent race condition
// when del && add cr with same crid
//1 根据协程 1d,获取协程的锁
MutexWrapper *wrapper = nullptr;
if (!id_map_mutex_.Get(cr->id(), &wrapper))
{
{
std::lock_guard<std::mutex> wl_lg(cr_wl_mtx_);
if (!id_map_mutex_.Get(cr->id(), &wrapper))
{
wrapper = new MutexWrapper();
id_map_mutex_.Set(cr->id(), wrapper);
}
}
}
std::lock_guard<std::mutex> lg(wrapper->Mutex());
// 2将协程放入扫程 map
{
WriteLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(cr->id()) != id_cr_.end())
{
return false;
}
id_cr_[cr->id()] = cr;
}
//设置协程的优先级和 group
if (cr_confs_.find(cr->name()) != cr_confs_.end())
{
ClassicTask task = cr_confs_[cr->name()];
cr->set_priority(task.prio());
cr->set_group_name(task.group_name());
}
else
{
// croutine that not exist in conf
cr->set_group_name(classic_conf_.groups(0).name());
}
if (cr->priority() >= MAX_PRIO)
{
AWARN << cr->name() << " prio is greater than MAX_PRIO[ << " << MAX_PRIO
<< "].";
cr->set_priority(MAX_PRIO - 1);
}
//将协程放入对应的优先级队列
// Enqueue task.
{
WriteLockGuard<AtomicRWLock> lk(
ClassicContext::rq_locks_[cr->group_name()].at(cr->priority()));
ClassicContext::cr_group_[cr->group_name()]
.at(cr->priority())
.emplace_back(cr);
}
//聊醒协程组
ClassicContext::Notify(cr->group_name());
return true;
}
bool SchedulerClassic::NotifyProcessor(uint64_t crid)
{
if (cyber_unlikely(stop_))
{
return true;
}
{
ReadLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(crid) != id_cr_.end())
{
auto cr = id_cr_[crid];
if (cr->state() == RoutineState::DATA_WAIT ||
cr->state() == RoutineState::IO_WAIT)
{
cr->SetUpdateFlag();
}
ClassicContext::Notify(cr->group_name());
return true;
}
}
return false;
}
std::shared_ptr<CRoutine> ClassicContext::NextRoutine()
{
if (cyber_unlikely(stop_.load()))
{
return nullptr;
}
// 1, 从优先级最高的队列开始遍历
for (int i = MAX_PRIO - 1; i >= 0; --i)
{
//获取当前优先级队列的锁
ReadLockGuard<AtomicRWLock> lk(lq_->at(i));
for (auto &cr : multi_pri_rq_->at(i))
{
if (!cr->Acquire())
{
continue;
}
//返回状态就绪的协程
if (cr->UpdateState() == RoutineState::READY)
{
return cr;
}
cr->Release();
}
}
return nullptr;
}
1、通过调用 sleep(millseconds)使任务进入休眼状态
2、通过调用 wait () 使线程挂起
3、等待某个输入、输出流
4、等待锁
而 Processor 绑定的线程阻塞是通过上下文的等待实现的。在 ClassicContext 中等待条件 (1s 的超时时间),
等待的时候设置 notify_grp 减 1。void ClassicContext::Wait()
{
//获取锁
std::unique_lock<std::mutex> lk(mtx_wrapper_->Mutex());
//等待条件大于0
cw_->Cv().wait_for(lk, std::chrono::milliseconds(1000),
[&]() { return notify_grp_[current_grp] > 0; });
if (notify_grp_[current_grp] > 0)
{
notify_grp_[current_grp]--;
}
}
SchedulerChoreography 创建 Processor,会分 2 部分创建: 一部分是有本地队列的 Processor,一部分是协程池的 Processor。void SchedulerChoreography::CreateProcessor()
{
for (uint32_t i = 0; i < proc_num_; i++)
{
auto proc = std::make_shared<Processor>();
//1. 绑定 ChoreographyContext
auto ctx = std::make_shared<ChoreographyContext>();
proc->BindContext(ctx);
SetSchedAffinity(proc->Thread(), choreography_cpuset_,
choreography_affinity_, i);
SetSchedPolicy(proc->Thread(), choreography_processor_policy_,
choreography_processor_prio_, proc->Tid());
pctxs_.emplace_back(ctx);
processors_.emplace_back(proc);
}
for (uint32_t i = 0; i < task_pool_size_; i++)
{
auto proc = std::make_shared<Processor>();
auto ctx = std::make_shared<ClassicContext>();
//2. 绑定ClassicContext
proc->BindContext(ctx);
SetSchedAffinity(proc->Thread(), pool_cpuset_, pool_affinity_, i);
SetSchedPolicy(proc->Thread(), pool_processor_policy_, pool_processor_prio_,
proc->Tid());
pctxs_.emplace_back(ctx);
processors_.emplace_back(proc);
}
}
bool SchedulerChoreography::DispatchTask(const std::shared_ptr<CRoutine> &cr)
{
// we use multi-key mutex to prevent race condition
// when del && add cr with same crid
MutexWrapper *wrapper = nullptr;
//根据抄程 id,获芭协程的锁
if (!id_map_mutex_.Get(cr->id(), &wrapper))
{
{
std::lock_guard<std::mutex> wl_lg(cr_wl_mtx_);
if (!id_map_mutex_.Get(cr->id(), &wrapper))
{
wrapper = new MutexWrapper();
id_map_mutex_.Set(cr->id(), wrapper);
}
}
}
std::lock_guard<std::mutex> lg(wrapper->Mutex());
// Assign sched cfg to tasks according to configuration.
// 2. 设置优先级和协程绑定的 Processor Id
if (cr_confs_.find(cr->name()) != cr_confs_.end())
{
ChoreographyTask taskconf = cr_confs_[cr->name()];
cr->set_priority(taskconf.prio());
if (taskconf.has_processor())
{
cr->set_processor_id(taskconf.processor());
}
}
{
WriteLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(cr->id()) != id_cr_.end())
{
return false;
}
id_cr_[cr->id()] = cr;
}
// Enqueue task.
uint32_t pid = cr->processor_id();
//3. 如果 Processor Id 小于 proc_num_,默认 Processor Id 为-1
if (pid < proc_num_)
{
// Enqueue task to Choreo Policy.
//协程放入上下文本地队列中
static_cast<ChoreographyContext *>(pctxs_[pid].get())->Enqueue(cr);
}
else
{
// Check if task prio is reasonable.
if (cr->priority() >= MAX_PRIO)
{
AWARN << cr->name() << " prio great than MAX_PRIO.";
cr->set_priority(MAX_PRIO - 1);
}
cr->set_group_name(DEFAULT_GROUP_NAME);
// Enqueue task to pool runqueue.
//协程放入 ClassicContext 协程池队列中
{
WriteLockGuard<AtomicRWLock> lk(
ClassicContext::rq_locks_[DEFAULT_GROUP_NAME].at(cr->priority()));
ClassicContext::cr_group_[DEFAULT_GROUP_NAME]
.at(cr->priority())
.emplace_back(cr);
}
}
return true;
}
std::shared_ptr<CRoutine> ChoreographyContext::NextRoutine()
{
if (cyber_unlikely(stop_.load()))
{
return nullptr;
}
ReadLockGuard<AtomicRWLock> lock(rq_lk_);
for (auto it : cr_queue_)
{
auto cr = it.second;
if (!cr->Acquire())
{
continue;
}
if (cr->UpdateState() == RoutineState::READY)
{
return cr;
}
cr->Release();
}
return nullptr;
}
template <typename F, typename... Args>
static auto Async(F &&f, Args &&... args)
-> std::future<typename std::result_of<F(Args...)>::type>
{
return GlobalData::Instance()->IsRealityMode()
? TaskManager::Instance()->Enqueue(std::forward<F>(f),
std::forward<Args>(args)...)
