实时数据平台-Mysql到Mysql(Flink CDC和Debezium)
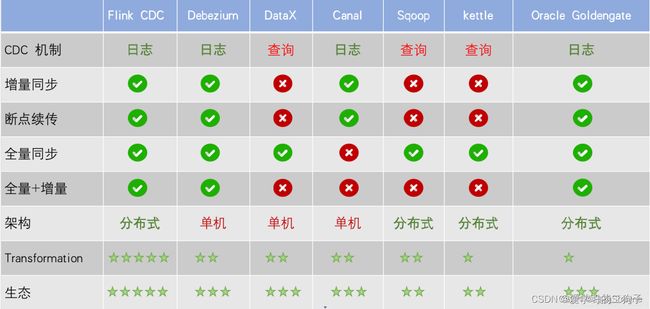
实时数据平台中经常需要跨级群间做数据的同步,这个同步不仅包括数据的实时同步,还包括表结构的实时同步。这里我们经常用到的组件是Flink CDC,从下图我们看到对于Flink CDC和Debezium的几个功能项都是支持的,区别为Flink CDC可以做分布式,Debezium只能做单机。
使用Flink CDC + Flink做实时数据同步的思路:
1.利用Flink CDC监控mysql的某个库下面的某张表或者多个表
2.将Flink CDC读取到mysql的binlog变更数据发送到kafka中
3.如果目的集群没有该表需要创建表时,或者源集群监控表表结构变动时如何做到实时感知感知表结构的变化呢?
创建表时:读取源表的schema构建建表语句,在目标集群创建该表
监控表结构变动:将每次获取的数据字段名存储在状态中,根据状态中的字段数据来确定源表的表结构是否发生变动
例如:现在有一个user表,有id,name,age三个字段,第一个数据来的时候里面三个字段都有,我们会将这三个字段存储在状态中,第二次数据来的时候,只有id,name两个字段,那我们就认为上游删除了一个age字段,下游也应该构建sql,删掉age字段;第三次数据来的时候有id,name,desc三个字段,我们就认为上游新增了一个字段,下游对应也新增字段;这样就可以通过状态实现表结构的动态同步,但这里有一个问题,就是Flink CDC同步数据时,如果某列的值为null时,同步数据的时候就不会出现该字段,这样就会导致我们schema实时同步出现问题:
解决方案1:可以通过规范表结构的数据,但我们不可能保证所有的数据都很规范
解决方案2:利用Debezium等其他数据同步工具去实现
使用debezium同步数据相比CDC优势:
1.不需要使用状态编程,作业可以更快地重启或者迁移
2.不需要频繁从mysql数据schema,可以加快job的运行
3.数据为null时也不影响表结构同步
1.Flink CDC实现数据库同步方案
1.Flink CDC代码
这里我们使用了自定义的DebeziumDeserializationSchema,根据上游数据库的操作方式不同,判断属于那种操作(插入,更新,删除),将对应的数据二次处理封装之后写入kafka
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.concurrent.TimeUnit;
public class FlinkCdc {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// TODO 2. 状态后端设置
/* env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);
env.setRestartStrategy(RestartStrategies.failureRateRestart(
10, Time.of(1L, TimeUnit.DAYS), Time.of(3L, TimeUnit.MINUTES)
));
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs://test1:8020/gmall/ck");
System.setProperty("HADOOP_USER_NAME", "root");*/
//2.创建Flink-MySQL-CDC的Source
DebeziumSourceFunction mysqlSource = MySqlSource.builder()
.hostname("hadoop100")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall")
//.tableList("test.*")
.tableList("gmall.activity_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
//.deserializer(new StringDebeziumDeserializationSchema())
.deserializer(new DebeziumDeserializationSchema() { //自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
//获取主题信息,包含着数据库和表名 mysql_binlog_source.gmall-flink.z_user_info
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取值信息并转换为Struct类型
Struct value = (Struct) sourceRecord.value();
//获取变化后的数据
Struct after = value.getStruct("after");
Struct before = value.getStruct("before");
//创建JSON对象用于存储数据信息
JSONObject data = new JSONObject();
//创建JSON对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
if(after != null && before == null) {
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
}else if(after != null && before != null){
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
}else {
for (Field field : before.schema().fields()) {
Object o = before.get(field);
data.put(field.name(), o);
}
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
}
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//3.使用CDC Source从MySQL读取数据
DataStreamSource mysqlDS = env.addSource(mysqlSource);
//4.打印数据
//mysqlDS.print();
mysqlDS.addSink(new FlinkKafkaProducer("hadoop100:9092","db_sync",new SimpleStringSchema()));
//5.执行任务
env.execute();
}
} 2.Flink Mysql同步代码
代码思路:
1.通过查询源表mysql schema获取字段名称和数据类型封装到map中
2.第一条数据来时,判断状态是否为空,为空的话更新状态并检查表是否存在,存在的话插入数据
3.如果状态数据和处理数据字段不一样的话,获取schema差异字段,判断是更新列,删除列,新增列,更新状态,最后插入数据
package com.longi.sync;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.sql.*;
import java.util.*;
public class MysqlToMysql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/*env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);
env.setRestartStrategy(
RestartStrategies.failureRateRestart(
3, Time.days(1), Time.minutes(1)
)
);
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop100:8020/ck");*/
//System.setProperty("HADOOP_USER_NAME", "root");
