dba成长随笔 -- 深入了解Oracle
Oracle cmd 下登录 sqlplus / as sysdba
Cmd 下关闭实例 shutdown abort; 不安全关闭
shutdown immediate; 安全关闭
Cmd 下打开数据库 startup;
Cmd 下重启 startup force;
startup nomount; 仅仅启动实例不启动控制文件
alter database mount; 修改数据库为 mount状态,会寻找控制文件
alter database open; 修改数据库为 open状态,校验数据和控制文件,发生实例恢复
column username format a10;设置显示时段长度
深入了解oracle
Oracle整体架构
Oracle组成
实例Instance 、 数据文件 Database 、其它组成部分
实例:实例内存区与进程两部分组成
数据文件:控制文件、重做文件、数据文件
其它组成部分:参数文件、密码文件、归档文件
Instance的内存区组成
SGA数据共享资源内存区:Shared Pool、Database buffer Cache、Redo Log Buffer、其它
Shared Pool:sql语句解析区
Library cache 保存可执行的sql及PL/SQL包,以及sql的执行计划和一些控制结构;
Data dictionary cache 存放Oracle数据字典信息,供sql解析的过程需要被频繁的访问到;
Server result cache 这部分保留了sql查询的结果集,这样对于后续相同的查询,直接使用现有的结果集;由参数 RESUT_CACHE_MOD设定;
默认manual,RESULT_CACHE 用hint启用;Force :所有查询有效,会消耗更多的shared_pool 资源
| SELECT /*+ RESULT_CACHE */ emp.deptno,AVG(emp.sal) FROM emp GROUP BY emp.deptno; |
Reserved pool
Database buffer Cache:数据缓冲区
Default pool 正常情况下,数据块存放的内存区域
Keep pool 这个区域用于将一些数据始终固定在内存中
Recycle pool 存放一些不经常使用的数据块,避免这些数据块在Default pool 中占据空间
2K、4K、16k、32k 用于存放不是标准大小(8K)表空间的数据块信息。
如建表空间时:
| create tablespace ts_16k blocksize 16k datafile 'D:\app\Tech-Winning\oradata\orcl11\ts_16k.dbf'size 1M ; show parameter k_cache_size进行查看 |
Redo Log Buffer:重做日志区
Java Pool :保存会话运行的Java代码
Large Pool :对数据的处理使用LRU算法,比shared pool 更高效的内存收取方式
Streams Pool sql共享区:存放流的信息
Fixed SGA
SGA区发生的事件:1.解析sql、生成执行计划、执行计划被共享
2.数据这里被访问、被共享
3.重做日志这里产生(几秒刷新一次、或者commit立即刷新)
-用于存放数据信息和数据控制信息;
-这些内存信息被所有进程共享;
PGA会话私有内存区:Sort Area(内存排序不够再用临时表空间排序)、Hash Area、…
PGA区发生的事件:
- 私有sql区:绑定变量值、运行时期内存结构信息等数据
- 游标、SQL区
- 会话内存:基于排序操作(order by、group by、窗口函数..)
查看PGA大小select sum(PGA_ALLOC_MEM) from v$process;
-它的数据和控制信息为某个进程独有;
-PGA属于单个内存服务端进程或后台进程
UGA 保存和当前会话相关的信息,比如pl/sql中的变量
SCA oracl自身软件存放代码的一个区
Instance的后台进程
查看后台进程数量:select count(1) from v$bgprocess;
pmon :处理会话,作用:回滚事务、释放锁及其它资源、重启调度器、在监听器注册服务信息
主要工作:
- 对异常状态的进行进行清理(进程异常终止、会话被杀掉、事务超过空闲时间、网络连接超时)
- 将实例信息注册到监听器
Pmon进程清理工作:
回滚未提交的事务、释放事务相关的资源
.重置undo数据块上的事务表的状态为inactive
.释放事务产生的锁
.从v$session中清除异常终止的会话ID
smon :作用:实例恢复(前滚、打开数据库、回滚)、清理和释放临时段上的数据、合并连续空闲的extent、维护回滚段的oline,offline 以及空间的回收
dbwn : 内存中写到磁盘脏数据的进程
负责将buffer cache 中的脏数据(修改过的数据)块写到磁盘上,由于数据块在磁盘上的位置不连续,这个过程会比较耗时
触发条件 1:server process 无法在buffer cache 中找到可用的buffer
2:DBWn接到 checkpoint的指令
可以设置多个DBWn进程加快数据写入速度,-- DB_WRITER_PROCESSES
lgwr : 写重做日志的进程
负责将log Buffer 中的数据顺序的写到磁盘上的online redo file ,由于是顺序的写入,效率比DBWn高很多
触发条件:
.用户提交事务
.日志切换
.最后一次提交经过3秒
.Redo log buffer 容量达到1/3或者达到1M的 redo 数据
.DBWn进程把脏数据写入磁盘之前,必须保证这些脏数据已经把日志写入磁盘上了,不然会通知LGWr进程写日志信息
ckpt : 通知启用 DBWn进程写脏数据、所有文件进行周期性同步
目的:减少数据恢复时间、让内存的脏数据及时写到磁盘、在数据库安全关闭时,保证所有提交的数据写到磁盘
Checkpoint的触发:
- database checkpoint
.Consisten database shutdown 数据库一致性(安全)的关闭
.Alter system checkpoint statement 执行Alter system checkpoint语句
.Oline redo log switch 切换日志 alter system switch logfile;
.Alter database begin backup ststement 数据库备份
- Tablespace and data file checkpoint
. tablespace read only 表空间设置成只读时
.tablespace offline normal 表空间正常下线的时候
Shrinking a data file 数据文件收缩
Alter tablespace begin backup 表空间的备份
- Incremental checkpoints 增量checkpoint
Server Process :接收客户端 sql请求 、完成sql的分析,执行计划和sql执行过程
ARCn : 归档进程,当数据库处于归档模式时,ARCn负责将online redo file 归档到目标存储位置,用于数据库的恢复,当在线日志切换时,会触发ARCn进程将在线日志文件归档。
在data guard 下将日志向远程的服务器发送。
Checkpoint 和 commit 对比
- Commit 提交事务修改的数据产生日志,必须立刻写到磁盘上
-刷新到磁盘的日志包含未提交的日志;(保护数据)
- Checkpoint 将脏数据写到磁盘上,减少数据库启动时恢复时间,为data buffer 提供空闲空间
-写到磁盘的数据并不一定是提交的;而数据生效与否由redo作为控制
-数据写到磁盘前,这部分数据对应的日志,必须提前写到磁盘上
-如果是 alter system checkpoint 将只会把commited 的数据块写到磁盘上
- 安全关闭数据库,所有的commited 的数据会写到磁盘上
数据字典
查询数据库所有字典
Select * from dict;
Oracle数据字典的基表
Select * from v$fixed_table;
常用数据字典视图—静态视图
user_tables 用户下面有那些表信息;其中分区表的表空间字段信息为空;
user_tab_partitions; 用户下有那些分区的信息;
user_indexes 用户下有那些索引信息;
user_ind_partitions 用户的分区索引信息;
user_segments 用户下的段对象(分配了空间的对象);
dba_data_files 数据库下包含的表空间、表空间下的数据库文件、文件的大小
dba_temp_files 数据库下包含的临时表空间;
常用数据字典视图—动态视图
v$instance 实例相关的信息
v$database 数据库相关信息
v$log + v$logfile redo log 相关信息
v$session 会话相关信息比如sql_id,在性能优化时候经常使用
v$sql 根据sql_id 查询正在执行的sql
v$mystat 查询当前会话的sid
v$session_wait 会话的等待事件
v$lock + v$locked_object 阻塞、锁视图
v$transaction 事务相关信息
set autotrace 参数详解
| 1 |
SET AUTOTRACE OFF |
此为默认值,即关闭Autotrace |
| 2 |
SET AUTOTRACE ON EXPLAIN |
只显示执行计划 |
| 3 |
SET AUTOTRACE ON STATISTICS |
只显示执行的统计信息 |
| 4 |
SET AUTOTRACE ON |
包含2,3两项内容 |
| 5 |
SET AUTOTRACE TRACEONLY |
与ON相似,但不显示语句的执行 |
说明:traceonly不显示查询结果
前三个参数{OFF | ON | TRACE[ONLY]} 里必需选择一个,而且只能选择一个
后两个参数[EXP[LAIN]] [STAT[ISTICS]]是可选的,也可以都不选择
TRACE[ONLY]的含意是只显示explain和statistic,不显示SQL的结果集,带TRACE[ONLY]的参数的以下的4,5,6最常用的是第4种
只要带上off,后面的[EXP[LAIN]] [STAT[ISTICS]]就无效了
据备份与恢复
Alter system checkpoint; 立即将所有事务刷入磁盘;
Commit --lgwr 事务相关操作,保证事务的安全;只是其他会话可以看见
Checkpoint --dbwr 数据相关操作,保证数据的安全,将修改(无论提交与否)的数据写到磁盘上;
实例恢复
1.什么时候发生: 1. Shutdown abort; 2 .数据库异常down掉(死机,掉电)3实例异常终止
2.实例恢复是一个自动的过程,不需要人工干预
