jvm学习-内存结构
JVM学习(一)
1.什么是jvm
定义:
Java Virtual Machine -java程序的运行环境(java二进制字节码的运行环境)
好处:
- 一次编写,到处运行
- 自动内存管理,垃圾回收功能
- 数组下标越界检查
- 多态
比较:
jvm jre jdk
jre = jvm+基础类库
jdk = jvm+基础类库+编译工具
2.学jvm有什么用
1.面试
2.帮助我们理解底层的实现原理
3.中高级程序员必备技能分析生产环境问题
3.常见的jvm
HotSpot
OpenJ9
GCJ等等
我们的学习还是以hotspot的为准
4.jvm的结构
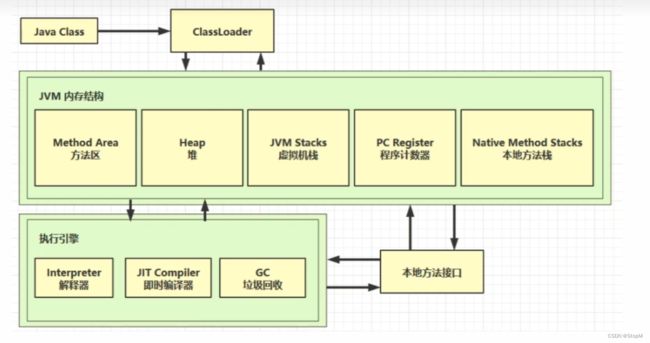
我们学习
1.jvm内存结构
2.GC
3.类的字节码结构以及优化和类加载器
4.执行引擎优化
5.内存结构
1.程序计数器
Program Counter Register
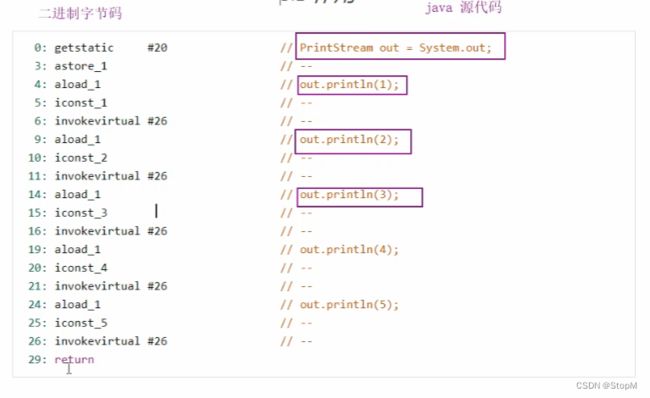
理解:我们右边的java代码是对应我们jvm中一套字节码规范(即jvm指令),我们的jvm指令通过执行引擎中的解释器将其翻译为机器码然后交给我们的cpu来进行执行
那么这和我们的程序计数器有什么关系呢?
1.作用
我们的程序计数器就是来记住下一条jvm指令的执行地址的
例如当我们的地址为0的指令在执行时,我们的地址3的指令便会放入程序计数器
程序计数器是一个寄存器(cpu组件里面读取速度最快的一个单元)
2.特点
1.是线程私有的(即每个线程有自己的程序计数器)
我们的cpu会对多个线程会有一个时间片策略
例如线程1时间片用完了,我们就需要程序计数器给我们返回执行状态
2.不会存在内存溢出的区域
2.虚拟机栈
1.定义
JVM Stacks
栈这个数据结构很熟悉把,就不多做解释了(先进后出)
虚拟机栈就是我们线程运行需要的内存空间
一个栈是由栈帧组成
那么什么是栈帧呢?栈帧对应着我们的一次方法的调用(每个方法运行时需要的内存)
栈帧中有:参数,局部变量,返回地址
当调用一个方法时把该方法的栈帧压入栈,结束将方法的栈帧出栈
-
每个线程运行时所需要的内存成为虚拟机栈
-
每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存
-
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
具体的代码可以去idea演示一个main线程嵌套调用m1,m1调用m2再看frames(我就不看了)
2.问题辨析
1.垃圾回收是否涉栈内存?
