第92步 深度学习图像分割:SegNet建模
基于WIN10的64位系统演示
一、写在前面
本期,我们继续学习深度学习图像分割系列的另一个模型,SegNet。
二、SegNet简介
(1)基本架构
SegNet由一个编码器网络和一个解码器网络组成,这两个网络都是卷积网络。编码器网络通常从一个预训练的VGG16网络中提取,并将其全连接层移除。解码器网络用于对从编码器网络中得到的特征进行上采样,以生成与输入图像相同大小的输出。
(2)池化索引
在编码阶段,当执行最大池化时,SegNet会记住每个池化区域的最大值的索引。在解码阶段,这些索引被用于上采样,从而提供更精确的结构重建。
(3)参数数量
由于SegNet只在编码器中使用了参数,而在解码器中使用了池化索引进行非学习上采样,所以相比其他模型如FCN,其参数数量更少。
(4)应用领域
由于其能够进行像素级的分类,SegNet特别适合于场景理解任务,如道路分割、建筑物分割等。
(5)性能
SegNet在多个基准数据集上的性能都很出色,并且由于其较少的参数和计算效率,它特别适合于需要实时响应的应用。
(6)优点
参数少,计算效率高。由于使用池化索引,能够更好地保留边界信息。
(7)缺点
尽管SegNet在多个任务上都表现得很好,但对于一些复杂的场景,它可能不如其他更复杂的模型,如U-Net或DeepLab。

三、数据源
来源于公共数据,主要目的是使用SegNet分割出电子显微镜下的细胞边缘:

数据分为训练集(train)、训练集的细胞边缘数据(label)以及验证集(test),注意哈,没有提供验证集的细胞边缘数据。因此,后面是算不出验证集的性能参数的。




四、SegNet实战:
这里,由于Pytorch并没有SegNet预训练模型,因此只能从头搭建咯。
上代码:
(a)数据读取和数据增强
import os
import numpy as np
from skimage.io import imread
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score
# 设置文件路径
data_folder = 'U-net-master\data_set'
train_images_folder = os.path.join(data_folder, 'train')
label_images_folder = os.path.join(data_folder, 'label')
test_images_folder = os.path.join(data_folder, 'test')
train_images = sorted(os.listdir(train_images_folder))
label_images = sorted(os.listdir(label_images_folder))
test_images = sorted(os.listdir(test_images_folder))
# 定义数据集类
class CustomDataset(Dataset):
def __init__(self, image_paths, mask_paths, transform=None):
self.image_paths = image_paths
self.mask_paths = mask_paths
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = imread(self.image_paths[idx])
mask = imread(self.mask_paths[idx])
mask[mask == 255] = 1
# Ensure the image has 3 channels
if len(image.shape) == 2:
image = np.stack((image,) * 3, axis=-1)
sample = {'image': image, 'mask': mask}
if self.transform:
sample = self.transform(sample)
return sample
class ToTensorAndNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, sample):
image, mask = sample['image'], sample['mask']
# Swap color axis
# numpy image: H x W x C
# torch image: C x H x W
image = image.transpose((2, 0, 1))
image = torch.from_numpy(image).float()
mask = torch.from_numpy(mask).float()
# Normalize the image
for t, m, s in zip(image, self.mean, self.std):
t.sub_(m).div_(s)
return {'image': image, 'mask': mask}
# Use the new transform for normalization
transform = ToTensorAndNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 获取数据集
train_dataset = CustomDataset(
image_paths=[os.path.join(train_images_folder, img) for img in train_images],
mask_paths=[os.path.join(label_images_folder, img) for img in label_images],
transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)解读:
其他没什么好说的,就是要注意:上述代码的数据需要人工的安排训练集和测试集。严格按照下面格式放置好各个文件,包括文件夹的命名也不要变动:

