彩虹桥架构演进之路-性能篇
一、前言
一年前的《彩虹桥架构演进之路》侧重探讨了稳定性和功能性两个方向。在过去一年中,尽管业务需求不断增长且流量激增了数倍,彩虹桥仍保持着零故障的一个状态,算是不错的阶段性成果。而这次的架构演进,主要分享一下近期针对性能层面做的一些架构调整和优化。其中最大的调整就是 Proxy-DB 层的线程模式从 BIO 改造成了性能更好的 NIO。下面会详细介绍一下具体的改造细节以及做了哪些优化。
阅读本文预计需要 20~30 分钟,整体内容会有些枯燥难懂,建议阅读前先看一下上一篇彩虹桥架构演进的文章(彩虹桥架构演进之路)以及 MySQL 协议相关基础知识。
二、改造前的架构
先来复习一下彩虹桥的全景架构图:
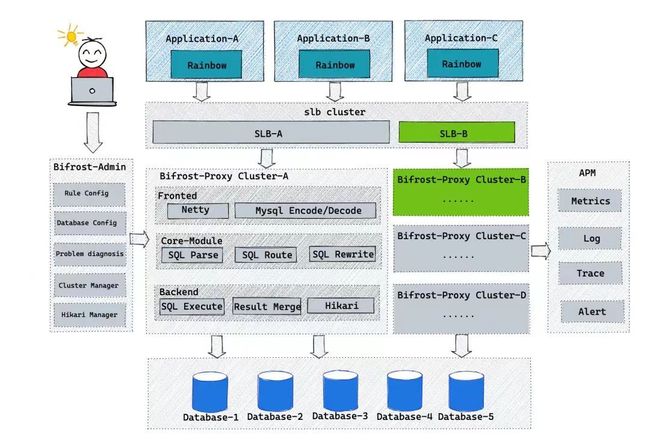
Proxy三层模块
针对 Proxy 这一层,可以大致分成 Frontend、Core、Backend 三层:
-
Frontend-服务暴露层:使用 Netty 作为服务器,按照 MySQL 协议对接收&返回的数据进行编解码。
-
Core-功能&内核层:通过解析、改写、路由等内核能力实现数据分片、读写分离、影子库路由等核心功能。
-
Backend-底层DB交互层:通过 JDBC 实现与数据库交互、对结果集改列、归并等操作。
BIO模式下的问题
这里 Core 层为纯计算操作,而 Frontend、Backend 都涉及 IO 操作,Frontend 层使用 Netty 暴露服务为 NIO 模式,但是 Backend 使用了数据库厂商提供的传统 JDBC 驱动,为 BIO 模式。所以 Proxy 的整体架构还是 BIO 模式。在 BIO 模型中,每个连接都需要一个独立的线程来处理。这种模型有一些明显的缺点:
-
高资源消耗:每个请求创建独立线程,伴随大量线程开销。线程切换与调度额外消耗 CPU。
-
扩展性受限:受系统线程上限影响,处理大量并发连接时,性能急剧下降。
-
I/O阻塞:BIO 模型中,读/写操作均为阻塞型,导致线程无法执行其他任务,造成资源浪费。
-
复杂的线程管理:线程管理和同步问题增加开发和维护难度。
我们看最简单的一个场景:在 JDBC 在发起请求后,当前线程会一直阻塞直到数据库返回数据,当出现大量慢查或者数据库出现故障时,会导致大量线程阻塞,最终雪崩。在上一篇彩虹桥架构演进文章中,我们做了一些改进来避免了 BIO 模型下的一些问题,比如使用线程池隔离来解决单库阻塞导致全局雪崩的问题。
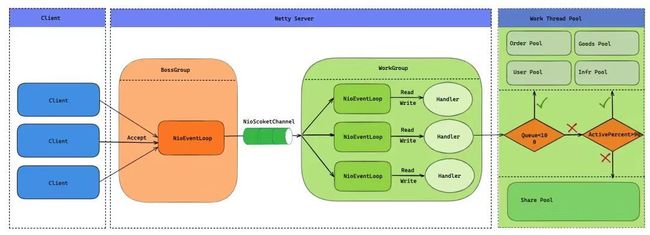
但是随着逻辑库数量的增多,最终导致 Proxy 的线程数膨胀。系统的可伸缩性和吞吐量都受到了挑战。因此有必要将现有的基于 JDBC 驱动的阻塞式连接升级为采用 NIO(非阻塞 I/O)方式连接数据库。
三、改造后的架构
- BIO->NIO
想把 Proxy 整体架构从 BIO->NIO,最简单的方式就是把传统的 BIO 数据库驱动 JDBC 换成 NIO 的数据库驱动,但是在调研过后发现开源的 NIO 驱动并不多,而且基本上没有什么最佳实践。最后在参考 ShardingSphere 社区之前做的调研后(https://github.com/apache/shardingsphere/issues/13957),决定使用 Vertx 来替换 JDBC。最开始使用 Vert.x 的原因,第一是 Vertx 的异步编码方式更友好,编码复杂度相对较低,第二是因为它实现了主流数据库的驱动。但最终的结果不尽人意,由于 Vertx 相关抽象化的架构,导致链路较长时,整个调用栈深非常夸张。最终压测出来的吞吐量提升只有 5% 不到,而且存在很多兼容性问题。于是推倒重来,决定自研数据库驱动和连接池。