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "mysql_sync1");
DataStreamSource sourceDS = env.addSource(new FlinkKafkaConsumer("db_sync2", new SimpleStringSchema(), pro));
SingleOutputStreamOperator mapDS = sourceDS.map(JSON::parseObject);
KeyedStream keyByDS = mapDS.keyBy(new KeySelector() {
@Override
public String getKey(JSONObject value) throws Exception {
String database = value.getString("database");
String table = value.getString("table");
return database + "-" + table;
}
});
//keyByDS.print();
keyByDS.addSink(new RichSinkFunction() {
private ValueState valueState;
private Connection conn;
private Statement statement;
private PreparedStatement pst;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
valueState = getRuntimeContext().getState(
new ValueStateDescriptor("schema", String.class)
);
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://hadoop100:3306/test1"; //JDBC的URL
conn = DriverManager.getConnection(url, "root", "123456");
statement = conn.createStatement();
}
@Override
public void close() throws Exception {
super.close();
if (statement != null) {
statement.close();
}
if (conn != null) {
statement.close();
}
}
@Override
public void invoke(JSONObject value, Context context) throws Exception {
JSONObject data = value.getJSONObject("data");
String table = value.getString("table");
String operation = value.getString("operation");
Set keySet = data.keySet();
String stateValue = valueState.value();
StringBuffer buffer = new StringBuffer();
for (String s : keySet) {
buffer.append(s).append(",");
}
String substring = buffer.toString();
System.out.println(substring);
//元数据库查询该表所有字段的数据类型
HashMap map = new HashMap();
String dataTypeSql = "select DISTINCT DATA_TYPE,COLUMN_NAME from \n" +
"INFORMATION_SCHEMA.Columns \n" +
"where table_name= '" + table + "' and TABLE_SCHEMA = 'test'";
ResultSet resultSet = statement.executeQuery(dataTypeSql);
while (resultSet.next()) {
String dataType = resultSet.getString(1);
String columnName = resultSet.getString(2);
map.put(columnName, dataType);
}
if (stateValue == null) {
//状态为空,更新状态
valueState.update(substring);
//判断表是否存在,不存在则建表
checkTable(table, conn, map, statement);
//插入数据
insertData(table, substring, data, conn, pst, map, operation, statement);
} else {
//如果状态数据不包含数据schema,更新状态,修改目标数据库
//获取两个schema的差异字段
StringBuffer addBuffer = new StringBuffer();
HashMap updateMap = new HashMap<>();
StringBuffer deleteBuffer = new StringBuffer();
List keyList = Arrays.asList(substring.split(","));
List stateList = Arrays.asList(stateValue.split(","));
ArrayList stateList2 = new ArrayList<>();
for (String s : stateList) {
stateList2.add(s.trim());
}
ArrayList keyList2 = new ArrayList<>();
for (String s : keyList) {
keyList2.add(s.trim());
}
for (int i = 0; i < keyList.size(); i++) {
String item = keyList.get(i).trim();
//新增column
if (!stateList2.contains(item) && stateList2.size() < keyList.size()) {
addBuffer.append(item);
// 如果当前字段不是最后一个字段,则追加","
if (i < keyList.size() - 1) {
addBuffer.append(",");
}
//update column
} else if (stateList2.size() == keyList.size() && !stateList2.contains(item)) {
for (String oldCol : stateList2) {
if (!keyList.contains(oldCol)) {
updateMap.put(oldCol, item);
}
}
}
}
//删除 col
if (keyList2.size() < stateList2.size()) {
stateList2.removeAll(keyList2);
System.out.println(stateList2);
for (int i = 0; i < stateList2.size(); i++) {
deleteBuffer.append(stateList2.get(i));
// 如果当前字段不是最后一个字段,则追加","
if (i < stateList2.size() - 1) {
deleteBuffer.append(",");
}
}
}
if (!"".equals(addBuffer.toString())) {
String sql = addColumn(table, addBuffer.toString(), "test1", map);
statement.execute(sql);
//插入数据
insertData(table, substring, data, conn, pst, map, operation, statement);
}