(b)SegNet建模
class SegNet(nn.Module):
def __init__(self, input_channels, output_channels):
super(SegNet, self).__init__()
# Encoder (Downsampling)
self.enc1 = self.conv_block(input_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# Decoder (Upsampling)
self.dec4 = self.upconv_block(512, 256)
self.dec3 = self.upconv_block(256, 128)
self.dec2 = self.upconv_block(128, 64)
self.final_dec = nn.ConvTranspose2d(64, output_channels, kernel_size=3, stride=2, padding=1, output_padding=1)
# Add the upsampling layer
self.final_upsample = nn.Upsample(size=(512, 512), mode='bilinear', align_corners=True)
def forward(self, x):
# Encoder
x1, idx1 = self.encode_block(x, self.enc1)
x2, idx2 = self.encode_block(x1, self.enc2)
x3, idx3 = self.encode_block(x2, self.enc3)
x4, idx4 = self.encode_block(x3, self.enc4)
# Decoder with skip connections
d4 = self.decode_block(x4, idx4, self.dec4)
d3 = self.decode_block(d4, idx3, self.dec3)
d2 = self.decode_block(d3, idx2, self.dec2)
out = self.final_dec(F.max_unpool2d(d2, idx1, kernel_size=2, stride=2))
# Apply the upsampling layer before returning
return self.final_upsample(out)
def encode_block(self, x, encoder):
x = encoder(x)
return F.max_pool2d(x, 2, return_indices=True)
def decode_block(self, x, indices, decoder):
x = F.max_unpool2d(x, indices, kernel_size=2, stride=2)
return decoder(x)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def upconv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(out_channels, out_channels, kernel_size=3, padding=1,),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 获取SegNet模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SegNet(input_channels=3, output_channels=2).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()
def calc_iou(pred, target):
# Convert prediction to boolean values and flatten
pred = (pred > 0.5).view(-1)
target = target.view(-1)
# Calculate intersection and union
intersection = torch.sum(pred & target)
union = torch.sum(pred | target)
# Avoid division by zero
iou = (intersection + 1e-8) / (union + 1e-8)
return iou.item()
# 初始化损失和IoU的历史记录列表
losses_history = []
ious_history = []
# 训练模型
epochs = 100
for epoch in range(epochs):
model.train()
running_loss = 0.0
total_iou = 0.0
for samples in train_loader:
images = samples['image'].to(device)
masks = samples['mask'].long().to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Calculate IOU
pred_masks = F.softmax(outputs, dim=1)[:, 1]
total_iou += calc_iou(pred_masks, masks)
avg_loss = running_loss / len(train_loader)
avg_iou = total_iou / len(train_loader)
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss}, IOU: {avg_iou}")
# Append to history
losses_history.append(avg_loss)
ious_history.append(avg_iou)2分钟不到:

(c)各种性能指标打印和可视化
###################################误差曲线#######################################
import matplotlib.pyplot as plt
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制训练损失和IoU
plt.figure(figsize=(12, 5))
# 绘制损失
plt.subplot(1, 2, 1)
plt.plot(losses_history, label='训练损失')
plt.title('损失随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.legend()
# 绘制IoU
plt.subplot(1, 2, 2)
plt.plot(ious_history, label='训练IoU')
plt.title('IoU随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('IoU')
plt.legend()
plt.tight_layout()
plt.show()直接看结果:

误差和IOU曲线,看起来模型收敛的不错。
##############################评价指标,对于某一个样本#######################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score
def calc_iou(y_true, y_pred):
intersection = np.logical_and(y_true, y_pred)
union = np.logical_or(y_true, y_pred)
return np.sum(intersection) / np.sum(union)
# 从数据集中获取一个样本
sample = train_dataset[0]
sample_img = sample['image'].unsqueeze(0).to(device)
sample_mask = sample['mask'].cpu().numpy()
# 使用模型进行预测
with torch.no_grad():
model.eval()
prediction = model(sample_img)['out']
# 取前景类并转为CPU
predicted_mask = prediction[0, 1].cpu().numpy()
predicted_mask = (predicted_mask > 0.5).astype(np.uint8)
# 计算ROC曲线
fpr_train, tpr_train, _ = roc_curve(sample_mask.ravel(), predicted_mask.ravel())
# 计算AUC
auc_train = auc(fpr_train, tpr_train)
# 计算其他评估指标
pixel_accuracy_train = accuracy_score(sample_mask.ravel(), predicted_mask.ravel())
iou_train = calc_iou(sample_mask, predicted_mask)
accuracy_train = accuracy_score(sample_mask.ravel(), predicted_mask.ravel())
recall_train = recall_score(sample_mask.ravel(), predicted_mask.ravel())
precision_train = precision_score(sample_mask.ravel(), predicted_mask.ravel())
f1_train = f1_score(sample_mask.ravel(), predicted_mask.ravel())
# 绘制ROC曲线
plt.figure()
plt.plot(fpr_train, tpr_train, color='blue', lw=2, label='Train ROC curve (area = %0.2f)' % auc_train)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
# 定义指标列表
metrics = [
("Pixel Accuracy", pixel_accuracy_train),
("IoU", iou_train),
("Accuracy", accuracy_train),
("Recall", recall_train),
("Precision", precision_train),
("F1 Score", f1_train)
]
# 打印表格的头部
print("+-----------------+------------+")
print("| Metric | Value |")
print("+-----------------+------------+")
# 打印每个指标的值
for metric_name, metric_value in metrics:
print(f"| {metric_name:15} | {metric_value:.6f} |")
print("+-----------------+------------+")注意哈,这个代码只是针对某一个样本的结果:

ROC曲线:这里存疑,感觉没啥意义,而且这个曲线看起来有问题,是一个三点折线。
一些性能指标,稍微解释,主要是前两个:
A)Pixel Accuracy:
定义:它是所有正确分类的像素总数与图像中所有像素的总数的比率。
计算:(正确预测的像素数量) / (所有像素数量)。
说明:这个指标评估了模型在每个像素级别上的准确性。但在某些场景中(尤其是当类别非常不平衡时),这个指标可能并不完全反映模型的表现。
B)IoU (Intersection over Union):
定义:对于每个类别,IoU 是该类别的预测结果(预测为该类别的像素)与真实标签之间的交集与并集的比率。
计算:(预测与真实标签的交集) / (预测与真实标签的并集)。
说明:它是一个很好的指标,因为它同时考虑了假阳性和假阴性,尤其在类别不平衡的情况下。
C)Accuracy:
定义:是所有正确分类的像素与所有像素的比例,通常与 Pixel Accuracy 相似。
计算:(正确预测的像素数量) / (所有像素数量)。
D)Recall (or Sensitivity or True Positive Rate):
定义:是真实正样本被正确预测的比例。
计算:(真阳性) / (真阳性 + 假阴性)。
说明:高召回率表示少数阳性样本不容易被漏掉。
E)Precision:
定义:是被预测为正的样本中实际为正的比例。
计算:(真阳性) / (真阳性 + 假阳性)。
说明:高精度表示假阳性的数量很少。
F)F1 Score:
定义:是精度和召回率的调和平均值。它考虑了假阳性和假阴性,并试图找到两者之间的平衡。
计算:2 × (精度 × 召回率) / (精度 + 召回率)。
说明:在不平衡类别的场景中,F1 Score 通常比单一的精度或召回率更有用。
##############################评价指标,对于全部训练集的样本#######################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score
# 初始化变量来存储评估指标的累积值和真实标签与预测值
total_pixel_accuracy = 0
total_iou = 0
total_accuracy = 0
total_recall = 0
total_precision = 0
total_f1 = 0
total_auc = 0
all_true_masks = []
all_predicted_masks = []
# 遍历整个训练集
for sample in train_dataset:
sample_img = sample['image'].unsqueeze(0).to(device)
sample_mask = sample['mask'].cpu().numpy()
# 使用模型进行预测
with torch.no_grad():
model.eval()
prediction = model(sample_img)['out']
# 取前景类并转为CPU
predicted_mask = prediction[0, 1].cpu().numpy()
predicted_mask = (predicted_mask > 0.5).astype(np.uint8)
# 收集真实标签和预测值
all_true_masks.extend(sample_mask.ravel())
all_predicted_masks.extend(predicted_mask.ravel())
# 计算ROC曲线和AUC
fpr_train, tpr_train, _ = roc_curve(all_true_masks, all_predicted_masks)
avg_auc = auc(fpr_train, tpr_train)
# 计算其他评估指标
avg_pixel_accuracy = accuracy_score(all_true_masks, all_predicted_masks)
avg_iou = calc_iou(np.array(all_true_masks), np.array(all_predicted_masks))
avg_accuracy = accuracy_score(all_true_masks, all_predicted_masks)
avg_recall = recall_score(all_true_masks, all_predicted_masks)
avg_precision = precision_score(all_true_masks, all_predicted_masks)
avg_f1 = f1_score(all_true_masks, all_predicted_masks)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr_train, tpr_train, color='blue', lw=2, label='Train ROC curve (area = %0.2f)' % avg_auc)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
# 打印评估指标的平均值
metrics = [
("Pixel Accuracy", avg_pixel_accuracy),
("IoU", avg_iou),
("Accuracy", avg_accuracy),
("Recall", avg_recall),
("Precision", avg_precision),
("F1 Score", avg_f1),
("AUC", avg_auc)
]
print("+-----------------+------------+")
print("| Metric | Value |")
print("+-----------------+------------+")