: std::async(
std::launch::async,
std::bind(std::forward<F>(f), std::forward<Args>(args)...));
}
TaskManager::TaskManager()
//1. 设置有界队列,长度为1000
: task_queue_size_(1000),
task_queue_(new base::BoundedQueue<std::function<void()>>())
{
if (!task_queue_->Init(task_queue_size_, new base::BlockWaitStrategy()))
{
AERROR << "Task queue init failed";
throw std::runtime_error("Task queue init failed");
}
// 2. 协程任务,每次从队列中取任务执行,如果没有任务则让出协程,等待数据
auto func = [this]()
{
while (!stop_)
{
std::function<void()> task;
if (!task_queue_->Dequeue(&task))
{
auto routine = croutine::CRoutine::GetCurrentRoutine();
routine->HangUp();
continue;
}
task();
}
};
num_threads_ = scheduler::Instance()->TaskPoolSize();
auto factory = croutine::CreateRoutineFactory(std::move(func));
tasks_.reserve(num_threads_);
// 3. 创建TaskPoolsize 个任务并且放入调度器
for (uint32_t i = 0; i < num_threads_; i++)
{
auto task_name = task_prefix + std::to_string(i);
tasks_.push_back(common::GlobalData::RegisterTaskName(task_name));
if (!scheduler::Instance()->CreateTask(factory, task_name))
{
AERROR << "CreateTask failed:" << task_name;
}
}
}
2、task_queue 会被多个协程访问,并发数据访问这里没有加锁,需要看下这个队列是如何实现的?
3、上述的任务可以在“conf”文件中设置“/intermnal/task + index”的优先级来实现。 template <typename F, typename... Args>
auto Enqueue(F &&func, Args &&... args)
-> std::future<typename std::result_of<F(Args...)>::type>
{
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(func), std::forward<Args>(args)...));
if (!stop_.load())
{
task_queue_->Enqueue([task]() { (*task)(); });
for (auto &task : tasks_)
{
scheduler::Instance()->NotifyTask(task);
}
}
std::future<return_type> res(task->get_future());
return res;
}
SysMo::SysMo() { Start(); }void SysMo::Start(){ auto sysmo_start = GetEnv("sysmo_start"); if (sysmo_start != "" && std::stoi(sysmo_start)) { start_ = true; sysmo_ = std::thread(&SysMo::Checker, this); }}
void SysMo::Checker()
{
while (cyber_unlikely(!shut_down_.load()))
{
scheduler::Instance()->CheckSchedStatus();
std::unique_lock<std::mutex> lk(lk_);
cv_.wait_for(lk, std::chrono::milliseconds(sysmo_interval_ms_));
}
}
void Scheduler::CheckSchedStatus()
{
std::string snap_info;
auto now = Time::Now().ToNanosecond();
for (auto processor : processors_)
{
auto snap = processor->ProcSnapshot();
if (snap->execute_start_time.load())
{
auto execute_time = (now - snap->execute_start_time.load()) / 1000000;
snap_info.append(std::to_string(snap->processor_id.load()))
.append(":")
.append(snap->routine_name)
.append(":")
.append(std::to_string(execute_time));
}
else
{
snap_info.append(std::to_string(snap->processor_id.load()))
.append(":idle");
}
snap_info.append(", ");
}
snap_info.append("timestamp: ").append(std::to_string(now));
AINFO << snap_info;
snap_info.clear();
}




时间轮实现的定时器非常高效。 TimerOption(uint32_t period, std::function<void()> callback, bool oneshot)
: period(period), callback(callback), oneshot(oneshot) {}
void Timer::Start()
{
// 1. 首先判断定时器是否已经启动
if (!common::GlobalData::Instance()->IsRealityMode())
{
return;
}
// 2. 初始化任务
if (!started_.exchange(true))
{
if (InitTimerTask())
{
// 3. 在时间轮中增加任务
timing_wheel_->AddTask(task_);
AINFO << "start timer [" << task_->timer_id_ << "]";
}
}
}
那么初始化任务中做了哪些事情呢?bool Timer::InitTimerTask()
{
// 1. 初始化定时任务
if (timer_opt_.period == 0)
{
AERROR << "Max interval must great than 0";
return false;
}
// 2. 是否单次触发
if (timer_opt_.period >= TIMER_MAX_INTERVAL_MS)
{
AERROR << "Max interval must less than " << TIMER_MAX_INTERVAL_MS;
return false;
}
task_.reset(new TimerTask(timer_id_));
task_->interval_ms = timer_opt_.period;
task_->next_fire_duration_ms = task_->interval_ms;
if (timer_opt_.oneshot)
{
std::weak_ptr<TimerTask> task_weak_ptr = task_;
// 注册任务回调
task_->callback = [callback = this->timer_opt_.callback, task_weak_ptr]()
{
auto task = task_weak_ptr.lock();
if (task)
{
std::lock_guard<std::mutex> lg(task->mutex);
callback();
}
};
}
else
{
std::weak_ptr<TimerTask> task_weak_ptr = task_;
//注册任务回调
task_->callback = [callback = this->timer_opt_.callback, task_weak_ptr]()
{
auto task = task_weak_ptr.lock();
if (!task)
{
return;
}
std::lock_guard<std::mutex> lg(task->mutex);
auto start = Time::MonoTime().ToNanosecond();
callback();
auto end = Time::MonoTime().ToNanosecond();
uint64_t execute_time_ns = end - start;
uint64_t execute_time_ms =
#if defined(__aarch64__)
::llround(static_cast<double>(execute_time_ns) / 1e6);
#else
std::llround(static_cast<double>(execute_time_ns) / 1e6);
#endif
if (task->last_execute_time_ns == 0)
{
task->last_execute_time_ns = start;
}
else
{
//1 start - task->last_execute_time_ns 为 2 次执行真实间隔时间,task->interval_ms 是设定的间隔时间
// 注意误差会修复补偿,因此这里用的是累计,2 次误差会抵消,保持绝对误差为
task->accumulated_error_ns +=
start - task->last_execute_time_ns - task->interval_ms * 1000000;
}
ADEBUG << "start: " << start << "\t last: " << task->last_execute_time_ns
<< "\t execut time:" << execute_time_ms
<< "\t accumulated_error_ns: " << task->accumulated_error_ns;
task->last_execute_time_ns = start;
//如果执行时间大于任务周期时间,则下一个 tick 马上执行
if (execute_time_ms >= task->interval_ms)
{
这里会补偿误差
task->next_fire_duration_ms = TIMER_RESOLUTION_MS;
}
else
{
#if defined(__aarch64__)
int64_t accumulated_error_ms = ::llround(
#else
int64_t accumulated_error_ms = std::llround(
#endif
static_cast<double>(task->accumulated_error_ns) / 1e6);
if (static_cast<int64_t>(task->interval_ms - execute_time_ms -
TIMER_RESOLUTION_MS) >= accumulated_error_ms)
{
task->next_fire_duration_ms =
task->interval_ms - execute_time_ms - accumulated_error_ms;
}
else
{
task->next_fire_duration_ms = TIMER_RESOLUTION_MS;
}
ADEBUG << "error ms: " << accumulated_error_ms
<< " execute time: " << execute_time_ms
<< " next fire: " << task->next_fire_duration_ms
<< " error ns: " << task->accumulated_error_ns;
}
TimingWheel::Instance()->AddTask(task);
};
}
return true;
}

512 个 bucket
64个round
tick 为 2ms
void TimingWheel::AddTask(const std::shared_ptr<TimerTask> &task,
const uint64_t current_work_wheel_index)
{
//不是运行状态则启动时间轮
if (!running_)
{
//启动 Tick 线程,并且加入 scheduler 调度。
Start();
}
// 3. 计算一下轮 bucket 编号
auto work_wheel_index = current_work_wheel_index +
static_cast<uint64_t>(std::ceil(
static_cast<double>(task->next_fire_duration_ms) /
TIMER_RESOLUTION_MS));
// 4. 如果超过最大的 bucket 数
if (work_wheel_index >= WORK_WHEEL_SIZE)
{
auto real_work_wheel_index = GetWorkWheelIndex(work_wheel_index);
task->remainder_interval_ms = real_work_wheel_index;
auto assistant_ticks = work_wheel_index / WORK_WHEEL_SIZE;
// 5.疑问,如果转了一圈之后,为什么直接加入剩余的 bucket?