3.oracle在打开数据库时(alter database open),会检查每个文件头上的信息(SCN),并同控制文件中相应的信息(SCN)比较,如果不一致,则进行实例恢复;
实例恢复的过程
- 前滚:读取状态未current和active状态的日志,将发生crash时,没有来得及写到磁盘上的数据块,使用redo的信息恢复。
- 打开数据库(alter database open)
- 回滚:将没有提交的事务进行回滚
介质恢复:(基于备份集)
当发生以下情况时,实例恢复无效,需要进行介质恢复
- 数据文件丢失,损坏
- 在线日志文件(online redo)丢失,损坏。
- 数据文件太旧(比如从一个备份集恢复过来的文件)
- 文件太新(比如其它所有文件都是从备份中恢复过来的)
介质恢复与实例恢复的区别
介质恢复需要人工进行指导
恢复过程
- 随着日志切换,产生了多个归档日志
- 比如在SCN为5的时候做了一次全库备份(数据文件、控制文件)
- 如果在scn=9时候,编号4的数据文件缺失、或者损坏
- Shutdown、startup mount、再将备份中的编号4的文件还原(Restore)到对应的位置
- 此时还原回去4号文件对应的SCN=5;对比控制文件为9存在差异,需要进行介质恢复
- 在进行介质恢复(recover);通过归档文件中的scn为6、7的文件进行恢复
- 再通过redo log file 中恢复SCN=8、9 号的日志文件
Oracl是如何开始恢复的---SCN
四个SCN
- 系统SCN --- system SCN --保存在控制文件中
select checkpoint_change# from v$database;
- 控制文件记录的数据文件SCN---datafile SCN --保存在控制文件中
Select name,checkpoint_change# from v$datafile;
- 数据文件自己头部的SCN---start SCN --保存在数据文件中
Select name, checkpoint_change# from v$datafile_header;
- 控制文件中记录的数据文件结束(数据库正常关闭时)的SCN – end SCN --保存在控制文件中
Select name,last_change# from v$datafile;
无需恢复
当System Checkpoint SCN,Datafile Checkpoint SCN 和Start SCN号都相同时,数据库可以正常启动,不需要做介质恢复。
介质恢复 --- media recovery
当System Checkpoint SCN,Datafile Checkpoint SCN 和Start SCN号有一个不相同时候,需要进行介质恢复
实例恢复 --- instance recovery
当控制文件中记录文件的end SCN为null时,需要进行实例恢复
从哪里开始恢复
在某一点,在之前的所有数据,oracle都已经成功写到磁盘上了。
这一点称为 full checkpoint (8i以前); full checkpoint 很消耗资源
Mini checkpoints(现在); 3秒钟后。更多的日志写到log file ,checkpoint 点也同时向前移动,dbwr负责将这部分数据写入磁盘
当oracle确认需要进行实例恢复时,从控制文件中取得最后一次checkpoint 点作为恢复的起点(low rba),一直恢复到redo最后一次写入磁盘的位置(on disk rba)
数据字典组成---两类视图
静态数据字典: dba_*、all_*、user_*
动态数据字典:v$*、gv$*
重做日志和日志挖掘
日志文件的四种状态
UNUSED: 新添加的日志组,还没有使用 ;
INACTIVE: 日志组对应的脏块已经从 data buffer 写入到 data file ,可以覆盖 ;
ACTIVE: 日志组对应的脏块还没有从 data buffer 写入到 data file,不能被覆盖 ;
CURRENT: 当前日志组,日志组对应的脏块还没有从 data buffer 写入到 data file,不能被覆盖;
Redo的机制
SCN System Commit Number
Scn是数据库中顺序增长的一个数字,用来精准的区别操作的先后顺序,比如Commit,rollback or checkpoint
日志文件结构
日志文件使用的是操作系统块大小
-通常为 512 bytes
-格式依赖于 操作系统和Oracle版本
Redo 日志组成
- 日志文件头
- 日志文件记录 Redo record
| Block 0 文件头 |
Block 1 Redo 头 |
Block2 Redo record 1 |
Block3 Redo record 2或3 |
Block 4 Redo record 3或4 |
…. |
Block M Redo record N |
Redo Record
1.一个Redo Record 记录包括 Redo记录头 和 一个或多个 改变向量
2.每个redo Record 包含每个原子改变的undo 和 redo
3.某些改动不需要redo(临时表、直接加载…)
| Redo Record Header |
Change #1 |
Change #2 |
Change #3 |
… |
Change #n |
日志挖掘---logminer
用途:对在线的redo,归档日志进行分析
目的:1.修正误操作 2. 审计(看是谁做的错误操作)
