Mysql高级语句
实验准备:
create table info(
id int (4) primary key,
name varchar(10) not null,
score decimal(5,2),
address varchar(20),
sex char(3) not null
);
order by排序查询
对表进行排序查看
ASC:升序排列,默认就是升序,可以不加
desc:降序排列
语法:
SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
例:
按照id降序排列姓名
select id,name from info order by id desc;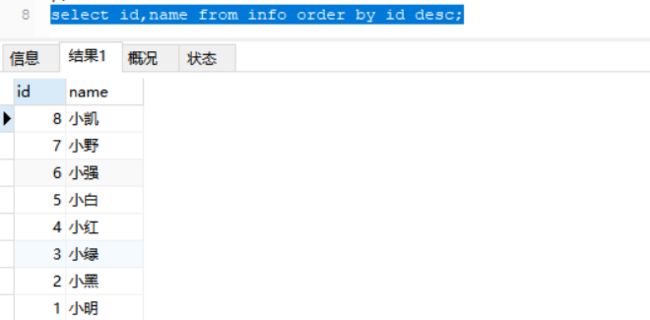
order by结合where条件过滤
例:
当address为'南京西路'时,根据成绩进行降序排列姓名和分数
select name,score from info where address='南京西路' order by score desc;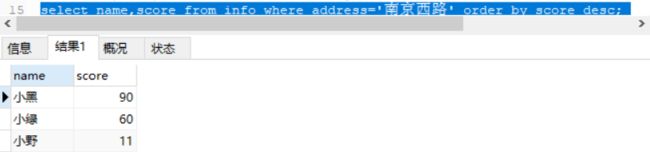
例:
当性别为女时,按照id和score降序排列出id、name、score
select id,name,score from info where sex='女' order by id desc,score desc;
and、or区间判断查询
用and或者or进行条件判断
and:且
or:或
例:
查找score大于70并且小于等于90的所有数据
select * from info where score > 70 and score <= 90;
例:
筛选出score大于90或者小于80的全部数据
select *from info where score < 80 or score > 90;
distinct去重查询
例:
降重查看表中所有的address
select distinct address from info;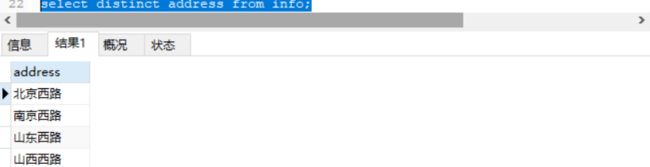
聚合函数
| 聚合函数 | 含义 |
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum() | 返回指定列的所有值之和 |
group by
group by对结果分组查询
一般和聚合函数结合使用,分组时可以按照一个字段,也可以按照多个字段对结果进行分组处理
count ():统计
例:
对性别分组,统计出成绩大于等于80的人数
select count(name),sex from info where score >= 80 group by sex ;
sum():列值相加求和
例:
对address分组,对score这一列进行求和
select sum(score),address from info group by address;
avg():列值求平均数
例:
对性别分组,算出男生和女生的平均成绩
select avg(score),sex from info group by sex;
max():过滤出列的最大值
例:
对性别分组,求出男生组和女生组的最高分
select max(score),name,sex from info group by sex;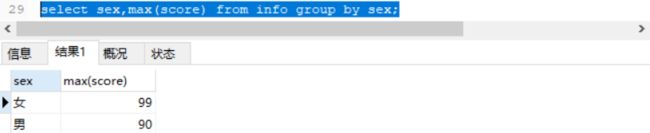
min():过滤出列的最小值
例:
对address分组,筛选出此地的最低分
select address,min(score) from info group by address;
group by实现条件过滤
例:
对address进行分组,对平均分数大于60的组根据平均分数进行倒序排列
select avg(score),address from info group by address having avg(score) > 60 order by avg(score) desc;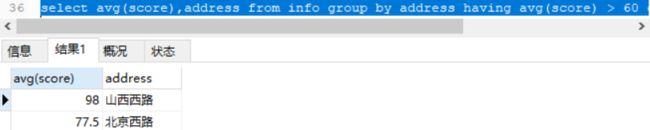
limit限制输出
例:
只查看表的前三行
select * from info limit 3;
例:
查看表的第6-8行
select * from info limit 5-7;
#注意,此条命令也可以表示为查看第6行之后的7行,但是没有这么多条数据
若数据足够,表示为查看第6行之后的7行的优先级高
通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关的结果查询出来
通配符和like一起使用,要使用where语句一起完成查询
%:表示可有可无,0、1、多个
_:表示单个字符
例:
查询address以'山'为开头的数据
select * from info where address like '山%';
#'%山%'表示查询内容包含'山'
别名
alias设置别名
在mysql查询时,表的名字或者字段名太长,可以用别名替代,方便书写,增加可读性
可以给表起别名,但是要注意别名不能和数据库中的其他表重名
列的别名在结果中可以显示,但是表的别名在结果中没有显示,只能用于查询
例:
name设置别名'姓名',score设置别名'成绩',表info设置别名'a'
查询name='小黑'并且其id=表a中的id数据
select name 姓名,score 成绩 from info a where name='小黑' and id = a.id;
as语句创表
例:
创建表test,其数据结构从表info复制过来
create table test as select * from info;
#注意,用as语句创建表时候主键会消失,约束和索引不会被复制过来
as+while选择数据创表
例:
创建表test1,其数据来自表info中score大于60的数据
create table test1 as select * from info where score >=60;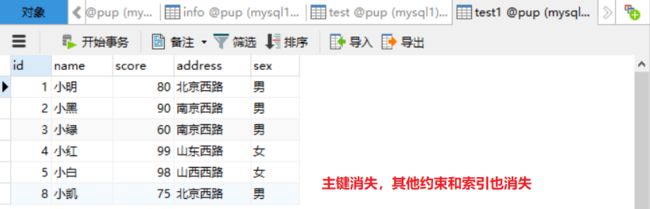
子查询
select ... (select...)
括号里面的查询语句会先于主查询语句执行,然后再把子查询的结果作为条件返回给主查询条件进行过滤
子查询返回的结果只能是单列
多表联查不超过三张
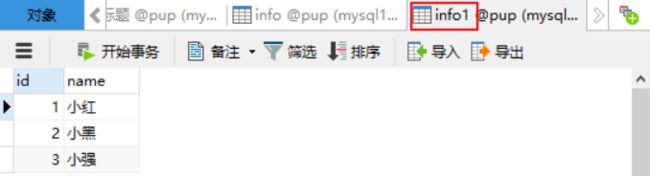
例:
从info1查询id,并作为从info查询id、那name、score的条件
select id,name,score from info where id in (select id from info1);