else if (!"".equals(updateMap.toString()) && updateMap.size() > 0) {
String sql = updateColumn(table, updateMap, "test1", map);
System.out.println(sql);
statement.execute(sql);
//插入数据
insertData(table, substring, data, conn, pst, map, operation, statement);
}
else if (!"".equals(deleteBuffer.toString())) {
String sql = deleteColumn(table, deleteBuffer.toString(), "test1");
System.out.println(sql);
statement.execute(sql);
//插入数据
insertData(table, substring, data, conn, pst, map, operation, statement);
}else {
//列没有变化,插入数据即可
insertData(table, substring, data, conn, pst, map, operation, statement);
}
valueState.update(substring);
}
}
});
env.execute();
}
public static void insertData(String table, String substring,
JSONObject data,
Connection conn,
PreparedStatement pst,
HashMap map,
String operation,
Statement statement) throws SQLException {
if ("read".equals(operation) || "create".equals(operation)) {
StringBuffer insertSql = new StringBuffer("insert into test1." + table
+ "(" + substring.substring(0, substring.length() - 1) + ")" + " values(");
for (int i = 0; i < data.keySet().size(); i++) {
insertSql.append("?");
// 如果当前字段不是最后一个字段,则追加","
if (i < data.keySet().size() - 1) {
insertSql.append(",");
} else {
insertSql.append(")");
}
}
System.out.println(insertSql.toString());
pst = conn.prepareStatement(insertSql.toString());
String[] field = substring.split(",");
for (int i = 1; i <= field.length; i++) {
String dataType = map.get(field[i - 1]);
if ("int".equals(dataType)) {
pst.setInt(i, data.getInteger(field[i - 1]));
} else if ("varchar".equals(dataType)) {
pst.setString(i, data.getString(field[i - 1]));
}
}
pst.addBatch();
pst.execute();
} else if ("update".equals(operation)) {
//update person set name = 'hehe',age = 233 where id = 1
StringBuffer updateSql = new StringBuffer("update test1." + table + " set ");
int i = 1;
for (String s : data.keySet()) {
updateSql.append(s);
if (map.get(s).equals("int")) {
updateSql.append("=" + data.getInteger(s));
} else if (map.get(s).equals("varchar")) {
updateSql.append("='" + data.getString(s) + "'");
}
// 如果当前字段不是最后一个字段,则追加","
if (i < data.keySet().size()) {
updateSql.append(",");
}
i++;
}
updateSql.append(" where id =" + data.getInteger("id"));
System.out.println(updateSql.toString());
statement.execute(updateSql.toString());
}else if ("delete".equals(operation)){
//delete from person where id = 1
StringBuffer deleteSql = new StringBuffer("delete from test1." + table + " where id = ");
Integer id = data.getInteger("id");
deleteSql.append(id);
statement.execute(deleteSql.toString());
}
}
public static String addColumn (String sinkTable, String sinkColumns, String
database, HashMap < String, String > map){
// 封装建表 SQL
StringBuilder sql = new StringBuilder();
sql.append("ALTER TABLE " + database
+ "." + sinkTable + " ADD (\n");
String[] columnArr = sinkColumns.split(",");
// 遍历添加字段信息
for (int i = 0; i < columnArr.length; i++) {
sql.append(columnArr[i]);
if ("int".equals(map.get(columnArr[i]))) {
sql.append(" int");
} else if ("varchar".equals(map.get(columnArr[i]))) {
sql.append(" varchar(255)");
}
// 如果当前字段不是最后一个字段,则追加","
if (i < columnArr.length - 1) {
sql.append(",\n");
}
}
sql.append(")");
String createStatement = sql.toString();
return createStatement;
}
//alter table stdent change name name1 varchar(255);
public static String updateColumn (String sinkTable, HashMap < String, String > updateMap, String
database, HashMap < String, String > schemaMap){
// 封装建表 SQL
StringBuilder sql = new StringBuilder();
sql.append("ALTER TABLE " + database
+ "." + sinkTable);
int i = 1;
for (String key : updateMap.keySet()) {
sql.append(" change column " + key + " ").append(updateMap.get(key));