Dbms_logmnr
- 可以基于日志文件分析(一个或多个)
- 可以基于时间段分析
- 可以基于scn分析
| 步骤 select * from v$log ; 查出当前使用的日志文件 命令模式下执行 EXEC dbms_logmnr.add_logfile(LogFileName => 'D:\app\Tech-Winning\oradata\orcl11\REDO01.LOG',Options => dbms_logmnr.new); 命令模式下执行 exec dbms_logmnr.start_logmnr(startScn => 1433192,endScn =>1433247,Options => dbms_logmnr.DICT_FROM_ONLINE_CATALOG); 查看解析完成的日志 select operation,sql_redo,sql_undo from v$logmnr_contents; |
DML 与DDL 中产生日志的区别
DML 会产生redo、undo日志,而DDL只会产生redo日志
使用附加日志信息
Alter database add supplemental log data;(强制Oracle 在写日志时候将用户名、会话名等附加信息写进日志)
回滚段及其用途—Undo
Undo 和 redo
Undo 用于撤销修改的操作(事务回滚)
Redo 用于数据修改重演一遍(恢复)
Undo的目的
事务的回滚
实例恢复(非正常关闭的数据库,将未提交的事务进行回滚)
提供查询的一致性读(查询开始那一刻的状态数据库的数据)
回滚段的逻辑结构
循环的结构,采用LRU算法进行回滚段块的清理
回滚段空间使用机制--增长
当下一个回滚段不允许覆盖还处于 Active状态时,会申请添加一个新的回滚段。
一致性读
优点: DML不再阻塞读
自动管理 AUM
Oracle 9i之前,需要手工创建回滚段
Create rollback segment rbs1 tablespace xxx;
--弊端 考虑回滚段的个数
考虑回滚段的存储设置
9i开始使用自动管理回滚段 AUM
优点:oracle 根据业务需求,自动创建新的回滚段或者多的回滚段离线
Oracle 自动管理UNDO数据的保留时间(需要预先设置)
Undo的相关参数
| undo_management |
string |
AUTO |
| undo_retention |
integer |
7200 |
| undo_tablespace |
string |
UNDOTBS1 |
注意:undo_retention 是一个动态调整的参数,同时,oracle无法保证在这时间内的undo数据不被覆盖,当undo空间不足时,Oracle将覆盖即使未过保留期的数据以释放空间。
强制保留undo_retention时间内的数据
只要时间没到,不允许覆盖
设置undo tablespace 为GUARANTEE属性
Alter tablespace undotbs1 retention GUARANTEE;
Alter tablespace undotbs1 retention noGUARANTEE;
Undo相关视图
v$rollname , v$rollstat
select a.usn,b.name,extents,rssize,shrinks,wraps,extends,status from v$rollname b, v$rollstat a where a.usn=b.usn;
usn:回滚段序号,可以手工使其online或者offline
extents:有多少个回滚段
rssize:回滚段尺寸
shrinks:回滚段回收的次数
wraps:事务从一个exted切换到下一个exted成为一个wraps
extends:扩展了多少次
v$undostat
保留四天数据,每次快照10分钟
再早的数据保留在DBA_HIST_ UNDOSTAT视图中
| select to_char(t.begin_time,'hh24:mi'),to_char(t.end_time,'hh24:mi'), t.undoblks,t.txncount,t.maxquerylen,t.maxqueryid,t.maxconcurrency,t.ssolderrcnt,t.nospaceerrcnt,t.activeblks,t.tuned_undoretention from v$undostat t |
数据结构
Oracle的数据存储结构
表空间 -- oracle中追打的逻辑存储单位
数据文件-- 表空间物理存储载体
段 -- oracle中所有占用空间的对象的总称
Extent – 段的组成单位
数据块 -- extent的组成单位,是oracle存储和数据操作的最小单位
Oracle的存储逻辑
一个段有多个extent分布在不同的数据文件上;
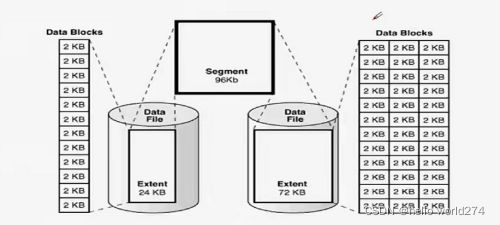
Oracle 数据块大小
- 2K、4k、8k(默认)、16k(32位操作系统)、32k(64位操作系统)
- 数据块大小的意义
对于大的对象操作时设置成大的数据块,能减少读的次数,提高性能
数据块--结构
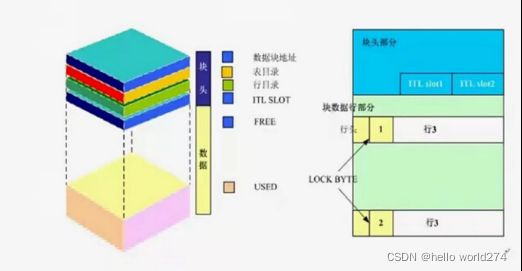
ITL SLOT:数据块头部的事物槽列表;
数据块 -- 结构 -- 行
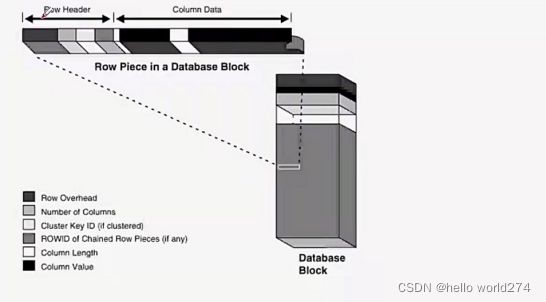
数据块 -- 结构 -- 行 -- Rowid