if (assistant_ticks == 1 &&
real_work_wheel_index < current_work_wheel_index_)
{
work_wheel_[real_work_wheel_index].AddTask(task);
ADEBUG << "add task to work wheel. index :" << real_work_wheel_index;
}
else
{
auto assistant_wheel_index = 0;
{
//6.如果超出,则放入上一级时间轮中
std::lock_guard<std::mutex> lock(current_assistant_wheel_index_mutex_);
assistant_wheel_index = GetAssistantWheelIndex(
current_assistant_wheel_index_ + assistant_ticks);
assistant_wheel_[assistant_wheel_index].AddTask(task);
}
ADEBUG << "add task to assistant wheel. index : "
<< assistant_wheel_index;
}
}
else
{
work_wheel_[work_wheel_index].AddTask(task);
ADEBUG << "add task [" << task->timer_id_
<< "] to work wheel. index :" << work_wheel_index;
}
}
接下来我们看下时间轮中的 Tick 是如何工作的。在上述“AddTask”中会调用“Start” 函数启动一个线程,线程执行“TickFunc”。void TimingWheel::TickFunc(){ Rate rate(TIMER_RESOLUTION_MS * 1000000); // ms to ns while (running_) { Tick(); // AINFO_EVERY(1000) << "Tick " << TickCount(); tick_count_++; rate.Sleep(); { std::lock_guard
经过上述分析,介绍了 Cyber 中定时器的实现原理,这里还有 2 个疑问。
lidar、摄像头、gnss、imu。
1 lidar 主要是来采集点云数据,因为激光雷达可以精确的反应出位置信息,所以激光雷达可以知道路面的宽度,红绿灯的高度,以及一些其他的信息,当然现在也有厂家基于视觉 SLAM 〈纯摄像头测距) 来制作地图的,有兴趣的也可以看下相关介绍。
2 ”摄像头主要是来采集一些路面的标志,车道线等,因为图像的像素信息更多,而位置信息不太精确,所以采用摄像头来识别车道线,路面的一些标志等。
3 gsgnss 记录了车辆的位置信息,记录了当前采集点的坐标。
4 imu 用来捕获车辆的角度和加速度信息,用来校正车辆的位置和角度。
用 apollo 的录制 bag 功能,可以把传感器的数据都录制下来,提供生成高精地图的原始数据。其实在录制
数据之前,需要对上面所说的传感器进行标定工作, 这部分的工作比较专业,涉及到坐标系转换,也涉及到一
些传感器的知识,所以对非专业人士来说不是那么好理解。或者开发一系列工具来实现标定。
采集过程中需要多次采集来保证采集的数据比较完整,比如你在路口的时候, 从不同的角度开车过去看到
的建筑物的轮廓是不二样的,这些轮廓就是激光雷达扫描到的数据。所以遇到路口,或者多车道的情况,尽可能的多采集几次,才能收集到比较完整的地图信息。并且速度不要太快,apollo 上的介绍是不超过 60km/h 〈这里没有特别说明会出现什么问题) 。5.1.2 点云地图制作如何加工上述地图? 首先需要生成一张原始的地图, 这里我们采用点云生成原始的地图, 因为点云的距离位置信息比较准确,因为点云数据是 0.1s 采集一帧,下面我们可以做一个计算。如果车速是 100km/h,对应27.8mAs。即 0.1s 车行驶的距离是 2.78m,而激光雷达的扫描距离大概是 150m,所以前后 2 帧大部分地方是重合的。因为数据是一帧一帧的,我们需要把上面说的每一帧进行合并,生成一张完整的地图,有点类似全景昭片拼接,这样我们就可以得到一张原始的采集路段的地图。这里用到了点云的配准技术,有 2 种算法: ICP 和NDT。基于上面的算法,可以把点云的姿态进行变换并且拼接。Autoware NDT mapping 采用开源社区 Autoware 提供的 NDT mapping,可以实现点云的拼接,从而得到整个街道的三维模型。各种离线 SLAM 建图方法,目前可以参考的基于激光雷达的 SLAM 建图方法如下:LOAM (A-LOAM、LeGO-LOAM) 、Cartographer、hdl_graph_slam、blam、LIO-mapping interactive_slam。xz@xiaqiu:~/study/apollo/modules/map$ tree
.