if ("int".equals(schemaMap.get(key))) {
sql.append(" int");
} else if ("varchar".equals(schemaMap.get(updateMap.get(key)))) {
sql.append(" varchar(255)");
}
if (updateMap.size() > 1 && i < updateMap.size()) {
sql.append(",");
}
i++;
}
String createStatement = sql.toString();
return createStatement;
}
//alter table stdent drop column name;
public static String deleteColumn (String sinkTable, String sinkColumns, String database){
// 封装建表 SQL
StringBuilder sql = new StringBuilder();
sql.append("ALTER TABLE " + database
+ "." + sinkTable);
String[] columnArr = sinkColumns.split(",");
// 遍历添加字段信息
for (int i = 0; i < columnArr.length; i++) {
sql.append(" drop column " + columnArr[i]);
// 如果当前字段不是最后一个字段,则追加","
if (i < columnArr.length - 1) {
sql.append(",\n");
}
}
String deleteSql = sql.toString();
return deleteSql;
}
public static void checkTable (String tableName, Connection
connection, HashMap < String, String > schemaMap, Statement statement) throws SQLException {
//判断表是否存在
String sql = "select 1 from information_schema.tables where table_schema='test1' and table_name ='" + tableName + "'";
PreparedStatement prepareStatement = connection.prepareStatement(sql);
ResultSet resultSet = prepareStatement.executeQuery();
int flag = 0;
if (resultSet.next()) {
flag = resultSet.getInt(1);
}
if (flag == 1) {
System.out.println("table already exists");
} else {
//建表
StringBuffer createTableSql = new StringBuffer("create table if not exists test1." + tableName + "(");
for (String key : schemaMap.keySet()) {
if ("id".equals(key)) {
createTableSql.append("id int primary key");
}
}
int i = 1;
for (String key : schemaMap.keySet()) {
createTableSql.append(key);
if ("int".equals(schemaMap.get(key))) {
createTableSql.append(" int");
} else if ("varchar".equals(schemaMap.get(key))) {
createTableSql.append(" varchar(255)");
}
if (schemaMap.size() > 1 && i < schemaMap.size()) {
createTableSql.append(",");
}
i++;
}
createTableSql.append(")");
statement.execute(createTableSql.toString());
}
}
}
2.Debezium实现数据库同步方案
1.Debezium代码
构建debezium代码监控mysql,并将读取到的Binlog数据发送到kafka
package com.xxx.com.xxx;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import io.debezium.engine.ChangeEvent;
import io.debezium.engine.DebeziumEngine;
import io.debezium.engine.format.Json;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class DebeziumTest {
private static DebeziumEngine> engine;
public static void main(String[] args) throws Exception {
final Properties props = new Properties();
props.setProperty("name", "dbz-engine");
props.setProperty("connector.class", "io.debezium.connector.mysql.MySqlConnector");
//offset config begin - 使用文件来存储已处理的binlog偏移量
props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
props.setProperty("offset.storage.file.filename", "/tmp/dbz/storage/mysql_offsets.dat");
props.setProperty("offset.flush.interval.ms", "0");
//offset config end
props.setProperty("database.server.name", "mysql-connector5");
props.setProperty("database.history", "io.debezium.relational.history.FileDatabaseHistory");
props.setProperty("database.history.file.filename", "/tmp/dbz/storage/mysql_dbhistory.txt");
props.setProperty("database.server.id", "1"); //需要与MySQL的server-id不同
props.setProperty("database.hostname", "hadoop100");
props.setProperty("database.port", "3306");
props.setProperty("database.user", "root");
props.setProperty("database.password", "123456");
props.setProperty("database.include.list", "gmall");//要捕获的数据库名
props.setProperty("table.include.list", "gmall.activity_rule");//要捕获的数据表
props.setProperty("snapshot.mode", "initial");//全量+增量
//kafka代码
Properties kafkaPro = new Properties();
kafkaPro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