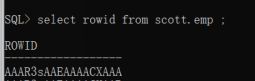
| AAAR3s |
AAE |
AAAACX |
AAA |
| Data obuject number |
relative file number |
Block number |
Row number |
DBMS_ROWID 包

数据块的存储属性
Pctfree
当数据块中的数据量达到这个值时,将不允许继续插入数据
Pctused
当数据块中数据占用空间小于这个比例时,数据块会再次使用
行链接和行迁移
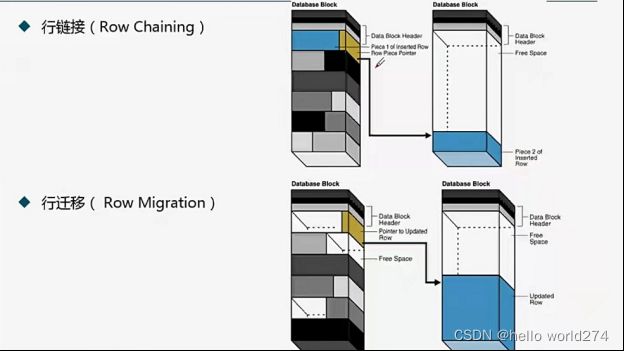
行链接:一个数据块放不下,有个指针将指向剩余数据存放的数据块
当我们在插入一行(比较大的字段、对象)到数据块中,Oracle没法将其全部插入,所以将其数据分散到一个或多个数据块中,然后保存指向的链接
行迁移: 将数据完全存放在另一个数据块,一个指针指向它
通常发生在update中,当数据块空间不够时,将数据完全迁移到另一个块中,再通过指针指过去
行链接和行迁移都有影响oracle的IO读写,所以可以通过以下方式减少行链接和行迁移:
增大数据块,可以减少行链接
设置合理的PCTFREE,可以减少行迁移
块数据空闲空间的合并
- 可以手工对数据块进行空闲空间合并,Oracle会在下一情况自动合并空闲空间
- 当一个插入或者跟新操作的行在一个数据块中有足够的空闲空间
- 并且空闲空间是碎片状态,无法满足一行数据的使用
- Oracle不是总是自动整理碎片的原因是,这将导致一定的系统资源开销
索引数据块的整理
alter index index_name coalesce;--合并同一个branch的数据块
alter index index_name rebuild ;--重建整个索引,一般需要2倍的index大小的空间。而且需要排序。
coalesce index比rebuild index产生更多的redo size
oracle的读操作
- 逻辑读 从内存中读取数据块
- 物理读 从磁盘读取数据
alter system flush buffer_cache; 刷新缓存
单块读和多块读
单块读:每次从磁盘读取一个数据块称为单块读
多块读:每次从磁盘读取多个数据块
每次读取的数据块由参数db_file_multiblock_read_count确定。
LRU
LRU使用中部插入算法,数据从中部插入列表
LRU列表分为热端和冷端
中部插入点称为冷端头部,热端尾部
数据块 touch count
- 每个buffer(内存数据块)头,包含如下信息
- Touch count
- timestamp
- 表示在每三秒钟内,数据块自从以下两种情况以来,被接触(touch)次数
- 数据块最后一次被读入内存
- Touch count被重置
- 当buffer到达冷端的最尾端时
- 如果touch count >=2 ,buffer将被转移到热端并且touch置0
- 否则将被作为空闲buffer被使用
单数据块读
读一个新磁盘数据块时,将冷端尾部的数据块取出存放读出来的磁盘数据,再将其放到中间;如果发现最冷端的数据块 touch数 >=2,说明这个数据可能还会被用这时候将其touch数改为0并存放到热端。
一致性读(构造数据库的多版本)
查询一个sql并附带之前的SCN,如果SCN号与buffer cache中的SCN一致,则直接读取;若不一致,则在undo里面找到对应版本的数据;再将最冷端touch<2的数据块拿出来重构存放该SCN对应的数据;这时候也叫做oracle的多版本。
多数据块读
首先找db_file_multiblock_read_count的值对应个数的可用的buffer,用来装从磁盘上读过来的多个数据块,还是插在中间;这时候读取插入的第一个数据块,读取完后将其放到最冷端;读取第2个后也放到最末端;所有数据块读取完并放到最冷端后,将其用以下次的多数据块读。
Extent
由一组连续的数据块组成,多个extent构成一个段;
当一个段被创建时候,Oracle会为其分配一个初始的extent
当初始extent满了后,oracle会继续分配后续的extents;
一个段的extents可以分布在多个数据文件上
段 -- segment
凡是分配了空间的对象,都称之为段。
注意:
但是当一个表有多个分区时候,比如有四个分区;那么这个表就不是段,而对应数据载体的4个分区分别为4个段。同理索引分区下的分区才是段。
当一个表的某个字段为大对象(LOB)是,则该大对象单独的一个段
段分类
- 数据段
- 临时段(临时表空间)
- 排序,hash,merge…(需要一个中间数据处理区)
创建索引、order by ,hash join ,merge join …
-
- 只有在内存空间(sort area)不足时,oracle才会在临时表空间上创建临时段
- 临时段上的操作不记录 redo log
临时表
临时表是临时段中的一种;
Oracle 的临时表只存在于某个会话或者事务的生命周期里,此时临时表中的数据只对当前这个会话可见。
临时表进程被用于存放图个操作的中间数据(数据处理的中间环节)
临时表由于不产生redo,能够提高数据的操纵性能。
创建临时表语法:
create global temporary table 临时表名
on commit delete rows /on commit preserve rows
(colum,colum,…);
on commit delete rows :基于事务,提交后即清空临时表