├── BUILD
├── data //生成好的地图
│ ├── borregas_ave
│ │ ├── base_map.bin
│ │ ├── routing_map.bin
│ │ └── sim_map.bin
│ ├── BUILD
│ ├── demo
│ │ ├── base_map.txt
│ │ ├── default_end_way_point.txt
│ │ ├── garage_routing.pb.txt
│ │ ├── routing_map.txt
│ │ └── sim_map.txt
│ └── README.md
├── hdmap //高精度地图
│ ├── adapter
│ │ ├── BUILD
│ │ ├── coordinate_convert_tool.cc
│ │ ├── coordinate_convert_tool.h
│ │ ├── opendrive_adapter.cc
│ │ ├── opendrive_adapter.h
│ │ ├── proto_organizer.cc
│ │ ├── proto_organizer.h
│ │ └── xml_parser //从xml文件读取地图(openstreet 保存格式为 xml)
│ │ ├── BUILD
│ │ ├── common_define.h
│ │ ├── header_xml_parser.cc
│ │ ├── header_xml_parser.h
│ │ ├── junctions_xml_parser.cc
│ │ ├── junctions_xml_parser.h
│ │ ├── lanes_xml_parser.cc
│ │ ├── lanes_xml_parser.h
│ │ ├── objects_xml_parser.cc
│ │ ├── objects_xml_parser.h
│ │ ├── roads_xml_parser.cc
│ │ ├── roads_xml_parser.h
│ │ ├── signals_xml_parser.cc
│ │ ├── signals_xml_parser.h
│ │ ├── status.h
│ │ ├── util_xml_parser.cc
│ │ └── util_xml_parser.h
│ ├── BUILD
│ ├── hdmap.cc
│ ├── hdmap_common.cc
│ ├── hdmap_common.h
│ ├── hdmap_common_test.cc
│ ├── hdmap.h
│ ├── hdmap_impl.cc
│ ├── hdmap_impl.h
│ ├── hdmap_impl_test.cc
│ ├── hdmap_util.cc
│ ├── hdmap_util.h
│ ├── hdmap_util_test.cc
│ └── test-data
│ └── base_map.bin
├── pnc_map //给规划控制模块用的地图
│ ├── BUILD
│ ├── cuda_util.cu
│ ├── cuda_util.h
│ ├── cuda_util_test.cc
│ ├── path.cc
│ ├── path.h
│ ├── path_test.cc
│ ├── pnc_map.cc
│ ├── pnc_map.h
│ ├── pnc_map_test.cc
│ ├── route_segments.cc
│ ├── route_segments.h
│ ├── route_segments_test.cc
│ └── testdata
│ └── sample_sunnyvale_loop_routing.pb.txt
├── proto //地图各元素的消息格式(人行横道,车道线等)
│ ├── BUILD
│ ├── map_clear_area.proto
│ ├── map_crosswalk.proto
│ ├── map_geometry.proto
│ ├── map_id.proto
│ ├── map_junction.proto
│ ├── map_lane.proto
│ ├── map_overlap.proto
│ ├── map_parking_space.proto
│ ├── map_pnc_junction.proto
│ ├── map.proto
│ ├── map_road.proto
│ ├── map_rsu.proto
│ ├── map_signal.proto
│ ├── map_speed_bump.proto
│ ├── map_speed_control.proto
│ ├── map_stop_sign.proto
│ └── map_yield_sign.proto
├── relative_map // 相对地图
│ ├── BUILD
│ ├── common
│ │ ├── BUILD
│ │ ├── relative_map_gflags.cc
│ │ └── relative_map_gflags.h
│ ├── conf
│ │ ├── navigator_config.pb.txt
│ │ ├── relative_map.conf
│ │ └── relative_map_config.pb.txt
│ ├── dag
│ │ └── relative_map.dag
│ ├── launch
│ │ └── relative_map.launch
│ ├── navigation_lane.cc
│ ├── navigation_lane.h
│ ├── navigation_lane_test.cc
│ ├── proto
│ │ ├── BUILD
│ │ ├── navigation.proto
│ │ ├── navigator_config.proto
│ │ └── relative_map_config.proto
│ ├── README.md
│ ├── relative_map.cc
│ ├── relative_map_component.cc
│ ├── relative_map_component.h
│ ├── relative_map.h
│ ├── testdata //测试数据
│ │ └── multi_lane_map
│ │ ├── chassis_info.pb.txt
│ │ ├── left.smoothed
│ │ ├── localization_info.pb.txt
│ │ ├── middle.smoothed
│ │ └── right.smoothed
│ └── tools
│ ├── BUILD
│ ├── navigation_dummy.cc
│ ├── navigator.cc
│ └── navigator.md
├── testdata
│ └── navigation_dummy
│ └── navigation_info.pb.txt
└── tools
├── bin_map_generator.cc
├── BUILD
├── map_datachecker
│ ├── client
│ │ ├── BUILD
│ │ ├── client_alignment.h
│ │ ├── client.cc
│ │ ├── client_channel_checker.cc
│ │ ├── client_channel_checker.h
│ │ ├── client_common.cc
│ │ ├── client_common.h
│ │ ├── client_gflags.cc
│ │ ├── client_gflags.h
│ │ ├── client.h
│ │ ├── client_loops_check.cc
│ │ ├── client_loops_check.h
│ │ ├── conf
│ │ │ ├── client.yaml
│ │ │ └── state_machine.yaml
│ │ ├── exception_handler.cc
│ │ ├── exception_handler.h
│ │ └── main.cc
│ ├── proto
│ │ ├── BUILD
│ │ ├── collection_check_message.proto
│ │ ├── collection_error_code.proto
│ │ └── collection_service.proto
│ └── server
│ ├── alignment_agent.h
│ ├── alignment.h
│ ├── BUILD
│ ├── channel_verify_agent.cc
│ ├── channel_verify_agent.h
│ ├── channel_verify.cc
│ ├── channel_verify.h
│ ├── common.cc
│ ├── common.h
│ ├── conf
│ │ ├── map-datachecker.conf
│ │ └── map-datachecker.json
│ ├── eight_route.cc
│ ├── eight_route.h
│ ├── laps_checker.cc
│ ├── laps_checker.h
│ ├── loops_verify_agent.cc
│ ├── loops_verify_agent.h
│ ├── main.cc
│ ├── pj_transformer.cc
│ ├── pj_transformer.h
│ ├── pose_collection_agent.cc
│ ├── pose_collection_agent.h
│ ├── pose_collection.cc
│ ├── pose_collection.h
│ ├── static_align.cc
│ ├── static_align.h
│ ├── worker_agent.cc
│ ├── worker_agent.h
│ ├── worker.cc
│ ├── worker_cyber_node.cc
│ ├── worker_cyber_node.h
│ ├── worker_gflags.cc
│ ├── worker_gflags.h
│ └── worker.h
├── map_tool.cc
├── map_xysl.cc
├── proto_map_generator.cc
├── quaternion_euler.cc
├── refresh_default_end_way_point.cc
└── sim_map_generator.cc
28 directories, 174 files
1、地图信息头
首先是地图的基本信息。message Header
{
optional bytes version = 1; //地图版本
optional bytes date = 2;//地图时间
optional Projection projection = 3;//投影方法
optional bytes district = 4;//区
optional bytes generation = 5;
optional bytes rev_major = 6;
optional bytes rev_minor = 7;
optional double left = 8;///左
optional double top = 9;
optional double right = 10;//右
optional double bottom = 11;//底
optional bytes vendor = 12;
}
message Map
{
optional Header header = 1; //上面所说的地图基本信息
repeated Crosswalk crosswalk = 2;//人行横道
repeated Junction junction = 3;//交叉路口
repeated Lane lane = 4;//车道
repeated StopSign stop_sign = 5;//停车标志
repeated Signal signal = 6;//信号灯
repeated YieldSign yield = 7;//让车标志
repeated Overlap overlap = 8;//重爱区域
repeated ClearArea clear_area = 9;//禁止停车区域
repeated SpeedBump speed_bump = 10;//减速带
repeated Road road = 11;//道路
repeated ParkingSpace parking_space = 12;//停车区域
repeated PNCJunction pnc_junction = 13;//路边的小路,或者行人走的路
repeated RSU rsu = 14;
}
// Crosswalk is a place designated for pedestrians to cross a road.
message Crosswalk
{
optional Id id = 1;//编号
optional Polygon polygon = 2;//多边形
repeated Id overlap_id = 3;//重die id
}
// A junction is the junction at-grade of two or more roads crossing.
message Junction
{
optional Id id = 1;
optional Polygon polygon = 2;
repeated Id overlap_id = 3;
}
syntax = "proto2";
package apollo.hdmap;
import "modules/map/proto/map_id.proto";
import "modules/map/proto/map_geometry.proto";
message LaneBoundaryType
{
enum Type
{
UNKNOWN = 0;
DOTTED_YELLOW = 1;
DOTTED_WHITE = 2;
SOLID_YELLOW = 3;
SOLID_WHITE = 4;
DOUBLE_YELLOW = 5;
CURB = 6;
};
// Offset relative to the starting point of boundary
optional double s = 1;
// support multiple types
repeated Type types = 2;
}
message LaneBoundary {
optional Curve curve = 1;
optional double length = 2;
// indicate whether the lane boundary exists in real world
optional bool virtual = 3;
// in ascending order of s
repeated LaneBoundaryType boundary_type = 4;
}
// Association between central point to closest boundary.
message LaneSampleAssociation {
optional double s = 1;
optional double width = 2;
}
// A lane is part of a roadway, that is designated for use by a single line of
// vehicles.