for metric_name, metric_value in metrics:
print(f"| {metric_name:15} | {metric_value:.6f} |")
print("+-----------------+------------+")
这个结果是针对有所训练集的:
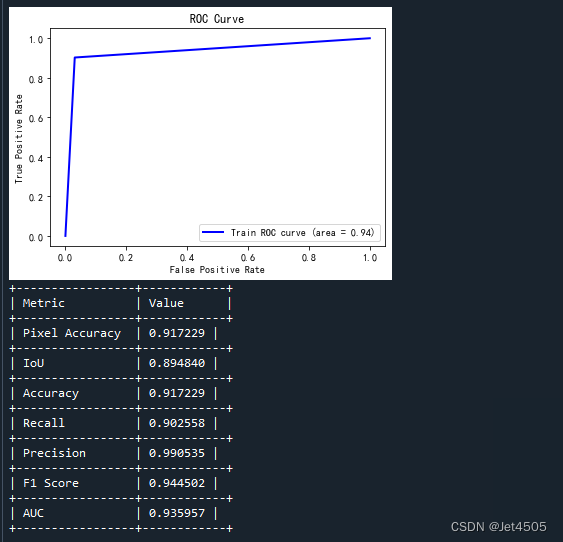
(d)查看验证集和验证集的具体分割情况
#######################看训练集图片的具体分割效果###########################################
import matplotlib.pyplot as plt
import numpy as np
# 选择一张训练集图片
img_index = 20
sample = train_dataset[img_index]
train_img = sample['image'].unsqueeze(0).to(device) # 为batch_size添加一个维度
with torch.no_grad():
model.eval()
prediction = model(train_img)['out']
# 使用阈值处理预测掩码
mask_threshold = 0.5
pred_mask = prediction[0, 1].cpu().numpy() # 选择前景类
pred_mask = (pred_mask > mask_threshold).astype(np.uint8)
# 使用matplotlib来展示原始图像、真实掩码和预测的分割图像
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.title("Original Image")
# Normalize the image to [0,1] range
denorm_img = train_img[0].permute(1, 2, 0).cpu().numpy()
denorm_img = denorm_img - denorm_img.min()
denorm_img = denorm_img / denorm_img.max()
plt.imshow(denorm_img.clip(0, 1))
plt.subplot(1, 3, 2)
plt.title("True Segmentation")
true_mask = sample['mask'].cpu().numpy()
if len(true_mask.shape) == 1: # Ensure mask is 2D
true_mask = true_mask.reshape(int(np.sqrt(true_mask.shape[0])), -1)
plt.imshow(true_mask, cmap='gray')
plt.subplot(1, 3, 3)
plt.title("Predicted Segmentation")
plt.imshow(pred_mask, cmap='gray')
plt.show()
#######################看测试集图片的具体分割效果###########################################
#看具体分割的效果
import matplotlib.pyplot as plt
test_dataset = CustomDataset(
image_paths=[os.path.join(test_images_folder, img) for img in test_images],
mask_paths=[os.path.join(label_images_folder, img) for img in label_images], # 这里我假设您的测试集的标签也在label_images_folder中
transform=transform
)
# 选择一张测试图片
img_index = 20
sample = test_dataset[img_index]
test_img = sample['image'].unsqueeze(0).to(device)
with torch.no_grad():
model.eval()
prediction = model(test_img)['out']
# 使用阈值处理预测掩码
mask_threshold = 0.5
pred_mask = prediction[0, 1].cpu().numpy()
pred_mask = (pred_mask > mask_threshold).astype(np.uint8)
# 使用matplotlib来展示原始图像、真实掩码和预测的分割图像
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.title("Original Image")
# Normalize the image to [0,1] range
denorm_img = test_img[0].permute(1, 2, 0).cpu().numpy()
denorm_img = denorm_img - denorm_img.min()
denorm_img = denorm_img / denorm_img.max()
plt.imshow(denorm_img.clip(0, 1))
plt.subplot(1, 3, 3)
plt.title("Predicted Segmentation")
plt.imshow(pred_mask, cmap='gray')
plt.show()查看训练集分割效果:

查看验证集分割效果(验证集没有label,所以中间是空的):

总体来看,勉强过关,收工!
五、写在后面
略~
六、数据
链接:https://pan.baidu.com/s/1Cb78MwfSBfLwlpIT0X3q9Q?pwd=u1q1
提取码:u1q1