不需要,栈帧的内存在执行完对应的方法后会释放
2.栈内存分配越大越好吗
-Xss size
这个参数就是设置栈的内存设置(默认1024kb)
栈内存太大了,线程不就少了吗。。。。
一个栈对应一个线程啊,所以肯定不是
设置的唯一需求的就是需要递归调用太多
3.方法内的局部变量是否线程安全
不一定,一个栈对应一个线程,局部变量对应就是每个线程的方法的栈帧,互不影响干扰
//多个线程执行此方法
static void m1(){
int x = 0;
for(int i = 0;i<5000;i++){
x++;
}
System.out.println(x);
}
//线程一的栈中有个对应m1方法的栈帧,栈帧中局部变量有一个x(且无法被其他线程访问),线程二同理
但是如果我们这个线程的局部变量(这个指的是引用类型)是作为参数或者返回值能够被其他线程所访问,就可能会存在线程安全的问题,
其实就是因为我们的引用类型变量都是放在堆里面的,如果其他线程拿不到就是安全,否则不安全
3.栈内存溢出
1.栈帧过多导致栈内存溢出(一般是递归死循环)
2.栈帧过大导致栈内存溢出(谁没事定义那么多局部变量)
4.线程诊断
案例1:cpu占用过多
在虚拟机上运行有问题的java代码,通过top命令可以看到是哪一个进程
发现是java进程我们可以再利用
ps -H eo pid,tid,%cpu |grep pid(top看到的)
-eo是指定哪些信息,下面是进程号,线程号,和cpu
这样定位到了线程了
我们再利用jdk中的jstack + pid 看出这个java此程序的线程信息
换算tid 找到jstack里面的tid就可以知道是哪个线程了并且能具体到行里面
案例2:程序运行很长时间没有结果
jstack pid
在我们的jstack的结尾我们可以看到一些提示
例如如果死锁了那么他会说我们的Threadxxx和Threadxxx死锁了
3.本地方法栈
Native Method Stacks
是给我们调用本地方法(C/C++与操作系统打交道)提供的一些内存空间
我们就不看了(课也没讲)
4.堆
1.定义
Heap
- 我们通过new关键字,创建的对象都会使用堆内存
特点
- 它是线程共享的,堆中对象若被多个线程使用需考虑线程安全问题
- 有垃圾回收机制
2.堆内存溢出
java.lang.OutOfMemoryError: java heap space
堆空间的最大设置
-Xmx(默认是4G)
3.堆内存诊断
1.jps工具 查看java进程
2.jmap工具 查看堆内存占用情况
3.jconsole 图形界面的多功能监测工具,可以连续监测
代码
public static void main(String[] args) throws InterruptedException {
System.out.println("1...");
Thread.sleep(30000);
byte[] array = new byte[1024 * 1024 * 10]; //10mb
System.out.println("2...");
Thread.sleep(30000);
array = null;
System.gc();
System.out.println("3...");
Thread.sleep(1000000L);
}
//这个代码的过程我相信不用解释了(等30s为了给jmap/jconsole调试时间)
jps
jmap -heap -pid
查看eden space
案例:垃圾回收后,内存占用仍然很高
代码运行后老年代一直有200mb
gc之后老年代根本就没有被回收(是否是编程失误导致一直没回收)
新工具:jvisualvm
5.方法区
1.定义
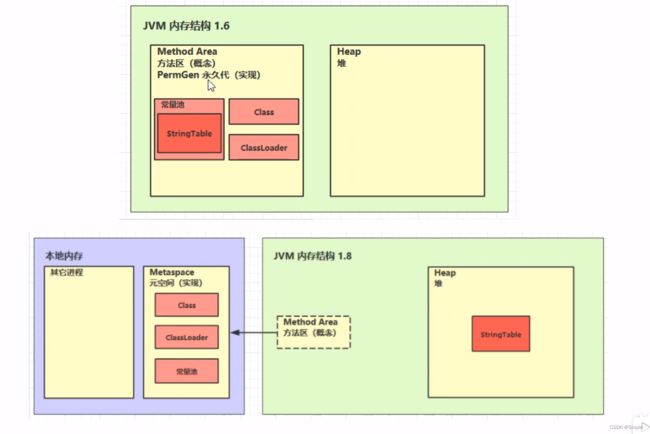
我们的方法区是存储我们的一些类的信息和类的加载器的信息的,我们在jvm1.6的结构可以看到永久代的实现,其中我们的class,classLoader以及我们的运行时常量池均在永久代里面,这个时候理论来说这个方法区是逻辑上的,实际上仍然使用的是我们的堆空间
而jvm1.8就已经没有了永久代这个说法,而是变成了元空间,不同的是现在我们的方法区并不占用我们的堆内存了转而占用我们的本地操作系统的内存,并且我们的StringTable也不在我们的方法区了而是到了我们的堆空间里面
2.方法区内存溢出
代码
public class Demo1_8 exitends ClassLoader{//可以用来加载类的二进制字节码
public static void main(String[] args){
int j = 0;
try{
Demo1_8 test = new Demo1_8();
for(int u = 0;i<10000;i++,j++){
//ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
//版本号,public,类名,包名,父类,接口
cw.visit(Opcodes.V1_8,Opcodes.ACC_PUBLIC,"class"+i,null,"java/lang/object",null);
//返回byte[]
byte[] code = cw.toByteArray();
//执行类的加载
test.defineClass("Class"+i,code,0,code.length);//Class对象
}
}finally{
System.out.println(j);
}
}
}
发现没有溢出!