// Most public roads (include highways) have more than two lanes.
message Lane {
optional Id id = 1; //编号
// Central lane as reference trajectory, not necessary to be the geometry
// central.
optional Curve central_curve = 2;//中心曲线
// Lane boundary curve.
optional LaneBoundary left_boundary = 3;//左边界
optional LaneBoundary right_boundary = 4;//右边界
// in meters.
optional double length = 5;//长度
// Speed limit of the lane, in meters per second.
optional double speed_limit = 6;//速度限制
repeated Id overlap_id = 7;//重叠区域 id
// All lanes can be driving into (or from).
repeated Id predecessor_id = 8;
repeated Id successor_id = 9;继任者 id
// Neighbor lanes on the same direction.
repeated Id left_neighbor_forward_lane_id = 10;//前面左边邻居 id
repeated Id right_neighbor_forward_lane_id = 11;//前面右边邻居 id
enum LaneType {//车道类型
NONE = 1;//无
CITY_DRIVING = 2;//城市道路
BIKING = 3;//自行车
SIDEWALK = 4;//人行道
PARKING = 5;//停车
SHOULDER = 6;
};
optional LaneType type = 12;//车道类型
enum LaneTurn {
NO_TURN = 1;//直行
LEFT_TURN = 2;//左转弯
RIGHT_TURN = 3;//右转弯
U_TURN = 4;//掉头
};
optional LaneTurn turn = 13;//转弯类型
repeated Id left_neighbor_reverse_lane_id = 14;//中心点与最近堪路边界之间的关联
repeated Id right_neighbor_reverse_lane_id = 15;//中心点与最近右路边界之间的关联
optional Id junction_id = 16;
// Association between central point to closest boundary.
repeated LaneSampleAssociation left_sample = 17;
repeated LaneSampleAssociation right_sample = 18;
enum LaneDirection {
FORWARD = 1;
BACKWARD = 2;
BIDIRECTION = 3;
}
optional LaneDirection direction = 19;
// Association between central point to closest road boundary.
repeated LaneSampleAssociation left_road_sample = 20;
repeated LaneSampleAssociation right_road_sample = 21;
repeated Id self_reverse_lane_id = 22;
}
// A stop sign is a traffic sign to notify drivers that they must stop before
// proceeding.
message StopSign {//编号
optional Id id = 1;
repeated Curve stop_line = 2;//停止线,Curve 曲线应该是基础类型
repeated Id overlap_id = 3;//重叠 id
enum StopType {
UNKNOWN = 0;//未知
ONE_WAY = 1;//只有一车道可以停
TWO_WAY = 2;
THREE_WAY = 3;
FOUR_WAY = 4;
ALL_WAY = 5;
};
optional StopType type = 4;
}
message Subsignal {
enum Type {
UNKNOWN = 1;//未知
CIRCLE = 2;//圈
ARROW_LEFT = 3;//左边
ARROW_FORWARD = 4;//前面
ARROW_RIGHT = 5;//右边
ARROW_LEFT_AND_FORWARD = 6;//左前
ARROW_RIGHT_AND_FORWARD = 7;//右前
ARROW_U_TURN = 8;//掉头
};
optional Id id = 1;
optional Type type = 2;
// Location of the center of the bulb. now no data support.
optional apollo.common.PointENU location = 3; //也是基础类型?
}
message SignInfo {
enum Type {
None = 0;
NO_RIGHT_TURN_ON_RED = 1;
};
optional Type type = 1;
}
message Signal {
enum Type {
UNKNOWN = 1;
MIX_2_HORIZONTAL = 2;
MIX_2_VERTICAL = 3;
MIX_3_HORIZONTAL = 4;
MIX_3_VERTICAL = 5;
SINGLE = 6;
};
optional Id id = 1;
optional Polygon boundary = 2;//多边形
repeated Subsignal subsignal = 3;//子信号
// TODO: add orientation. now no data support.
repeated Id overlap_id = 4;//重叠 id
optional Type type = 5;
// stop line
repeated Curve stop_line = 6;
repeated SignInfo sign_info = 7;
}
// A yield indicates that each driver must prepare to stop if necessary to let a
// driver on another approach proceed.
// A driver who stops or slows down to let another vehicle through has yielded
// the right of way to that vehicle.
message YieldSign {
optional Id id = 1;
repeated Curve stop_line = 2;
repeated Id overlap_id = 3;
}
message LaneOverlapInfo {
optional double start_s = 1; // position (s-coordinate)
optional double end_s = 2; // position (s-coordinate)
optional bool is_merge = 3;
optional Id region_overlap_id = 4;
}
message SignalOverlapInfo {}
message StopSignOverlapInfo {}
message CrosswalkOverlapInfo {
optional Id region_overlap_id = 1;
}
message JunctionOverlapInfo {}
message YieldOverlapInfo {}
message ClearAreaOverlapInfo {}
message SpeedBumpOverlapInfo {}
message ParkingSpaceOverlapInfo {}
message PNCJunctionOverlapInfo {}
message RSUOverlapInfo {}
message RegionOverlapInfo {
optional Id id = 1;
repeated Polygon polygon = 2;
}
// Information about one object in the overlap.
message ObjectOverlapInfo {
optional Id id = 1;
oneof overlap_info {
LaneOverlapInfo lane_overlap_info = 3;
SignalOverlapInfo signal_overlap_info = 4;
StopSignOverlapInfo stop_sign_overlap_info = 5;
CrosswalkOverlapInfo crosswalk_overlap_info = 6;
JunctionOverlapInfo junction_overlap_info = 7;
YieldOverlapInfo yield_sign_overlap_info = 8;
ClearAreaOverlapInfo clear_area_overlap_info = 9;
SpeedBumpOverlapInfo speed_bump_overlap_info = 10;
ParkingSpaceOverlapInfo parking_space_overlap_info = 11;
PNCJunctionOverlapInfo pnc_junction_overlap_info = 12;
RSUOverlapInfo rsu_overlap_info = 13;
}
}
// Here, the "overlap" includes any pair of objects on the map
// (e.g. lanes, junctions, and crosswalks).
message Overlap {
optional Id id = 1;
// Information about one overlap, include all overlapped objects.
repeated ObjectOverlapInfo object = 2;
repeated RegionOverlapInfo region_overlap = 3;
}
// A clear area means in which stopping car is prohibited
message ClearArea {
optional Id id = 1;
repeated Id overlap_id = 2;
optional Polygon polygon = 3;
}
message SpeedBump {
optional Id id = 1;
repeated Id overlap_id = 2;
repeated Curve position = 3;
}
message BoundaryEdge {
optional Curve curve = 1;
enum Type {
UNKNOWN = 0;
NORMAL = 1;
LEFT_BOUNDARY = 2;
RIGHT_BOUNDARY = 3;
};
optional Type type = 2;
}
message BoundaryPolygon {
repeated BoundaryEdge edge = 1;
}
// boundary with holes
message RoadBoundary {
optional BoundaryPolygon outer_polygon = 1;
// if boundary without hole, hole is null
repeated BoundaryPolygon hole = 2;
}
message RoadROIBoundary {
optional Id id = 1;
repeated RoadBoundary road_boundaries = 2;
}
// road section defines a road cross-section, At least one section must be
// defined in order to
// use a road, If multiple road sections are defined, they must be listed in
// order along the road
message RoadSection {
optional Id id = 1;
// lanes contained in this section
repeated Id lane_id = 2;
// boundary of section
optional RoadBoundary boundary = 3;
}
// The road is a collection of traffic elements, such as lanes, road boundary
// etc.