on commit preserve rows:基于会话,会话结束时中间表才清空
- 回滚段
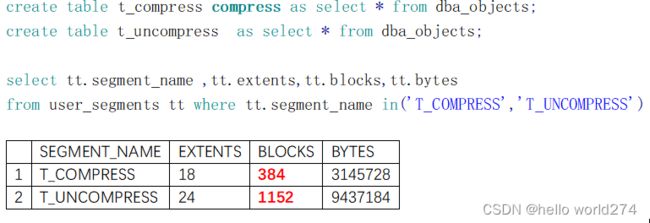
段数据的压缩
Oracle允许对段进行压缩
优点:1. 减少储存空间
···· 2. 减少处理的数据块
- 减少内存占用
- 提高I/O速度
- 提高查询效率
缺点:因为额外对数据做处理,在数据插入时,会消耗更多的资源和时间
压缩的效果
段压缩的级别
表级(索引)
Alter table t_compress nocompress; 将压缩表改成不压缩
Alter table t_uncompress move compress; 将未压缩状态的表改成压缩状态
查看表的压缩状态
select table_name , compression
from user_tables ttt
where ttt.table_name in('T_COMPRESS','T_UNCOMPRESS')表空间级别
将表空间的属性加上 compress;alter tablespace users default compress;
然后创建表时,指定对应的表空间;这样这张表也是压缩的表
Create table t_compress tablespace users as select * from dba_objects;
段的存储管理(数据块集的管理)
MSSM -- Manual Segment Space Managenet
手工设定对象的存储参数
PCTFREE、PCTUSED、FREELISTS…
freelists :将空闲空间拆成多个,用于增大并发响应的能力
优点:给予dba更大的空间管理余地
对于一些数据块操作非常敏感的场景依然有用
不足:设置参数多
参数设定值困难

大文件表空间
普通的数据文件,受到数据块的限制
每个数据文件最多只包含222-1(4M)个数据块;由于数据块默认8k,则该文件最多32G;
大数据文件,可以使用232(4G)个数据块;8k---32T
大数据文件优势: 减少数据库的数据文件个数
方便文件管理,不需要人工干预表空间文件大小
减少数据库对文件头同步的开销
ASSM – Automatic Segment Space Managenet
通过位图方式管理空间
Oracle自动设定对象的存储参数
只可手工设定PCTFREE参数,其它由Oracle自动设定
优势:简化管理
增大并发度
RAC环境下改善并发性能
劣势: 全表扫描
大数据加载导致性能下降
影响索引的集成因子
表空间的管理方式
本地管理表空间(local)
优点:自动跟踪表空间上数据的变化并进行调整
自动确定表空间上的extent的大小
字典管理表空间(已经废弃)(dictionary)
表空间的存储信息记录再oracle的system表空间中,凡是DML操作,都需要访问system表空间和相关的视图
表空间的Extent管理方式
- Autoallocate 自动管理
自动根据数据的储存情况,自动调整分配下一次extent的大小(bytes)
- Uniform 固定
统一extent的尺寸

查看表空间、段、extent管理方式

表空间的默认存储属性
首先指定一个表空间默认的存放位置的路径
show parameter db_create_file_dest;
创建表空间的时候只指定一个名字
Create tablespace test_mr;
默认属性如下:

表空间属性—段属性
段对象的存储属性可以直接从所在的表空间继承过来
也可以单独设定自己的属性
Create table t storage(initial 2m next 2m) tablespace test select * from dba_objects;
指定了test表空间,但是修改了继承过来的属性
ASM 自动存储管理
Oracle文件系统的历史
- 操作系统 – 数据文件 由Oracle访问文件经过操作系统,所以其性能优点低
- 裸设备 直接访问物理设备,不经过操作系统;由于每个文件是一个设备,不方便管理。优点:性能更好
- ASM 介于文件系统和裸设备之间;Oracle经过优化相当于自己优化后的文件系统
- OCFS 集群的文件系统
Oracle备份方式
Rman(物理备份)
--数据库、表空间、数据文件、数据块
Exp,exodp(逻辑备份)
--用户,数据库对象(表,分区)
只读表空间+传递表空间
Data guard
Rman备份对象
数据文件、控制文件、参数文件、归档文件
- Cmd 下 rman target / ;进入RMAN 命令模式
- backup database; 全库备份
backup database format='D:\oracle\backup\%d_%s.bak'; 备份至指定路径
list backupset; 查看备份内容
crosscheck backup; →查出无效的备份
delete noprompt expired backup; →删除无效的备份
show all; 可以自己制定策略,保留几份备份,默认保存一份有效备份,可以show all 查看到:
configure ‘参数名’ ‘参数值’
report obsolete ; 查看过期的备份:
delete noprompt obsolete ; 删除不需要的备份
delete backup; 删除全部备份
delete obsolete 删除过期的备份
delete backupset 19; 删除特定备份片
rman参数配置链接