说过了自从1.8之后我们的已经改为元空间并且使用的是系统的内存,溢出肯定很难啊
所以我们改个参数 -XX:MaxMetaspaceSize=8m
永久代要用1.6
-XX:MaxPermSize=8m
场景
-
spring
-
mybatis
均使用cglib来产生代理对象和我们的mapper实现类
产生大量动态代理类对象导致元空间溢出
3.运行时常量池
我们将代码转化为二进制字节码
二进制字节码包括什么呢?
类基本信息,常量池,类方法定义,包含了虚拟机指令
我们通过javap -v 反编译字节码文件
里面有全类名,版本内部信息(上面都是)
下面是常量池 constant pool
然后是构造方法 main方法
方法里面就有虚拟机的指令交给我们的解释器来处理
总结:
常量池就是一张表,虚拟机指令根据这张常量表找到要执行的类名,方法名,参数类型,字面量等信息
运行时常量池,常量池是.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并将里面的符号地址转变为真实地址
4.StringTable
常量池运行时会被加载到我们的运行时常量池,这时 a b ab都是常量池的符号,还没有变成java字符串对象
ldc #2 会将a符号变为“a”的字符串对象
StringTable[] 会去找"a"这个字符串对象,如果没有那么我们会将这个字符串对象放入StringTable
然后变成StringTable[“a”]
只有当用到了这个字符串对象才会放入(懒惰的)
最后就会变成StringTable[“a”,“b”,“ab”]
HashTable结构且不能扩容
面试题解析
public class Demo{
public static void main(String[] args){
String s1 = 'a';
String s2 = 'b';
String s3 = 'ab';
String s4 = s1 + s2;
System.out.println(s3 == s4);
String s5 = "a"+"b";
System.out.println(s3 == s5);
}
}
1.我们的s4一行的是如何进行的呢?
我们不确定变量的结果所以在编译期间优化不了,就要走下面这些行为
我们实际先创建了一个StringBuilder对象,且调用的是无参构造
加载了s1我们就会进行append,加载了s2我们又会进行append
最后调用了toString方法
将toString得到的结果我们又new了一个String对象
结果就是我们的s4实际上是堆对象的引用而我们的s3是对我们StringTable的引用所以不是一个对象所以是false
2.我们的s5一行是如何进行的呢?
ldc #4 我们直接找到的是String ab 然后存在局部变量表中的5号然后return
都是常量池中的4号位置
这个其实是javac在我们的编译期间的优化,常量的结果在编译期间已经确定,所以会直接拼接为ab
特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象(懒加载)
- 利用串池的机制来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder(1.8)
- 字符串常量拼接的原理是编译器优化
- 可以使用intern方法主动将串池中还没有的字符串对象放入串池
代码:
public class Demo{
public static void main(String[] args){
String s1 = new String("a");
String s2 = new String("b");
String s =s1+s2;
System.out.println(s1 == "a");
System.out.println(s2 == "b");
//用到了"a"和"b"放入串池,并且new了两个String对象值分别为a和b
//变量的拼接用到了StringBuilder所以相当于new了一个("ab")的String对象位于堆中
//所以上面是5个对象串池的"a" "b"和堆中的s1 s2 s
s.intern();
//将这个字符串对象尝试放入串池,如果有则不会放入,并返回串中的对象(成功放入串池是不是就是我堆中的对象呢)
//验证
System.out.println(s == "ab");
//确实是,所以仍然是5个对象
}
}
//不考虑1.6了写的是1.8
StringTable的位置
1.6的StringTable是常量池一部分位于永久代(full gc 才会触发回收效率不高)
1.8的StringTable是堆里面的一部分
StringTable垃圾回收
下面是一段代码演示(所有代码均采用jdk1.8)
/*
*演示StringTable垃圾回收
*-Xmx10m -XX:+PrintStringTableStatistics -XX:+printGCDetails -verbose:gc
*前面这个是堆内存最大10m 第二个是打印我们StringTable的信息 而第三个是我们垃圾回收的信息
*/
public class Demo{
public static void main(String[] args)throws InterruptedException{
int j = 0;
for(int i = 0;i<10000;i++){
String.valueOf(i).intern();
//放池子
j++;
}
try{
}catch(Throwable e){
e.printStackTrace();
}finally{
System.out.println(j);
}
}
}
我们在运行时,光我们的各种类名方法名符号名已经占据了我们的串池的1754个空间,记得不错的话(HashTable),我们执行上面这个会添加10000个串池对象进去但是触发垃圾回收后只剩余了7000多个,因为没被引用被年轻代收回了,所以StringTable也会被垃圾回收
StringTable性能调优
- 调整 -XX:StringTableSize=桶个数
因为我们的StringTable的底层是一个HashTable,当我们的桶数量偏多时,我们的碰撞会减少很多,并且链表长度也会变小就会让查找的效率高非常多,其实主要就是调整我们HashTable桶的个数了
看下面一段代码