- 跳过不必要的编解码阶段
由于 JDBC 驱动会自动把 MySQL 的字节数据编解码成 Java 对象,然后 Proxy 再把这些结果集经过一些加工(元信息修正、结果集归并)后再进行编码返回给上游。如果自研驱动的话,就可以把编解码流程控制的更细致一些,把 Proxy 不需要加工的数据直接转发给上游,跳过无意义的编解码。后面会介绍一下哪些场景是不需要 Proxy 对结果集进行加工的。
自研NIO数据库驱动
数据库驱动主要是封装了与 DB 层交互协议,封装成高级 API。下面 2 张图是 java.sql 包中的 Connection 和 Statement 的一些核心接口。
所以首先我们需要了解一下,如何与数据库进行数据交互,以 MySQL 为例,使用 Netty 连接 MySQL,简单的交互流程如下。
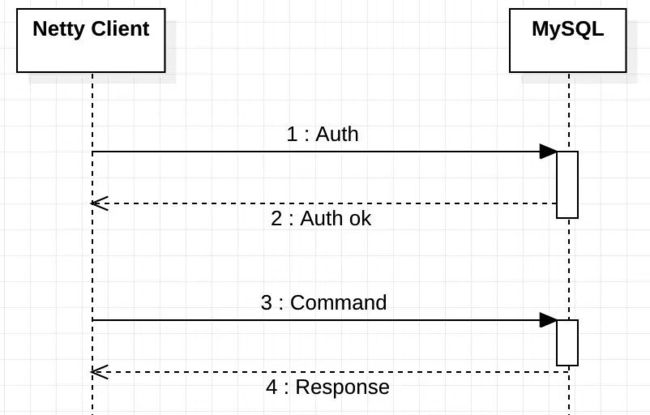
使用 Netty 与 MySQL 连接建立后,我们要做的就是按照 MySQL 协议规定的数据格式,先鉴权后再发送具体的命令包即可。下面是 MySQL 官方文档中鉴权流程和命令执行流程:
- 鉴权流程:https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_connection_phase.html
- 执行命令流程:https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_command_phase.html
下面就是按照 MySQL 的文档,去实现编解码 Handle,我们简单看一下实现的代码。
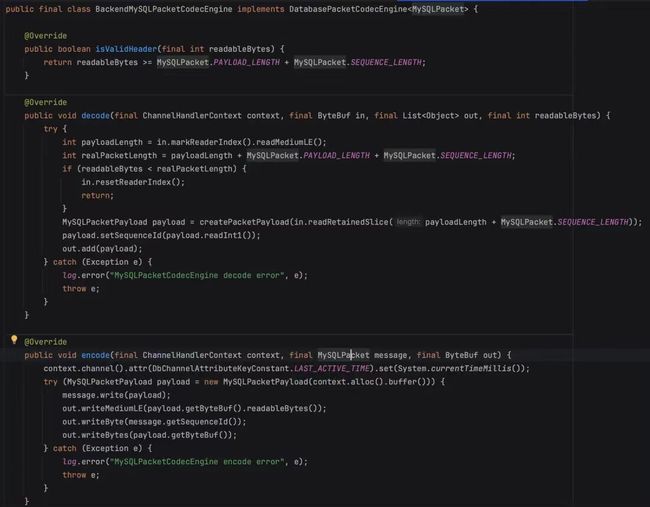
- decode 解码
就是针对 MySQL 返回的数据包解码,根据长度解析出 Palyload 封装成 MySQLPacketPayload 传给对应的 Handle 处理。
- encode 编码
把具体的命令类转换成具体的 MySQL 数据包,这里的 MySQLPacket 有多个实现类,跟 MySQL的Command 类型一一对应。
现在还需要一个类似 java.sql.Connection 的实现类,来组装 MySQLPacket 并写入到 Netty 通道中,并且解析编码后的 MySQLPacketPayload 转换成 ResultSet。
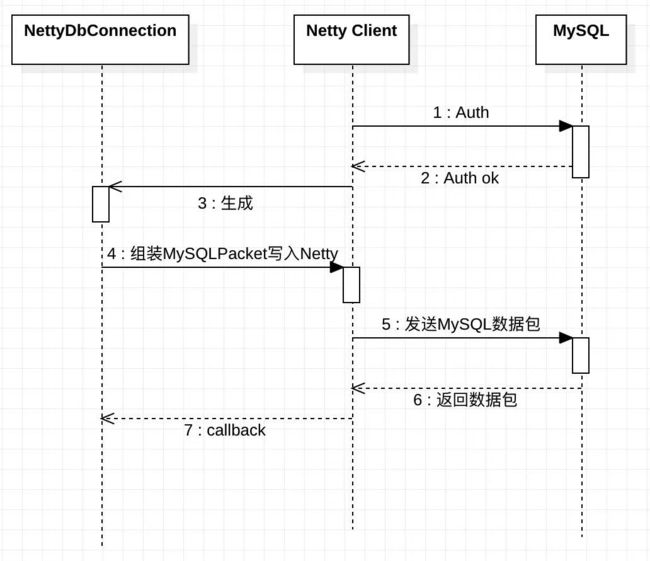
看起来比较简单,交互流程和传统的 JDBC 几乎一样,但是由于现在是异步化流程,所有的 Response 都是通过回调返回,所以这里有 2 个难点:
- 由于 MySQL 在上一条命令没结束前无法接受新的命令,所以如何控制单个连接的命令串行化?
- 如何将 MySQL 返回的数据包和发起命令的 Request 一一绑定?
首先 NettyDbConnection 引入了一个无锁化非阻塞队列 ConcurrentLinkedQueue。
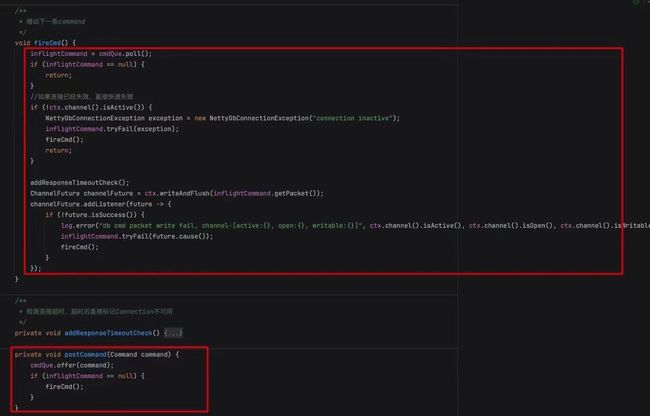
在发送 Command 时,如何没有正在进行中的 Command,则直接发送,如果有正在进行中的 Command,直接扔到队列中,等待上一条 Command 处理完成后推动下一条命令的执行。保证了单个连接命令串行化。
其次,NettyDbConnection 在执行命令时,传入一个 Promise,在 MySQL 数据包全部返回后,这个 Promise 将会被设置完成,即可于发起命令的 Request 一一绑定。