http://docs.oracle.com/cd/E11882_01/backup.112/e10643/rcmsynta010.htm#RCMRF113
表空间的备份与恢复,数据库状态为mount;状态:
- backup tablespace users format='D:\oracle\backup2\%d_%s.bak'; 备份指定的表空间;
- recover tablespace users format='D:\oracle\backup2\%d_%s.bak';
数据文件备份
backup as copy datafile 4 format='D:\oracle\backup3\%d_%s.bak';
差异与累积与备份级别
默认备份级别4级(0,1,2,3,4)
差异增量备份(oracl默认增量备份方式)
N级备份,备份n级或更低级别备份以来更改过的所有数据块
累积增量备份
N级备份,备份n-1级或更低级别备份以来更改过的所有数据块
增量备份
Backup incremental level 0 database; 全库备份
Backup incremental level 1 database; 若没有level0备份自动创建level0备份
增量备份的恢复
原则: 最近的一次0级备份+最近一次1级备份+最近一次2级备份+归档+online redo
RMAN恢复
Restore datafile 4;
Recover datafile 4;
Rman恢复窗口---recover window
通过设置恢复窗口,既可以满足数据安全,也可以节省存储空间,删除过期的备份数据。
Rman恢复目录数据库—catalog database

闪回
alter system set log_archive_dest_1="location=/data/u01/app/oracle/archive";
alter database archivelog; 开启归档
show parameter db_recovery_file_dest; 查看闪回区大小及位置
alter database flashback off [on]; 关闭或开启闪回
select flashback_on from v$database ; 是否开启闪回
show parameter undo; 闪回参数
假设闪存区3G
undo_retention:900 ,超过闪存区的数据 必须在900秒内闪回
alter system set undo_retention=7200 scope = both ;
both 当前有效重启也有效| memory 当前数据库有效,重启无效| spfile 当前数据库无效,重启有效。
数据库的闪回 依赖于归档和日志文件
不同于查询闪回和归档闪回的另一种闪回机制
需要配置闪回区区域
记录数据块的修改,称为flashback logs
通过后台进程RVWR来工作
show parameter db_recovery_file_dest; 查看闪回区大小及位置
时间转scn
- 基于SCN的闪回 flashback database to scn 1177813;
- 基于时间的闪回 flashback database to ‘2:05 PM’
闪回后报错ORA-01589: 要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项则需要alter database open resetlogs;
Alter system set db_flashback_retention_target=2880 scope=both; 设置数据库闪回保留时长2880分钟。
数据库闪回相关的时间和scn
当前scn
Select current_scn from v$database;
允许闪回最早的scn
Select oldest_flashback_scn from v$flashback_database_log;
允许闪回最早时间
Select oldest_flashback_time from v$flashback_database_log;
闪回归档
用实际的数据来记录数据的修改,让恢复永不过期;专有的后台进程fbda异步的扑获数据。
创建用于存放的闪回数据的表空间
create tablespace FLUSHBACK_DATA_TABLESPACE
logging
datafile '/data/u01/app/oracle/oradata/orcl/flushback_data_tablespace.dbf'
size 2G
autoextend on
next 2G
maxsize unlimited
extent management local
segment space management auto;
创建闪回归档策略
create flashback archive default fb_a1
tablespace flushback_data_tablespace
quota 200M
retention 30 day ; -- 保留30天的策略,过了时间自动删除
授予用户闪回归档的权限
grant flashback archive on fb_a1 to scott;
创建表时开启闪回归档,表的所有操作将记录到该闪回的分区
create table emp_sal (
empno number,
ename varchar2(20),
sal number)
flashback archive;常用的视图:
select flashback_archive_name,tablespace_name,quota_in_mb
from dba_flashback_archive_ts;
select flashback_archive_name,to_char(create_time,'yyyy-mm-dd') created ,
retention_in_days,status from dba_flashback_archive;
select table_name,flashback_archive_name,archive_table_name,status
from dba_flashback_archive_tables ;
闪回表
Flashback table tablename to before drop; 闪回删除前,类似于回收站
查看回收站 Show recyclebin;
清空回收站 purge recyclebin;
DML闪回
alter table testfb enable row movement; 开启表的行移动
flashback table testfb to timestamp to_timestamp('2020-12-28 21:18:00','yyyy-mm-dd hh24:mi:ss'); 将表闪回到指定的时间的状态。
Flashback table testfb to scn 6944918;
闪回查询 基于undo
- 基于时间的查询闪回:
Select * from emp2 as of timestamp sysdate-5/1440;
- 基于SCN的查询闪回
Select * from emp2 as of scn 34197;
闪回版本查询 基于undo
查询某一段时间所有的操作
--查询这段时间的所有事务操作
Select versions_xid xid,
versions_starttime starttime,
versions_endtime endtime,
versions_operation operation,
empno from scott.emp_bak versions between timestamp minvalue and maxvalue;闪回事务查询基于undo的查询
alter database add supplemental log data;
alter database add supplemental log data(primary key) columns; 启用对DML更改引用的列值和主键值的日志记录
select operation,undo_sql ,logon_user from flashback_transaction_query
where logon_user='SCOTT' and xid=hextoraw('090015004F030000');
事务
事务的属性-ACID
原子性 同时成功或者同时失败
一致性 指事务不能违反对于数据的约束、唯一等等
隔离性
持久性
并发与数据的读取
脏读:一个事务读取另一个未提交事务的数据的值
不可重复度: 在一个事务过程中,同样的数据被2次读取,并得到不同的值,称为不可重复读。
幻读:在一个事务中,同样的sql执行两次时,得到的结果集不同。
事务隔离等级(ANSI定义的等级)
| 事务隔离等级 |
脏读 |
不可重复读 |
幻读 |
并发性/查询结果 |
| Read uncommitted |
Y |
Y |
Y |
无影响/脏 |
| Read committed |
N |
Y |
Y |
Writer block reader/查询结果在查询结束时才能确定 |
| Repeatable read |
N |
N |
Y |
Writer block reade and reader block writer /查询结果在查询结束时才能确定 |
| serializable |
N |
N |
N |
Reader block writer |
结论: read committed 无法保证读取的一致性
Repeatable read 把读了的数据块也加了锁;若未读到的数据块此时被另一个事务修改了,那么当事务读到该数据块时也是修改后的数据,而不是事务开始时候的状态数据;还有个隐患:‘死锁’。
Serializable:阻塞 事务需要访问的所有表;
事务隔离等级(oracl)
| Read committed |
oracle默认的隔离等级,对一条sql,可以保证数据的一致性读,对于一个事务,无法做到repeatable read |
|
| serializable |
只能看到事务开始时所有提交的改变以及自身的改变 |
Set transaction isolation level serializable; |
| Read-only |
只能看到事务开始时所有提交的改变,自身不允许DML操作 |
Set transaction read only |
结论
只读事务隔离等级:
不能执行任何DML操作
可以确保取得特定的时间点的数据
Serializable:
只能看到事务开始时所有提交的改变以及自身的改变
只针对DML操作的改变
DDL操作对serializable隔离等级可见(原因:ddl不产生undo)
只读事务隔离等级与一致性读的关系
- 一致性读的数据库一致性只针对单条数据
- 只读事务在整个事务过程中,所有的操作都保证数据一致性
- 都依赖undo信息保证数据一致性,因此执行时间都不宜过长,否则可能导致ora-01555错误。