kafkaPro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
kafkaPro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 3. 创建 kafka 生产者对象
KafkaProducer kafkaProducer = new KafkaProducer(kafkaPro);
// 使用上述配置创建Debezium引擎,输出样式为Json字符串格式
engine = DebeziumEngine.create(Json.class)
.using(props)
.notifying(record -> {
System.out.println(record.toString());
kafkaProducer.send(new ProducerRecord<>("debezium_cdc2",record.toString()));
})
.using((success, message, error) -> {
if (error != null) {
// 报错回调
System.out.println("------------error, message:" + message + "exception:" + error);
}
closeEngine(engine);
})
.build();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);
addShutdownHook(engine);
awaitTermination(executor);
// 5. 关闭资源
kafkaProducer.close();
}
private static void closeEngine(DebeziumEngine> engine) {
try {
engine.close();
} catch (IOException ignored) {
}
}
private static void addShutdownHook(DebeziumEngine> engine) {
Runtime.getRuntime().addShutdownHook(new Thread(() -> closeEngine(engine)));
}
private static void awaitTermination(ExecutorService executor) {
if (executor != null) {
try {
executor.shutdown();
while (!executor.awaitTermination(5, TimeUnit.SECONDS)) {
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
} 2.Flink Mysql同步代码
这个代码实现就比用cdc那个简单多了,不需要用状态编程,数据类型也在消息体内,不需要去数据库获取schema,唯一的不好就是debezium的消息体过于复杂
package com.longi.debezium;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.math.BigDecimal;
import java.sql.*;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
public class MysqlToMysql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// TODO 3. 从 Kafka debezium_cdc 主题读取数据
String topic = "debezium_cdc2";
String groupId = "debezium_cdc_49";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop100:9092");
properties.setProperty("group.id", groupId);
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "earliest");
DataStreamSource kafkaDS = env.addSource(new FlinkKafkaConsumer(topic, new SimpleStringSchema(), properties));
SingleOutputStreamOperator, JSONObject>> mapDS = kafkaDS.map(
new MapFunction, JSONObject>>() {
@Override
public Tuple2, JSONObject> map(String value) throws Exception {
String str = value.replace("EmbeddedEngineChangeEvent [key=", "");
//System.out.println(str);
String[] split = str.split(", value=");
String key = split[0];
String[] split1 = split[1].split(", sourceRecord=SourceRecord");
String val = split1[0];
HashMap map = new HashMap<>();
JSONObject valueJson = JSONObject.parseObject(val);
JSONObject payload = null;
String ddl = "";
if(valueJson !=null){
payload = valueJson.getJSONObject("payload");
ddl = payload.getString("ddl");
}
if(ddl != "" && null != ddl){
map.put("ddl",ddl);
}else if(valueJson != null){
JSONObject schema = valueJson.getJSONObject("schema");
JSONArray fields = schema.getJSONArray("fields");
String s = fields.get(0).toString();
JSONObject array = JSON.parseObject(s);
JSONArray fields1 = array.getJSONArray("fields");
for (int i = 0; i < fields1.size(); i++) {
JSONObject jsonObject = JSON.parseObject(fields1.getString(i));
//System.out.println(jsonObject.toString());
String field = jsonObject.getString("field");
String name = jsonObject.getString("name");
if (name != null && name.equals("io.debezium.time.Timestamp")) {
map.put(field, "datetime");
} else {
String type = jsonObject.getString("type");
if (type.equals("int64")){
map.put(field, "bigint");
}else if(type.equals("string")){
map.put(field, "varchar");
}else if(type.equals("int32")){
map.put(field, "int");
}else if(type.equals("bytes")){
map.put(field, "bigdecimal");
}
}
}
}
JSONObject jsonObj = new JSONObject();
String[] source = split[2].replace("Struct{after=Struct", "").split(",source=Struct");