public class Demo1_25 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line.intern());
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
}
//linux的词典有48w行词
//读取并放入串池
//我们调整 -XX:StringTableSize=桶个数(默认60013) 大概花费0.6s
//而调整为20w桶 就会快一点大概0.4s
//如果说设置为1089(最小) 要12s
//所以当我们的串池有大量的字符串对象时,我们就要考虑调整桶的大小了
- 考虑字符串对象是否入池
有这么一个案例,推特在当初在存储用户的地区信息时,如果将将所有用户的地区信息存入了内存,需要花费30个g的内存,但是推特使用intern来入池,大量重复的地区被入池,所以最后优化成了上百m。
我们来看下面的一个代码
package cn.itcast.jvm.t1.stringtable;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* 演示 intern 减少内存占用
* -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics
* -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
*/
public class Demo1_25 {
public static void main(String[] args) throws IOException {
//扔进arraylist防止被垃圾回收
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line);
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
//我们来回车开始读取10次linux词典,共480w词语
//我们读完(char数组和String)就有300m内存被消耗了
}
}
我们做一下修改
public class Demo1_25 {
public static void main(String[] args) throws IOException {
//扔进arraylist防止被垃圾回收
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line.intern());
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
//我们通过串池来优化,扔进串池
//读完了有效的其实是48w个,我们去visualVm看看
//我们读完只有30m被消耗了
}
}
6.直接内存
它并不属于我们jvm的内存结构,他是我们的操作系统的内存
- 常用于NIO操作,用于数据缓冲区
- 分配回收成本高,但读写性能高
- 不受jvm内存回收管理
看下面的一段代码
package cn.itcast.jvm.t1.direct;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "E:\\编程资料\\第三方教学视频\\youtube\\Getting Started with Spring Boot-sbPSjI4tt10.mp4";
//这个视频大概是800多m
static final String TO = "E:\\a.mp4";
static final int _1Mb = 1024 * 1024;
//读写缓冲都是1m奥
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io()
//正常的输入流读和输出流写
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
//结论:直接内存的速度确实比正常的io流快很多
读取过程
io:
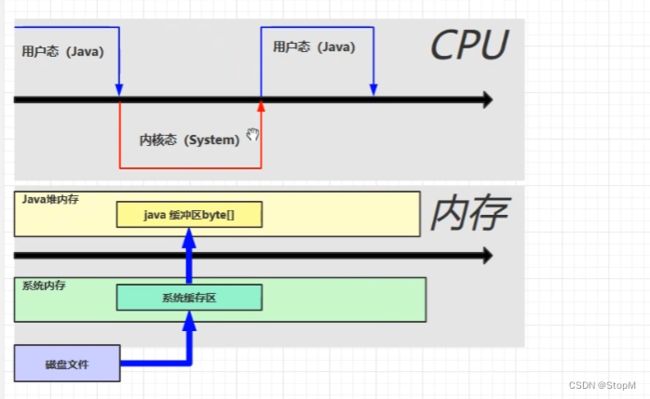
先将磁盘的内容先读入到系统缓冲区里面,系统缓冲区的内容是无法被java代码读取,我们又要从系统缓冲区读入到我们的java缓冲区,那么是不是这一块数据我们就有两份存储并且读取也是有时间消耗的,所以我们最终时长较长
当我们使用直接内存时,我们使用direct memory申请的内存对于我们的系统内存和java堆内存就是一块可以共享的内存区,将磁盘文件读入到我们的直接内存,少了一次缓存操作,适合做文件的io操作
直接内存溢出
好是好,但是它不受jvm内存回收管理啊,会不会导致内存溢出啊
package cn.itcast.jvm.t1.direct;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
/**
* 演示直接内存溢出
*/
public class Demo1_10 {
static int _100Mb = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
// 方法区是jvm规范, jdk6 中对方法区的实现称为永久代\
// jdk8 对方法区的实现称为元空间
}
}
//最终在我们的分配到3600mb内存时溢出了
//Direct buffer memory
直接内存释放
那么我们来演示一下如何来进行内存释放了
package cn.itcast.jvm.t1.direct;
import java.io.IOException;
import java.nio.ByteBuffer;
/**
* 禁用显式回收对直接内存的影响
*/
public class Demo1_26 {
static int _1Gb = 1024 * 1024 * 1024;
/*
* -XX:+DisableExplicitGC 显式的
*/
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc(); // 显式的垃圾回收,Full GC
System.in.read();
}
}
//因为我们的采用的是直接内存所以是要在我们的任务管理器来看内存增长
//欸,我们在将bytebuffer设置为null时,没有使用这块内存之后我们回收成功了
//那是不是因为垃圾回收将直接内存回收掉了呢(不是,垃圾回收是回收jvm的内存)
直接内存释放原理
package cn.itcast.jvm.t1.direct;