// It provides general information about the road.
message Road {
optional Id id = 1;
repeated RoadSection section = 2;
// if lane road not in the junction, junction id is null.
optional Id junction_id = 3;
enum Type {
UNKNOWN = 0;
HIGHWAY = 1;
CITY_ROAD = 2;
PARK = 3;
};
optional Type type = 4;
}
// ParkingSpace is a place designated to park a car.
message ParkingSpace {
optional Id id = 1;
optional Polygon polygon = 2;
repeated Id overlap_id = 3;
optional double heading = 4;
}
// ParkingLot is a place for parking cars.
message ParkingLot {
optional Id id = 1;
optional Polygon polygon = 2;
repeated Id overlap_id = 3;
}
// This proto defines the format of an auxiliary file that helps to
// define the speed limit on certain area of road.
// Apollo can use this file to quickly fix speed problems on maps,
// instead of waiting for updating map data.
message SpeedControl {
optional string name = 1;
optional apollo.hdmap.Polygon polygon = 2;
optional double speed_limit = 3;
}
message SpeedControls {
repeated SpeedControl speed_control = 1;
}
syntax = "proto2";
import "modules/common/proto/geometry.proto";
package apollo.hdmap;
// Polygon, not necessary convex.
message Polygon {
repeated apollo.common.PointENU point = 1;
}
// Straight line segment.
message LineSegment {
repeated apollo.common.PointENU point = 1;
}
// Generalization of a line.
message CurveSegment {
oneof curve_type {
LineSegment line_segment = 1;
}
optional double s = 6; // start position (s-coordinate)
optional apollo.common.PointENU start_position = 7;
optional double heading = 8; // start orientation
optional double length = 9;
}
// An object similar to a line but that need not be straight.
message Curve {
repeated CurveSegment segment = 1;
}
syntax = "proto2";
package apollo.hdmap;
import "modules/map/proto/map_id.proto";
import "modules/map/proto/map_geometry.proto";
message Passage {
optional Id id = 1;
repeated Id signal_id = 2;
repeated Id yield_id = 3;
repeated Id stop_sign_id = 4;
repeated Id lane_id = 5;
enum Type {
UNKNOWN = 0;
ENTRANCE = 1;
EXIT = 2;
};
optional Type type = 6;
};
message PassageGroup {
optional Id id = 1;
repeated Passage passage = 2;
};
message PNCJunction {
optional Id id = 1;
optional Polygon polygon = 2;
repeated Id overlap_id = 3;
repeated PassageGroup passage_group = 4;
}
message RSU {
optional Id id = 1;
optional Id junction_id = 2;
repeated Id overlap_id = 3;
};
上面只是简单的介绍了下地图的数据格式,具体的应用场景,还需要结合 routing 、planning 等模块进一步学习。 我们再回过头来看 adapter 模块,其中 xml_parser 就是针对道路的不同元素部分做解析。xz@xiaqiu:~/study/apollo/modules/map/hdmap/adapter$ tree
.
├── BUILD
├── coordinate_convert_tool.cc //坐标转换王具
├── coordinate_convert_tool.h
├── opendrive_adapter.cc // 加载 opendrive 格式地图
├── opendrive_adapter.h
├── proto_organizer.cc
├── proto_organizer.h
└── xml_parser //针对道路的不同元素做相应解析
├── BUILD
├── common_define.h
├── header_xml_parser.cc
├── header_xml_parser.h
├── junctions_xml_parser.cc
├── junctions_xml_parser.h
├── lanes_xml_parser.cc
├── lanes_xml_parser.h
├── objects_xml_parser.cc
├── objects_xml_parser.h
├── roads_xml_parser.cc
├── roads_xml_parser.h
├── signals_xml_parser.cc
├── signals_xml_parser.h
├── status.h
├── util_xml_parser.cc
└── util_xml_parser.h
1 directory, 24 files
Status JunctionsXmlParser::Parse(const tinyxml2::XMLElement &xml_node,
std::vector<JunctionInternal> *junctions)
{
const tinyxml2::XMLElement *junction_node =
xml_node.FirstChildElement("junction");
while (junction_node)
{
// id
std::string junction_id;
int checker =
UtilXmlParser::QueryStringAttribute(*junction_node, "id", &junction_id);
if (checker != tinyxml2::XML_SUCCESS)
{
std::string err_msg = "Error parse junction id";
return Status(apollo::common::ErrorCode::HDMAP_DATA_ERROR, err_msg);
}
// outline
const tinyxml2::XMLElement *sub_node =
junction_node->FirstChildElement("outline");
if (!sub_node)
{
std::string err_msg = "Error parse junction outline";
return Status(apollo::common::ErrorCode::HDMAP_DATA_ERROR, err_msg);
}
PbJunction junction;
junction.mutable_id()->set_id(junction_id);
PbPolygon *polygon = junction.mutable_polygon();
RETURN_IF_ERROR(UtilXmlParser::ParseOutline(*sub_node, polygon));
JunctionInternal junction_internal;
junction_internal.junction = junction;
// overlap
sub_node = junction_node->FirstChildElement("objectOverlapGroup");
if (sub_node)
{
sub_node = sub_node->FirstChildElement("objectReference");
while (sub_node)
{
std::string object_id;
checker =
UtilXmlParser::QueryStringAttribute(*sub_node, "id", &object_id);
if (checker != tinyxml2::XML_SUCCESS)
{
std::string err_msg = "Error parse junction overlap id";
return Status(apollo::common::ErrorCode::HDMAP_DATA_ERROR, err_msg);
}
OverlapWithJunction overlap_with_juntion;
overlap_with_juntion.object_id = object_id;
junction_internal.overlap_with_junctions.push_back(
overlap_with_juntion);
sub_node = sub_node->NextSiblingElement("objectReference");
}
}
junctions->push_back(junction_internal);
junction_node = junction_node->NextSiblingElement("junction");
}
return Status::OK();
}
bool PncMap::UpdateRoutingResponse(const routing::RoutingResponse &routing)
{
range_lane_ids_.clear();
route_indices_.clear();
all_lane_ids_.clear();
//step 工响应结果剥离
for (int road_index = 0; road_index < routing.road_size(); ++road_index)
{
const auto &road_segment = routing.road(road_index);
for (int passage_index = 0; passage_index < road_segment.passage_size();
++passage_index)
{
const auto &passage = road_segment.passage(passage_index);
for (int lane_index = 0; lane_index < passage.segment_size();
++lane_index)
{
all_lane_ids_.insert(passage.segment(lane_index).id());
route_indices_.emplace_back();
route_indices_.back().segment =
ToLaneSegment(passage.segment(lane_index));
if (route_indices_.back().segment.lane == nullptr)
{
AERROR << "Failed to get lane segment from passage.";
return false;
}
route_indices_.back().index = {road_index, passage_index, lane_index};
}
}
}
range_start_ = 0;
range_end_ = 0;
adc_route_index_ = -1;
next_routing_waypoint_index_ = 0;
UpdateRoutingRange(adc_route_index_);
routing_waypoint_index_.clear();
const auto &request_waypoints = routing.routing_request().waypoint();
if (request_waypoints.empty())
{
AERROR << "Invalid routing: no request waypoints.";
return false;
}
int i = 0;
for (size_t j = 0; j < route_indices_.size(); ++j)
{
//2查询点处理
while (i < request_waypoints.size() &&
RouteSegments::WithinLaneSegment(route_indices_[j].segment,
request_waypoints.Get(i)))
{
routing_waypoint_index_.emplace_back(
LaneWaypoint(route_indices_[j].segment.lane,
request_waypoints.Get(i).s()),
j);
++i;
}
}
routing_ = routing;
adc_waypoint_ = LaneWaypoint();
stop_for_destination_ = false;
return true;
}

bool RouteSegments::WithinLaneSegment(const LaneSegment &lane_segment,
const LaneWaypoint &waypoint) {
return waypoint.lane &&
lane_segment.lane->id().id() == waypoint.lane->id().id() &&
lane_segment.start_s - kSegmentationEpsilon <= waypoint.s &&
lane_segment.end_s + kSegmentationEpsilon >= waypoint.s;
}
bool PncMap::UpdateRoutingResponse(const routing::RoutingResponse &routing)
{
...