自研NIO数据库连接池
前面介绍了 NettyDbConnection 这个类,实现了与 MySQL 的交互,并且提供了执行 SQL 的高级 API,但实际使用过程中,不可能每次都创建一个连接执行完 SQL 就关闭。所以需要对 NettyDbConnection 进行池化,统一管理连接的生命周期。其功能类似于传统连接池 HikariCP,在完成基本能力的基础上,做了很多性能优化。
- 连接生命周期管控
- 连接池动态伸缩
- 完善的监控
- 连接异步保活
- 超时控制
- EventLoop 亲和性
这里除了 EventLoop 亲和性,其他几个功能只要用过传统的数据库连接池应该都比较熟悉,这里不做过多展开。这里主要针对 EventLoop 亲和性展开介绍一下。
在文章开头我们说到 Proxy 的三层模块,Frontend、Core、Backend,如果现在我们把 Backend 层于数据库交互的组件换成了我们自研的驱动,那么 Proxy 就即是Netty Server,也是Netty Client,所以 Frontend 和 Backend 可以共用一个 EventLoopGroup。为了降低线程上下文切换,在单个请求从 Frontend 接收、经过 Core 层计算后转发到 MySQL ,再到接收 MySQL 服务响应,以及最终的回写给 Client 端,这一些列操作尽量放在一个 EventLoop 线程中处理。