子查询语句还可以用在insert、update、delete一起使用
exists
关键字在子查询时,主要用于判断子查询的结果集是否为空,不为空,返回true 为空返回false
例:
根据info表,查询出大于80分的人,然后统计有多少个
select count(*) from info a where exists (select id from info where score > 80 and info.id=a.id);
视图
视图在mysql中是一个虚拟表,基于查询结果得出的一个虚拟表
在工作当中,我们查询的表未必是真表,有可能是基于真表查询结果的一个虚拟表
可以简化复杂的查询语句,隐藏表的细节,提供安全的数据访问
创建视图表可以是一张表的结果集,也可以是多个表共同的查询的结果集
视图表和真表之间的区别:
1、存储方式不一样,真表存储实际数据,真正写在磁盘当中的 视图不存储任何数据,仅仅是一个查询结果集的虚拟表
2、表可以增删改查,视图只能查看,展示数据
3、真表真实占用空间,视图不占用数据库空间
创建视图
例:
创建视图,其数据来自info中score大于等于80的行
create view test2 as select * from info where score >= 80;
查询视图
show full tables in 库名 where table_type like 'view';删除视图
drop view 视图名;根据多个表的结果集创建视图
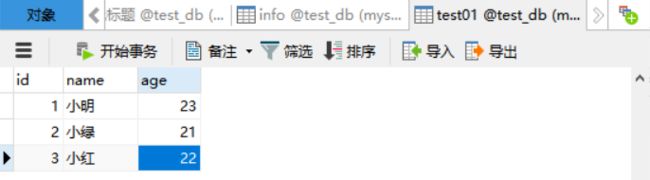
新建表test01:
create table test01 (
id int(4),
name varchar(15),
age int(2)
);
例:
info和test01表,创建视图,根据info的id,name,score加上test01的age
create view v_info(id,name,score,age) as select a.id,a.name,a.score,b.age from info a,test01 b where a.name=b.name;
更新info表数据:
update info set score = 95 where name = '小明';
更新视图中的数据:
update v_info set age=100 where name = '小红';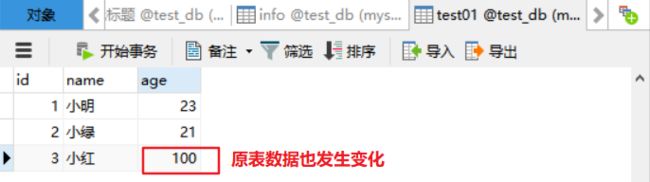
原表的数据发生变化,视图表的数据同步更新
更新视图表原表的数据也会发生变化
null值和空值

select * from info where address is null;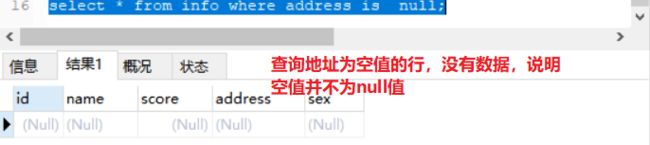
select count(score) from info;
select count(address) from info;
连接查询
内连接
将两张表或者多张表(不超过三张),同时符合特定条件的数据记录的组合
一个或者多个列的相同值才会有查询结果

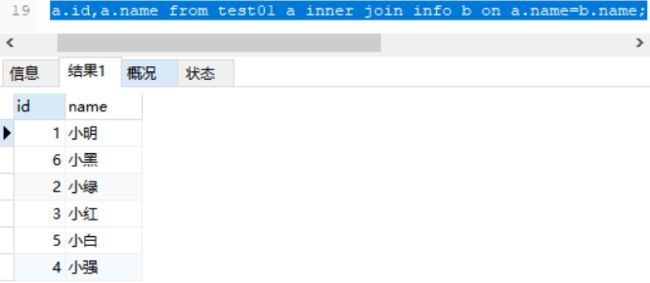
例:
select a.id,a.name from test01 a inner join info b on a.name=b.name;
左连接
左外连接,left join关键字表示
在左连接当中,左侧表是基础表,会接收左表的所有行,然后和右表(参考表)记录进行匹配
会匹配左表当中的所有行以及右表中符合条件的行
例:
select * from test01 a left join info b on a.name=b.name;
例:
select a.name,a.id,b.name from test01 a left join info b on a.name=b.name;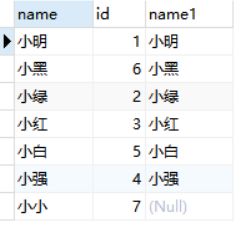
右连接
右外连接,right join关键字表示
在右连接当中,右侧表是基础表,会接收右表的所有行,然后和左表(参考表)记录进行匹配
会匹配右表当中的所有行以及左表中符合条件的行