import sun.misc.Unsafe;
import java.io.IOException;
import java.lang.reflect.Field;
/**
* 直接内存分配的底层原理:Unsafe
* 这个类就是释放直接内存的类(jdk用的,非常底层)
* 当然这个类无法直接获得我们就用反射来获得即可
*/
public class Demo1_27 {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = getUnsafe();
// 分配内存的两个方法
//base 是分配的内存地址
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 直接内存只能通过freeMemory来释放内存
unsafe.freeMemory(base);
System.in.read();
}
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe;
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
//那么为什么ByteBuffer.allocateDirect(_1Gb)能申请直接内存呢
//自然是用到了我们说的unsafe类了
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
//创建了DirectByteBuffer对象,我们看看构造方法里是个啥
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
//果然
base = unsafe.allocateMemory(size);
unsafe.setMemory(base, size, (byte) 0);
//那么我们为啥我们没用freeMemory还是在gc后释放了呢
//其实是因为我们的一个回调任务
//其中还是调用了unsafe的free
//那么重点就是我们的Cleaner了
new Deallocator(base, size, cap)
private static class Deallocator
implements Runnable
{
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
//Cleaner在我们java类库里叫虚引用类型,特点是当他关联的对象(DirectByteBuffer对象)被我们的垃圾回收掉时,会触发我们虚引用类型的Cleaner对象的线程属性thunk的run方法,就会执行释放内存,触发是靠我们的ReferenceHandler的线程来监听虚引用对象,当关联的对象被回收时就会调用clearner对象的clean方法然后进一步执行传进来的线程属性(Deallocator对象)的run方法来freeMemory
//下面就是Cleaner类
public class Cleaner extends PhantomReference<Object> {
private static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue();
private static Cleaner first = null;
private Cleaner next = null;
private Cleaner prev = null;
private final Runnable thunk;
private static synchronized Cleaner add(Cleaner var0) {
if (first != null) {
var0.next = first;
first.prev = var0;
}
first = var0;
return var0;
}
private static synchronized boolean remove(Cleaner var0) {
if (var0.next == var0) {
return false;
} else {
if (first == var0) {
if (var0.next != null) {
first = var0.next;
} else {
first = var0.prev;
}
}
if (var0.next != null) {
var0.next.prev = var0.prev;
}
if (var0.prev != null) {
var0.prev.next = var0.next;
}
var0.next = var0;
var0.prev = var0;
return true;
}
}
private Cleaner(Object var1, Runnable var2) {
super(var1, dummyQueue);
this.thunk = var2;
}
public static Cleaner create(Object var0, Runnable var1) {
return var1 == null ? null : add(new Cleaner(var0, var1));
}
public void clean() {
if (remove(this)) {
try {
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
}
总结:
- 使用Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法
- ByteBuffer实现类的内部使用了Cleaner(虚引用)来监测ByteBuffer对象一旦该对象被垃圾回收,那么由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存
禁用显式回收对直接内存的影响
因为显式的回收full gc会十分耗费时间和性能,我们jvm调优时经常会加上
-XX +DisableExplicitGC 来禁用
但是这个会影响我们直接内存释放(System.gc()没用)
即便是byteBuffer没引用对象了,但是内存充裕我们的ByteBuffer对象依然存活着
那么那一块直接内存我们就不会被回收(只会等到真正的垃圾回收才会清理)
导致直接内存长时间无法释放
我们的解决方法:
1.还是手动的使用Unsafe来管理直接内存了