具体的做法就是 Backend 在选择与数据库连接时,优先选择与当前 EventLoop 绑定的连接。也就是前面提到的 EventLoop 亲和性,这样就能保证大部分场景下一次请求从头到尾都由同一个 EventLoop 处理,下面我们看一下具体的代码实现。
在 NettyDbConnectionPool 类中使用一个 Map 存储连接池中的空闲连接,Key 为 EventLoop,Value 为当前 EventLoop 绑定的空闲连接队列。

在获取时,优先获取当前 EventLoop 绑定的连接,如果当前 EventLoop 未绑定连接,则会借用其他 EventLoop 的连接。

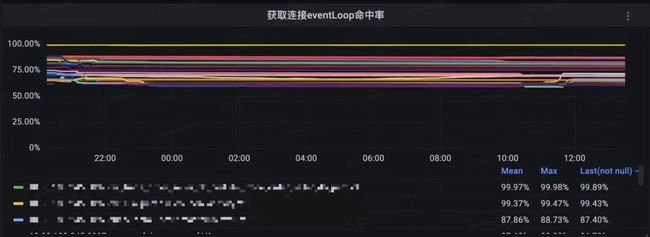
为了提高 EventLoop 命中率,需要注意几点配置:
- EventLoop 线程数量尽量与 CPU 核心数保持一致。
- 连接池最大连接数超过 EventLoop 线程数越多,EventLoop 命中率越高。
下面放一张压测环境(8C16G、连接池最大连接数 10~30)的命中率监控,大部分保持在 75% 左右。
跳过不必要的编解码
前面说到,有部分 SQL 的结果集是不需要 Proxy 进行加工的,也就是可以直接把 MySQL 返回的数据流原封不动转发给上游,直接省去编解码操作。那什么 SQL 是不需要 Proxy 进行加工的呢,我们举个例子说明一下。
假设逻辑库 A 里面有一张表 User 做了分库,分了 2 个库 DB1 和 DB2,分片算法是 user_id%2。
- SQL 1
SELECT id, name FROM user WHERE user_id in (1, 2)
- SQL 2
SELECT id, name FROM user WHERE user_id in (1)
很显然 SQL 1由于有 2 个分片 Value,最终匹配到了 2 个节点,SQL 2 只会匹配到 1 个节点。

SQL 1 由于需要对结果集进行归并,所以无法跳过编解码,SQL 2 不需要对结果集归并,只需要把结果集中的列定义数据做修正后,真正的 Row 数据无需处理,这种情况就可以把 Row 数据直接转发至上游。
全链路异步化
Backend 层用自研连接池+驱动替换原先的 HikariCP+JDBC 后,从 Frontend-Core-Backend 全链路涉及到阻塞的操作需要全部替换成异步化编码,也就是通过 Netty 的 Promise 和 Future 来实现。

由于部分场景拿到 Future 时,可能当前 Future 已经完成了,如果每次都是无脑的加 Listener 会让调用栈加长,所以我们定义了一个通用的工具类来处理 Future,即 future.isDone() 时直接执行,反之才会 addListener,最大化降低整个调用栈的深度。

兼容性
除了以上基本代码的改造外,还需要做大量的兼容工作:
-
特殊数据库字段类型处理
-
JDBC URL 参数兼容
-
ThreadLocal 相关数据全部需要迁移至 ChannelHandlerContext 中
-
日志 MDC、TraceContext 相关数据传递
-
……
四、性能表现
经过几轮性能压测后,NIO架构相较于BIO架构性能有较大提升:
- 整体最大吞吐量提升 67%
- LOAD 下降 37% 左右
- 高负载情况下 BIO 多次出现进程夯住现象,NIO 相对较稳定
- 线程数减少 98% 左右
五、总结
NIO 架构的改造工作量相当巨大,中间也经历了一些曲折,但是最终的结果令人满意。得益于 ShardingShpere 本身内核层面的高性能加上本次 NIO 改造后,彩虹桥在 DAL 中间件性能层面基本上可以算是第一梯队了。
*文 / 新一
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!