System.out.println(source[0]);
//针对更新数据做处理
if(!source[0].startsWith("Struct{source=") && !source[0].startsWith("null") ){
if(source[0].startsWith("Struct{before") && source[0].contains("after")){
String[] split2 = source[0].replace("Struct{after=Struct", "").split(",after=Struct");
String replace = split2[1].replace("=", ":").replace("{","").replace("}","");
String[] dataKv = replace.split(",");
JSONObject data = new JSONObject();
for (String s : dataKv) {
String[] split3 = s.split(":");
data.put(split3[0],split3[1]);
}
jsonObj.put("data",data);
}else if(source[0].startsWith("{")){
JSONObject data = JSON.parseObject(source[0].replace("=", ":"));
jsonObj.put("data",data);
}
}
jsonObj.put("key", key);
jsonObj.put("sch", val);
return new Tuple2<>(map, jsonObj);
}
}
);
//mapDS.print();
mapDS.addSink(new RichSinkFunction, JSONObject>>() {
private Connection conn;
private Statement statement;
private PreparedStatement pst;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://test3:3306/gmall";
conn = DriverManager.getConnection(url,"root","123456");
statement = conn.createStatement();
}
@Override
public void invoke(Tuple2, JSONObject> value, Context context) throws Exception {
String ddl = value.f0.get("ddl");
JSONObject value1 = value.f1.getJSONObject("sch");
if(ddl != "" && null != ddl){
String table = "activity_rule";
if(ddl.contains(table)){
statement.execute(ddl);
}
}else if(value1 != null){
HashMap map = value.f0;
//System.out.println(value1.toString());
JSONObject payload = value1.getJSONObject("payload");
JSONObject before = payload.getJSONObject("before");
JSONObject after = payload.getJSONObject("after");
String operate = payload.getString("op");
JSONObject fields = value1.getJSONObject("fields");
//System.out.println(fields);
JSONObject key = value.f1.getJSONObject("key");
JSONObject schema = key.getJSONObject("schema");
String name = schema.getString("name");
String[] split = name.split("\\.");
String database = split[1];
String table1 = split[2];
JSONObject data = value.f1.getJSONObject("data");
//1. 新增数据拼接sql,直接插入
if((operate.equals("r") || operate.equals("c")) && data != null ){
insertData(database,table1,data,conn,pst,map);
}else if(operate.equals("u")){
//更新数据,根据主键删除之前的数据,再插入新的数据
JSONArray fields1 = schema.getJSONArray("fields");
String primaryKey = JSON.parseObject(fields1.get(0).toString()).getString("field");
String keyData = key.getJSONObject("payload").getString(primaryKey);
deleteData(database,table1,primaryKey,conn,pst,keyData);
insertData(database,table1,data,conn,pst,map);
}else if(operate.equals("d")){
JSONArray fields1 = schema.getJSONArray("fields");
String primaryKey = JSON.parseObject(fields1.get(0).toString()).getString("field");
String keyData = key.getJSONObject("payload").getString(primaryKey);
deleteData(database,table1,primaryKey,conn,pst,keyData);
}
}
}
@Override
public void close() throws Exception {
super.close();
if(statement != null){
statement.close();
}
if(conn != null){
conn.close();
}
}
});
env.execute();
}
/**
* 根据id删除对应的数据
* @param database
* @param table1
* @param primaryKey
* @param conn
* @param pst
* @param data
*/
private static void deleteData(String database, String table1, String primaryKey, Connection conn, PreparedStatement pst, String data) throws SQLException {
StringBuffer deleteSql = new StringBuffer("delete from "+ database + "." + table1);
deleteSql.append(" where "+primaryKey + " = " + data );
pst = conn.prepareStatement(deleteSql.toString());
pst.execute();
}
/**
* 插入数据
* @param database 插入的数据库
* @param table 插入的表
* @param data 插入的数据
* @param conn jdbc连接对象
* @param pst jdbc 执行对象
* @param map 数据对应的类型map
* @throws SQLException