for (size_t j = 0; j < route_indices_.size(); ++j)
{
while (i < request_waypoints.size() &&
RouteSegments::WithinLaneSegment(route_indices_[j].segment,
request_waypoints.Get(i)))
{
routing_waypoint_index_.emplace_back(
LaneWaypoint(route_indices_[j].segment.lane,
request_waypoints.Get(i).s()),
j);
++i;
}
}
routing_ = routing;
adc_waypoint_ = LaneWaypoint();
stop_for_destination_ = false;
return true;
}
bool PncMap::GetRouteSegments(const VehicleState &vehicle_state,
const double backward_length,
const double forward_length,
std::list<RouteSegments> *const route_segments)
这里的无人车状态不是无人车自身坐标,速度等信息,而是在上述更新路由信息过程中得到的Toute_indices_ 中,无人车在哪个 LaneSegment 中,距离无人车最近的下一个查询点 waypoint 的信息。bool PncMap::GetRouteSegments(const VehicleState &vehicle_state,
const double backward_length,
const double forward_length,
std::list<RouteSegments> *const route_segments)
{
//step 1., 更新车辆状态
if (!UpdateVehicleState(vehicle_state))
{
AERROR << "Failed to update vehicle state in pnc_map.";
return false;
}
// Vehicle has to be this close to lane center before considering change
// lane
if (!adc_waypoint_.lane || adc_route_index_ < 0 ||
adc_route_index_ >= static_cast<int>(route_indices_.size()))
{
AERROR << "Invalid vehicle state in pnc_map, update vehicle state first.";
return false;
}
const auto &route_index = route_indices_[adc_route_index_].index;
const int road_index = route_index[0];
const int passage_index = route_index[1];
const auto &road = routing_.road(road_index);
// Raw filter to find all neighboring passages
auto drive_passages = GetNeighborPassages(road, passage_index);
for (const int index : drive_passages)
{
const auto &passage = road.passage(index);
RouteSegments segments;
if (!PassageToSegments(passage, &segments))
{
ADEBUG << "Failed to convert passage to lane segments.";
continue;
}
const PointENU nearest_point =
index == passage_index
? adc_waypoint_.lane->GetSmoothPoint(adc_waypoint_.s)
: PointFactory::ToPointENU(adc_state_);
common::SLPoint sl;
LaneWaypoint segment_waypoint;
if (!segments.GetProjection(nearest_point, &sl, &segment_waypoint))
{
ADEBUG << "Failed to get projection from point: "
<< nearest_point.ShortDebugString();
continue;
}
if (index != passage_index)
{
if (!segments.CanDriveFrom(adc_waypoint_))
{
ADEBUG << "You cannot drive from current waypoint to passage: "
<< index;
continue;
}
}
route_segments->emplace_back();
const auto last_waypoint = segments.LastWaypoint();
if (!ExtendSegments(segments, sl.s() - backward_length,
sl.s() + forward_length, &route_segments->back()))
{
AERROR << "Failed to extend segments with s=" << sl.s()
<< ", backward: " << backward_length
<< ", forward: " << forward_length;
return false;
}
if (route_segments->back().IsWaypointOnSegment(last_waypoint))
{
route_segments->back().SetRouteEndWaypoint(last_waypoint);
}
route_segments->back().SetCanExit(passage.can_exit());
route_segments->back().SetNextAction(passage.change_lane_type());
const std::string route_segment_id = absl::StrCat(road_index, "_", index);
route_segments->back().SetId(route_segment_id);
route_segments->back().SetStopForDestination(stop_for_destination_);
if (index == passage_index)
{
route_segments->back().SetIsOnSegment(true);
route_segments->back().SetPreviousAction(routing::FORWARD);
}
else if (sl.l() > 0)
{
route_segments->back().SetPreviousAction(routing::RIGHT);
}
else
{
route_segments->back().SetPreviousAction(routing::LEFT);
}
}
return !route_segments->empty();
}
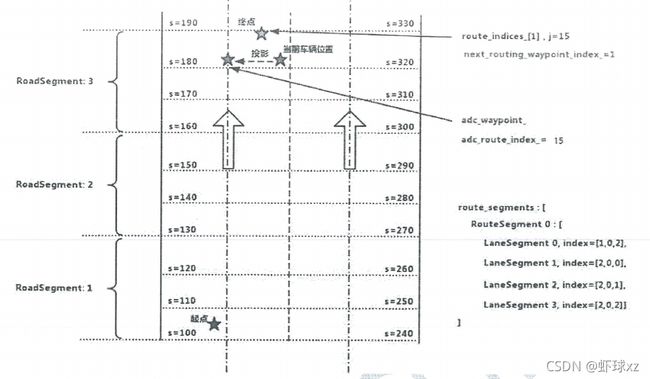
bool PncMap::UpdateVehicleState(const VehicleState &vehicle_state)
{
if (!ValidateRouting(routing_))
{
AERROR << "The routing is invalid when updating vehicle state.";
return false;
}
if (!adc_state_.has_x() ||
(common::util::DistanceXY(adc_state_, vehicle_state) >
FLAGS_replan_lateral_distance_threshold +
FLAGS_replan_longitudinal_distance_threshold))
{
// Position is reset, but not replan.
next_routing_waypoint_index_ = 0;
adc_route_index_ = -1;
stop_for_destination_ = false;
}
// Step 1: 计算当前车辆在对应车道上的投影 adc_waypoint
adc_state_ = vehicle_state;
if (!GetNearestPointFromRouting(vehicle_state, &adc_waypoint_))
{
AERROR << "Failed to get waypoint from routing with point: "
<< "(" << vehicle_state.x() << ", " << vehicle_state.y() << ", "
<< vehicle_state.z() << ").";
return false;
}
// Step 2. 计算车辆投影点所在 LaneSegment 在 route_indices_的索引`dc_route_index
int route_index = GetWaypointIndex(adc_waypoint_);
if (route_index < 0 ||
route_index >= static_cast<int>(route_indices_.size()))
{
AERROR << "Cannot find waypoint: " << adc_waypoint_.DebugString();
return false;
}
//Step3.下一个最近查询点在 routing_waypoint_index_中的索引 next_routing_waypoint index_
// Track how many routing request waypoints the adc have passed.