*/
public static void insertData( String database,
String table,
JSONObject data,
Connection conn,
PreparedStatement pst,
HashMap map) throws SQLException {
Map dataMap = JSONObject.toJavaObject(data, Map.class);
Set keySet = null;
if(dataMap != null){
keySet = dataMap.keySet();
}
Set mapKey = map.keySet();
StringBuffer insertSql = new StringBuffer("insert into "+ database + "." + table
+ "(" + StringUtils.join(mapKey,",")+ ")" + " values(");
for (int i = 0; i < mapKey.size(); i++) {
insertSql.append("?");
// 如果当前字段不是最后一个字段,则追加","
if (i < mapKey.size() - 1) {
insertSql.append(",");
} else {
insertSql.append(")");
}
}
System.out.println(insertSql.toString());
pst = conn.prepareStatement(insertSql.toString());
String join = StringUtils.join(map.keySet(), ",");
String[] field = join.split(",");
String dataKeys = StringUtils.join(keySet, ",");
for (int i = 1; i <=field.length ; i++) {
String fieldName = field[i - 1];
String dataType = map.get(fieldName);
if("bigint".equals(dataType)){
if(dataKeys.contains(fieldName)){
pst.setInt(i, data.getIntValue(fieldName));
}else{
pst.setInt(i, 0);
}
}else if("varchar".equals(dataType)){
if(dataKeys.contains(fieldName)){
pst.setString(i, data.getString(fieldName));
}else{
pst.setString(i, "");
}
}else if("datetime".equals(dataType)){
if(dataKeys.contains(fieldName)){
pst.setTimestamp(i, data.getTimestamp(fieldName));
}else{
pst.setTimestamp(i,null);
}
}
else if("int".equals(dataType)){
if(dataKeys.contains(fieldName)){
pst.setInt(i, data.getIntValue(fieldName));
}else{
pst.setInt(i, 0);
}
}else if("bigdecimal".equals(dataType)){
if(dataKeys.contains(fieldName)){
pst.setBigDecimal(i, data.getBigDecimal(fieldName));
}else{
pst.setBigDecimal(i, BigDecimal.valueOf(0));
}
}
}
pst.addBatch();
pst.execute();
}
}
3.Flink CDC和Debezium消息体
1.Flink CDC消息体
整个消息体分为两部分sourceRecord和ConnectRecord,sourceRecord中主要存放的binlog偏移信息,connectRecord中keySchema中存放的database和table名,value中存放的数据信息
SourceRecord{
sourcePartition={server=mysql_binlog_source},
sourceOffset={ts_sec=1694764944, file=mysql-bin.000016, pos=8017, snapshot=true}}
ConnectRecord{topic='mysql_binlog_source.gmall.activity_info', kafkaPartition=null, key=Struct{id=1},
keySchema=Schema{mysql_binlog_source.gmall.activity_info.Key:STRUCT},
value=Struct{after=Struct{id=1,activity_name=assss,activity_type=1001},
source=Struct{version=1.5.4.Final,connector=mysql,name=mysql_binlog_source,
ts_ms=1694764944151,snapshot=true,db=gmall,table=activity_info,server_id=0,
file=mysql-bin.000016,pos=8017,row=0},
op=r,ts_ms=1694764944157},
valueSchema=Schema{mysql_binlog_source.gmall.activity_info.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}2. Debezium消息体
debezium消息体比较复杂,有好几层。
第一层:key和value,sourceRecord和ConnectRecord
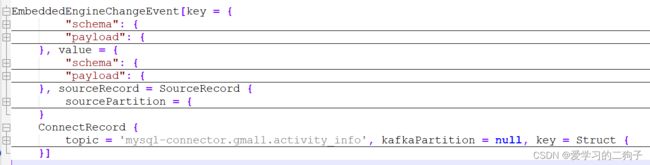
这里的sourceRecord和ConnectRecord就是CDC中的消息体结构
第二层:
key--> schema 可从此结构中分解出数据库名和表名

key--> payload 可以提取出主键和对应的主键数据

value-->schema 这个fields中就存放的变更前后的数据类型
 value-->payload 这里存放的就是变更前后的数据
value-->payload 这里存放的就是变更前后的数据

最后附上完整的消息体
EmbeddedEngineChangeEvent[key = {
"schema": {
"type": "struct",
"fields": [{
"type": "int64",
"optional": false,
"field": "id"
}],
"optional": false,
"name": "mysql_connector.gmall.activity_info.Key"
},
"payload": {
"id": 3
}
}, value = {
"schema": {
"type": "struct",
"fields": [{
"type": "struct",
"fields": [{
"type": "int64",
"optional": false,
"field": "id"
}, {
"type": "string",
"optional": true,
"field": "activity_name"
}, {
"type": "string",
"optional": true,
"field": "activity_type"
}, {
"type": "string",
"optional": true,
"field": "activity_desc"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "start_time"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "end_time"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "create_time"
}],
"optional": true,
"name": "mysql_connector.gmall.activity_info.Value",
"field": "before"
}, {
"type": "struct",
"fields": [{
"type": "int64",
"optional": false,
"field": "id"
}, {
"type": "string",
"optional": true,
"field": "activity_name"
}, {
"type": "string",
"optional": true,
"field": "activity_type"
}, {
"type": "string",
"optional": true,
"field": "activity_desc"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "start_time"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "end_time"
}, {
"type": "int64",
"optional": true,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "create_time"
}],
"optional": true,
"name": "mysql_connector.gmall.activity_info.Value",
"field": "after"
}, {
"type": "struct",
"fields": [{
"type": "string",
"optional": false,
"field": "version"
}, {
"type": "string",
"optional": false,
"field": "connector"
}, {
"type": "string",
"optional": false,
"field": "name"
}, {
"type": "int64",
"optional": false,
"field": "ts_ms"
}, {
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false,incremental"
},
"default": "false",
"field": "snapshot"
}, {
"type": "string",
"optional": false,
"field": "db"
}, {
"type": "string",
"optional": true,
"field": "sequence"
}, {
"type": "string",
"optional": true,
"field": "table"
}, {
"type": "int64",
"optional": false,
"field": "server_id"
}, {
"type": "string",
"optional": true,
"field": "gtid"
}, {
"type": "string",
"optional": false,
"field": "file"
}, {
"type": "int64",
"optional": false,
"field": "pos"
}, {
"type": "int32",
"optional": false,
"field": "row"
}, {
"type": "int64",
"optional": true,
"field": "thread"
}, {
"type": "string",
"optional": true,
"field": "query"
}],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
}, {
"type": "string",
"optional": false,
"field": "op"
}, {
"type": "int64",
"optional": true,
"field": "ts_ms"
}, {
"type": "struct",
"fields": [{
"type": "string",
"optional": false,
"field": "id"
}, {
"type": "int64",
"optional": false,
"field": "total_order"
}, {
"type": "int64",
"optional": false,
"field": "data_collection_order"
}],
"optional": true,
"field": "transaction"
}],
"optional": false,
"name": "mysql_connector.gmall.activity_info.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 3,
"activity_name": "ccccc",
"activity_type": "1003",
"activity_desc": "fffff",
"start_time": null,
"end_time": null,
"create_time": null
},
"source": {
"version": "1.9.5.Final",
"connector": "mysql",
"name": "mysql-connector",
"ts_ms": 1694568910248,
"snapshot": "true",
"db": "gmall",
"sequence": null,
"table": "activity_info",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000015",
"pos": 154,
"row": 0,
"thread": null,
"query": null
},
"op": "r",
"ts_ms": 1694568910248,
"transaction": null
}
}, sourceRecord = SourceRecord {
sourcePartition = {
server = mysql - connector
}, sourceOffset = {
ts_sec = 1694568910,
file = mysql - bin .000015,
pos = 154,
snapshot = true
}
}
ConnectRecord {
topic = 'mysql-connector.gmall.activity_info', kafkaPartition = null, key = Struct {
id = 3
}, keySchema = Schema {
mysql_connector.gmall.activity_info.Key: STRUCT
}, value = Struct {
after = Struct {
id = 3, activity_name = ccccc, activity_type = 1003, activity_desc = fffff
}, source = Struct {
version = 1.9 .5.Final, connector = mysql, name = mysql - connector, ts_ms = 1694568910248, snapshot = true, db = gmall, table = activity_info, server_id = 0, file = mysql - bin .000015, pos = 154, row = 0
}, op = r, ts_ms = 1694568910248
}, valueSchema = Schema {
mysql_connector.gmall.activity_info.Envelope: STRUCT
}, timestamp = null, headers = ConnectHeaders(headers = )
}]