UpdateNextRoutingWaypointIndex(route_index);
adc_route_index_ = route_index;
UpdateRoutingRange(adc_route_index_);
if (routing_waypoint_index_.empty())
{
AERROR << "No routing waypoint index.";
return false;
}
//step4.如果 next_routing_waypoint_index_ 是终点的索引,表示已经到达目的地。
if (next_routing_waypoint_index_ == routing_waypoint_index_.size() - 1)
{
stop_for_destination_ = true;
}
return true;
}
void PncMap::UpdateNextRoutingWaypointIndex(int cur_index)
{
if (cur_index < 0)
{
next_routing_waypoint_index_ = 0;
return;
}
if (cur_index >= static_cast<int>(route_indices_.size()))
{
next_routing_waypoint_index_ = routing_waypoint_index_.size() - 1;
return;
}
// Search backwards when the car is driven backward on the route.
// 情况1. 车道倒车,后向查找,下一个查询点 waypoint 对应的索引查找
while (next_routing_waypoint_index_ != 0 &&
next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
routing_waypoint_index_[next_routing_waypoint_index_].index >
cur_index)
{
--next_routing_waypoint_index_;
}
// 情况 2. 车道前进,前向查找,下一个查询点 waypoint 对应的索引查找
// 第1步,查找最近包含有 waypoint 的 LaneSegment
while (next_routing_waypoint_index_ != 0 &&
next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
routing_waypoint_index_[next_routing_waypoint_index_].index ==
cur_index &&
adc_waypoint_.s <
routing_waypoint_index_[next_routing_waypoint_index_].waypoint.s)
{
--next_routing_waypoint_index_;
}
// Search forwards
// 第2步, 查找下一个最近的 waypoint 对应的索引
while (next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
routing_waypoint_index_[next_routing_waypoint_index_].index <
cur_index)
{
++next_routing_waypoint_index_;
}
while (next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
cur_index ==
routing_waypoint_index_[next_routing_waypoint_index_].index &&
adc_waypoint_.s >=
routing_waypoint_index_[next_routing_waypoint_index_].waypoint.s)
{
++next_routing_waypoint_index_;
}
if (next_routing_waypoint_index_ >= routing_waypoint_index_.size())
{
next_routing_waypoint_index_ = routing_waypoint_index_.size() - 1;
}
}
std::vector<int> PncMap::GetNeighborPassages(const routing::RoadSegment &road,
int start_passage) const
{
CHECK_GE(start_passage, 0);
CHECK_LE(start_passage, road.passage_size());
std::vector<int> result;
const auto &source_passage = road.passage(start_passage);
result.emplace_back(start_passage);
if (source_passage.change_lane_type() == routing::FORWARD)
{
return result;
}
if (source_passage.can_exit()) // No need to change lane
{
return result;
}
RouteSegments source_segments;
if (!PassageToSegments(source_passage, &source_segments))
{
AERROR << "Failed to convert passage to segments";
return result;
}
if (next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
source_segments.IsWaypointOnSegment(
routing_waypoint_index_[next_routing_waypoint_index_].waypoint))
{
ADEBUG << "Need to pass next waypoint[" << next_routing_waypoint_index_
<< "] before change lane";
return result;
}
std::unordered_set<std::string> neighbor_lanes;
if (source_passage.change_lane_type() == routing::LEFT)
{
for (const auto &segment : source_segments)
{
for (const auto &left_id :
segment.lane->lane().left_neighbor_forward_lane_id())
{
neighbor_lanes.insert(left_id.id());
}
}
}
else if (source_passage.change_lane_type() == routing::RIGHT)
{
for (const auto &segment : source_segments)
{
for (const auto &right_id :
segment.lane->lane().right_neighbor_forward_lane_id())
{
neighbor_lanes.insert(right_id.id());
}
}
}
for (int i = 0; i < road.passage_size(); ++i)
{
if (i == start_passage)
{
continue;
}
const auto &target_passage = road.passage(i);
for (const auto &segment : target_passage.segment())
{
if (neighbor_lanes.count(segment.id()))
{
result.emplace_back(i);
break;
}
}
}
return result;
}
if(source_passage.change_lane_type() == routing::FORWARD)
{
return result;
}
if(source_passage.can_exit())
{
return result;
}
RouteSegments source_segments;
if (!PassageToSegments(source_passage, &source_segments))
{
AERROR << "Failed to convert passage to segments";
return result;
}
if (next_routing_waypoint_index_ < routing_waypoint_index_.size() &&
source_segments.IsWaypointOnSegment(
routing_waypoint_index_[next_routing_waypoint_index_].waypoint))
{
ADEBUG << "Need to pass next waypoint[" << next_routing_waypoint_index_
<< "] before change lane";
return result;
}
if (source_passage.change_lane_type() == routing::LEFT)
{
for (const auto &segment : source_segments)
{
// 查询当前 Passage 中每个LaneSsegment 所在车道的邻接左车道
for (const auto &left_id :
segment.lane->lane().left_neighbor_forward_lane_id())
{
neighbor_lanes.insert(left_id.id());
}
}
}
else if (source_passage.change_lane_type() == routing::RIGHT)
{
for (const auto &segment : source_segments)
{
//查询当前 Passage 中每个Lanesegment 所在车道的邻接右车道
for (const auto &right_id :
segment.lane->lane().right_neighbor_forward_lane_id())
{
neighbor_lanes.insert(right_id.id());
}
}
}
for (int i = 0; i < road.passage_size(); ++i)
{
if (i == start_passage)
{
continue;
}
const auto &target_passage = road.passage(i);
for (const auto &segment : target_passage.segment())
{
if (neighbor_lanes.count(segment.id()))
{
result.emplace_back(i);
break;
}
}
}
return result;
}
const PointENU nearest_point =
index == passage_index
? adc_waypoint_.lane->GetSmoothPoint(adc_waypoint_.s)
: PointFactory::ToPointENU(adc_state_);
common::SLPoint sl;
LaneWaypoint segment_waypoint;
if (!segments.GetProjection(nearest_point, &sl, &segment_waypoint))
{
ADEBUG << "Failed to get projection from point: "
<< nearest_point.ShortDebugString();
continue;
}
计算临近通道时,我们根据当前的位置以及车道变道情况得到了一系列临近车道, 但是这些邻接车道是否可驶入没有被检查,这部分就对车道行驶的合法进行检查。//step 3.2 check if an drive to passage
if (index != passage_index)
{
if (!segments.CanDriveFrom(adc_waypoint_))
{
ADEBUG << "You cannot drive from current waypoint to passage: "
<< index;
continue;
}
}